




 这篇教程介绍了PyTorch的环境配置,包括Anaconda的安装、PyCharm编辑器的使用以及Jupyter Notebook的安装。接着讲解了Python中的常用工具函数,并展示了如何创建自定义的DataSet类来处理图像数据。还探讨了PyTorch中的Transforms,如Resize、ToTensor和Normalize等,以及Tensorboard的使用,用于训练结果的可视化。此外,文章还提供了代码示例,帮助理解每个步骤。
这篇教程介绍了PyTorch的环境配置,包括Anaconda的安装、PyCharm编辑器的使用以及Jupyter Notebook的安装。接着讲解了Python中的常用工具函数,并展示了如何创建自定义的DataSet类来处理图像数据。还探讨了PyTorch中的Transforms,如Resize、ToTensor和Normalize等,以及Tensorboard的使用,用于训练结果的可视化。此外,文章还提供了代码示例,帮助理解每个步骤。
来源:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
一、环境配置
- 安装anaconda:集成各种package的软件
安装Anacodna3.5.2 清华大学镜像 - 创建环境
在Anaconda Prompt里面:
conda create -n pytorch python=3.6 #创建一个含有Python包的环境,名字叫pytorch
conda activate pytorch#进入这个环境
pip list #列出在这个环境中已经安装的package

- 安装CPU版本的pytorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch

- PyCharm编辑器
创建pycharm项目,导入之前创建的pytroch环境,在Python interpreter里面选择conda environment ,选择之前anaconda的安装路径

- Jupyter安装
在命令行界面,进入pytorch环境
conda install nb_conda
jupyter notebook
二、Python学习中的两大法宝函数
import torch
dir(torch)
dir(torch.cuda) #获取这个工具箱里的工具目录
help(torch.cuda.is_available) #获取函数的作用,要去掉括号
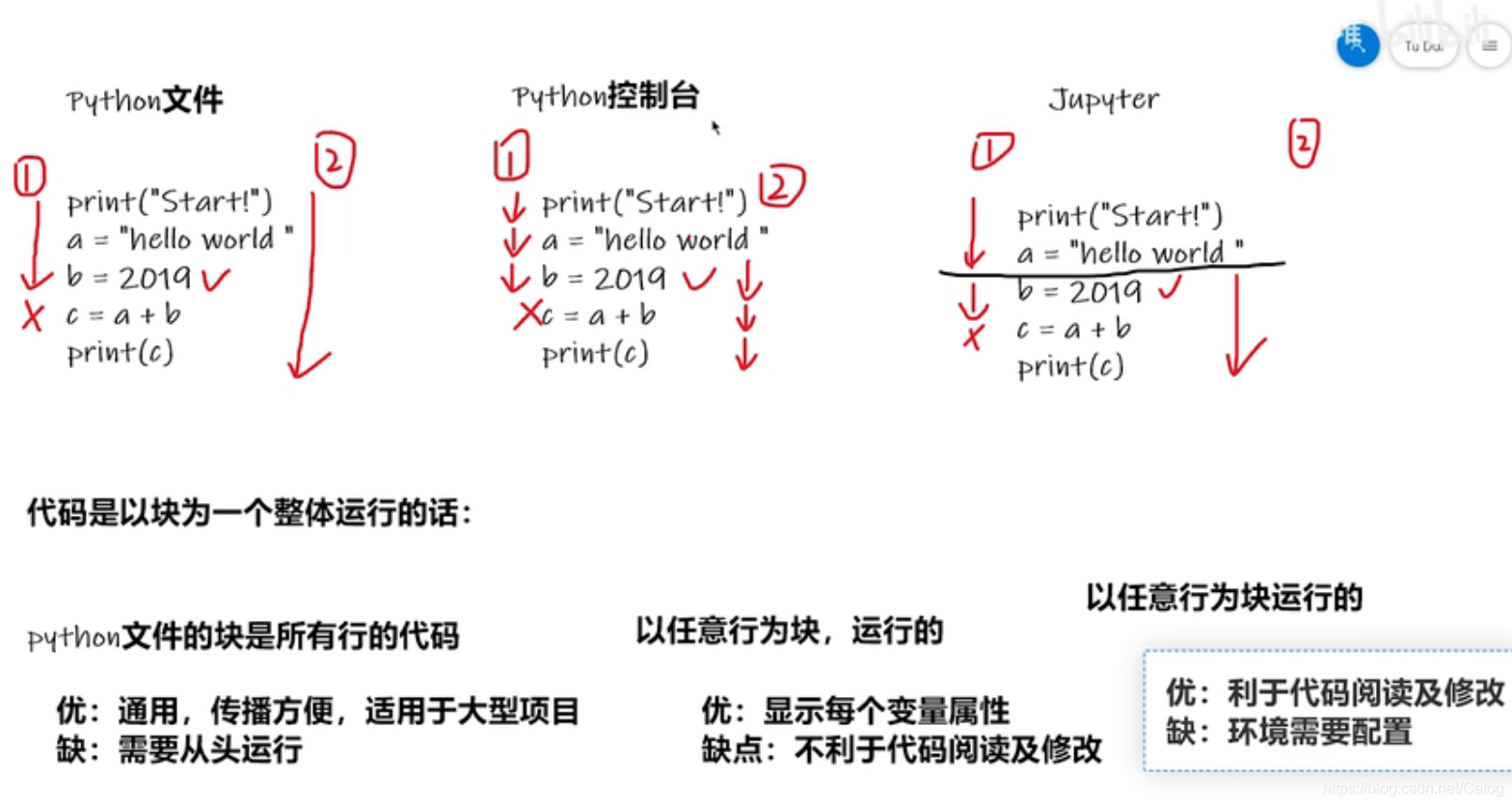
三、PyCharm及Jupyter使用及对比
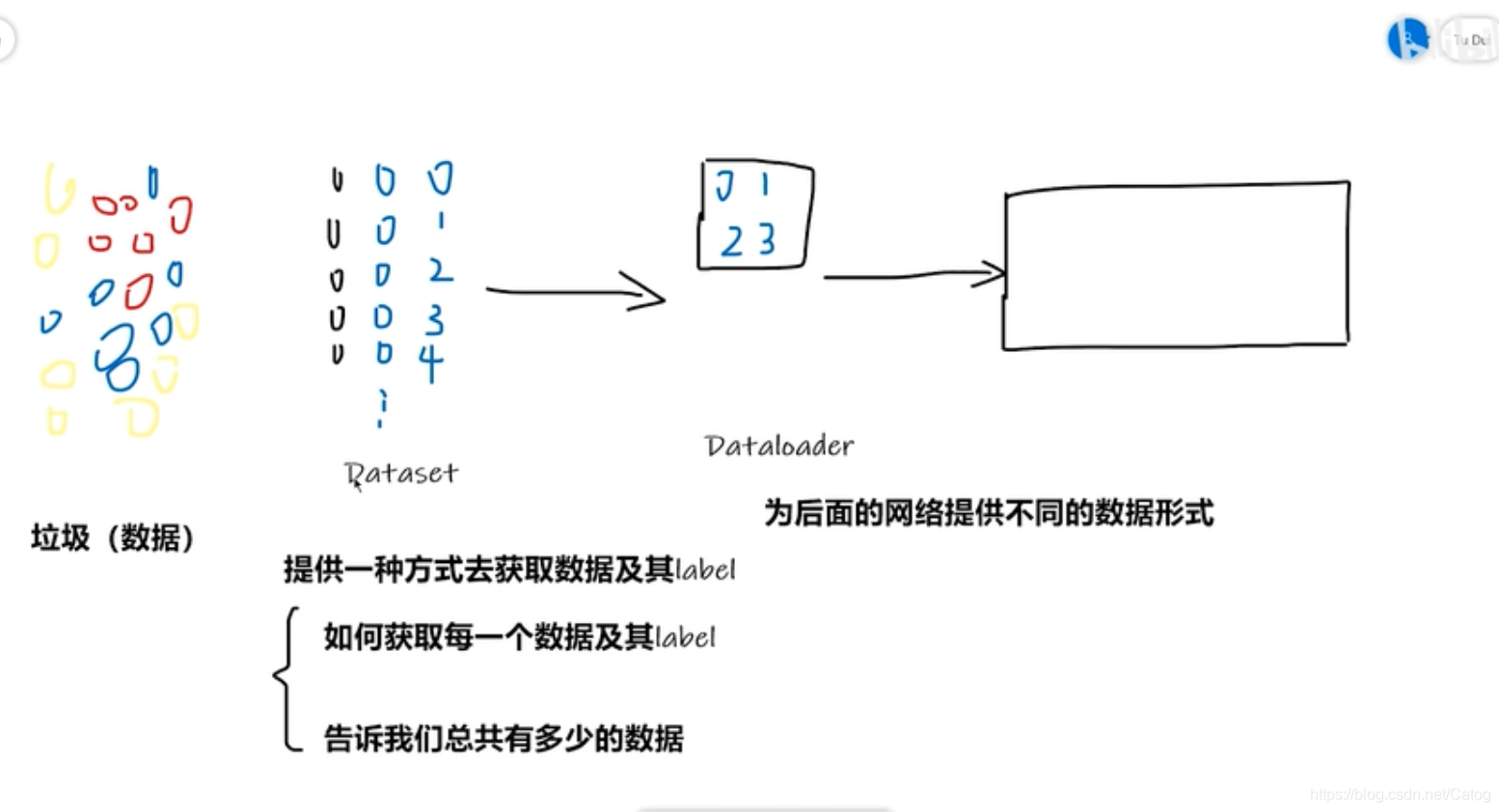
四、 PyTorch加载数据初认识
4.1 数据集的形式:
- 文件夹的名称对应label;
- 图片一个文件夹,label在另一个文件夹,每张图片对一个txt文件,txt里储存着图片里物体的位置和信息;

- 用label来命名图片
4.2 DataSet类代码实践
- DataSet类 所有的数据类必须是dataset类的子类,必须重写__getitem__,以获取每个数据集对应的label。
同时可以选择性地重写__len__,返回数据的长度 - 读取图片
from PIL import Image
img_path="E:\\PycharmProjects\\dataset\\hymenoptera_data\\train\\ants\\0013035.jpg"
img=Image.open(img_path)
img.size
img.show()
- 获取图片文件名列表
import os
dir_path="dataset/hymenoptera_data/train/ants"
img_name_list=os.listdir(dir_path)
img_name_list[0]
- 写DataSet类
#从torch大的工具包里有一个常用的工具区utils,里面的data区
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):#定义一个自己的类,继承与Dataset
def __init__(self,root_dir,label_dir): #初始化类,创建类实例的时候运行的函数,一般写类的全局变量
self.root_dir=root_dir #函数的变量是不能直接传递的,而通过self这个全局的结构体,是可以传递的,定义根目录
self.label_dir=label_dir #定义label目录
self.path=os.path.join(root_dir,label_dir) #得到label下的路径
self.name_list=os.listdir(self.path) #得到这个路径下所有文件名字的列表
def __getitem__(self, idx):
img_name=self.name_list[idx] #通过名字列表获取单张图片的名字
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) #单张图片的路径
img=Image.open(img_item_path)
label=self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
- 生成数据集
root_dir="dataset/hymenoptera_data/train"
ants_label_dir="ants"
bees_label_dir="bees"
ants_dataset=MyData(root_dir,ants_label_dir)
bees_dataset=MyData(root_dir,bees_label_dir)
img,label=ants_dataset[0]
img.show()
tran_dataset=ants_dataset+bees_dataset #把两个数据集进行拼接
五、Tensorboard的使用
- tensorboard是一个训练结果可视化的工具,而suammarywriter是把信息写到日志文件中,日志文件可以被Tensorboard解析
- 创建summarywriter的实例,写入日志文件
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
tag (string)#标题
scalar_value (float or string/blobname)#y值
global_step (int)#x值的步数
- 用pycharm的终端安装tensorboard,在事文件夹目录打开日志文件,指定输出的窗口是6007
pip install tensorboard
tensorboard --logdir==logs --port=6007

- 图像写入日志
def add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats='CHW'):
#写入图像到summary
tag (string): 标题
img_tensor (torch.Tensor, numpy.array, or string/blobname): 图像类型
global_step (int): 训练的第几步
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs") #创建一个实例
#创建一个写图像的的日志文件
imagepath="dataset/hymenoptera_data/train/ants/0013035.jpg"
img_pil=Image.open(imagepath)
img_array=np.array(img_pil)#文件格式由原本PIL转成ndarray
print(type(img_pil))
print(type(img_array))
print(img_array.shape)#图片格式是HWC,但添加图片函数默认图片格式是CHW
writer.add_image("train",img_array,2,dataformats="HWC")#标题,图片,第几次,图片格式(宽度,高度,通道)
writer.close()
六、Transforms
6.1 transform简介
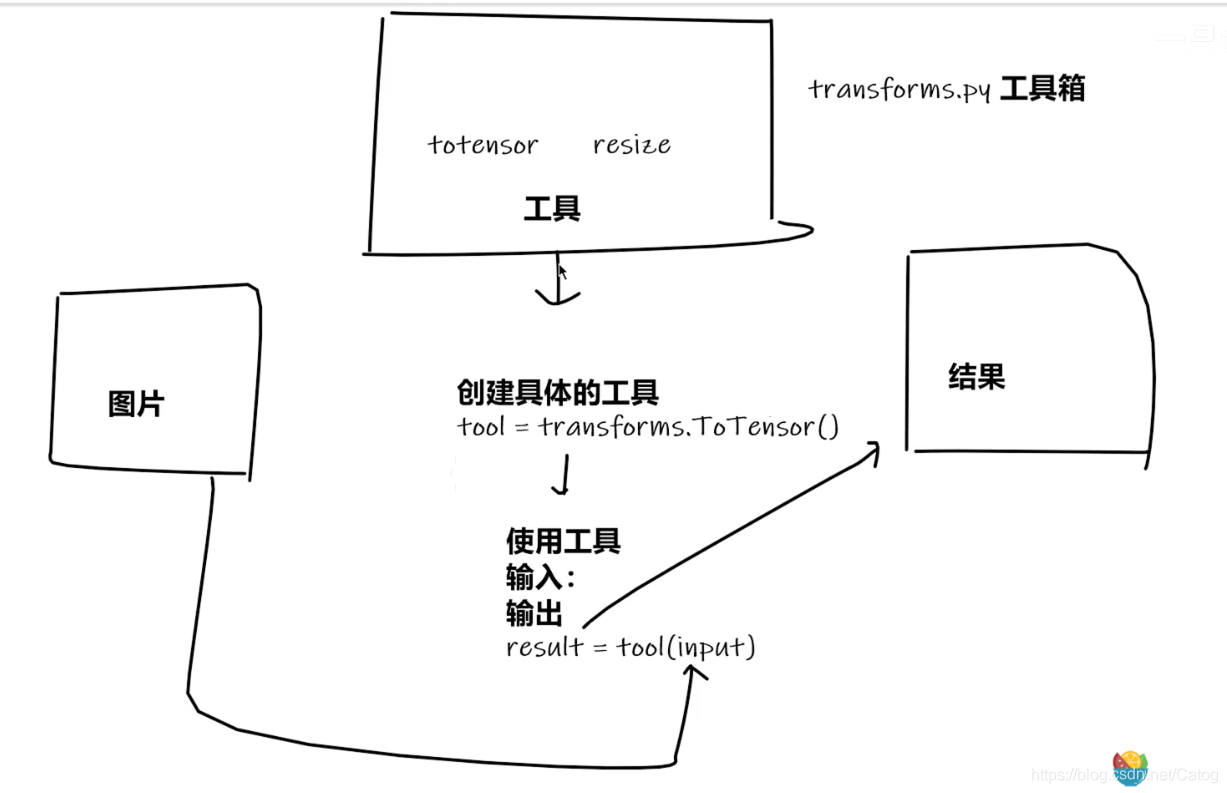
- 在transform.py文件里有很多的类(工具),这些工具是对图像进行处理:
class Compose #将几种transform组合在一块
class ToTensor #变成Tensor格式
class Normalize#正则化
class Resize
Example:
transforms.Compose([
transforms.CenterCrop(10),#进行中心裁剪
transforms.ToTensor(),#变成tensor
])
- transform的使用
from torchvision import transforms
from PIL import Image
img_path="dataset/hymenoptera_data/train/ants/0013035.jpg"
img=Image.open(img_path)
#totensor也是一个类,要创建这个类的一个实例,才能去用它里面的函数
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)
- 使用tensor数据类型,是因为这个数据类型里包含里使用神经网络需要的参数
6.2 常见的Transform
- 图片格式不同,打开的方式也不同
PIL --Image.open()
tensor --ToTensor()
narrays --cv.imread()
- call函数的用法
class person:
def __call__(self, name):
print("__call"+name)
def hello(self,name):
print(name)
person1=person()
person1("zhangsan")#如果定义了内置call,可以直接用参数调用这个函数
person1.hello("lisi")#而这个需要用点调用的方法
- Totensor的用法
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
img=Image.open("image/111.jpg")
tran_tensor=transforms.ToTensor()
img_tensor=tran_tensor(img)
writer.add_image("tensor",img_tensor)
- Normalize用法
class Normalize(torch.nn.Module):
#输入必须为tensor类型的图像,并且有均值和标准差
#给定的均值标准差按照通道数(mean[1],...,mean[n]) (std[1],..,std[n])
#输出[channel] = (输入[channel] - 均值[channel]) / 标准差[channel]
tran_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=tran_norm(img_tensor)
writer.add_image("normalize",img_norm,2)
- resize的用法
输入是PIL格式的,如果给定长宽则正常缩放,如果给定一边,则按照最短边等比缩放。
返回的也是PIL格式的
tran_resize=transforms.Resize((512,512))
#img PIL -> resize -> img_size PIL
img_size=tran_resize(img)
#img_size PIL ->img_size tensor
img_size=tran_tensor(img_size)
writer.add_image("resize",img_size,0)
- compose的用法
注意格式,输入根据resize所以输入的是PIL格式的
tran_resize2=transforms.Resize(512)
#PIL -> PIL ->tensor
tran_compose=transforms.Compose([tran_resize2,tran_tensor])
img_size2=tran_compose(img)
writer.add_image("resize2",img_size2,3)
- radomcrop随机裁剪
tran_radom=transforms.RandomCrop(512)
tran_compose2=transforms.Compose([tran_radom,tran_tensor])
for i in range(10):
img_crop=tran_compose2(img)
writer.add_image("random",img_crop,i)


















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









