




 本文介绍了一种基于预训练视觉-语言模型的新型框架BIKE,它在视频识别中探索双向知识。通过视频属性关联和概念发现,提升视频识别性能,并展示了时间显著性和属性互补性的效果。
本文介绍了一种基于预训练视觉-语言模型的新型框架BIKE,它在视频识别中探索双向知识。通过视频属性关联和概念发现,提升视频识别性能,并展示了时间显著性和属性互补性的效果。
**基于预训练视觉-语言模型的双向跨模态知识挖掘视频识别**
前由
在大规模图像-文本对上预训练的视觉语言模型(Vision-language models (VLMs))在各种视觉任务上表现出令人印象深刻的可移植性。从这种强大的VLM中传输知识是构建有效视频识别模型的一个有前途的方向。然而,目前在这一领域的探索仍然有限。我们认为,预先训练的VLM的最大价值在于建立视觉和文本域之间的桥梁。
贡献点
1.我们提出了一个名为BIKE的新框架,该框架从预训练的视频识别视觉语言模型中探索双向知识。
2.在视频到文本的方向,我们引入视频属性关联机制,以产生额外的属性互补视频识别。
3.在文本到视频的方向,我们引入视频概念发现机制,以产生时间显着性,这是用来产生增强的视频识别的紧凑的视频表示。
框架
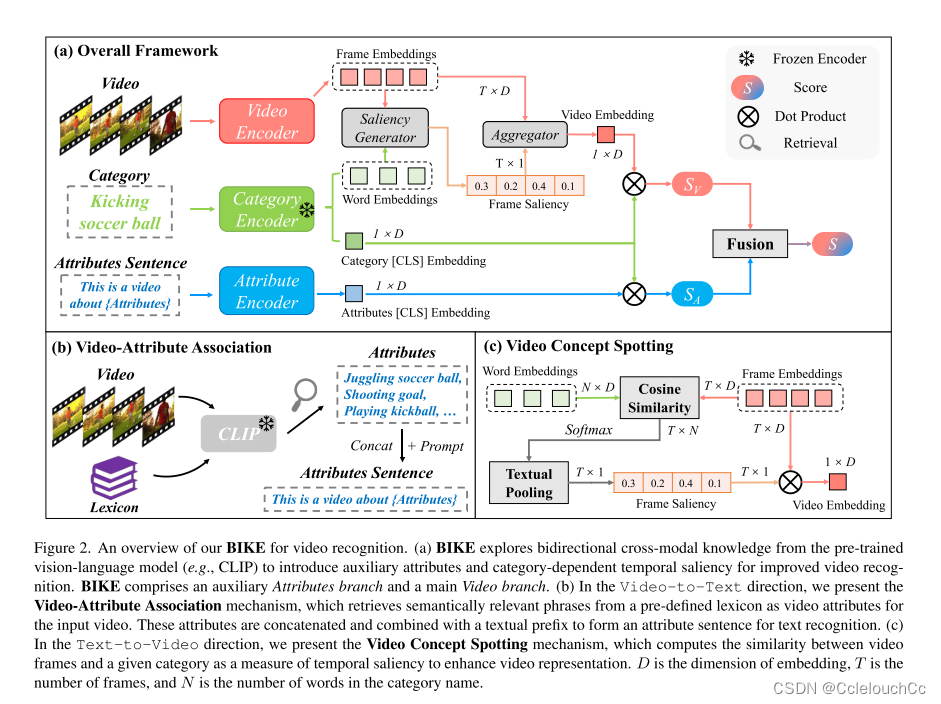
N:词的长度
D:维度
T:视频长度
(c)图展示了具体如何进行相似度进行得到的S(v):
词向量是N x D的,视频向量是T x D的,这也可以理解,因为踢足球就三个字,但是踢足球这个视频肯定不止三帧。二者经过转置相乘后,得到T x N维的向量,这时每一帧有N维,再将每一帧的N维进行Textual Pooling(实际上就是平均池化),得到T x 1的向量,这时每一帧都是一维的且有相似性分数,但是我们希望的是这整个视频对应这个词,因此我们需要将视频帧也进行压缩,就有了Frame Embeddings与Frame Saliency转置相乘得到了只有长度为1但维数是D维的向量,接下来消除D维即可。
(b)图展示了视频属性关联机制,以产生额外的属性互补视频识别
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2040
2040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









