



为了便于大家更系统的入门和学习AI智能体,最近,我们将为大家分享系列内容
在前面的文章中,我们讲解了智能体的基础知识,并体验了主流框架带来的开发便利。从本文开始,我们将进入一个更具挑战也更有价值的阶段:从零开始,逐步构建一个智能体框架 —— HelloAgents。
一、为什么需要自建Agent框架?
在智能体技术快速发展的今天,市面上已经存在众多成熟的Agent框架。那么,为什么我们还要从零开始构建一个新的框架呢?
1)市面框架的快速迭代与局限性
智能体领域是一个快速发展的领域,随时会有新的概念产生,对于智能体的设计每个框架都有自己的定位和理解,不过智能体的核心知识点是一致的。
- 过度抽象的复杂性:许多框架为了追求通用性,引入了大量抽象层和配置选项。以LangChain为例,其链式调用机制虽然灵活,但对初学者而言学习曲线陡峭,往往需要理解大量概念才能完成简单任务。
- 快速迭代带来的不稳定性:商业化框架为了抢占市场,API接口变更频繁。开发者经常面临版本升级后代码无法运行的困扰,维护成本居高不下。
- 黑盒化的实现逻辑:许多框架将核心逻辑封装得过于严密,开发者难以理解Agent的内部工作机制,缺乏深度定制能力。遇到问题时只能依赖文档和社区支持,尤其是如果社区不够活跃,可能一个反馈意见会非常久也没有人推进,影响后续的开发效率。
- 依赖关系的复杂性:成熟框架往往携带大量依赖包,安装包体积庞大,在需要与别的项目代码配合的下可能出现依赖冲突问题。
2)从使用者到构建者的能力跃迁
构建自己的Agent框架,实际上是一个从"使用者"向"构建者"转变的过程。这种转变带来的价值是长远的。
- 深度理解Agent工作原理:通过亲手实现每个组件,开发者能够真正理解Agent的思考过程、工具调用机制、以及各种设计模式的好坏与区别。
- 获得完全的控制权:自建框架意味着对每一行代码都有完全的掌控,可以根据具体需求进行精确调优,而不受第三方框架设计理念的束缚。
- 培养系统设计能力:框架构建过程涉及模块化设计、接口抽象、错误处理等软件工程核心技能,这些能力对开发者的长期成长具有重要价值。
3)定制化需求与深度掌握的必要性
在实际应用中,不同场景对智能体的需求差异巨大,往往都需要在通用框架基础上做二次开发。
- 特定领域的优化需求:金融、医疗、教育等垂直领域往往需要针对性的提示词模板、特殊的工具集成、以及定制化的安全策略。
- 性能与资源的精确控制:生产环境中,对响应时间、内存占用、并发处理能力都有严格要求,通用框架的"一刀切"方案往往无法满足精细化需求。
- 学习与教学的透明性要求:在我们的教学场景中,学习者更期待的是清晰地看到智能体的每一步构建过程,理解不同范式的工作机制,这要求框架具有高度的可观测性和可解释性。
构建一个新框架需要怎么设计?
构建一个新的Agent框架,关键不在于功能的多少,而在于设计理念是否能真正解决现有框架的痛点。HelloAgents框架的设计围绕着一个核心问题展开:如何让学习者既能快速上手,又能深入理解Agent的工作原理?
当你初次接触任何成熟的框架时,可能会被其丰富的功能所吸引,但很快就会发现一个问题:要完成一个简单的任务,往往需要理解Chain、Agent、Tool、Memory、Retriever等十几个不同的概念。每个概念都有自己的抽象层,学习曲线变得异常陡峭。这种复杂性虽然带来了强大的功能,但也成为了初学者的障碍。HelloAgents框架试图在功能完整性和学习友好性之间找到平衡点,形成了四个核心的设计理念。
1)轻量级与教学友好的平衡
一个优秀的学习框架应该具备完整的可读性。HelloAgents将核心代码按照章节区分开,这是基于一个简单的原则:任何有一定编程基础的开发者都应该能够在合理的时间内完全理解框架的工作原理。在依赖管理方面,框架采用了极简主义的策略。除了OpenAI的官方SDK和几个必要的基础库外,不引入任何重型依赖。如果遇到问题时,我们可以直接定位到框架本身的代码,而不需要在复杂的依赖关系中寻找答案。
2)基于标准API的务实选择
OpenAI的API已经成为了行业标准,几乎所有主流的LLM提供商都在努力兼容这套接口。HelloAgents选择在这个标准之上构建,而不是重新发明一套抽象接口。这个决定主要是出于几点动机。首先是兼容性的保证,当你掌握了HelloAgents的使用方法后,迁移到其他框架或将其集成到现有项目中时,底层的API调用逻辑是完全一致的。其次是学习成本的降低。你不需要学习新的概念模型,因为所有的操作都基于你已经熟悉的标准接口。
3)渐进式学习路径的精心设计
HelloAgents提供了一条清晰的学习路径。我们将会把每一章的学习代码,保存为一个可以pip下载的历史版本,因此无需担心代码的使用成本,因为每一个核心的功能都将会是你自己编写的。这种设计让你能够按照自己的需求和节奏前进。每一步的升级都是自然而然的,不会产生概念上的跳跃或理解上的断层。值得一提的是,我们这一章的内容,也是基于前六章的内容来完善的。同样,这一章也是为后续高级知识学习部分打下框架基础。
4)统一的“工具”抽象:万物皆为工具
为了彻底贯彻轻量级与教学友好的理念,HelloAgents在架构上做出了一个关键的简化:除了核心的Agent类,一切皆为Tools。在许多其他框架中需要独立学习的Memory(记忆)、RAG(检索增强生成)、RL(强化学习)、MCP(协议)等模块,在HelloAgents中都被统一抽象为一种“工具”。这种设计的初衷是消除不必要的抽象层,让学习者可以回归到最直观的“智能体调用工具”这一核心逻辑上,从而真正实现快速上手和深入理解的统一。
构建一个新框架的全过程
以我们的HelloAgents为例,让我们先看看核心学习内容:
hello-agents/├── hello_agents/│ ││ ├── core/ # 核心框架层│ │ ├── agent.py # Agent基类│ │ ├── llm.py # HelloAgentsLLM统一接口│ │ ├── message.py # 消息系统│ │ ├── config.py # 配置管理│ │ └── exceptions.py # 异常体系│ ││ ├── agents/ # Agent实现层│ │ ├── simple_agent.py # SimpleAgent实现│ │ ├── react_agent.py # ReActAgent实现│ │ ├── reflection_agent.py # ReflectionAgent实现│ │ └── plan_solve_agent.py # PlanAndSolveAgent实现│ ││ ├── tools/ # 工具系统层│ │ ├── base.py # 工具基类│ │ ├── registry.py # 工具注册机制│ │ ├── chain.py # 工具链管理系统│ │ ├── async_executor.py # 异步工具执行器│ │ └── builtin/ # 内置工具集│ │ ├── calculator.py # 计算工具│ │ └── search.py # 搜索工具└──
在开始编写具体代码之前,我们需要先建立一个清晰的架构蓝图。HelloAgents的架构设计遵循了"分层解耦、职责单一、接口统一"的核心原则,这样既保持了代码的组织性,也便于按照章节扩展内容。
模块一:核心框架层
1、HelloAgentsLLM 扩展
本节重点给大家介绍我们的升级方向,代码不会展开。代码实践查看:https://datawhalechina.github.io/hello-agents,我们将把这个基础客户端,改造为一个更具适应性的模型调用中枢。本次升级主要围绕以下三个目标展开:
- 多提供商支持:实现对 OpenAI、ModelScope、智谱 AI 等多种主流 LLM 服务商的无缝切换,避免框架与特定供应商绑定。
- 本地模型集成:引入 VLLM 和 Ollama 这两种高性能本地部署方案,作为对第 3.2.3 节中 Hugging Face Transformers 方案的生产级补充,满足数据隐私和成本控制的需求。
- 自动检测机制:建立一套自动识别机制,使框架能根据环境信息智能推断所使用的 LLM 服务类型,简化用户的配置过程。
1️⃣ 支持多提供商
我们之前定义的 HelloAgentsLLM 类,已经能够通过 api_key 和 base_url 这两个核心参数,连接任何兼容 OpenAI 接口的服务。这在理论上保证了通用性,但在实际应用中,不同的服务商在环境变量命名、默认 API 地址和推荐模型等方面都存在差异。如果每次切换服务商都需要用户手动查询并修改代码,会极大影响开发效率。为了解决这一问题,我们引入 provider。其改进思路是:让 HelloAgentsLLM 在内部处理不同服务商的配置细节,从而为用户提供一个统一、简洁的调用体验。
2️⃣ 本地模型调用
为了在本地实现高性能、生产级的模型推理服务,社区涌现出了 VLLM 和 Ollama 等优秀工具。它们通过连续批处理、PagedAttention 等技术,显著提升了模型的吞吐量和运行效率,并将模型封装为兼容 OpenAI 标准的 API 服务。这意味着,我们可以将它们无缝地集成到 HelloAgentsLLM 中。
VLLM
VLLM 是一个为 LLM 推理设计的高性能 Python 库。它通过 PagedAttention 等先进技术,可以实现比标准 Transformers 实现高出数倍的吞吐量。下面是在本地部署一个 VLLM 服务的完整步骤:
首先,需要根据你的硬件环境(特别是 CUDA 版本)安装 VLLM。推荐遵循其官方文档进行安装,以避免版本不匹配问题。
安装完成后,使用以下命令即可启动一个兼容 OpenAI 的 API 服务。VLLM 会自动从 Hugging Face Hub 下载指定的模型权重(如果本地不存在)。服务启动后,便会在 http://localhost:8000/v1 地址上提供与 OpenAI 兼容的 API。
Ollama
Ollama 进一步简化了本地模型的管理和部署,它将模型下载、配置和服务启动等步骤封装到了一条命令中,非常适合快速上手。访问 Ollama 官方网站下载并安装适用于你操作系统的客户端。
安装后,打开终端,执行以下命令即可下载并运行一个模型(以 Llama 3 为例)。Ollama 会自动处理模型的下载、服务封装和硬件加速配置。
当你在终端看到模型的交互提示时,即表示服务已经成功在后台启动。Ollama 默认会在 http://localhost:11434/v1 地址上暴露 OpenAI 兼容的 API 接口。
接入 HelloAgentsLLM
由于 VLLM 和 Ollama 都遵循了行业标准 API,将它们接入 HelloAgentsLLM 的过程非常简单。我们只需在实例化客户端时,将它们视为一个新的 provider 即可。
通过这种统一的设计,我们的智能体核心代码无需任何修改,就可以在云端 API 和本地模型之间自由切换。这为后续应用的开发、部署、成本控制以及保护数据隐私提供了极大的灵活性。
3️⃣ 自动检测机制
为了尽可能减少用户的配置负担并遵循“约定优于配置”的原则,HelloAgentsLLM 内部设计了两个核心辅助方法:_auto_detect_provider 和 _resolve_credentials。它们协同工作,_auto_detect_provider 负责根据环境信息推断服务商,而 _resolve_credentials 则根据推断结果完成具体的参数配置。
_auto_detect_provider 方法负责根据环境信息,按照下述优先级顺序,尝试自动推断服务商:
- 最高优先级:检查特定服务商的环境变量 这是最直接、最可靠的判断依据。框架会依次检查
MODELSCOPE_API_KEY,OPENAI_API_KEY,ZHIPU_API_KEY等环境变量是否存在。一旦发现任何一个,就会立即确定对应的服务商。 - 次高优先级:根据
base_url进行判断 如果用户没有设置特定服务商的密钥,但设置了通用的LLM_BASE_URL,框架会转而解析这个 URL。
- 域名匹配:通过检查 URL 中是否包含
"api-inference.modelscope.cn","api.openai.com"等特征字符串来识别云服务商。 - 端口匹配:通过检查 URL 中是否包含
:11434(Ollama),:8000(VLLM) 等本地服务的标准端口来识别本地部署方案。
- 辅助判断:分析 API 密钥的格式 在某些情况下,如果上述两种方式都无法确定,框架会尝试分析通用环境变量
LLM_API_KEY的格式。例如,某些服务商的 API 密钥有固定的前缀或独特的编码格式。不过,由于这种方式可能存在模糊性(例如多个服务商的密钥格式相似),因此它的优先级较低,仅作为辅助手段。
一旦 provider 被确定(无论是用户指定还是自动检测),_resolve_credentials 方法便会接手处理服务商的差异化配置。它会根据 provider 的值,去主动查找对应的环境变量,并为其设置默认的 base_url。
通过三种方法,现在的HelloAgentsLLM具有以下显著优势:
表 1 HelloAgentLLM不同版本特性对比

如上表所示,这种演进体现了框架设计的重要原则:从简单开始,逐步完善。我们在保持接口简洁的同时,增强了功能的完整性。
2、框架接口实现
在上节中,我们构建了 HelloAgentsLLM 这一核心组件,解决了与大语言模型通信的关键问题。不过它还需要一系列配套的接口和组件来处理数据流、管理配置、应对异常,并为上层应用的构建提供一个清晰、统一的结构。本节将讲述以下三个核心文件:
message.py: 定义了框架内统一的消息格式,确保了智能体与模型之间信息传递的标准化。config.py: 提供了一个中心化的配置管理方案,使框架的行为易于调整和扩展。agent.py: 定义了所有智能体的抽象基类(Agent),为后续实现不同类型的智能体提供了统一的接口和规范。
1️⃣ Message 类
在智能体与大语言模型的交互中,对话历史是至关重要的上下文。为了规范地管理这些信息,我们设计了一个简易 Message 类。在后续上下文工程章节中,会对其进行扩展。
"""消息系统"""from typing import Optional, Dict, Any, Literalfrom datetime import datetimefrom pydantic import BaseModel# 定义消息角色的类型,限制其取值MessageRole = Literal["user", "assistant", "system", "tool"]class Message(BaseModel): """消息类""" content: str role: MessageRole timestamp: datetime = None metadata: Optional[Dict[str, Any]] = None def __init__(self, content: str, role: MessageRole, **kwargs): super().__init__( content=content, role=role, timestamp=kwargs.get('timestamp', datetime.now()), metadata=kwargs.get('metadata', {}) ) def to_dict(self) -> Dict[str, Any]: """转换为字典格式(OpenAI API格式)""" return { "role": self.role, "content": self.content } def __str__(self) -> str: returnf"[{self.role}] {self.content}"
该类的设计有几个关键点。首先,我们通过 typing.Literal 将 role 字段的取值严格限制为 "user", "assistant", "system", "tool" 四种,这直接对应 OpenAI API 的规范,保证了类型安全。除了 content 和 role 这两个核心字段外,我们还增加了 timestamp 和 metadata,为日志记录和未来功能扩展预留了空间。最后,to_dict() 方法是其核心功能之一,负责将内部使用的 Message 对象转换为与 OpenAI API 兼容的字典格式,体现了“对内丰富,对外兼容”的设计原则。
2️⃣ Config 类
Config 类的职责是将代码中硬编码配置参数集中起来,并支持从环境变量中读取。
"""配置管理"""import osfrom typing import Optional, Dict, Anyfrom pydantic import BaseModelclass Config(BaseModel): """HelloAgents配置类""" # LLM配置 default_model: str = "gpt-3.5-turbo" default_provider: str = "openai" temperature: float = 0.7 max_tokens: Optional[int] = None # 系统配置 debug: bool = False log_level: str = "INFO" # 其他配置 max_history_length: int = 100 @classmethod def from_env(cls) -> "Config": """从环境变量创建配置""" return cls( debug=os.getenv("DEBUG", "false").lower() == "true", log_level=os.getenv("LOG_LEVEL", "INFO"), temperature=float(os.getenv("TEMPERATURE", "0.7")), max_tokens=int(os.getenv("MAX_TOKENS")) if os.getenv("MAX_TOKENS") elseNone, ) def to_dict(self) -> Dict[str, Any]: """转换为字典""" return self.dict()
首先,我们将配置项按逻辑划分为 LLM配置、系统配置 等,使结构一目了然。其次,每个配置项都设有合理的默认值,保证了框架在零配置下也能工作。最核心的是 from_env() 类方法,它允许用户通过设置环境变量来覆盖默认配置,无需修改代码,这在部署到不同环境时尤其有用。
3️⃣ Agent 抽象基类
Agent 类是整个框架的顶层抽象。它定义了一个智能体应该具备的通用行为和属性,但并不关心具体的实现方式。我们通过 Python 的 abc (Abstract Base Classes) 模块来实现它,这强制所有具体的智能体实现(如后续章节的 SimpleAgent, ReActAgent 等)都必须遵循同一个“接口”。
"""Agent基类"""from abc import ABC, abstractmethodfrom typing import Optional, Anyfrom .message import Messagefrom .llm import HelloAgentsLLMfrom .config import Configclass Agent(ABC): """Agent基类""" def __init__( self, name: str, llm: HelloAgentsLLM, system_prompt: Optional[str] = None, config: Optional[Config] = None ): self.name = name self.llm = llm self.system_prompt = system_prompt self.config = config or Config() self._history: list[Message] = [] @abstractmethod def run(self, input_text: str, **kwargs) -> str: """运行Agent""" pass def add_message(self, message: Message): """添加消息到历史记录""" self._history.append(message) def clear_history(self): """清空历史记录""" self._history.clear() def get_history(self) -> list[Message]: """获取历史记录""" return self._history.copy() def __str__(self) -> str: returnf"Agent(name={self.name}, provider={self.llm.provider})"
该类的设计体现了面向对象中的抽象原则。首先,它通过继承 ABC 被定义为一个不能直接实例化的抽象类。其构造函数 __init__ 清晰地定义了 Agent 的核心依赖:名称、LLM 实例、系统提示词和配置。最重要的部分是使用 @abstractmethod 装饰的 run 方法,它强制所有子类必须实现此方法,从而保证了所有智能体都有统一的执行入口。此外,基类还提供了通用的历史记录管理方法,这些方法与 Message 类协同工作,体现了组件间的联系。
至此,我们已经完成了 HelloAgents 框架核心基础组件的设计与实现。
模块二:Agent实现层
本节内容将在三种经典Agent范式(ReAct、Plan-and-Solve、Reflection)基础上进行框架化重构,并新增SimpleAgent作为基础对话范式。我们将把这些独立的Agent实现,改造为基于统一架构的框架组件。本次重构主要围绕以下三个核心目标展开:
- 提示词工程的系统性提升:对第四章中的提示词进行深度优化,从特定任务导向转向通用化设计,同时增强格式约束和角色定义。
- 接口与格式的标准化统一:建立统一的Agent基类和标准化的运行接口,所有Agent都遵循相同的初始化参数、方法签名和历史管理机制。
- 高度可配置的自定义能力:支持用户自定义提示词模板、配置参数和执行策略。
1️⃣ SimpleAgent
SimpleAgent是最基础的Agent实现,它展示了如何在框架基础上构建一个完整的对话智能体。我们将通过继承框架基类来重写SimpleAgent。首先,在你的项目目录中创建一个my_simple_agent.py文件:
# my_simple_agent.pyfrom typing import Optional, Iteratorfrom hello_agents import SimpleAgent, HelloAgentsLLM, Config, Messageclass MySimpleAgent(SimpleAgent): """ 重写的简单对话Agent 展示如何基于框架基类构建自定义Agent """ def __init__( self, name: str, llm: HelloAgentsLLM, system_prompt: Optional[str] = None, config: Optional[Config] = None, tool_registry: Optional['ToolRegistry'] = None, enable_tool_calling: bool = True ): super().__init__(name, llm, system_prompt, config) self.tool_registry = tool_registry self.enable_tool_calling = enable_tool_calling and tool_registry is not None print(f"✅ {name} 初始化完成,工具调用: {'启用' if self.enable_tool_calling else '禁用'}")
接下来,我们需要重写Agent基类的抽象方法run。SimpleAgent支持可选的工具调用功能,也方便后续章节的扩展:
# 继续在 my_simple_agent.py 中添加import reclass MySimpleAgent(SimpleAgent): # ... 前面的 __init__ 方法 def run(self, input_text: str, max_tool_iterations: int = 3, **kwargs) -> str: """ 重写的运行方法 - 实现简单对话逻辑,支持可选工具调用 """ print(f"🤖 {self.name} 正在处理: {input_text}") # 构建消息列表 messages = [] # 添加系统消息(可能包含工具信息) enhanced_system_prompt = self._get_enhanced_system_prompt() messages.append({"role": "system", "content": enhanced_system_prompt}) # 添加历史消息 for msg in self._history: messages.append({"role": msg.role, "content": msg.content}) # 添加当前用户消息 messages.append({"role": "user", "content": input_text}) # 如果没有启用工具调用,使用简单对话逻辑 ifnot self.enable_tool_calling: response = self.llm.invoke(messages, **kwargs) self.add_message(Message(input_text, "user")) self.add_message(Message(response, "assistant")) print(f"✅ {self.name} 响应完成") return response # 支持多轮工具调用的逻辑 return self._run_with_tools(messages, input_text, max_tool_iterations, **kwargs) def _get_enhanced_system_prompt(self) -> str: """构建增强的系统提示词,包含工具信息""" base_prompt = self.system_prompt or"你是一个有用的AI助手。" ifnot self.enable_tool_calling ornot self.tool_registry: return base_prompt # 获取工具描述 tools_description = self.tool_registry.get_tools_description() ifnot tools_description or tools_description == "暂无可用工具": return base_prompt tools_section = "\n\n## 可用工具\n" tools_section += "你可以使用以下工具来帮助回答问题:\n" tools_section += tools_description + "\n" tools_section += "\n## 工具调用格式\n" tools_section += "当需要使用工具时,请使用以下格式:\n" tools_section += "`[TOOL_CALL:{tool_name}:{parameters}]`\n" tools_section += "例如:`[TOOL_CALL:search:Python编程]` 或 `[TOOL_CALL:memory:recall=用户信息]`\n\n" tools_section += "工具调用结果会自动插入到对话中,然后你可以基于结果继续回答。\n" return base_prompt + tools_section
现在我们实现工具调用的核心逻辑:
# 继续在 my_simple_agent.py 中添加class MySimpleAgent(SimpleAgent): # ... 前面的方法 def _run_with_tools(self, messages: list, input_text: str, max_tool_iterations: int, **kwargs) -> str: """支持工具调用的运行逻辑""" current_iteration = 0 final_response = "" while current_iteration < max_tool_iterations: # 调用LLM response = self.llm.invoke(messages, **kwargs) # 检查是否有工具调用 tool_calls = self._parse_tool_calls(response) if tool_calls: print(f"🔧 检测到 {len(tool_calls)} 个工具调用") # 执行所有工具调用并收集结果 tool_results = [] clean_response = response for call in tool_calls: result = self._execute_tool_call(call['tool_name'], call['parameters']) tool_results.append(result) # 从响应中移除工具调用标记 clean_response = clean_response.replace(call['original'], "") # 构建包含工具结果的消息 messages.append({"role": "assistant", "content": clean_response}) # 添加工具结果 tool_results_text = "\n\n".join(tool_results) messages.append({"role": "user", "content": f"工具执行结果:\n{tool_results_text}\n\n请基于这些结果给出完整的回答。"}) current_iteration += 1 continue # 没有工具调用,这是最终回答 final_response = response break # 如果超过最大迭代次数,获取最后一次回答 if current_iteration >= max_tool_iterations andnot final_response: final_response = self.llm.invoke(messages, **kwargs) # 保存到历史记录 self.add_message(Message(input_text, "user")) self.add_message(Message(final_response, "assistant")) print(f"✅ {self.name} 响应完成") return final_response def _parse_tool_calls(self, text: str) -> list: """解析文本中的工具调用""" pattern = r'\[TOOL_CALL:([^:]+):([^\]]+)\]' matches = re.findall(pattern, text) tool_calls = [] for tool_name, parameters in matches: tool_calls.append({ 'tool_name': tool_name.strip(), 'parameters': parameters.strip(), 'original': f'[TOOL_CALL:{tool_name}:{parameters}]' }) return tool_calls def _execute_tool_call(self, tool_name: str, parameters: str) -> str: """执行工具调用""" ifnot self.tool_registry: returnf"❌ 错误:未配置工具注册表" try: # 智能参数解析 if tool_name == 'calculator': # 计算器工具直接传入表达式 result = self.tool_registry.execute_tool(tool_name, parameters) else: # 其他工具使用智能参数解析 param_dict = self._parse_tool_parameters(tool_name, parameters) tool = self.tool_registry.get_tool(tool_name) ifnot tool: returnf"❌ 错误:未找到工具 '{tool_name}'" result = tool.run(param_dict) returnf"🔧 工具 {tool_name} 执行结果:\n{result}" except Exception as e: returnf"❌ 工具调用失败:{str(e)}" def _parse_tool_parameters(self, tool_name: str, parameters: str) -> dict: """智能解析工具参数""" param_dict = {} if'='in parameters: # 格式: key=value 或 action=search,query=Python if','in parameters: # 多个参数:action=search,query=Python,limit=3 pairs = parameters.split(',') for pair in pairs: if'='in pair: key, value = pair.split('=', 1) param_dict[key.strip()] = value.strip() else: # 单个参数:key=value key, value = parameters.split('=', 1) param_dict[key.strip()] = value.strip() else: # 直接传入参数,根据工具类型智能推断 if tool_name == 'search': param_dict = {'query': parameters} elif tool_name == 'memory': param_dict = {'action': 'search', 'query': parameters} else: param_dict = {'input': parameters} return param_dict
我们还可以为自定义Agent添加流式响应功能和便利方法:
# 继续在 my_simple_agent.py 中添加class MySimpleAgent(SimpleAgent): # ... 前面的方法 def stream_run(self, input_text: str, **kwargs) -> Iterator[str]: """ 自定义的流式运行方法 """ print(f"🌊 {self.name} 开始流式处理: {input_text}") messages = [] if self.system_prompt: messages.append({"role": "system", "content": self.system_prompt}) for msg in self._history: messages.append({"role": msg.role, "content": msg.content}) messages.append({"role": "user", "content": input_text}) # 流式调用LLM full_response = "" print("📝 实时响应: ", end="") for chunk in self.llm.stream_invoke(messages, **kwargs): full_response += chunk print(chunk, end="", flush=True) yield chunk print() # 换行 # 保存完整对话到历史记录 self.add_message(Message(input_text, "user")) self.add_message(Message(full_response, "assistant")) print(f"✅ {self.name} 流式响应完成") def add_tool(self, tool) -> None: """添加工具到Agent(便利方法)""" ifnot self.tool_registry: from hello_agents import ToolRegistry self.tool_registry = ToolRegistry() self.enable_tool_calling = True self.tool_registry.register_tool(tool) print(f"🔧 工具 '{tool.name}' 已添加") def has_tools(self) -> bool: """检查是否有可用工具""" return self.enable_tool_calling and self.tool_registry isnotNone def remove_tool(self, tool_name: str) -> bool: """移除工具(便利方法)""" if self.tool_registry: self.tool_registry.unregister(tool_name) returnTrue returnFalse def list_tools(self) -> list: """列出所有可用工具""" if self.tool_registry: return self.tool_registry.list_tools() return []
创建一个测试文件test_simple_agent.py:
# test_simple_agent.pyfrom dotenv import load_dotenvfrom hello_agents import HelloAgentsLLM, ToolRegistryfrom hello_agents.tools import CalculatorToolfrom my_simple_agent import MySimpleAgent# 加载环境变量load_dotenv()# 创建LLM实例llm = HelloAgentsLLM()# 测试1:基础对话Agent(无工具)print("=== 测试1:基础对话 ===")basic_agent = MySimpleAgent( name="基础助手", llm=llm, system_prompt="你是一个友好的AI助手,请用简洁明了的方式回答问题。")response1 = basic_agent.run("你好,请介绍一下自己")print(f"基础对话响应: {response1}\n")# 测试2:带工具的Agentprint("=== 测试2:工具增强对话 ===")tool_registry = ToolRegistry()calculator = CalculatorTool()tool_registry.register_tool(calculator)enhanced_agent = MySimpleAgent( name="增强助手", llm=llm, system_prompt="你是一个智能助手,可以使用工具来帮助用户。", tool_registry=tool_registry, enable_tool_calling=True)response2 = enhanced_agent.run("请帮我计算 15 * 8 + 32")print(f"工具增强响应: {response2}\n")# 测试3:流式响应print("=== 测试3:流式响应 ===")print("流式响应: ", end="")for chunk in basic_agent.stream_run("请解释什么是人工智能"): pass# 内容已在stream_run中实时打印# 测试4:动态添加工具print("\n=== 测试4:动态工具管理 ===")print(f"添加工具前: {basic_agent.has_tools()}")basic_agent.add_tool(calculator)print(f"添加工具后: {basic_agent.has_tools()}")print(f"可用工具: {basic_agent.list_tools()}")# 查看对话历史print(f"\n对话历史: {len(basic_agent.get_history())} 条消息")
在本节中,我们通过继承 Agent 基类,成功构建了一个功能完备且遵循框架规范的基础对话智能体 MySimpleAgent。它不仅支持基础对话,还具备可选的工具调用能力、流式响应和便利的工具管理方法。
2️⃣ ReActAgent
框架化的 ReActAgent 在保持核心逻辑不变的同时,提升了代码的组织性和可维护性,主要是通过提示词优化和与框架工具系统的集成。
1)提示词模板的改进
保持了原有的格式要求,强调"每次只能执行一个步骤",避免混乱,并明确了两种Action的使用场景。
MY_REACT_PROMPT = """你是一个具备推理和行动能力的AI助手。你可以通过思考分析问题,然后调用合适的工具来获取信息,最终给出准确的答案。## 可用工具{tools}## 工作流程请严格按照以下格式进行回应,每次只能执行一个步骤:Thought: 分析当前问题,思考需要什么信息或采取什么行动。Action: 选择一个行动,格式必须是以下之一:- `{{tool_name}}[{{tool_input}}]` - 调用指定工具- `Finish[最终答案]` - 当你有足够信息给出最终答案时## 重要提醒1. 每次回应必须包含Thought和Action两部分2. 工具调用的格式必须严格遵循:工具名[参数]3. 只有当你确信有足够信息回答问题时,才使用Finish4. 如果工具返回的信息不够,继续使用其他工具或相同工具的不同参数## 当前任务**Question:** {question}## 执行历史{history}现在开始你的推理和行动:"""
(2)重写ReActAgent的完整实现
创建my_react_agent.py文件来重写ReActAgent:
# my_react_agent.pyimport refrom typing import Optional, List, Tuplefrom hello_agents import ReActAgent, HelloAgentsLLM, Config, Message, ToolRegistryclass MyReActAgent(ReActAgent): """ 重写的ReAct Agent - 推理与行动结合的智能体 """ def __init__( self, name: str, llm: HelloAgentsLLM, tool_registry: ToolRegistry, system_prompt: Optional[str] = None, config: Optional[Config] = None, max_steps: int = 5, custom_prompt: Optional[str] = None ): super().__init__(name, llm, system_prompt, config) self.tool_registry = tool_registry self.max_steps = max_steps self.current_history: List[str] = [] self.prompt_template = custom_prompt if custom_prompt else MY_REACT_PROMPT print(f"✅ {name} 初始化完成,最大步数: {max_steps}")
其初始化参数的含义如下:
name: Agent的名称。llm:HelloAgentsLLM的实例,负责与大语言模型通信。tool_registry:ToolRegistry的实例,用于管理和执行Agent可用的工具。system_prompt: 系统提示词,用于设定Agent的角色和行为准则。config: 配置对象,用于传递框架级的设置。max_steps: ReAct循环的最大执行步数,防止无限循环。custom_prompt: 自定义的提示词模板,用于替换默认的ReAct提示词。
框架化的ReActAgent将执行流程分解为清晰的步骤:
def run(self, input_text: str, **kwargs) -> str: """运行ReAct Agent""" self.current_history = [] current_step = 0 print(f"\n🤖 {self.name} 开始处理问题: {input_text}") while current_step < self.max_steps: current_step += 1 print(f"\n--- 第 {current_step} 步 ---") # 1. 构建提示词 tools_desc = self.tool_registry.get_tools_description() history_str = "\n".join(self.current_history) prompt = self.prompt_template.format( tools=tools_desc, question=input_text, history=history_str ) # 2. 调用LLM messages = [{"role": "user", "content": prompt}] response_text = self.llm.invoke(messages, **kwargs) # 3. 解析输出 thought, action = self._parse_output(response_text) # 4. 检查完成条件 if action and action.startswith("Finish"): final_answer = self._parse_action_input(action) self.add_message(Message(input_text, "user")) self.add_message(Message(final_answer, "assistant")) return final_answer # 5. 执行工具调用 if action: tool_name, tool_input = self._parse_action(action) observation = self.tool_registry.execute_tool(tool_name, tool_input) self.current_history.append(f"Action: {action}") self.current_history.append(f"Observation: {observation}") # 达到最大步数 final_answer = "抱歉,我无法在限定步数内完成这个任务。" self.add_message(Message(input_text, "user")) self.add_message(Message(final_answer, "assistant")) return final_answer
通过以上重构,我们将 ReAct 范式成功地集成到了框架中。核心改进在于利用了统一的 ToolRegistry 接口,并通过一个可配置、格式更严谨的提示词模板,提升了智能体执行思考-行动循环的稳定性。对于ReAct的测试案例,由于需要调用工具,所以统一放在文末提供测试代码。
3️⃣ ReflectionAgent
由于这几类Agent已经实现过核心逻辑,所以这里只给出对应的Prompt。与之前专门针对代码生成的提示词不同,框架化的版本采用了通用化设计,使其适用于文本生成、分析、创作等多种场景,并通过custom_prompts参数支持用户深度定制。
DEFAULT_PROMPTS = { "initial": """请根据以下要求完成任务:任务: {task}请提供一个完整、准确的回答。""", "reflect": """请仔细审查以下回答,并找出可能的问题或改进空间:# 原始任务:{task}# 当前回答:{content}请分析这个回答的质量,指出不足之处,并提出具体的改进建议。如果回答已经很好,请回答"无需改进"。""", "refine": """请根据反馈意见改进你的回答:# 原始任务:{task}# 上一轮回答:{last_attempt}# 反馈意见:{feedback}请提供一个改进后的回答。"""}
你可以尝试根据第四章的代码,以及上文ReAct的实现,构建出自己的MyReflectionAgent。下面提供一个测试代码供验证想法。
# test_reflection_agent.pyfrom dotenv import load_dotenvfrom hello_agents import HelloAgentsLLMfrom my_reflection_agent import MyReflectionAgentload_dotenv()llm = HelloAgentsLLM()# 使用默认通用提示词general_agent = MyReflectionAgent(name="我的反思助手", llm=llm)# 使用自定义代码生成提示词(类似第四章)code_prompts = { "initial": "你是Python专家,请编写函数:{task}", "reflect": "请审查代码的算法效率:\n任务:{task}\n代码:{content}", "refine": "请根据反馈优化代码:\n任务:{task}\n反馈:{feedback}"}code_agent = MyReflectionAgent( name="我的代码生成助手", llm=llm, custom_prompts=code_prompts)# 测试使用result = general_agent.run("写一篇关于人工智能发展历程的简短文章")print(f"最终结果: {result}")
4️⃣ PlanAndSolveAgent
与第四章自由文本的计划输出不同,框架化版本强制要求Planner以Python列表的格式输出计划,并提供了完整的异常处理机制,确保了后续步骤能够稳定执行。框架化的Plan-and-Solve提示词:
# 默认规划器提示词模板DEFAULT_PLANNER_PROMPT = """你是一个顶级的AI规划专家。你的任务是将用户提出的复杂问题分解成一个由多个简单步骤组成的行动计划。请确保计划中的每个步骤都是一个独立的、可执行的子任务,并且严格按照逻辑顺序排列。你的输出必须是一个Python列表,其中每个元素都是一个描述子任务的字符串。问题: {question}请严格按照以下格式输出你的计划:```python["步骤1", "步骤2", "步骤3", ...]```"""# 默认执行器提示词模板DEFAULT_EXECUTOR_PROMPT = """你是一位顶级的AI执行专家。你的任务是严格按照给定的计划,一步步地解决问题。你将收到原始问题、完整的计划、以及到目前为止已经完成的步骤和结果。请你专注于解决"当前步骤",并仅输出该步骤的最终答案,不要输出任何额外的解释或对话。# 原始问题:{question}# 完整计划:{plan}# 历史步骤与结果:{history}# 当前步骤:{current_step}请仅输出针对"当前步骤"的回答:"""
这一节仍然给出一个综合测试文件test_plan_solve_agent.py,可以自行设计实现。
# test_plan_solve_agent.pyfrom dotenv import load_dotenvfrom hello_agents.core.llm import HelloAgentsLLMfrom my_plan_solve_agent import MyPlanAndSolveAgent# 加载环境变量load_dotenv()# 创建LLM实例llm = HelloAgentsLLM()# 创建自定义PlanAndSolveAgentagent = MyPlanAndSolveAgent( name="我的规划执行助手", llm=llm)# 测试复杂问题question = "一个水果店周一卖出了15个苹果。周二卖出的苹果数量是周一的两倍。周三卖出的数量比周二少了5个。请问这三天总共卖出了多少个苹果?"result = agent.run(question)print(f"\n最终结果: {result}")# 查看对话历史print(f"对话历史: {len(agent.get_history())} 条消息")
在最后可以补充一款新的提示词,可以尝试实现custom_prompt载入自定义提示词。
# 创建专门用于数学问题的自定义提示词math_prompts = { "planner": """你是数学问题规划专家。请将数学问题分解为计算步骤:问题: {question}输出格式:python["计算步骤1", "计算步骤2", "求总和"]""", "executor": """你是数学计算专家。请计算当前步骤:问题: {question}计划: {plan}历史: {history}当前步骤: {current_step}请只输出数值结果:"""}# 使用自定义提示词创建数学专用Agentmath_agent = MyPlanAndSolveAgent( name="数学计算助手", llm=llm, custom_prompts=math_prompts)# 测试数学问题math_result = math_agent.run(question)print(f"数学专用Agent结果: {math_result}")
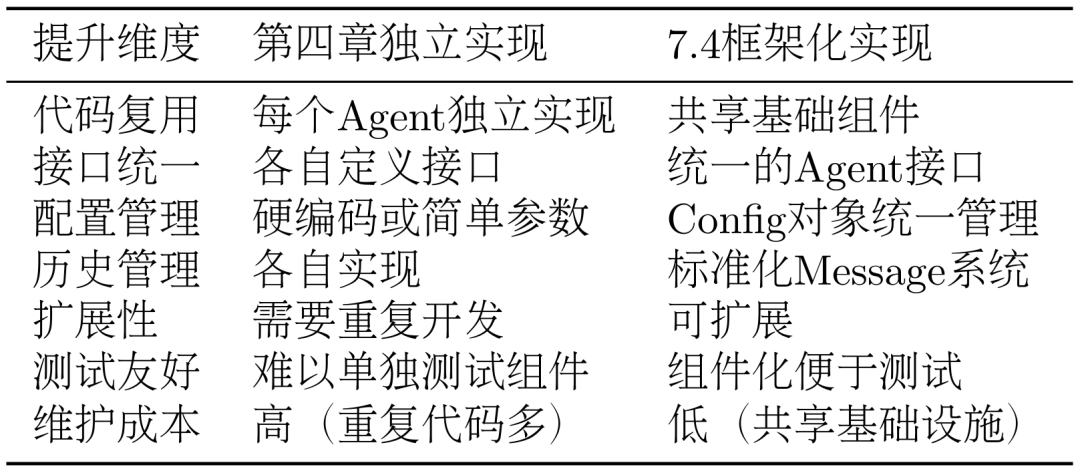
如表2所示,通过这种框架化的重构,我们不仅保持了第四章中各种Agent范式的核心功能,还大幅提升了代码的组织性、可维护性和扩展性。所有Agent现在都共享统一的基础架构,同时保持了各自的特色和优势。
表 2 Agent不同章节实现对比
5️⃣ FunctionCallAgent
FunctionCallAgent是hello-agents在0.2.8之后引入的Agent,它基于OpenAI原生函数调用机制的Agent,展示了如何使用OpenAI的函数调用机制来构建Agent。 它支持以下功能: _build_tool_schemas:通过工具的description构建OpenAI的function calling schema _extract_message_content:从OpenAI的响应中提取文本 _parse_function_call_arguments:解析模型返回的JSON字符串参数 _convert_parameter_types:转换参数类型
这些功能可以使其具备原生的OpenAI Functioncall的能力,对比使用prompt约束的方式,具备更强的鲁棒性。
def _invoke_with_tools(self, messages: list[dict[str, Any]], tools: list[dict[str, Any]], tool_choice: Union[str, dict], **kwargs): """调用底层OpenAI客户端执行函数调用""" client = getattr(self.llm, "_client", None) if client isNone: raise RuntimeError("HelloAgentsLLM 未正确初始化客户端,无法执行函数调用。") client_kwargs = dict(kwargs) client_kwargs.setdefault("temperature", self.llm.temperature) if self.llm.max_tokens isnotNone: client_kwargs.setdefault("max_tokens", self.llm.max_tokens) return client.chat.completions.create( model=self.llm.model, messages=messages, tools=tools, tool_choice=tool_choice, **client_kwargs, )#内部逻辑是对Openai 原生的functioncall作再封装#OpenAI 原生functioncall示例from openai import OpenAIclient = OpenAI()tools = [ { "type": "function", "function": { "name": "get_current_weather", "description": "Get the current weather in a given location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city and state, e.g. San Francisco, CA", }, "unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}, }, "required": ["location"], }, } }]messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]completion = client.chat.completions.create( model="gpt-5", messages=messages, tools=tools, tool_choice="auto")print(completion)
模块三:工具系统层
本节内容将在前面构建的Agent基础架构上,深入探讨工具系统的设计与实现。我们将从基础设施建设开始,逐步深入到自定义开发设计。本节的学习目标围绕以下三个核心方面展开:
- 统一的工具抽象与管理:建立标准化的Tool基类和ToolRegistry注册机制,为工具的开发、注册、发现和执行提供统一的基础设施。
- 实战驱动的工具开发:以数学计算工具为案例,展示如何设计和实现自定义工具,让读者掌握工具开发的完整流程。
- 高级整合与优化策略:通过多源搜索工具的设计,展示如何整合多个外部服务,实现智能后端选择、结果合并和容错处理,体现工具系统在复杂场景下的设计思维。
1️⃣ 工具基类与注册机制设计
在构建可扩展的工具系统时,我们需要首先建立一套标准化的基础设施。这套基础设施包括Tool基类、ToolRegistry注册表,以及工具管理机制。
1)Tool基类的抽象设计
Tool基类是整个工具系统的核心抽象,它定义了所有工具必须遵循的接口规范:
class Tool(ABC): """工具基类""" def __init__(self, name: str, description: str): self.name = name self.description = description @abstractmethod def run(self, parameters: Dict[str, Any]) -> str: """执行工具""" pass @abstractmethod def get_parameters(self) -> List[ToolParameter]: """获取工具参数定义""" pass
这个设计体现了面向对象设计的核心思想:通过统一的run方法接口,所有工具都能以一致的方式执行,接受字典参数并返回字符串结果,确保了框架的一致性。同时,工具具备了自描述能力,通过get_parameters方法能够清晰地告诉调用者自己需要什么参数,这种内省机制为自动化文档生成和参数验证提供了基础。而name和description等元数据的设计,则让工具系统具备了良好的可发现性和可理解性。
2)ToolParameter参数定义系统
为了支持复杂的参数验证和文档生成,我们设计了ToolParameter类:
class ToolParameter(BaseModel): """工具参数定义""" name: str type: str description: str required: bool = True default: Any = None
这种设计让工具能够精确描述自己的参数需求,支持类型检查、默认值设置和文档自动生成。
3)ToolRegistry注册表的实现
ToolRegistry是工具系统的管理中枢,它提供了工具的注册、发现、执行等核心功能,在这一节我们主要用到以下功能:
class ToolRegistry: """HelloAgents工具注册表""" def __init__(self): self._tools: dict[str, Tool] = {} self._functions: dict[str, dict[str, Any]] = {} def register_tool(self, tool: Tool): """注册Tool对象""" if tool.name in self._tools: print(f"⚠️ 警告:工具 '{tool.name}' 已存在,将被覆盖。") self._tools[tool.name] = tool print(f"✅ 工具 '{tool.name}' 已注册。") def register_function(self, name: str, description: str, func: Callable[[str], str]): """ 直接注册函数作为工具(简便方式) Args: name: 工具名称 description: 工具描述 func: 工具函数,接受字符串参数,返回字符串结果 """ if name in self._functions: print(f"⚠️ 警告:工具 '{name}' 已存在,将被覆盖。") self._functions[name] = { "description": description, "func": func } print(f"✅ 工具 '{name}' 已注册。")
ToolRegistry支持两种注册方式:
- Tool对象注册:适合复杂工具,支持完整的参数定义和验证
- 函数直接注册:适合简单工具,快速集成现有函数
4)工具发现与管理机制
注册表提供了丰富的工具管理功能:
def get_tools_description(self) -> str: """获取所有可用工具的格式化描述字符串""" descriptions = [] # Tool对象描述 for tool in self._tools.values(): descriptions.append(f"- {tool.name}: {tool.description}") # 函数工具描述 for name, info in self._functions.items(): descriptions.append(f"- {name}: {info['description']}") return "\n".join(descriptions) if descriptions else "暂无可用工具"
这个方法生成的描述字符串可以直接用于构建Agent的提示词,让Agent了解可用的工具。
def to_openai_schema(self) -> Dict[str, Any]: """转换为 OpenAI function calling schema 格式 用于 FunctionCallAgent,使工具能够被 OpenAI 原生 function calling 使用 Returns: 符合 OpenAI function calling 标准的 schema """ parameters = self.get_parameters() # 构建 properties properties = {} required = [] for param in parameters: # 基础属性定义 prop = { "type": param.type, "description": param.description } # 如果有默认值,添加到描述中(OpenAI schema 不支持 default 字段) if param.default isnotNone: prop["description"] = f"{param.description} (默认: {param.default})" # 如果是数组类型,添加 items 定义 if param.type == "array": prop["items"] = {"type": "string"} # 默认字符串数组 properties[param.name] = prop # 收集必需参数 if param.required: required.append(param.name) return { "type": "function", "function": { "name": self.name, "description": self.description, "parameters": { "type": "object", "properties": properties, "required": required } } }
这个方法生成的schema可以直接用于原生的OpenAI SDK的工具调用。
2️⃣ 自定义工具开发
有了基础设施后,我们来看看如何开发一个完整的自定义工具。数学计算工具是一个很好的例子,因为它简单直观,最直接的方式是使用ToolRegistry的函数注册功能。
让我们创建一个自定义的数学计算工具。首先,在你的项目目录中创建my_calculator_tool.py:
# my_calculator_tool.pyimport astimport operatorimport mathfrom hello_agents import ToolRegistrydef my_calculate(expression: str) -> str: """简单的数学计算函数""" ifnot expression.strip(): return"计算表达式不能为空" # 支持的基本运算 operators = { ast.Add: operator.add, # + ast.Sub: operator.sub, # - ast.Mult: operator.mul, # * ast.Div: operator.truediv, # / } # 支持的基本函数 functions = { 'sqrt': math.sqrt, 'pi': math.pi, } try: node = ast.parse(expression, mode='eval') result = _eval_node(node.body, operators, functions) return str(result) except: return"计算失败,请检查表达式格式"def _eval_node(node, operators, functions): """简化的表达式求值""" if isinstance(node, ast.Constant): return node.value elif isinstance(node, ast.BinOp): left = _eval_node(node.left, operators, functions) right = _eval_node(node.right, operators, functions) op = operators.get(type(node.op)) return op(left, right) elif isinstance(node, ast.Call): func_name = node.func.id if func_name in functions: args = [_eval_node(arg, operators, functions) for arg in node.args] return functions[func_name](*args) elif isinstance(node, ast.Name): if node.id in functions: return functions[node.id]def create_calculator_registry(): """创建包含计算器的工具注册表""" registry = ToolRegistry() # 注册计算器函数 registry.register_function( name="my_calculator", description="简单的数学计算工具,支持基本运算(+,-,*,/)和sqrt函数", func=my_calculate ) return registry
工具不仅支持基本的四则运算,还涵盖了常用的数学函数和常数,满足了大多数计算场景的需求。你也可以自己扩展这个文件,制作一个更加完备的计算函数。我们提供一个测试文件test_my_calculator.py帮助你验证功能实现:
# test_my_calculator.pyfrom dotenv import load_dotenvfrom my_calculator_tool import create_calculator_registry# 加载环境变量load_dotenv()def test_calculator_tool(): """测试自定义计算器工具""" # 创建包含计算器的注册表 registry = create_calculator_registry() print("🧪 测试自定义计算器工具\n") # 简单测试用例 test_cases = [ "2 + 3", # 基本加法 "10 - 4", # 基本减法 "5 * 6", # 基本乘法 "15 / 3", # 基本除法 "sqrt(16)", # 平方根 ] for i, expression in enumerate(test_cases, 1): print(f"测试 {i}: {expression}") result = registry.execute_tool("my_calculator", expression) print(f"结果: {result}\n")def test_with_simple_agent(): """测试与SimpleAgent的集成""" from hello_agents import HelloAgentsLLM # 创建LLM客户端 llm = HelloAgentsLLM() # 创建包含计算器的注册表 registry = create_calculator_registry() print("🤖 与SimpleAgent集成测试:") # 模拟SimpleAgent使用工具的场景 user_question = "请帮我计算 sqrt(16) + 2 * 3" print(f"用户问题: {user_question}") # 使用工具计算 calc_result = registry.execute_tool("my_calculator", "sqrt(16) + 2 * 3") print(f"计算结果: {calc_result}") # 构建最终回答 final_messages = [ {"role": "user", "content": f"计算结果是 {calc_result},请用自然语言回答用户的问题:{user_question}"} ] print("\n🎯 SimpleAgent的回答:") response = llm.think(final_messages) for chunk in response: print(chunk, end="", flush=True) print("\n")if __name__ == "__main__": test_calculator_tool() test_with_simple_agent()
通过这个简化的数学计算工具案例,我们学会了如何快速开发自定义工具:编写一个简单的计算函数,通过ToolRegistry注册,然后与SimpleAgent集成使用。为了更直观的观察,这里提供了图1,可以清晰理解代码的运行逻辑。
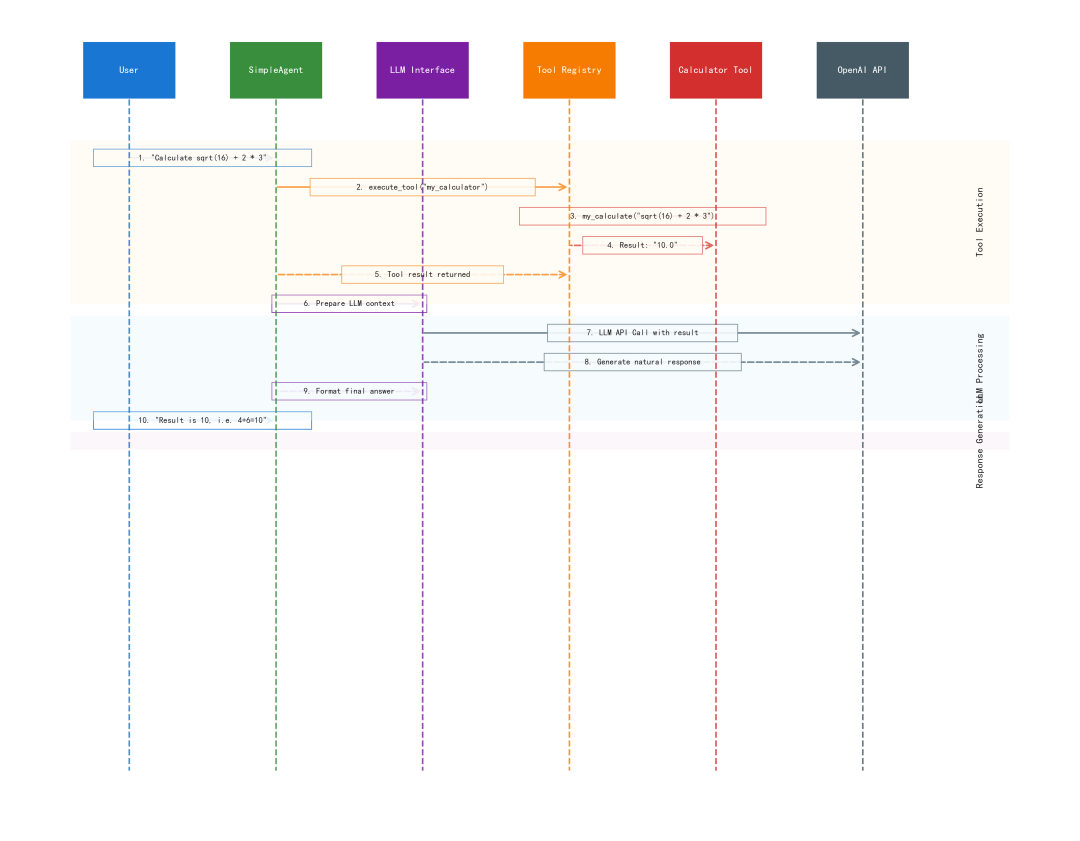
图 1 基于Helloagents的SimpleAgent运行工作流
3️⃣ 多源搜索工具
在实际应用中,我们经常需要整合多个外部服务来提供更强大的功能。搜索工具就是一个典型的例子,它整合多个搜索引擎,能提供更加完备的真实信息。在第一章我们使用过Tavily的搜索API,在第四章我们使用过SerpApi的搜索API。因此这次我们使用这两个API来实现多源搜索功能。如果没安装对应的python依赖可以运行下面这条脚本:
pip install "hello-agents[search]==0.1.1"
1)搜索工具的统一接口设计
HelloAgents框架内置的SearchTool展示了如何设计一个高级的多源搜索工具:
class SearchTool(Tool): """ 智能混合搜索工具 支持多种搜索引擎后端,智能选择最佳搜索源: 1. 混合模式 (hybrid) - 智能选择TAVILY或SERPAPI 2. Tavily API (tavily) - 专业AI搜索 3. SerpApi (serpapi) - 传统Google搜索 """ def __init__(self, backend: str = "hybrid", tavily_key: Optional[str] = None, serpapi_key: Optional[str] = None): super().__init__( name="search", description="一个智能网页搜索引擎。支持混合搜索模式,自动选择最佳搜索源。" ) self.backend = backend self.tavily_key = tavily_key or os.getenv("TAVILY_API_KEY") self.serpapi_key = serpapi_key or os.getenv("SERPAPI_API_KEY") self.available_backends = [] self._setup_backends()
这个设计的核心思想是根据可用的API密钥和依赖库,自动选择最佳的搜索后端。
2)TAVILY与SERPAPI搜索源的整合策略
框架实现了智能的后端选择逻辑:
def _search_hybrid(self, query: str) -> str: """混合搜索 - 智能选择最佳搜索源""" # 优先使用Tavily(AI优化的搜索) if"tavily"in self.available_backends: try: return self._search_tavily(query) except Exception as e: print(f"⚠️ Tavily搜索失败: {e}") # 如果Tavily失败,尝试SerpApi if"serpapi"in self.available_backends: print("🔄 切换到SerpApi搜索") return self._search_serpapi(query) # 如果Tavily不可用,使用SerpApi elif"serpapi"in self.available_backends: try: return self._search_serpapi(query) except Exception as e: print(f"⚠️ SerpApi搜索失败: {e}") # 如果都不可用,提示用户配置API return"❌ 没有可用的搜索源,请配置TAVILY_API_KEY或SERPAPI_API_KEY环境变量"
这种设计体现了高可用系统的核心理念:通过降级机制,系统能够从最优的搜索源逐步降级到可用的备选方案。当所有搜索源都不可用时,明确提示用户配置正确的API密钥。
3)搜索结果的统一格式化
不同搜索引擎返回的结果格式不同,框架通过统一的格式化方法来处理:
def _search_tavily(self, query: str) -> str: """使用Tavily搜索""" response = self.tavily_client.search( query=query, search_depth="basic", include_answer=True, max_results=3 ) result = f"🎯 Tavily AI搜索结果:{response.get('answer', '未找到直接答案')}\n\n" for i, item in enumerate(response.get('results', [])[:3], 1): result += f"[{i}] {item.get('title', '')}\n" result += f" {item.get('content', '')[:200]}...\n" result += f" 来源: {item.get('url', '')}\n\n" return result
基于框架的设计思想,我们可以创建自己的高级搜索工具。这次我们使用类的方式来展示不同的实现方法,创建my_advanced_search.py:
# my_advanced_search.pyimport osfrom typing import Optional, List, Dict, Anyfrom hello_agents import ToolRegistryclass MyAdvancedSearchTool: """ 自定义高级搜索工具类 展示多源整合和智能选择的设计模式 """ def __init__(self): self.name = "my_advanced_search" self.description = "智能搜索工具,支持多个搜索源,自动选择最佳结果" self.search_sources = [] self._setup_search_sources() def _setup_search_sources(self): """设置可用的搜索源""" # 检查Tavily可用性 if os.getenv("TAVILY_API_KEY"): try: from tavily import TavilyClient self.tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY")) self.search_sources.append("tavily") print("✅ Tavily搜索源已启用") except ImportError: print("⚠️ Tavily库未安装") # 检查SerpApi可用性 if os.getenv("SERPAPI_API_KEY"): try: import serpapi self.search_sources.append("serpapi") print("✅ SerpApi搜索源已启用") except ImportError: print("⚠️ SerpApi库未安装") if self.search_sources: print(f"🔧 可用搜索源: {', '.join(self.search_sources)}") else: print("⚠️ 没有可用的搜索源,请配置API密钥") def search(self, query: str) -> str: """执行智能搜索""" ifnot query.strip(): return"❌ 错误:搜索查询不能为空" # 检查是否有可用的搜索源 ifnot self.search_sources: return"""❌ 没有可用的搜索源,请配置以下API密钥之一:1. Tavily API: 设置环境变量 TAVILY_API_KEY 获取地址: https://tavily.com/2. SerpAPI: 设置环境变量 SERPAPI_API_KEY 获取地址: https://serpapi.com/配置后重新运行程序。""" print(f"🔍 开始智能搜索: {query}") # 尝试多个搜索源,返回最佳结果 for source in self.search_sources: try: if source == "tavily": result = self._search_with_tavily(query) if result and"未找到"notin result: returnf"📊 Tavily AI搜索结果:\n\n{result}" elif source == "serpapi": result = self._search_with_serpapi(query) if result and"未找到"notin result: returnf"🌐 SerpApi Google搜索结果:\n\n{result}" except Exception as e: print(f"⚠️ {source} 搜索失败: {e}") continue return"❌ 所有搜索源都失败了,请检查网络连接和API密钥配置" def _search_with_tavily(self, query: str) -> str: """使用Tavily搜索""" response = self.tavily_client.search(query=query, max_results=3) if response.get('answer'): result = f"💡 AI直接答案:{response['answer']}\n\n" else: result = "" result += "🔗 相关结果:\n" for i, item in enumerate(response.get('results', [])[:3], 1): result += f"[{i}] {item.get('title', '')}\n" result += f" {item.get('content', '')[:150]}...\n\n" return result def _search_with_serpapi(self, query: str) -> str: """使用SerpApi搜索""" import serpapi search = serpapi.GoogleSearch({ "q": query, "api_key": os.getenv("SERPAPI_API_KEY"), "num": 3 }) results = search.get_dict() result = "🔗 Google搜索结果:\n" if"organic_results"in results: for i, res in enumerate(results["organic_results"][:3], 1): result += f"[{i}] {res.get('title', '')}\n" result += f" {res.get('snippet', '')}\n\n" return resultdef create_advanced_search_registry(): """创建包含高级搜索工具的注册表""" registry = ToolRegistry() # 创建搜索工具实例 search_tool = MyAdvancedSearchTool() # 注册搜索工具的方法作为函数 registry.register_function( name="advanced_search", description="高级搜索工具,整合Tavily和SerpAPI多个搜索源,提供更全面的搜索结果", func=search_tool.search ) return registry
接下来可以测试我们自己编写的工具,创建test_advanced_search.py:
# test_advanced_search.pyfrom dotenv import load_dotenvfrom my_advanced_search import create_advanced_search_registry, MyAdvancedSearchTool# 加载环境变量load_dotenv()def test_advanced_search(): """测试高级搜索工具""" # 创建包含高级搜索工具的注册表 registry = create_advanced_search_registry() print("🔍 测试高级搜索工具\n") # 测试查询 test_queries = [ "Python编程语言的历史", "人工智能的最新发展", "2024年科技趋势" ] for i, query in enumerate(test_queries, 1): print(f"测试 {i}: {query}") result = registry.execute_tool("advanced_search", query) print(f"结果: {result}\n") print("-" * 60 + "\n")def test_api_configuration(): """测试API配置检查""" print("🔧 测试API配置检查:") # 直接创建搜索工具实例 search_tool = MyAdvancedSearchTool() # 如果没有配置API,会显示配置提示 result = search_tool.search("机器学习算法") print(f"搜索结果: {result}")def test_with_agent(): """测试与Agent的集成""" print("\n🤖 与Agent集成测试:") print("高级搜索工具已准备就绪,可以与Agent集成使用") # 显示工具描述 registry = create_advanced_search_registry() tools_desc = registry.get_tools_description() print(f"工具描述:\n{tools_desc}")if __name__ == "__main__": test_advanced_search() test_api_configuration() test_with_agent()
通过这个高级搜索工具的设计实践,我们学会了如何使用类的方式来构建复杂的工具系统。相比函数方式,类方式更适合需要维护状态(如API客户端、配置信息)的工具。
4️⃣ 工具系统的高级特性
在掌握了基础的工具开发和多源整合后,我们来探讨工具系统的高级特性。这些特性能够让工具系统在复杂的生产环境中稳定运行,并为Agent提供更强大的能力。
1)工具链式调用机制
在实际应用中,Agent经常需要组合使用多个工具来完成复杂任务。我们可以设计一个工具链管理器来支持这种场景,这里借鉴了提到的图的概念:
# tool_chain_manager.pyfrom typing import List, Dict, Any, Optionalfrom hello_agents import ToolRegistryclass ToolChain: """工具链 - 支持多个工具的顺序执行""" def __init__(self, name: str, description: str): self.name = name self.description = description self.steps: List[Dict[str, Any]] = [] def add_step(self, tool_name: str, input_template: str, output_key: str = None): """ 添加工具执行步骤 Args: tool_name: 工具名称 input_template: 输入模板,支持变量替换 output_key: 输出结果的键名,用于后续步骤引用 """ self.steps.append({ "tool_name": tool_name, "input_template": input_template, "output_key": output_key orf"step_{len(self.steps)}_result" }) def execute(self, registry: ToolRegistry, initial_input: str, context: Dict[str, Any] = None) -> str: """执行工具链""" context = context or {} context["input"] = initial_input print(f"🔗 开始执行工具链: {self.name}") for i, step in enumerate(self.steps, 1): tool_name = step["tool_name"] input_template = step["input_template"] output_key = step["output_key"] # 替换模板中的变量 try: tool_input = input_template.format(**context) except KeyError as e: returnf"❌ 工具链执行失败:模板变量 {e} 未找到" print(f" 步骤 {i}: 使用 {tool_name} 处理 '{tool_input[:50]}...'") # 执行工具 result = registry.execute_tool(tool_name, tool_input) context[output_key] = result print(f" ✅ 步骤 {i} 完成,结果长度: {len(result)} 字符") # 返回最后一步的结果 final_result = context[self.steps[-1]["output_key"]] print(f"🎉 工具链 '{self.name}' 执行完成") return final_resultclass ToolChainManager: """工具链管理器""" def __init__(self, registry: ToolRegistry): self.registry = registry self.chains: Dict[str, ToolChain] = {} def register_chain(self, chain: ToolChain): """注册工具链""" self.chains[chain.name] = chain print(f"✅ 工具链 '{chain.name}' 已注册") def execute_chain(self, chain_name: str, input_data: str, context: Dict[str, Any] = None) -> str: """执行指定的工具链""" if chain_name notin self.chains: returnf"❌ 工具链 '{chain_name}' 不存在" chain = self.chains[chain_name] return chain.execute(self.registry, input_data, context) def list_chains(self) -> List[str]: """列出所有工具链""" return list(self.chains.keys())# 使用示例def create_research_chain() -> ToolChain: """创建一个研究工具链:搜索 -> 计算 -> 总结""" chain = ToolChain( name="research_and_calculate", description="搜索信息并进行相关计算" ) # 步骤1:搜索信息 chain.add_step( tool_name="search", input_template="{input}", output_key="search_result" ) # 步骤2:基于搜索结果进行计算(如果需要) chain.add_step( tool_name="my_calculator", input_template="根据以下信息计算相关数值:{search_result}", output_key="calculation_result" ) return chain
2)异步工具执行支持
对于耗时的工具操作,我们可以提供异步执行支持:
# async_tool_executor.pyimport asyncioimport concurrent.futuresfrom typing import Dict, Any, List, Callablefrom hello_agents import ToolRegistryclass AsyncToolExecutor: """异步工具执行器""" def __init__(self, registry: ToolRegistry, max_workers: int = 4): self.registry = registry self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) asyncdef execute_tool_async(self, tool_name: str, input_data: str) -> str: """异步执行单个工具""" loop = asyncio.get_event_loop() def _execute(): return self.registry.execute_tool(tool_name, input_data) result = await loop.run_in_executor(self.executor, _execute) return result asyncdef execute_tools_parallel(self, tasks: List[Dict[str, str]]) -> List[str]: """并行执行多个工具""" print(f"🚀 开始并行执行 {len(tasks)} 个工具任务") # 创建异步任务 async_tasks = [] for task in tasks: tool_name = task["tool_name"] input_data = task["input_data"] async_task = self.execute_tool_async(tool_name, input_data) async_tasks.append(async_task) # 等待所有任务完成 results = await asyncio.gather(*async_tasks) print(f"✅ 所有工具任务执行完成") return results def __del__(self): """清理资源""" if hasattr(self, 'executor'): self.executor.shutdown(wait=True)# 使用示例asyncdef test_parallel_execution(): """测试并行工具执行""" from hello_agents import ToolRegistry registry = ToolRegistry() # 假设已经注册了搜索和计算工具 executor = AsyncToolExecutor(registry) # 定义并行任务 tasks = [ {"tool_name": "search", "input_data": "Python编程"}, {"tool_name": "search", "input_data": "机器学习"}, {"tool_name": "my_calculator", "input_data": "2 + 2"}, {"tool_name": "my_calculator", "input_data": "sqrt(16)"}, ] # 并行执行 results = await executor.execute_tools_parallel(tasks) for i, result in enumerate(results): print(f"任务 {i+1} 结果: {result[:100]}...")
基于以上的设计和实现经验,我们可以总结出工具系统开发的核心理念:在设计层面,每个工具都应该遵循单一职责原则,专注于特定功能的同时保持接口的统一性,并将完善的异常处理和安全优先的输入验证作为基本要求。在性能优化方面,利用异步执行提高并发处理能力,同时合理管理外部连接和系统资源。
本文小结
回顾本文,我们完成了一项富有挑战的任务:一步步构建了一个基础的智能体框架——HelloAgents。这个过程始终遵循着“分层解耦、职责单一、接口统一”的核心原则。
在框架的具体实现中,我们再次实现了四种经典的Agent范式。从SimpleAgent的基础对话模式,到ReActAgent的推理与行动结合;从ReflectionAgent的自我反思与迭代优化,到PlanAndSolveAgent的分解规划与逐步执行。而工具系统作为Agent能力延伸的核心,其构建过程则是一次完整的工程实践。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









