



一、当GraphRAG遇到LPG,为何传统方法失灵?
当前GraphRAG研究存在明显偏见:90%的工作集中在RDF三元组图谱和SPARQL查询上,而**Labeled Property Graph(LPG)**这一更强大、更灵活的图模型却被严重忽视。LPG不仅支持节点和边的丰富属性,还允许动态schema,天生适合用Cypher查询——可这个组合在LLM时代几乎还是空白。

LPG的独特挑战
论文给出了严格的数学定义:LPG是一个有向多重图𝒢=(N,E,ρ,λ,σ),其中:
- 节点和边都带标签(λ函数)
- 每个实体都有属性键值对(σ函数)
- 支持复杂的多跳路径查询
这种灵活性也带来了三大痛点:
- Schema可变性:相比RDF的固定本体,LPG的schema更动态,LLM更容易"幻觉"出根本不存在的标签或属性
- 查询复杂性:Cypher需要处理关系方向、类型、属性过滤等多重约束,生成难度远超SPARQL
- 幻觉级联效应:一个错误的节点标签或属性名就会让查询返回空结果,且错误难以自动发现
二、七剑客协同作战,打造会"反思"的查询引擎
核心思想:用Agent军队替代单体LLM
图1:Multi-Agent GraphRAG工作流程状态图,展示了从查询生成到迭代优化的完整闭环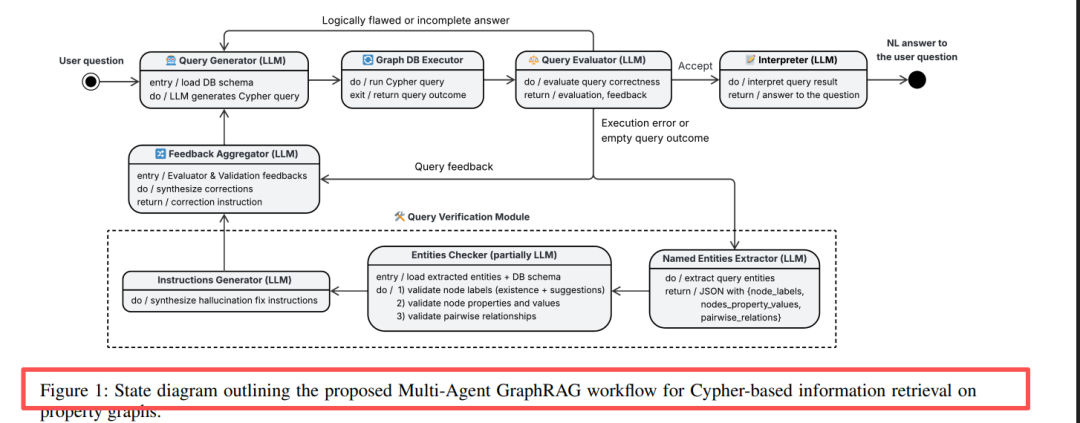
Multi-Agent GraphRAG的精髓在于模块化分工+迭代反馈。系统不是让单个LLM一次性生成完美查询,而是模拟人类工程师的调试过程:写查询→执行→观察错误→修正→再执行,直到正确为止。
整个系统由7个专业化Agent和1个执行器组成,形成精密的生产线:
| Agent角色 | 职责 | 核心价值 |
|---|---|---|
| Query Generator | 根据自然语言生成Cypher查询 | 初始查询生成+后续迭代优化 |
| Graph DB Executor | 在Memgraph中执行查询 | 连接真实数据库,获取执行结果或错误 |
| Query Evaluator | 评估查询语义正确性 | LLM-as-a-Judge,给出Accept/Incorrect/Error三级评分 |
| Named Entity Extractor | 提取查询中的实体(标签、属性值、关系) | 定位易幻觉部分 |
| Verification Module | 验证实体在数据库中的存在性 | 用辅助Cypher查询+Levenshtein相似度检测幻觉 |
| Instructions Generator | 生成修正指令 | 结合相似度匹配和LLM语义排序给出具体修改建议 |
| Feedback Aggregator | 整合多源反馈 | 合并语义错误和schema错误,形成统一修正策略 |
三、结论篇:工业级场景验证,准确率提升超10%
CypherBench benchmark全面胜出
在涵盖艺术、飞行事故、公司、地理、虚构人物5大领域的CypherBench数据集上,Multi-Agent GraphRAG展现了压倒性优势:
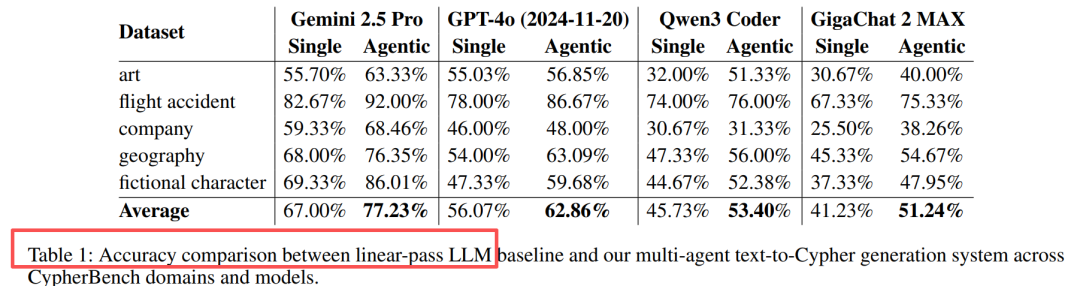
表1:单遍LLM vs 多智能体系统在CypherBench上的表现
关键数据:
- Gemini 2.5 Pro: 基线准确率 → 提升10.23%
- GPT-4o: 基线准确率 → 提升6.79%
- Qwen3 Coder: 基线准确率 → 提升7.67%
- GigaChat 2 MAX: 基线准确率 → 提升10.01%
平均来看,Agentic workflow比单遍生成高出7-10个百分点,这证明迭代修正的价值远超让模型多次独立尝试。更重要的是,这种提升在所有模型、所有领域一致出现,说明框架具有极强的通用性。
IFC建筑数据:从实验室到工地

Figure 2: IFC建筑数字孪生模型示例
最惊艳的验证来自**建筑信息模型(BIM)**领域。团队将IFC标准格式的建筑数据(Sample House模型)转换为LPG,测试10个工程实际问题:
| 问题示例 | Agentic系统表现 |
|---|---|
| “屋顶空间体积是多少?” | 返回76,465.52 m³并**主动标注"此值异常大"**,展现不确定性表达能力 |
| “入口大厅周长?” | 精确返回12.81m,优于基线方法 |
| “建筑地址?” | 正确提取"Westminster, London, UK"并提示"部分字段缺失" |
相比之前的GraphRAG方法,本系统正确回答了3个此前无法处理的复杂问题,特别是在处理数值异常、缺失字段等工程实际问题上表现出色。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









