



Transformer是一种深度学习架构,由Vaswani等人在2017年提出,完全依赖自注意力机制建模序列依赖关系。主要分为三类:纯编码器(如BERT,适合信息提取任务)、纯解码器(如GPT,适合生成任务)和编码器-解码器(如T5,适合序列到序列任务)。其核心组件包括自注意力层、前馈层和位置嵌入。Transformer彻底改变了序列数据处理方式,通过全局依赖捕捉和高度并行化提升了训练效率,为大规模预训练模型奠定了基础。
Transformer是一种在自然语言处理以及更广泛的序列建模任务中被广泛采用的深度学习架构,由Vaswani等人在2017年的论文《Attention is All You Need》[1]中首次提出。与以往的序列模型不同,Transformer最大的创新之处在于彻底摒弃了循环神经网络和卷积神经网络等传统结构,完全依赖一种被称为自注意力机制的方法来建模序列中不同位置之间的依赖关系。
Transformer基于编码器-解码器架构,该架构广泛用于机器翻译等任务中,即将一个单词序列从一种语言翻译成另一种语言。该架构由如图1所示的几个构建块组成。图1中展示了Transformer整体的编码器-解码器结构,各模块之间通过注意力机制相互作用,实现从输入到输出的转换[2]。
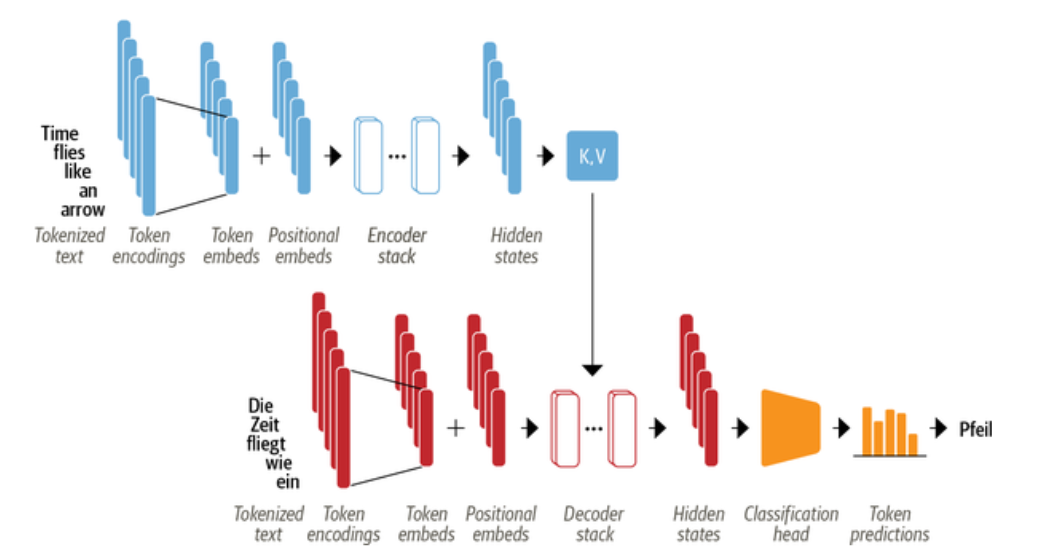
图1 Transformer的编码器-解码器架构
Transformer架构最初是为序列到序列的任务(如机器翻译)而设计的,但编码器和解码器模块很快就被抽出来单独形成模型。虽然Transformer模型已经有数百种不同的变体,但其中大部分属于“纯编码器”、“纯解码器”以及“编码器-解码器”三种类型之一。
一、纯编码器
这种架构通常被应用于提取信息的任务,例如新闻分类、情感分析、文档主题识别等,因为它能够利用上下文的双向信息生成精确的文本表示。BERT[3]及其变体,例如RoBERTa和DistilBERT,属于这类架构。此架构中为给定词元计算的表示取决于左侧(词元之前)和右侧(词元之后)上下文,这通常称为双向注意力。
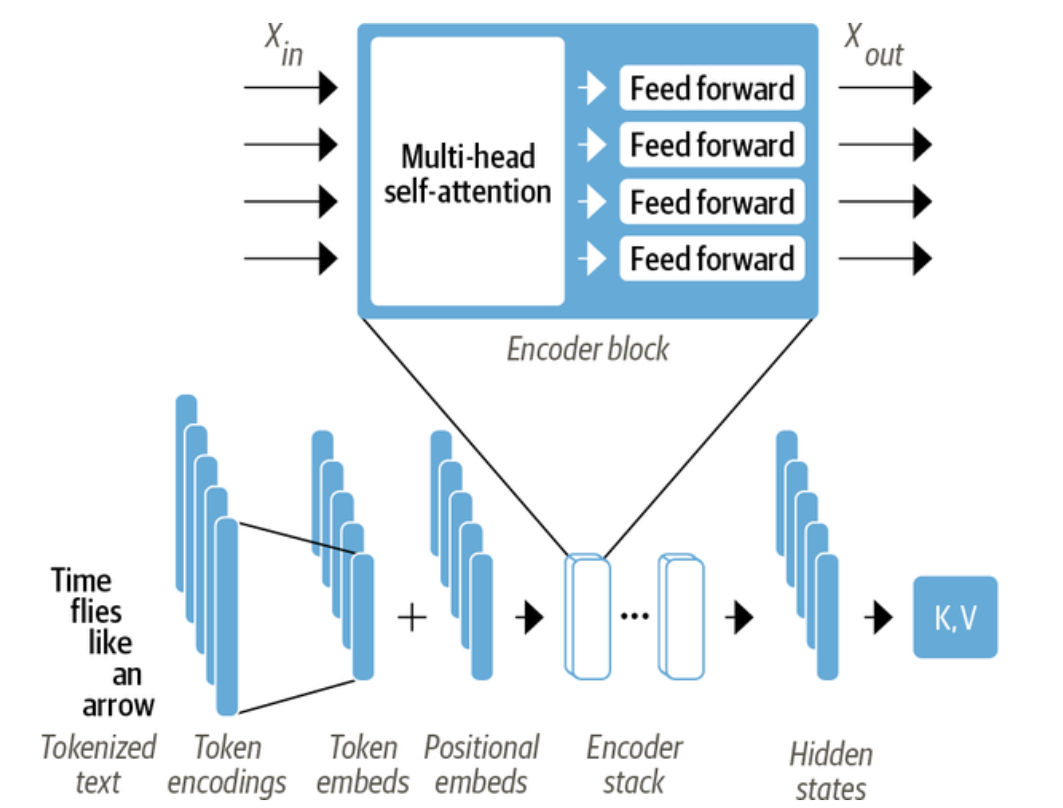
图2 编码器层放大图
Transformer的编码器由许多编码器层相互堆叠而成。如图2所示,每个编码器层接收一系列嵌入,然后通过多头自注意力层和全连接前馈层进行馈送处理。但要想真正理解Transformer的工作原理,还需要更深入地研究它的构建模块:
1. 自注意力层:注意力机制是一种神经网络为序列中的每个元素分配不同权重或“注意力”的机制。自注意力的主要思想是,不是使用固定的嵌入值来表示每个词元,而是使用整个序列来计算每个嵌入值的加权平均值。
2. 前馈层:编码器和解码器中的前馈子层仅是一个简单的两层全连接神经网络,但有一点小小的不同:它不会将整个嵌入序列处理为单个向量,而是独立处理每个嵌入。
3. 位置嵌入:位置编码是用一个按向量排列的位置相关模式来增强词元嵌入。如果该模式对于每个位置都是特定的,那么每个栈中的注意力头和前馈层可以学习将位置信息融合到它们的转换中。 举个例子,如果句子是“我 爱 自然语言处理”,第一个“我”和第二个词“爱”在位置编码上会有不同的数值模式,模型因此能够区分它们在句子中的顺序。
二、纯解码器
这类架构适合需要从头到尾生成内容的场景,例如自动写作、代码生成、诗歌创作等任务。针对像“谢谢你的午餐,我有一个……”这样的文本提示,这类模型将通过迭代预测最可能的下一个词来自动完成这个序列。GPT模型[4]家族属于这一类。在这种架构中,对于给定词元计算出来的表示仅依赖于左侧的上下文。这通常称为因果或自回归注意力。
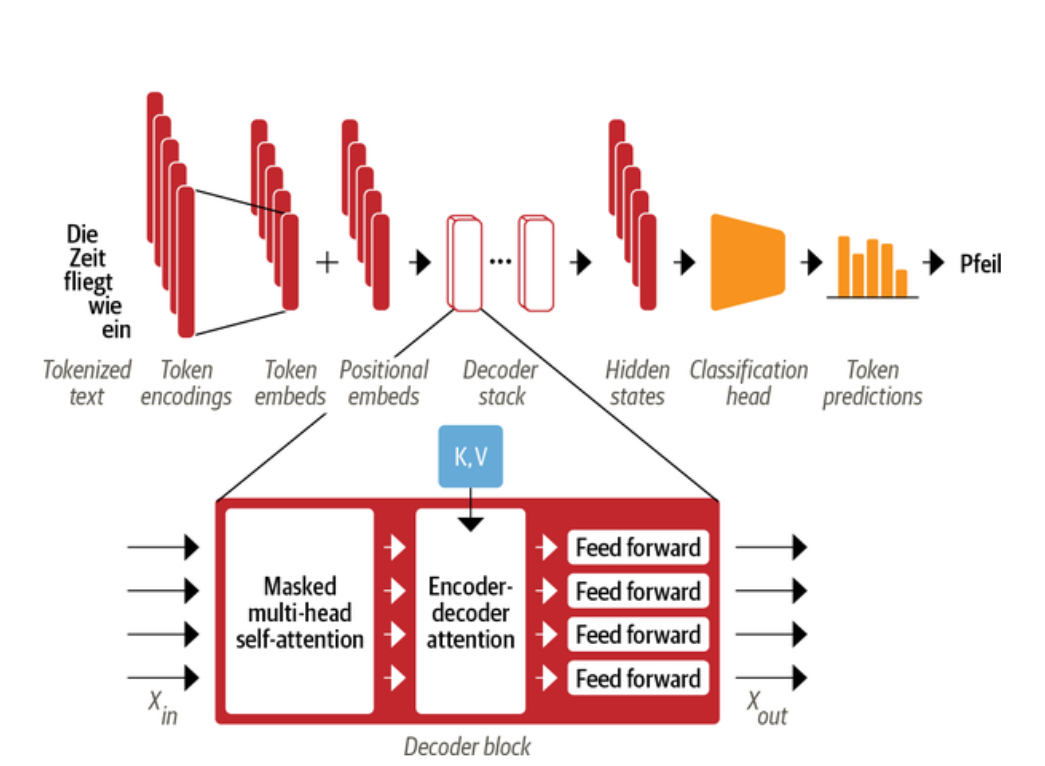
图3 Transformer解码器层放大图
解码器和编码器的主要区别在于解码器有两个注意力子层:
1. 掩码多头自注意力层:确保我们在每个时间步生成的词元只基于过去的输出和当前正在预测的词元。如果没有这样做,那么解码器将能够在训练时通过简单复制目标翻译来欺骗我们,导致训练失败。我们需要对输入进行掩码,以确保任务不是简单复制目标翻译。
2. 编码器-解码器注意力层:与自注意力层不同,编码器-解码器注意力中的key和query向量可能具有不同的长度。这是因为编码器和解码器输入通常涉及长度不同的序列。因此,此层中的注意力得分矩阵是矩形的,而不是正方形的。
三、编码器-解码器
这类模型用于对一个文本序列到另一个文本序列的复杂映射进行建模。它们适用于机器翻译和摘要任务。除了Transformer架构,它将编码器和解码器相结合,BART和T5模型[5]也属于这个类。
四、总结
总的来说,Transformer架构在诞生后的几年间,研究人员不断在不同规模、不同类型的数据集上进行探索,尝试设计新的预训练目标,并在结构上进行改进与优化。这些努力催生了数百种不同的Transformer变体,虽然它们在细节设计、训练方式和应用领域上各不相同,但从整体结构来看,依然可以归纳为三大类,如图4所示。
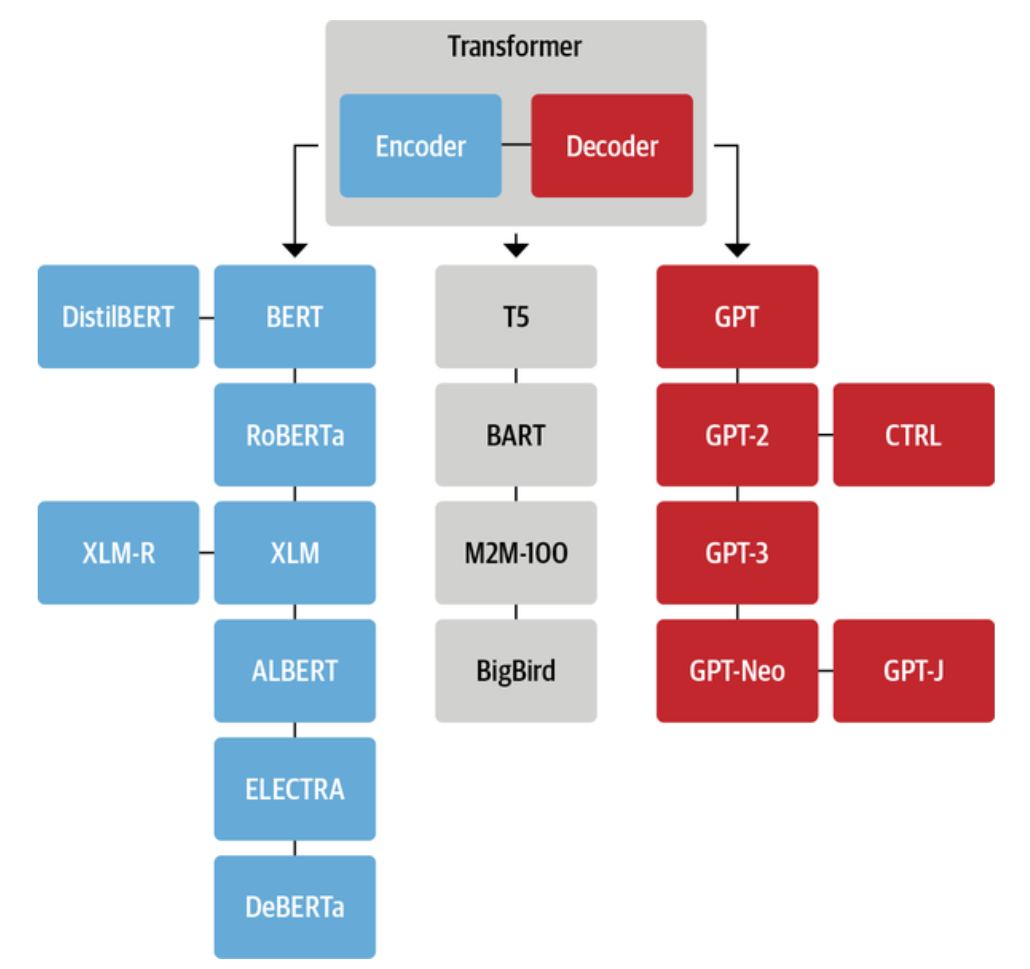
图4 Transformer最突出的架构及生命树
Transformer的出现彻底改变了深度学习对序列数据的处理方式。它以自注意力机制取代传统的循环和卷积结构,让模型能够在一次计算中捕捉全局依赖关系,并通过高度并行化显著提升训练与推理效率。这种设计不仅解决了长距离依赖难题,还为大规模预训练模型的发展奠定了基础,使NLP、计算机视觉、语音识别等领域都迎来了性能飞跃。在应用上,纯编码器适合信息提取类任务,如文本分类、情感分析;纯解码器专注生成式任务,如对话、内容创作;编码器-解码器则擅长翻译、摘要等序列到序列任务。未来,Transformer 的研究将聚焦于提升长序列处理效率、优化低资源场景表现,并探索与领域知识的深度融合,从而在更多实际应用中展现更强的价值与生命力。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Tunstall L, von Werra L, Wolf T. (叶伟民, 叶志远, 译.)Transformer自然语言处理实战[M]. 北京:机械工业出版社, 2024.
[3] Devlin J, Chang M W, Lee K, et al. Bert:Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019: 4171-4186.
[4] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[5] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









