



RAG(检索增强生成)是一种让大模型从专属资料库检索信息再生成回答的技术,区别于普通大模型的通用回答。它能解决企业客服、金融合规、知识管理等场景中的痛点,节省80%翻文档时间,减少错误。要实现精准回答,需做好数据清洗、合理切分文档、优化向量模型,并定期维护知识库。RAG调优的关键在于资料质量和规则设计,做好这三点,RAG系统就能持续高效运行。
很多人都在问:RAG 到底是什么? 为什么越来越多企业都在抢着用?今天就用大白话拆解清楚,还附上 3 个实操调优技巧,帮你把 RAG 的价值拉满!
一、先搞懂:RAG 到底是什么?
RAG,全称 Retrieval-Augmented Generation(检索增强生成),通俗点说,就是给大模型开了一场 “开卷考试”——它不只是靠自己的 “记忆”(训练数据)回答问题,还会先去你提前准备好的 “专属资料库” 里精准找答案,再结合大模型的理解,生成贴合需求的回复。
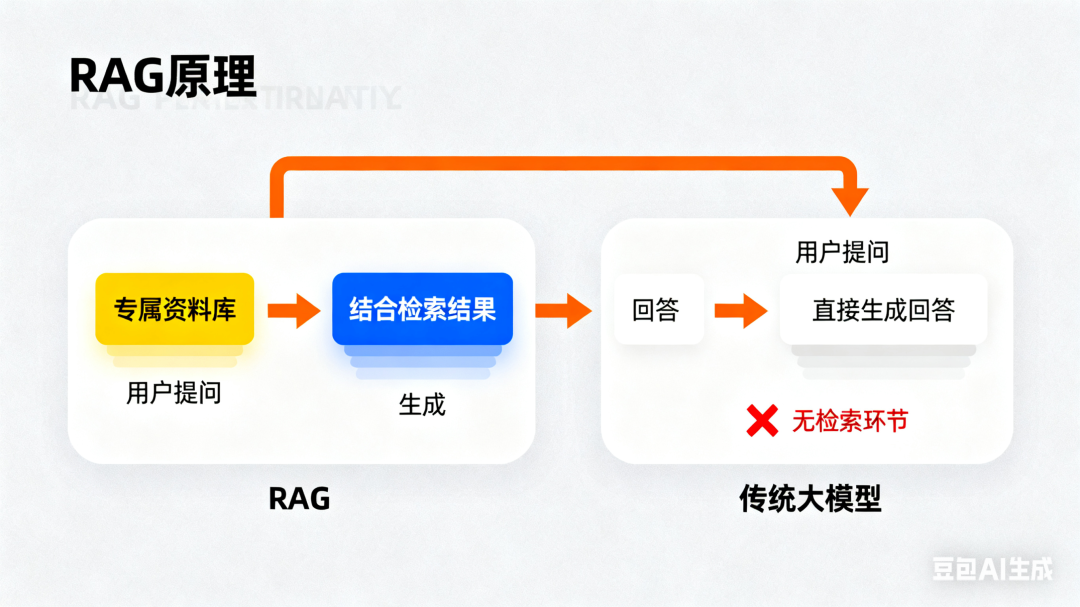
二、RAG vs 普通大模型(如 ChatGPT):区别在哪?
很多人会混淆:既然 ChatGPT 也能联网搜索,为什么还要用 RAG?核心差异就在于 “资料的专属权” 和 “回答的精准度”。
用表格对比更清晰:
| 对比维度 | 普通大模型(如 ChatGPT) | RAG(检索增强生成) |
|---|---|---|
| 数据来源 | 公开训练数据 + 联网通用信息 | 你的专属资料库(企业文档、内部 FAQ 等) |
| 回答针对性 | 通用化,难贴合具体业务场景 | 高度定制,紧扣你提供的资料内容 |
| 信息时效性 | 依赖联网,无法保证 “你的资料” 是最新的 | 资料库可实时更新,确保信息时效性 |
| 核心用途 | 日常问答、通用知识查询 | 企业客服、内部知识管理、合规查询等 |
简单说:你问 ChatGPT “公司产品的退款政策”,它只能给你通用的退款逻辑;但用 RAG,它会直接从你上传的《产品退款手册》里找答案,精准度拉满。
三、RAG 能帮哪些行业提效?3 个真实案例
现在很多行业都在靠 RAG 解决 “翻文档慢、回答不准” 的痛点,看看这些典型场景:
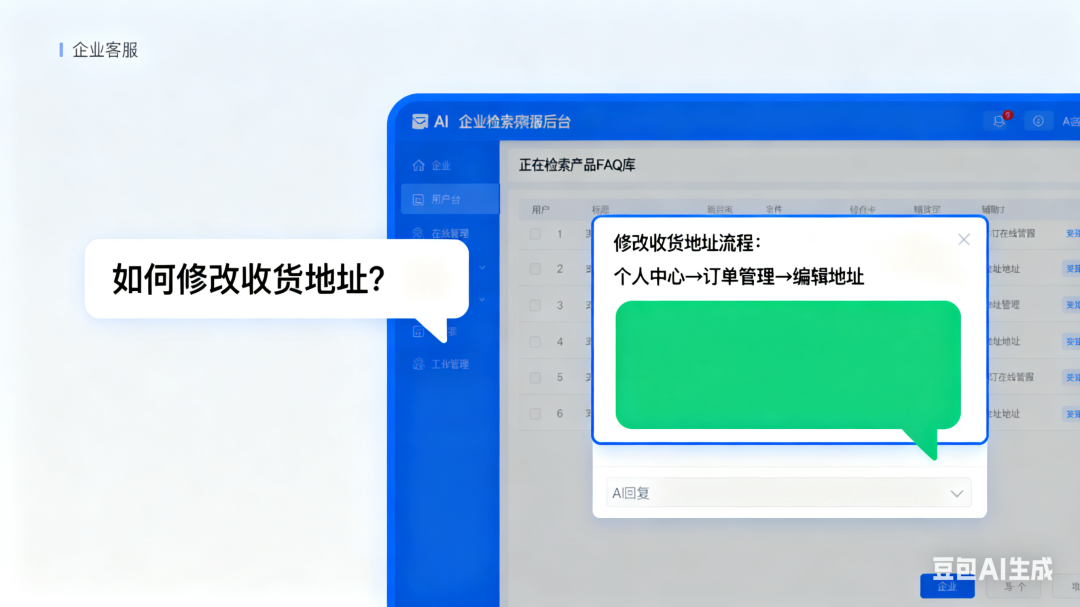
1. 企业客服:减少 80% 重复劳动
像字节跳动、阿里巴巴等企业,都在探索用 RAG 优化在线客服:
-
把产品手册、常见问题(FAQ)、售后规则等资料录入 RAG 知识库;
-
用户咨询 “如何修改收货地址”“会员积分怎么用” 时,AI 能 1 秒从资料库找答案,不用人工反复复制粘贴。
效果:人工客服从 “重复答疑” 中解放,专注处理复杂投诉。
2. 金融与法律合规:10 分钟搞定 1 小时的查阅量
金融行业最头疼 “查法规、对合规”,摩根大通(J.P. Morgan) 曾尝试用 RAG 处理这类需求:
-
把监管政策、合规手册、合同模板等资料整理成知识库;
-
员工需要确认 “某业务是否符合新规” 时,AI 能快速定位关键条款,还能标注出处。
效果:原本 1 小时的查阅工作,现在 10 分钟就能完成

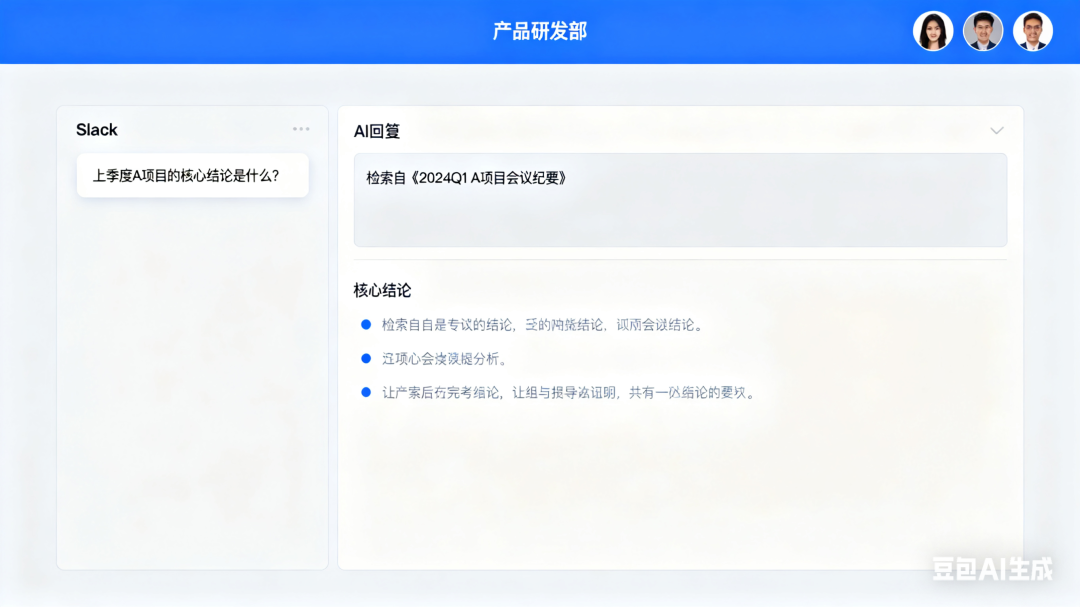
3. 教育与知识管理:团队知识 “随用随取”
像Notion AI、Slack GPT 这类工具,就引入了类似 RAG 的技术:
-
把团队的会议纪要、项目文档、笔记等内容存入知识库;
-
员工想知道 “上季度项目的核心结论” 时,不用翻聊天记录或文件夹,AI 直接检索生成总结。
效果:新人快速上手,老员工不用反复 “被提问”。
3. 教育与知识管理:团队知识 “随用随取”
像Notion AI、Slack GPT 这类工具,就引入了类似 RAG 的技术:
-
把团队的会议纪要、项目文档、笔记等内容存入知识库;
-
员工想知道 “上季度项目的核心结论” 时,不用翻聊天记录或文件夹,AI 直接检索生成总结。
效果:新人快速上手,老员工不用反复 “被提问”。
四、RAG 的核心好处:省人、省时、少出错
总结下来,RAG 最直接的价值就是 ——把人从 “翻文档” 的重复劳动中解放出来:
-
省人力:70%~80% 的基础咨询、资料查阅工作,AI 能自动完成;
-
省时间:原本几小时的找资料时间,缩短到几秒 / 几分钟;
-
少出错:基于固定资料库回答,避免 “凭记忆回答” 的偏差,还能标注出处,方便验证。
五、为什么有人的 RAG 答非所问?3 个调优技巧
很多人反馈:“同样是做 RAG,别人的 AI 回答很准,我的却经常跑偏?”
其实 RAG 就像一支 “开卷考试的笔”—— 能不能写好,关键看你喂进去的资料和规则。分享 3 个实用技巧,帮你解决 90% 的问题:
技巧 1:提升 “召回精度”—— 让 AI 找对资料
“召回” 就是 AI 从资料库找信息的过程,找错了资料,回答自然不准。做好这 3 点:
- 数据清洗
去掉重复、过时、无关的资料(比如 2020 年的旧政策、与业务无关的测试文档);
2. 合理切分
别把 100 页的长文档直接塞进去!按 “章节”“问题” 拆分(比如把《售后手册》拆成 “退款”“换货”“维修” 3 个模块),更利于精准匹配;
3. Embedding 优化
别只用默认的向量模型!如果是法律、医疗类专业资料,试试专门的领域向量模型(如 LegalBERT),匹配精度会更高。

六、小结:RAG 调优不是玄学,而是系统工程
想让 RAG 的回答准、稳、专业,核心就是做好这 3 个环节:
- 数据干净→召回准确
别让杂乱的资料拖后腿;
2. 知识库健康→回答稳定
定期 “体检”,避免信息过时、冲突;
3. Prompt 设计好→输出专业
让 AI 按你的规则 “好好说话”。
把这 3 步做到位,你的 RAG 就能从 “偶尔靠谱” 变成 “持续好用”,真正帮你提效!
3 句话总结今天的干货:
① RAG 准不准,关键看 “资料 + 规则”;
② 3 个调优技巧:清数据、检知识库、好 Prompt;
③ 用对 RAG,能省 80% 翻文档时间。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】

















 2039
2039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









