



Hierarchical Vector Quantization for Unsupervised Action Segmentation
1.题目理解
题目涉及了向量量化:向量量化(Vector Quantization, VQ) 是一种将连续向量映射到有限离散码本(codebook)的方法,具有代表性的模型是VQ-VAE,由三部分组成:编码器-向量量化和码本-解码器。编码器一般是卷积神经网络映射出的高维(连续)特征,然后再把高维特征映射到码本最近的低维的码字中,让码字代表高维特征,输入到解码器里,再重建出特征。损失函数一般是均方损失+码本损失+承诺损失。

(向量量化)离散化的核心优势:
(1) 更强的语义表达能力:
离散码字 = 离散语义单元
每个码字可以对应一个具体的语义概念(如“猫耳”“奔跑动作”),而连续空间无法直接表达这种“原子级”语义。
例子:在图像生成中,离散码本可以明确区分“猫”和“狗”,而连续空间可能混淆两者。
2.提出背景
同一类别内时间片段间的大范围变化问题:即使属于同一动作类别,不同视频中的动作片段在执行方式、持续时间、外观等方面可能存在显著差异。例如:同一动作在不同环境中进行时,外观特征(如光线、背景)也会发生变化。无监督动作分割的原理是对视频帧做聚类,但是因为同一类别内时间片段间的大范围变化问题,会导致本应该属于一类的帧被分配给不同类。
因此本文提出了方法:层次聚类来代替原来的K-means聚类,因为本应该属于一类的帧被分配给不同类,这样的话再第一次聚类的基础上再进行一次聚类,即层次聚类。
3.主要贡献
1.本文提出基于端到端的无监督时间动作分割方法.层次化方法能够捕捉动作聚类的可变性,并且在性能上大大优于非层次化变体。
2.我们引入了一种新的度量的基础上的JensenShannon距离的预测段长度的偏差进行评估。
3.我们的方法在召回率和F1分数方面实现了无监督时间动作分割的最新结果,并且偏差较小。
4.框架
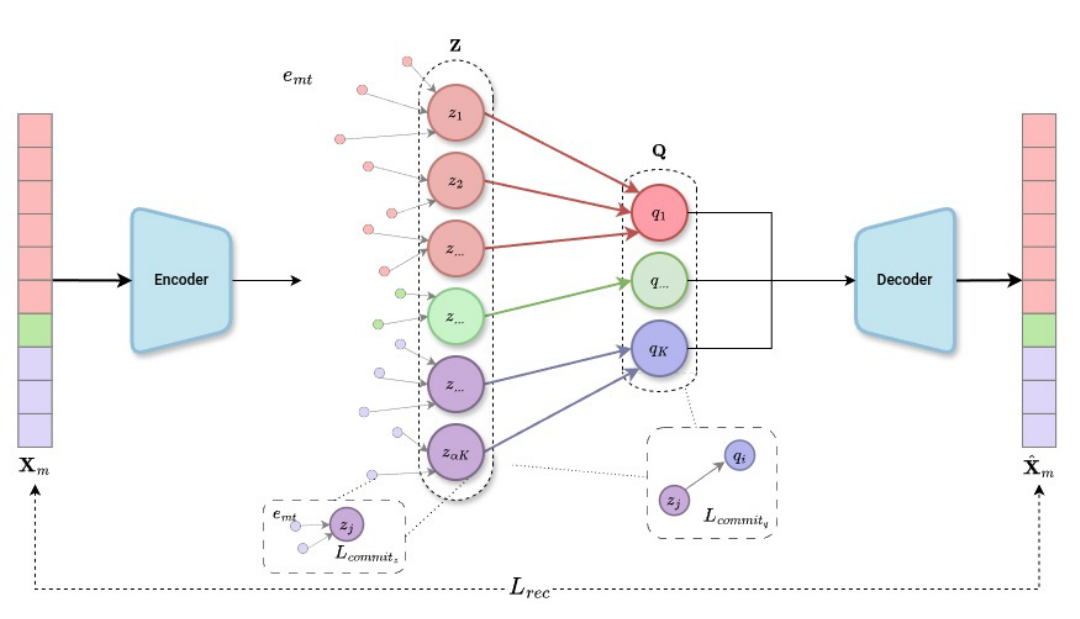
1. 编码器:
编码器将视频帧作为输入,并将其编码成嵌入向量。编码器使用轻量级的 MS-TCN 结构,包含两个阶段,每个阶段包含10层。
每个阶段都包含时间卷积层,卷积核大小为3,步长为1,膨胀因子逐层翻倍。编码器输出的嵌入向量包含了视频帧的时空特征。
2. 第一层向量量化:
第一层向量量化将编码器输出的嵌入向量分配到第一层码本中的原型向量上(实际上就是K-means:随机初始化聚类中心。即初始化码本,然后K-means不断更新)。第一层码本包含了 αK 个原型向量(聚类中心),其中 α 是超参数,数值为2,意义是第一层聚类中心个数是第二层的α倍;K 是动作类别数。每个原型向量代表一个子动作的聚类中心,第一层有αK 个,第二层是K个。第一层向量量化的目的是将动作片段分割成更精细的子动作,从而更好地捕捉同一类别内动作片段的内在变化。公式如下:
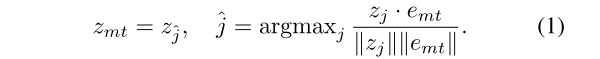
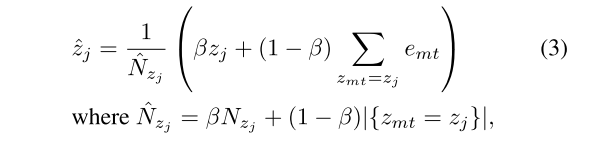
公式1是算每一帧和每个聚类中心的最大余弦相似度,从而确定哪一帧属于哪个聚类中心;
公式3是动态稳定更新聚类中心,在更新聚类中心时,不仅考虑聚类中心所有样本,还需要着重考虑原始聚类中心。以下图为例:若是不考虑原始聚类中心,则更新的会特别快。

3. 第二层向量量化:
第二层向量量化将第一层向量量化输出的嵌入向量分配到第二层码本中的原型向量上。第二层码本包含了 K 个原型向量,每个原型向量代表一个动作的聚类中心。第二层向量量化的目的是将子动作聚类成更粗粒度的动作,从而对子动作的内在变化具有一定的鲁棒性。公式如下:
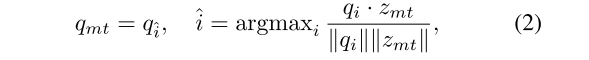
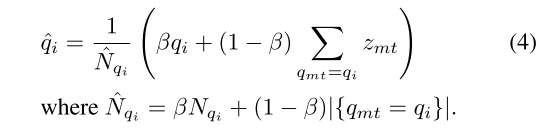
公式解释和第一层量化一样,不同仅仅是第一层输入的是视频帧,第二层的输入是第一层聚出来的簇
4. 解码器:
解码器将第二层向量量化输出的嵌入向量作为输入,并尝试重建原始视频帧。解码器使用与编码器相同的 MS-TCN 结构,但最后一个阶段被移除。解码器的目标是生成与原始视频帧尽可能接近的重建帧。
5. 损失函数:
5.1均方损失:重建损失函数使用均方误差 (MSE) 来计算差异,用于衡量解码器重建帧与原始视频帧之间的差异。
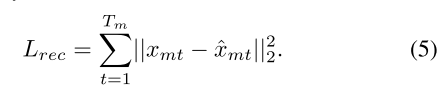
5.2第一层向量量化承诺函数:如果没有承诺损失,编码器可能生成的视频帧特征故意远离所有聚类中心(比如在两个聚类中心中间),最小化承诺损失则强制视频帧特征尽可能靠近某个聚类中心,确保量化操作有效。
5.3第二层向量量化承诺函数:和第一层类似。
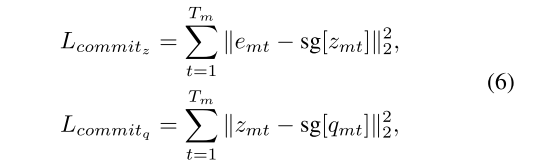
6. 推理过程:
在推理过程中,模型使用编码器和两个层次的向量量化来预测每个视频帧的动作类别。
模型还使用 FIFA 解码器来平滑预测结果,并生成最终的动作分割结果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









