



如何让大模型低成本、可控、可持续地使用私有数据?
这正是 Llama-Index 诞生的起点。
从最初的GPT Index,到今天覆盖数据加载、索引构建、检索、路由、评估的完整 RAG 框架,LlamaIndex 已经不再只是一个“向量检索工具”,而是演化成了一个真正意义上的 数据驱动型大模型应用开发框架。
在这篇文章中,我将带你系统梳理 LlamaIndex 的框架入门介绍、RAG全生命周期能力,以及那些在真实项目中能显著拉开效果差距的“黑科技”~
一、Llama-Index框架入门介绍
- Llama-Index 项目介绍
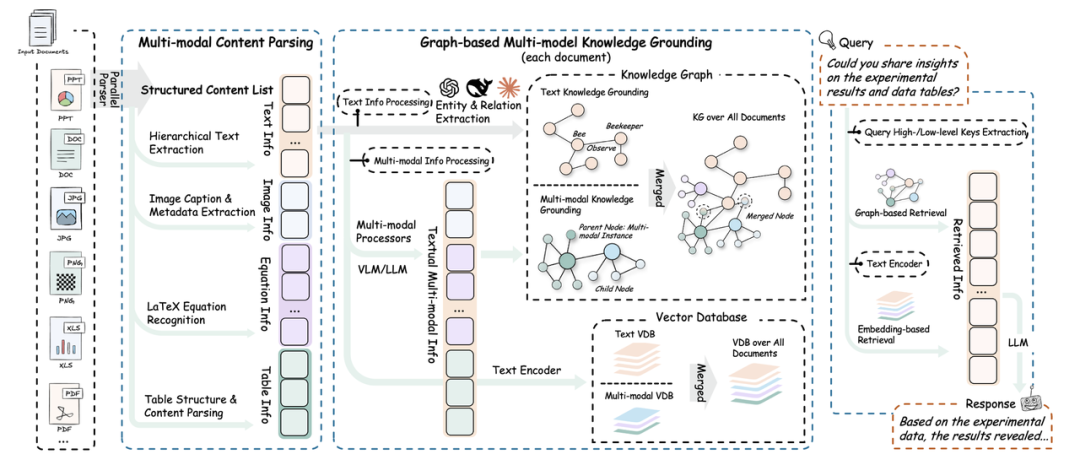
Llama-Index(前身为 GPT Index)由 Jerry Liu 于 2022 年底发起。项目的诞生背景源于大语言模型(LLM)落地初期的一个核心痛点:模型虽然具备强大的通用推理能力,但缺乏特定领域的私有知识(Private Knowledge),且受限于上下文窗口(Context Window)的长度,无法处理大规模文档。
Llama-Index 最初的初衷非常纯粹:构建一个高效的“接口”,将用户的私有数据(如 PDF、Notion、SQL、API 数据)转化为 LLM 能够理解和利用的格式,从而通过上下文学习(In-context Learning)来增强模型的能力。经过两年的高速迭代,它已从一个简单的索引工具演变为一个完整的**“数据驱动型”大模型应用开发框架**。
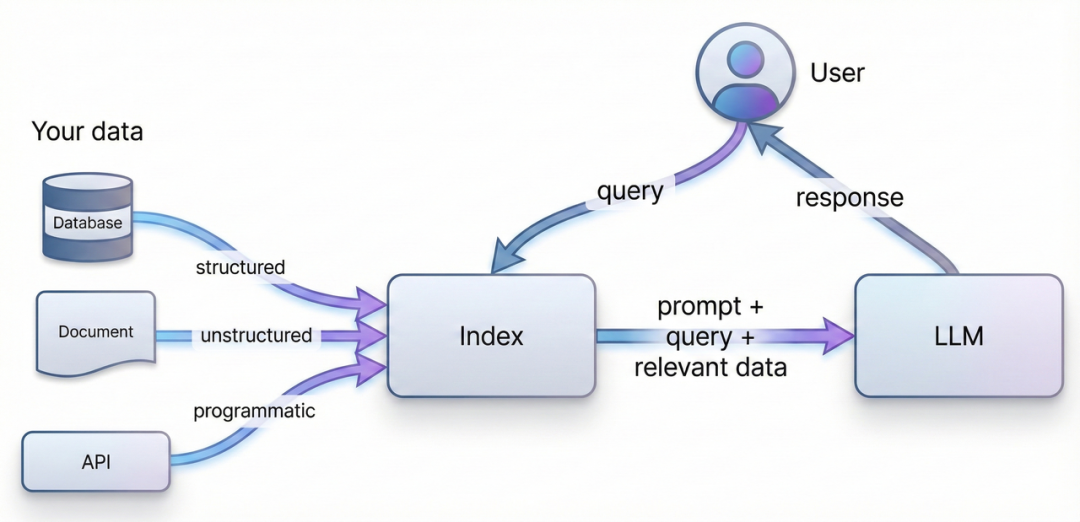
如果把大模型比作“大脑”,Llama-Index 的定位就是“记忆增强系统”。它的官方定义是:“用于构建上下文增强型(Context-augmented)LLM 应用程序的数据框架”**。
它不仅仅关注于如何向模型提问(Prompt Engineering),更侧重于数据管理(Data Management)的全生命周期,包括数据的摄入(Ingestion)、结构化索引(Indexing)以及高效检索(Retrieval)。其核心目标是打破私有数据孤岛,让 LLM 能够以最低的成本、最高的精度访问海量外部知识。
目前,Llama-Index 是全球 AI 开源社区中最活跃的项目之一。
- 技术迭代: 保持着极高的更新频率,已发布 v0.10+ 版本,完成了核心架构的模块化重构,具备了企业级生产环境所需的稳定性。
- 生态系统: 拥有庞大的 LlamaHub 数据加载器生态,支持数百种数据源(从文件系统到 SaaS 服务)的开箱即用连接;同时支持 Python 和 TypeScript 双语言版本。
在 LLM 开发领域,通过对比可以更清晰地理解两者的差异:
- LangChain(通用编排者):
- 定位: 通用的 LLM 应用开发框架。
- 强项: 侧重于**“计算逻辑”**的编排。它擅长管理复杂的 Agent 行为链、工具调用(Tool Usage)以及多模态交互的流程控制。它像是一个“胶水”,连接模型与万物。
- Llama-Index(数据专家):
- 定位: 专注于数据处理与检索的垂直框架。
- 强项: 侧重于**“数据结构”**的优化。它在 RAG 领域拥有更深的护城河,特别是在处理非结构化数据切片、层级索引构建、复杂查询路由等方面提供了更精细的控制能力。
相较于其他框架,Llama-Index 在 RAG(检索增强生成)方面展现出显著的专业性优势:
- 更丰富的数据索引结构: 不仅支持简单的向量索引,还原生支持树状索引、关键词表索引、知识图谱索引等多种结构。
- 更高级的检索策略: 提供了递归检索(Recursive Retrieval)、混合检索(Hybrid Search)及元数据过滤等开箱即用的高级功能。
- 数据与 LLM 的深度对齐: 能够更好地处理长文档摘要、跨文档推理等复杂的数据任务。
完整项目源码+讲解视频,可扫码添加助教老师免费获取哦~
- Llama-Index RAG核心优势
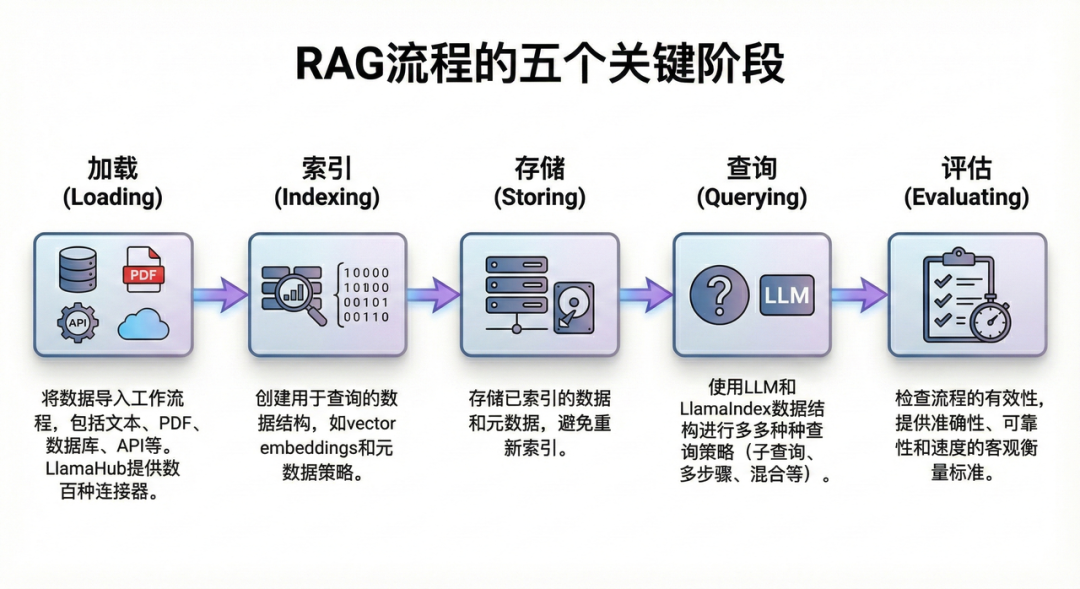
2.1 RAG 全生命周期(Full-Lifecycle)的闭环支持
与许多仅关注“向量检索”单一环节的工具不同,Llama-Index 提供了从数据源头到最终评估的 RAG 全流程解决方案。它将 RAG 系统抽象为五个标准化的流水线环节,开发者可以在同一个框架内完成所有工作,无需拼凑多个零散的工具库。
- 数据加载 (Loading): 提供统一接口将各类非结构化数据转化为标准的 Document 对象。
- 索引构建 (Indexing): 将文档切分(Chunking)并向量化(Embedding),构建出不仅包含向量、还包含元数据(Metadata)和节点关系(Relationships)的高级索引结构。
- 存储 (Storing): 原生适配数十种主流向量数据库(如 Chroma, Weaviate, Milvus)及图数据库,支持索引的持久化与增量更新。
- 查询 (Querying): 这一环节是 Llama-Index 的核心,它封装了检索、后处理和合成的复杂逻辑,对外提供简洁的查询接口。
- 评估 (Evaluation): 独有的 “Evaluation-First” 理念,内置了基于 LLM 的评估模块,能够对检索的准确性(Retrieval metrics)和生成的质量(Response metrics)进行自动化评分,解决了 RAG 难以优化的痛点。
2.2 极致的定制化空间与丰富的功能接口
Llama-Index 最大的架构优势在于其模块化(Modularity)设计。它将 RAG 的每个步骤都解耦为可插拔的组件,特别是在查询引擎(Query Engine)环节,提供了极高的定制自由度:
- 高级后处理 (Post-Processing):
在检索与生成之间,Llama-Index 允许开发者插入“节点后处理器(Node Postprocessors)”。这使得我们可以轻松实现:
- 重排序(Re-ranking): 集成 Cohere Rerank 或 BGE Rerank 模型,对检索到的 Top-K 结果进行二次精排,大幅提升相关性。
- 元数据过滤(Metadata Filtering): 基于时间、作者或文件类型过滤节点。
- 相似度截断(Similarity Cutoff): 自动丢弃相似度低于阈值的噪声数据。
- 灵活的响应合成 (Response Synthesis):
针对不同的业务场景,提供了多种内置的合成策略,而非单一的拼接:
- Refine(精炼模式): 线性遍历检索结果,逐步迭代优化答案,适合生成详尽的回答。
- Tree Summarize(树状总结): 自底向上构建摘要树,适合处理海量上下文的归纳总结任务。
- Compact(紧凑模式): 最大化利用 Context Window,平衡速度与成本。
2.3 庞大的数据生态:LlamaHub
Llama-Index 拥有目前 AI 社区中最丰富的数据连接器生态——LlamaHub。它解决了 RAG 开发中“最后一公里”的数据获取难题,让开发者无需自行编写爬虫或解析脚本。
- 海量数据加载器 (Data Loaders):
社区维护了超过 400 种数据加载器,覆盖了几乎所有主流数据源:
- 文件类: PDF, Markdown, PowerPoint, Word, Excel, CSV 等。
- SaaS 类: Notion, Slack, Discord, Jira, Salesforce, Google Docs 等。
- 网络类: Wikipedia, YouTube Transcripts, Web Page Reader 等。
- 数据库类: PostgreSQL, MongoDB, SQL Database 等。
- 多模态原生支持:
除了文本,LlamaHub 还提供了针对图像、音频和视频的加载器,支持构建图文混排的 RAG 系统,能够将多模态信息统一映射到向量空间。
2.4 企业级云服务:LlamaCloud
为了满足企业对高性能和免运维的需求,Llama-Index 团队还推出了配套的商业化云服务,进一步补全了开源框架的拼图:
- LlamaParse:
这是目前业界最先进的文档解析服务之一。专为解决 RAG 中的“复杂文档处理”难题而生,能够精准识别和解析 PDF 中的复杂表格、图表、数学公式以及多栏排版,将其转化为 LLM 易于理解的 Markdown 格式,从源头上提升了 RAG 的检索质量。 - Managed Indexing:
提供“检索即服务(Retrieval-as-a-Service)”,开发者无需自行维护向量数据库和索引管道,通过 API 即可直接上传文件并进行高效检索,大幅降低了企业级 RAG 的落地门槛。
3.Llama-Index RAG 黑科技
在 Llama-Index 的工具箱中,隐藏着几种能够显著提升 RAG 性能的“杀手级”特性。这些技术突破了传统 RAG 的线性流程,引入了逻辑推理、代码执行和多模态能力。
3.1 Small-to-Big Retrieval(小索引,大窗口)
- 痛点: 传统 RAG 直接对切片进行检索。切片太小,上下文缺失(LLM 看不懂);切片太大,包含过多噪声(检索不准)。
- 黑科技原理:“索引粒度”与“生成粒度”分离。系统将文档切分成极小的句子(Sentence)进行精准检索,但在提交给 LLM 时,自动将该句子替换为它周围更大的文本窗口(Window)。既保证了检索的高精度(High Precision),又提供了生成所需的丰富上下文(Rich Context)。
- 伪代码示例:
# 1. 使用窗口解析器,记录每句话的“上下文窗口”node_parser = SentenceWindowNodeParser.from_defaults( window_size=3 # 检索到一句话,同时带出前后各3句话)# 2. 在查询时,启用元数据替换功能query_engine = index.as_query_engine( node_postprocessors=[MetadataReplacementPostProcessor(...)])
3.2 Pandas Query Engine(结构化数据RAG)
- 痛点: 用户问:“计算 Q3 销售额的总和。” 传统 RAG 会检索出一堆包含数字的文本,让 LLM 自己算,极易出现数学幻觉(Math Hallucination)。
- 黑科技原理:将“检索任务”转化为“编程任务”。Llama-Index 不去搜索文本,而是让 LLM 编写一段 Pandas Python 代码,并在本地沙箱中执行。这相当于让 RAG 拥有了类似 ChatGPT Code Interpreter 的能力,实现 100% 准确的数据计算。
- 伪代码示例:
import pandas as pdfrom llama_index.experimental import PandasQueryEnginedf = pd.read_excel("sales_data.xlsx")# 引擎会自动生成代码:df[df['quarter']=='Q3']['sales'].sum() 并执行query_engine = PandasQueryEngine(df=df, verbose=True)response = query_engine.query("Q3 的销售总额是多少?")
3.3 Router Query Engine(智能路由分诊)
- 痛点: 系统中既有非结构化的 PDF(适合语义检索),又有结构化的 SQL 数据库(适合精确查询)。用户提问时,系统不知道该查哪一个。
- 黑科技原理:RAG 的“前置大脑”。Router 是一个轻量级的分类器(Agent),它会先分析用户意图,然后动态决定将问题路由给“向量检索引擎”还是“SQL 查询引擎”,甚至同时查询两者。
- 伪代码示例:
from llama_index.core.tools import QueryEngineToolfrom llama_index.core.query_engine import RouterQueryEngine# 定义两个工具:一个查文档,一个查摘要summary_tool = QueryEngineTool.from_defaults(query_engine=summary_engine, description="查摘要")vector_tool = QueryEngineTool.from_defaults(query_engine=vector_engine, description="查细节")# 智能路由:根据问题自动选择用哪个工具query_engine = RouterQueryEngine( selector=LLMSingleSelector.from_defaults(), query_engine_tools=[summary_tool, vector_tool])
3.4 Sub-Question Query Engine(多子问题查询)
- 痛点: 用户问:“对比 A 公司和 B 公司的营收增长率。” 这是一个多跳推理(Multi-hop)问题,单次检索往往只能搜到其中一家的数据,导致回答不全。
- 黑科技原理:分而治之(Divide and Conquer)。引擎会自动将这个复杂问题拆解为三个子问题:(1)查 A 公司营收;(2)查 B 公司营收;(3)对比结果。系统并发执行查询,最后汇总答案。
- 伪代码示例:
from llama_index.core.query_engine import SubQuestionQueryEngine# 引擎运行时会打印:# > Generated sub-question: What is the revenue of Company A?# > Generated sub-question: What is the revenue of Company B?query_engine = SubQuestionQueryEngine.from_defaults( query_engine_tools=tools)
3.5 Native Multimodal RAG(原生多模态检索)
- 痛点: PDF 中的架构图、流程图或产品照片被传统 OCR 忽略,导致关键信息丢失。
- 黑科技原理:CLIP 跨模态对齐。利用 CLIP 模型将文本和图像映射到同一个向量空间。无需 OCR 转文字,系统可以直接用“文字”检索到“图片”,并将图片直接喂给 GPT-4o 或 LLaVA 等多模态大模型进行理解。
- 伪代码示例:
from llama_index.core.indices import MultiModalVectorStoreIndex# 建立包含文本和图片的混合索引index = MultiModalVectorStoreIndex.from_documents(documents)# 检索结果包含 ImageNode,可直接展示图片或喂给视觉模型retriever = index.as_retriever(image_similarity_top_k=2)
三、Llama-Index快速上手指南
1.基本环境搭建与快速运行
课程开始之前,我们需要构建一个干净、独立的 Python 开发环境。Llama-Index 迭代速度极快,使用虚拟环境可以避免与您本地的其他项目产生依赖冲突。
1.1 创建 Python 虚拟环境
推荐使用 Conda 进行环境管理(也可以使用 Python 自带的 venv)。我们将创建一个名为 llama-index-demo 的环境,并指定 Python 版本为 3.10 或以上(Llama-Index 对新特性支持较好)。
- 打开终端(Terminal)或 Anaconda Prompt,执行以下命令:
# 1. 创建虚拟环境conda create -n llamaindex python=3.12 -y# 2. 激活虚拟环境conda activate llamaindex# 3.安装jupyter kernelconda install jupyterlabconda install ipykernelpython -m ipykernel install --user --name llamaindex --display-name "Python (llamaindex)"# 4.启动jupyterjupyter lab
1.2 安装 Llama-Index 核心库
自 v0.10.0 版本起,Llama-Index 采用了模块化架构。对于初学者,我们直接安装主包,它会自动包含核心组件(Core)以及常用的 OpenAI 适配器。
- 执行安装命令:
# 安装 Llama-Index 主包pip install llama-index -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装环境变量管理工具 (用于加载 .env 文件)pip install python-dotenv -i https://pypi.tuna.tsinghua.edu.cn/simple
是一个包含以下软件包的入门级捆绑包
- llama-index-core
- llama-index-llms-openai
- llama-index-embeddings-openai
- llama-index-readers-file
注意: llama-index-core已预先捆绑 NLTK 和 tiktoken 文件,以避免运行时下载和网络调用。
1.3 配置 OpenAI API Key
Llama-Index 默认使用 OpenAI 的 GPT-3.5-turbo 进行推理以及 text-embedding-ada-002 进行向量化。虽然框架支持更换任意模型,但在快速上手阶段,使用 OpenAI 是最稳定、调试最方便的选择。
为了安全起见,我们严禁将 API Key 直接硬编码在代码中。我们将采用业界标准的 .env 环境变量文件进行配置。
- 步骤 1: 在项目根目录下,创建一个名为 .env 的新文件(注意文件名前面有个点,且没有后缀名)。
- 步骤 2: 使用文本编辑器打开该文件,并写入您的 API Key:
# .env 文件内容示例OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxBASE_URL=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx

1.4 验证安装
import osfrom dotenv import load_dotenvimport llama_index.core
# 1. 加载环境变量load_dotenv()# 2. 检查 Llama-Index 版本print(f"Llama-Index Version: {llama_index.core.__version__}")
Llama-Index Version: 0.14.10
- 模型调用测试
from openai import OpenAIclient = OpenAI(base_url=os.getenv("BASE_URL"),api_key=os.getenv("OPENAI_API_KEY"),)# 查看模型列表model_list = client.models.list()
model_list.data
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









