




 本文介绍了一种针对SQuAD数据集设计的深度学习模型,用于解决阅读理解中的答案预测问题。模型首先调整文档的词嵌入向量,通过计算问题与文档单词的相似性来赋予权重,然后利用双向LSTM编码问题和加权后的文档,最终通过预测答案的起始和结束位置来定位答案。模型包括词表示层、过滤层、上下文编码层、多视角匹配层、聚合层和预测层。
本文介绍了一种针对SQuAD数据集设计的深度学习模型,用于解决阅读理解中的答案预测问题。模型首先调整文档的词嵌入向量,通过计算问题与文档单词的相似性来赋予权重,然后利用双向LSTM编码问题和加权后的文档,最终通过预测答案的起始和结束位置来定位答案。模型包括词表示层、过滤层、上下文编码层、多视角匹配层、聚合层和预测层。
(1)论文解决SQuAD数据集上的答案预测问题:1、通过乘以根据问题计算的相关权重来调整文档的词嵌入向量;2、通过双向LSTMs编码问题和加权后的文档;3、通过预测答案的开头和结束位置来得到答案。
(2)论文预测答案的方法基于假设:如果这个上下文与问题非常相似,则这个范围很可能是正确答案。
(3)任务:选择开始与结束位置概率最高的位置
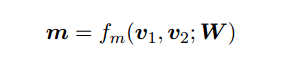 ab为答案开始位置,ae为答案结束位置
ab为答案开始位置,ae为答案结束位置
(4)模型结构
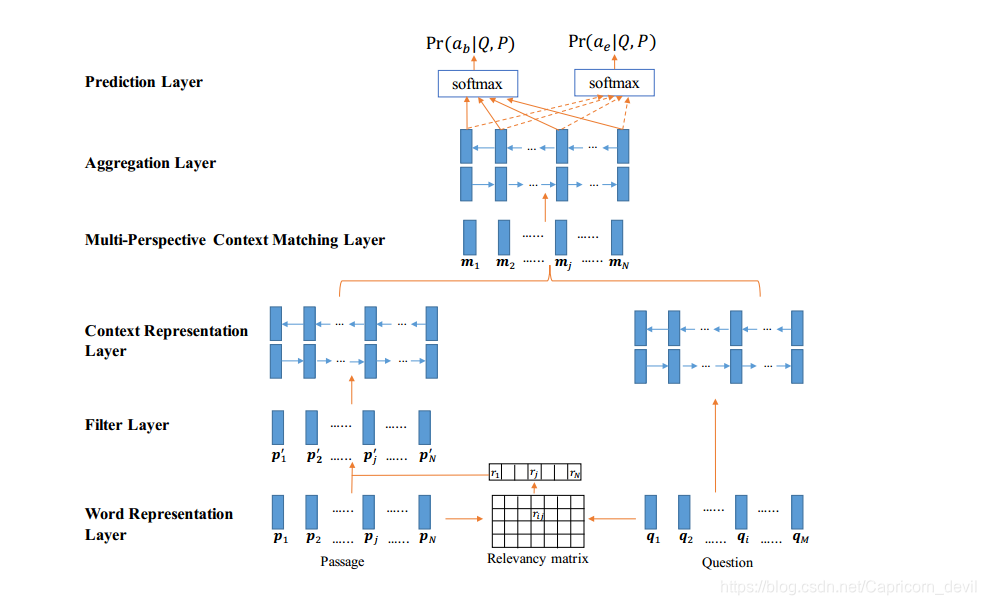
1、Word Representation Layer
使用d维向量表示question与passage中的每个词,使用word embeddings 和 character-composed embeddings来构造该向量。word embedding是使用训练好的GloVe向量,字符嵌入 通过将单词的每个字母送入LSTM来构造。该层的输出是词向量序列
![]()
2、Filter Layer:目的过滤冗余信息,与问题相关性大的单词权重更大
通过计算question与passage单词的余弦相似度,得到相似性矩阵,通过将Pi乘以相关性得到Pi'

3、Context Representation Layer
进行上下文编码,使用双向LSTM
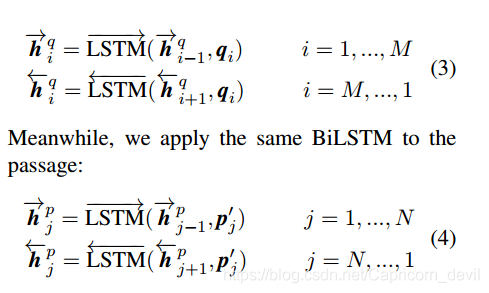
4、Multi-Perspective Context Matching Layer
W为l*d矩阵,l为perspective的数目,v1v2为d维向量
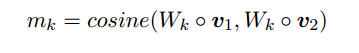 对位相乘,Wk为W第k行
对位相乘,Wk为W第k行
采用三种匹配策略,将得到的向量连接后为mj

5、Aggregation Layer:使用BiLSTM训练4得出的匹配向量,得到aggregation vector。为了将passage的每个时间步考虑到上下文信息
6、预测层:使用前馈神经网络算出ab,ae的概率,再通过softmax层归一化,选出最大值
(5)结果
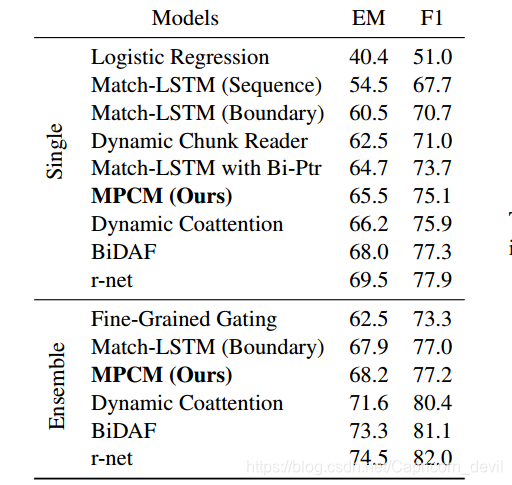
(6)问题:答案都为上下文中出现的连续单词

















 888
888




 到【灌水乐园】发言
到【灌水乐园】发言







