



作者 | BigBite 来源 | BigBite思维随笔
原文链接:模仿学习无法真正端到端
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
自动驾驶行业新的技术名词层出不穷,在大家争论到底是VLA更好,还是世界模型更先进的时候,其实忽略了相比模型架构,训练方法才是决定功能效果的关键。事实上无论是VLA也好,世界行为模型也罢,本质上他们都是实现端到端的具体模型结构,可是随着越来越多头部企业在端到端的技术范式上努力探索投入,头部团队逐渐发现单纯依靠模仿学习实现不了彻底的端到端自动驾驶!
那么模仿学习在自动驾驶领域中的问题和局限性到底在哪里呢?
模仿学习假定专家数据是最优的
模仿学习的潜在假设是每一条训练数据轨迹都给出了在当前状态下最优的行为真值,因此越接近训练数据的行为就是越好的行为。
然而实际上在驾驶这样一个存在着非常丰富多模态解的场景下,根本就没有所谓的唯一完美驾驶行为。在纯粹基于模仿学习的端到端模型训练过程中,训练数据主要来自风格,驾驶技术,文明礼让各异的真人驾驶数据,然而不是所有驾驶员都是遵纪守法的老司机,因此这些驾驶数据不仅在驾驶风格,策略上缺乏一致性,更加难以称得上是最优且完美的,从这样不完美的数据集自然学不到清晰正确的驾驶逻辑,最多能学到一些相对模糊似是而非的驾驶模式而已。
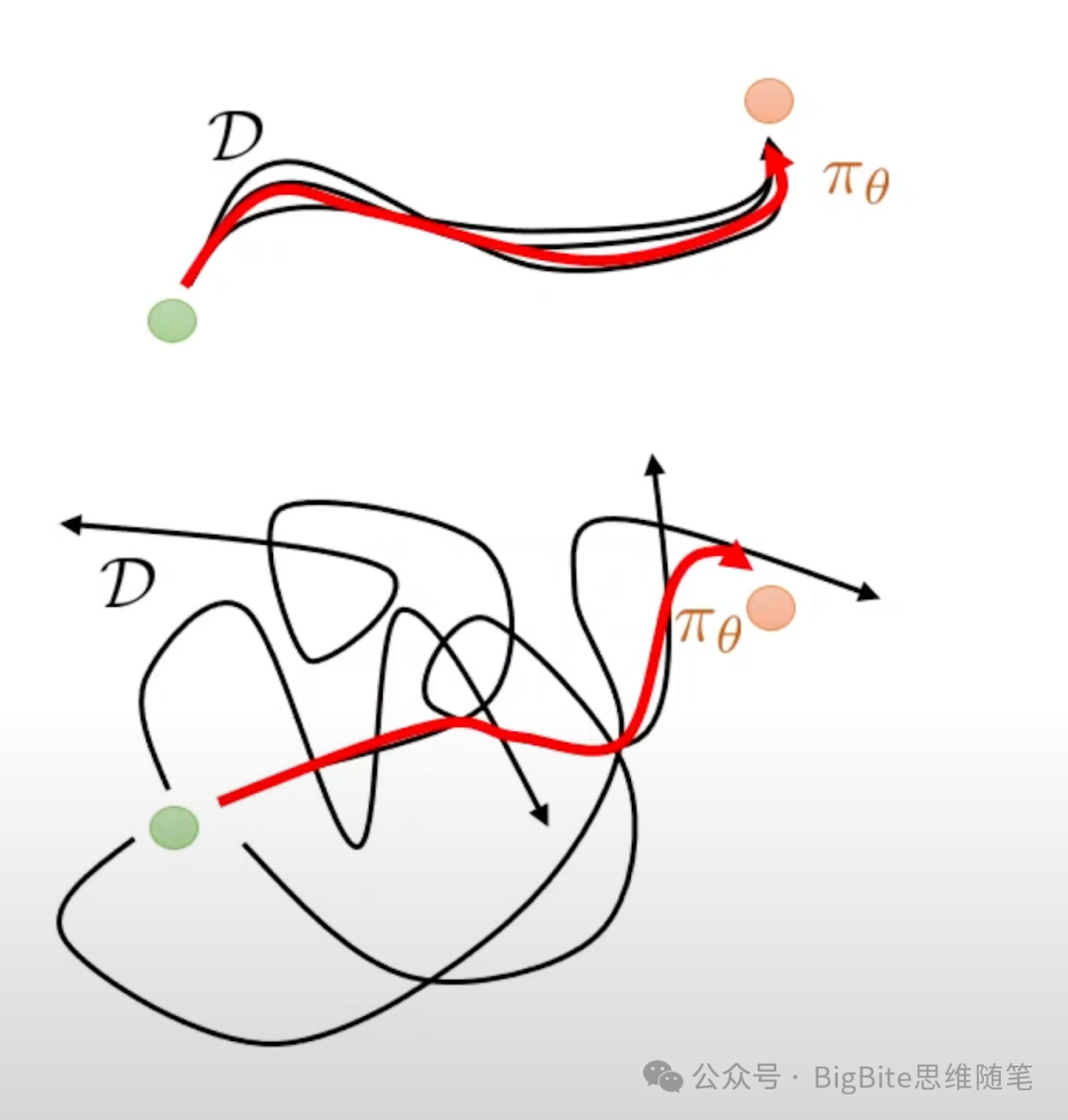
所以纯粹基于模仿学习的端到端模型很难学到人们期待的有很强逻辑和因果关系的拟人驾驶策略,表现出来的反而是极强的随机性和不确定性。
模仿学习忽略了关键决策的重要性
模仿学习的另一个核心问题在于模仿学习假定每时每刻人驾数据的真值的正确性都是等权重的,人驾数据在训练中对于Policy行为模型参数的影响都是吃大锅饭,决策轨迹的每个局部都尽量尝试逼近人驾数据真值,而无法区分哪些决策是关键场景决策,哪些决策是阈值宽松的普通场景决策。由于没有对不同的场景决策区别对待,任何时候决策的重要性都差不多,这样的模型因为训练阶段没有强调重点,便会在很多关键时刻犯下致命错误,导致一些时候模型的输出没办法被完全信赖,还需要其他兜底策略的引入。
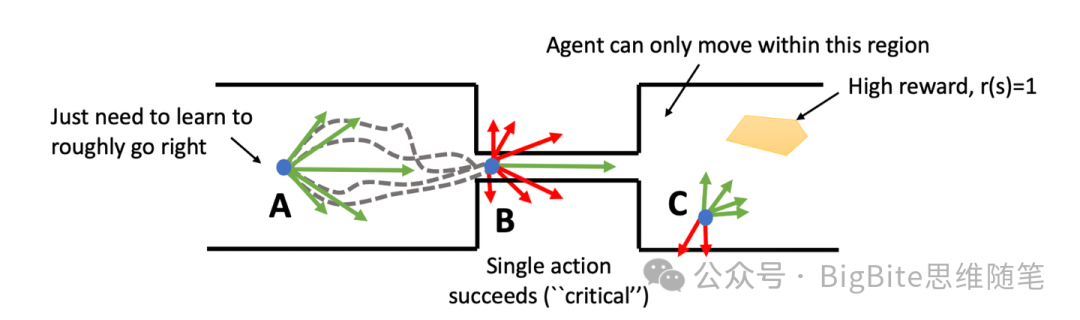
正如上图所在场景中,A是一个相对简单的场景,即使相对随机的朝右轨迹都可以顺利通过宽阔的A区域不会产生明显问题,而狭窄的B位置则是一个非常关键的场景,除了一条平直绿色向右轨迹,绝大多数轨迹都会发生碰撞,因此这个场景Policy模型的输出精度就非常的关键。而最后C位置难度则介于A,B之间,此时模型只需要通过训练理解到朝向High reward区域的动作更有优势,就可以找到相对更优的行为决策。
那么怎么定义关键场景或者关键状态呢?强化学习领域里就把给定状态下某个特定动作未来会获得的动作回报相比于其他动作会获得的未来平均回报的差异值叫做优势,一个场景/状态下最优动作和其他动作相比优势越显著,那么这个场景就越该被认定为关键状态,反之则是非关键状态。
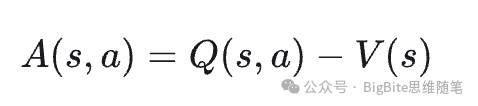
自动驾驶恰恰是一个充满关键场景的领域,因此单纯依靠模仿学习,端到端模型可能在一般场景能够表现出一定的性能,但是在至关重要的关键场景则很容易发挥不如人意。例如纯粹模仿学习的端到端系统可能在普通场景下仍旧能够进行控车,但是当需要系统在旁侧车辆紧急切车时候能够在很短的时间窗口下即时响应减速,避让风险,那往往纯粹模仿学习的系统就很难输出符合安全要求的完美轨迹了。
开环模仿学习会因为累积误差进入OOD场景
开环模仿学习还会由于累积误差的产生,进入与训练数据完全不同的分布从而失效。由于自动驾驶是一个长时序动作任务,因为开环模仿学习学到的Policy和最优解之间存在微小误差,这些误差的累积就会导致自车进入人驾很少遇到的驾驶状态,而由于新的驾驶状态在训练数据分布中缺失,模型的行为也很难预判,就会造成性能的显著下降。
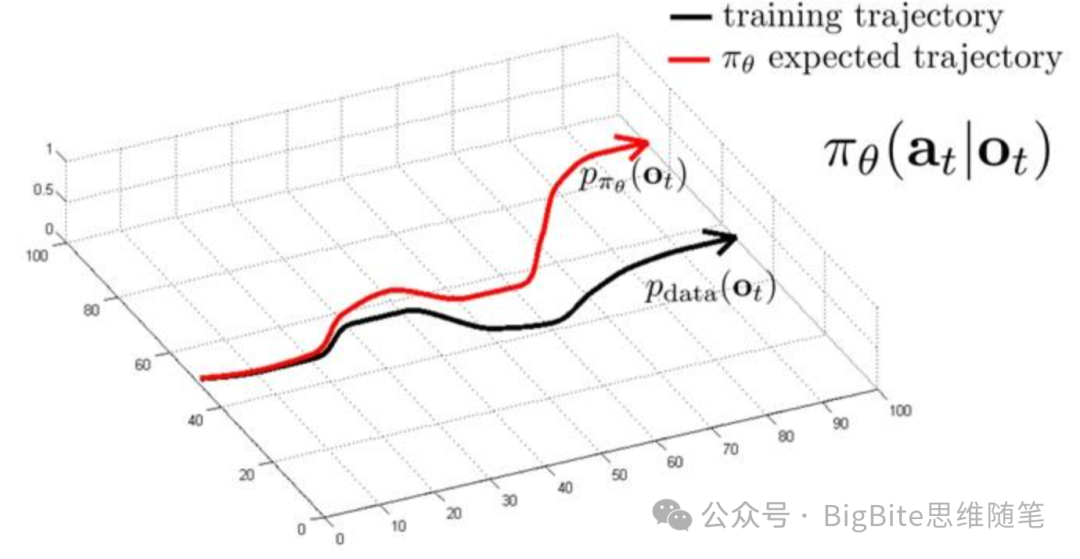
这种现象表现在实车就会发生例如人类数据里驾驶员往往早早完成车道规划,避免驶入不可通行方向的车道。但是当某一模型的行为不是最优的,就可能出现迟迟不能变道到正确车道的问题,然而很晚发生变道的现象在人驾数据分布中非常少见,最终结果是越到了不得不变道的最后时刻,纯模仿学习端到端系统越容易临阵放弃,最终错过导航,发生接管。
总结
技术研发最核心的关键不在于紧追潮流,而在于能否识别研发的关键路线和瓶颈,当人们争论不同的技术路线孰优孰劣的时候,其实经常陷入了舍本逐末的误区。随着实践端到端技术方案的经验增长,越发意识到我们的问题在于如何找到模仿学习训练范式之外的新方法,而引入新的方案如何帮助解决纯模仿学习系统的技术瓶颈,后面有机会再来与大家一起讨论一番。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









