




想象一下,你正在教一个模型学习开车。你给它看了一堆人类司机的驾驶录像,希望它能模仿得一模一样。听起来很合理对吧?但问题来了——人类司机偶尔也会犯错,或者做出一些在特定情况下很危险的操作!
这就是当前端到端自动驾驶面临的最大挑战:模仿学习虽然能让模型开车像人类,但不能保证它开得安全。针对这个现象,中科院的团队认为模仿学习主要有两个大问题:
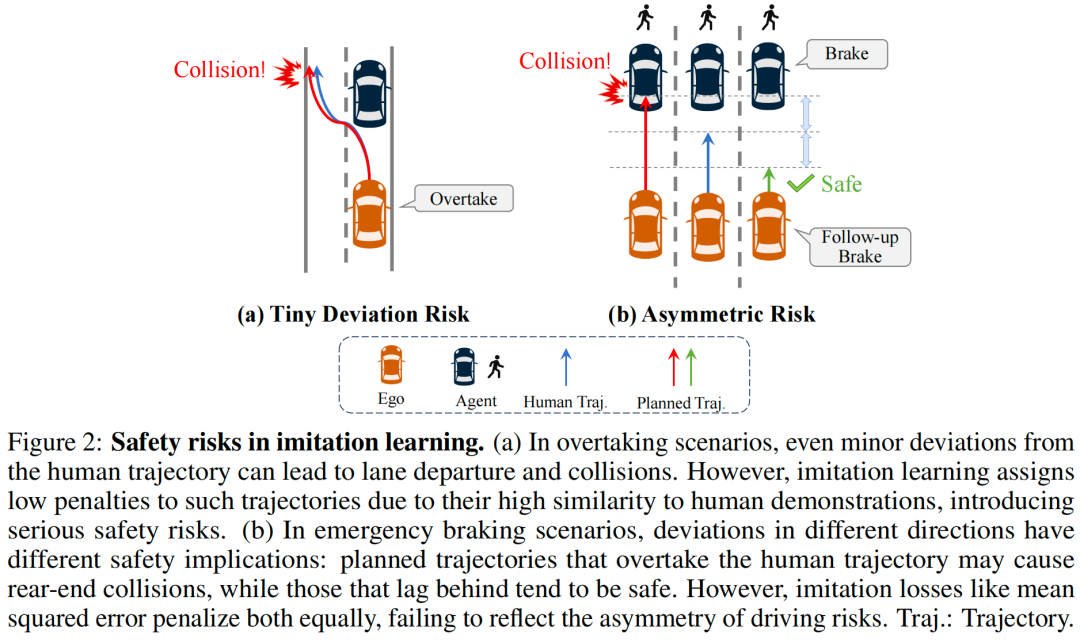
几何距离不等于安全距离:模仿学习通常使用均方误差等对称损失函数,只关心预测轨迹与人类轨迹的几何相似度。但现实中,即使轨迹看起来很像,安全性可能天差地别;
对称损失忽略风险不对称性:在紧急刹车时,超越人类轨迹可能导致追尾,而滞后于人类轨迹通常更安全。但对称损失函数对两个方向的偏差给予同等惩罚,完全无法反映驾驶风险的不对称性。
为了解决上述的问题,中科院的团队提出了DriveDPO - 一种基于safety DPO的策略学习框架。首先从人类模仿相似度和基于规则的安全分数中提炼出统一的策略分布,用于直接的策略优化;其次,引入迭代式DPO,将其构建为轨迹级别的偏好对齐任务。在NAVSIM基准数据集上的大量实验表明,DriveDPO实现了90.0的最新最优PDMS。此外在多种复杂场景下的定性结果进一步证明,DriveDPO能够生成更安全、更可靠的驾驶行为。
论文链接:https://arxiv.org/abs/2509.17940
论文标题:DriveDPO: Policy Learning via Safety DPO For End-to-End Autonomous Driving
更多自动驾驶的最新技术进展、行业动态和岗位招聘,欢迎加入自动驾驶之心知识星球!

背景回顾
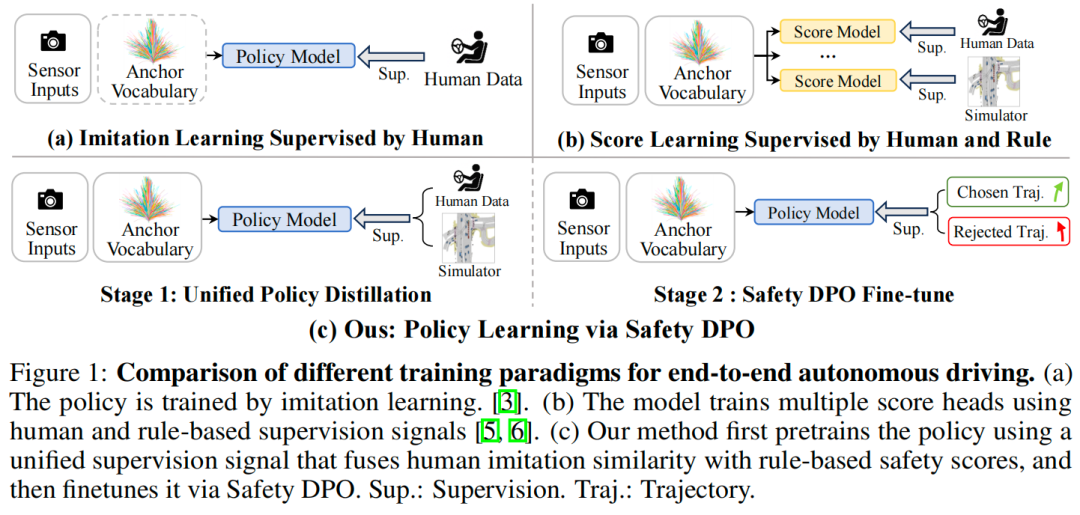
近年来端到端自动驾驶发展很快。与传统的模块化流程不同,端到端方法直接从原始传感器输入预测未来轨迹,既避免了模块间的误差累积,又简化了整个系统的流程。如图1a所示,主流端到端方法通过模仿学习优化。尽管模仿学习能生成符合人类驾驶习惯的行为,但它存在两个关键的安全性问题:
第一,模仿学习的核心是最小化预测轨迹与人类轨迹之间的几何距离。然而即使与人类轨迹的差距很小也可能导致危险结果;
第二,模仿学习中常用的对称损失(如均方误差)会对两个方向的偏差施加同等的惩罚,但不同方向的偏差对安全性的影响差异极大(见图2b)。因此仅通过模仿学习训练的策略往往会生成看似合理、但在实际驾驶场景中存在安全风险的行为。
为解决安全性问题,一些引入了基于规则的指导模型,并采用多目标蒸馏技术,将多个规则驱动的指标作为监督信号进行回归,具体如图1b所示。尽管此类设计在安全性上优于纯模仿学习,但它们会为每条锚定轨迹独立学习单独的评分函数,而未直接优化底层的策略分布,最终导致驾驶性能欠佳。
受模仿学习的安全性问题以及基于分数的方法在优化间接性上的局限所启发,本文提出DriveDPO——一种基于安全直接偏好优化(Safety DPO)的策略学习框架。具体而言:
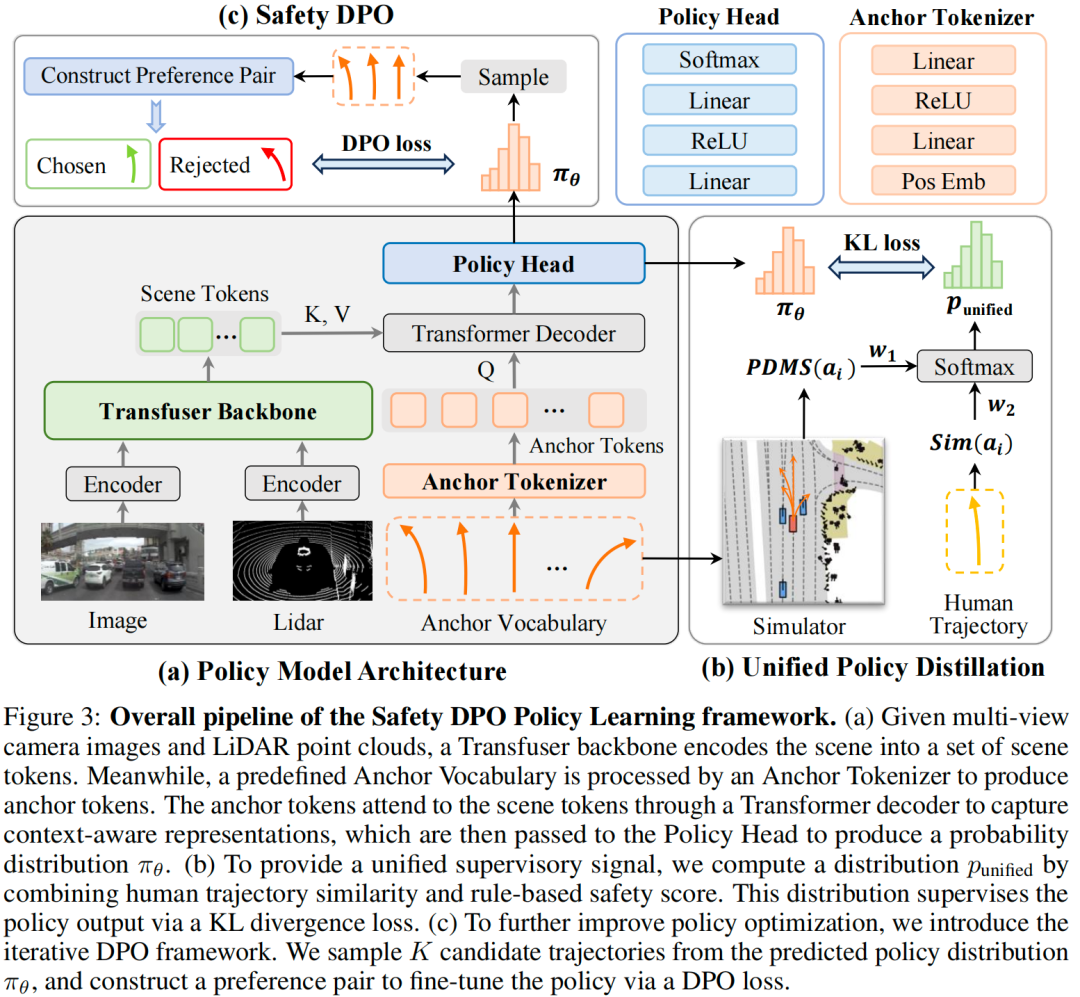
针对基于分数的方法仅优化单条锚定轨迹的分数、而非整体策略分布的问题,本文提出统一策略蒸馏方法:将人类模仿相似度与基于规则的安全分数融合为单一监督信号,用于策略模型的训练。与基于分数的方法为每个候选轨迹构建独立评分头不同,本文方法直接对所有锚定轨迹的策略分布进行监督,从而实现更连贯的端到端策略优化。
然而将模仿监督与安全监督直接融合为单一训练目标会引发多目标优化问题。为解决这一问题,本文引入迭代式DPO,提出“安全直接偏好优化(Safety DPO)”——将监督信号重构为轨迹级别的偏好对齐任务。该方法通过更稳定、更具针对性的优化,增强策略对安全导向偏好的响应能力。通过对轨迹对进行偏好学习,Safety DPO能优先选择“符合人类驾驶习惯且安全”的轨迹,而非“符合人类驾驶习惯但不安全”的轨迹,从而在策略学习中实现更精准的安全偏好对齐。
本文在NAVSIM基准数据集和Bench2Drive基准数据集上对所提框架进行了评估。在使用ResNet-34 backbone的统一实验设置下,实现了90.0的最新最优PDMS,相较于基于模仿学习PDMS提升了1.9;相较于基于分数的最新最优方法PDMS提升了2.0。此外,定性结果还表明,本文方法在复杂场景中显著提升了所学策略的安全性。
本文的贡献可总结如下:
明确了现有模仿学习方法与基于分数的方法的核心挑战:纯模仿学习无法区分“看似符合人类驾驶习惯但存在安全隐患”的轨迹;而基于分数的方法将分数预测与直接策略优化相分离,导致性能不佳。
为应对上述挑战,提出DriveDPO(基于Safety DPO的策略学习框架):首先从人类模仿信号与基于规则的安全分数中提炼统一的策略分布,随后通过DPO的微调阶段进一步优化策略。
在NAVSIM基准数据集上开展了全面实验,实现了90.0的最新最优PDMS,在多个安全关键指标上均取得显著提升。通过有效抑制不安全行为,本文方法为安全关键型端到端自动驾驶应用展现出巨大潜力。
DriveDPO算法详解
策略模型架构
模型的输入包括多视图相机图像、激光雷达(LiDAR)点云、当前自车状态(ego state)与导航指令,输出为预定义的 个离散候选轨迹上的概率分布,具体如图3a所示。首先,本文构建离散的锚点轨迹集合以定义策略网络的输出空间:通过对NAVSIM数据集Navtrain子集中的人类驾驶轨迹进行 -均值聚类,得到 个具有代表性的锚点轨迹,记为 (其中 )。每个锚点轨迹
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









