



作者 | 胖胖橙 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/11652672895
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
1. 决策过程的引入
有了planning,为什么还需要decision-making?
key Point:交互性、不确定性!
Geometric World(几何世界)--> Probabilistic World(概率世界),几何世界关注的是空间的静态性质,而概率世界关注的是动态的、不确定的过程。
在自动驾驶系统中,planning(规划)和decision-making(决策)虽然紧密相关,但它们各自扮演着不同的角色,都是确保自动驾驶车辆安全、高效运行的重要组成部分。
a.Planning(规划)
规划通常指的是自动驾驶系统中的路径规划功能。它的核心任务是基于车辆的当前位置、目标位置以及周围环境信息,生成一条从起点到终点的最优路径。这包括:
全局路径规划:在高层次上,规划出从起点到目标地点的最佳路径,这可能涉及跨越多个道路段、交叉口等。
局部路径规划:在每个时刻,根据当前环境和交通状况,调整并优化行驶路径。
避障:处理动态障碍物(如行人、其他车辆)和静态障碍物(如路障)的问题,确保路径的安全性和有效性。
b.Decision-Making(决策)
决策涉及在复杂的交通环境中做出具体的驾驶决策。这包括:
交通规则遵循:遵守交通信号灯、标志、限速等规则。
交互决策:与其他交通参与者的互动,例如在复杂交叉口时如何选择合适的行驶策略,或者如何应对突发状况(如另一辆车突然变道)。
优先级处理:决定在某些情况下的优先权问题,比如在遇到紧急车辆时的让行策略。
c.为什么都需要?
复杂性和动态性:虽然路径规划可以为车辆提供一条理想的路线,但现实世界中情况复杂且不断变化。决策系统需要实时处理各种动态因素,如其他车辆的行为、交通信号的变化等。
安全性:决策系统确保车辆在实际道路上安全行驶,通过对各种复杂情况的判断,调整规划结果以应对意外和突发事件。
交通规则和法规:规划可能无法完全满足所有交通规则的要求,决策系统负责确保车辆在遵守交通法规的同时执行适当的行驶策略。
决策规划的一些思考
在运动规划和控制模块的基础上,为什么还需要决策过程?
对于下图的场景,自车实际可以采取不同的action,包括,让行、抢道等等。
每种方案实际上对应一种决策,每种决策实际上对应一簇规划。
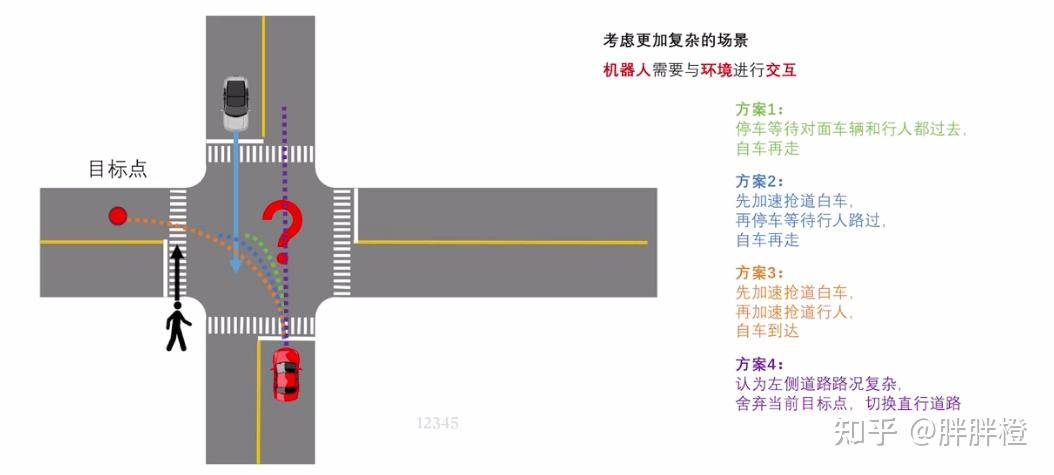
智能驾驶决策的应用场景:路径规划、交通行为预测、避障决策、交叉路口处理、自主停车、道路选择等等。
关键问题:决策问题如何定义,决策空间如何求解?
所有的障碍物存在一定的概率分布,包括感知不确定、预测不确定等;
自车做出一定的action后,对手车也会做出相应的动作,并且状态转移过程为随机过程,不易建模;
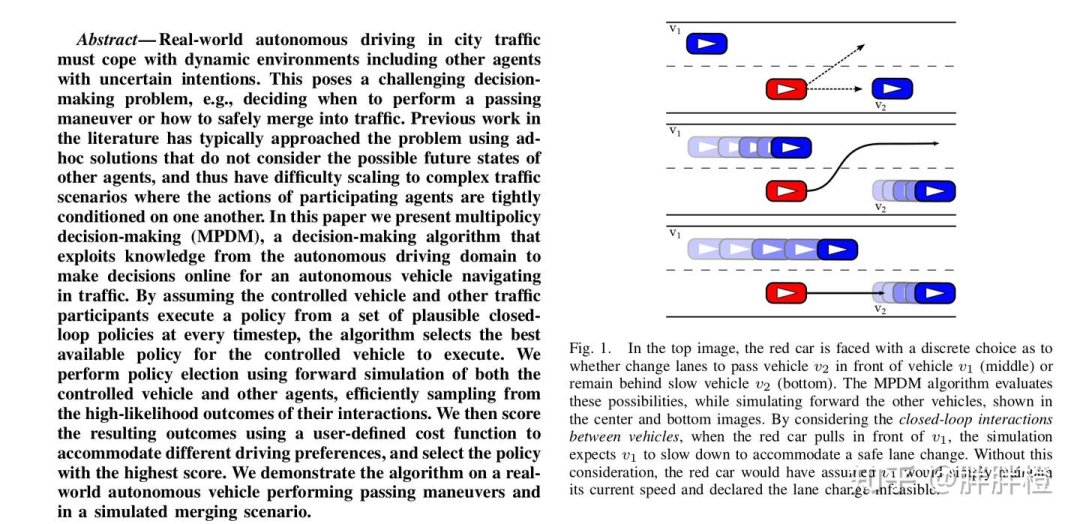
2. MPDM:Multipolicy Decision-Making 多策略决策 (考虑与他车的交互)
论文链接:MPDM: Multipolicy decision-making in dynamic, uncertain environments for autonomous driving
其他资料参考:论文推土机:MPDM: Multipolicy Decision-Making in Dynamic, Uncertain Environments for Autonomous Driving
MPDM 主要工作:
将车辆行为建模为合理、安全的策略,减少不确定性;(desire policy:变道、保持、减速,每个交通参与者(包括自车和其他车辆)的策略从一个有限的策略集合中选择)
通过前向模拟考虑其他车对自身的影响;(forward simulation:基于当前状态和policy,推演出各个交通参与者未来一段时间的状态,模拟出未来可能的场景)
评估不同策略下的模拟结果,选择最优策略;
2.1 决策过程问题描述:

建模自车动作以及其他车的动作,关键:其他车如何建模?(如何预测出其他车的状态?)
目标:选择决策周期H中奖励期望最大的策略,即:
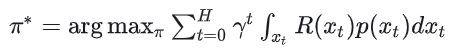
符号定义:

联合概率密度建模 p()
联合概率密度p()表示从当前状态到下一时间步的状态转移概率,定义为:
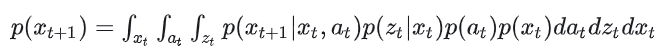
其中:
p(|,):描述在给定当前状态和动作后,状态如何转移到。
p(|):描述观测噪声对状态的影响。
p():动作的分布,描述可能采取的行为。
p():当前状态的先验概率。
这一步通过积分对所有可能的状态、动作和观测取平均,得到的联合概率密度。
假设每辆车的瞬时行为是独立
假设每辆车的瞬时行为相互独立,这使得联合概率密度可以表示为各车辆独立概率的乘积,自车和其他车辆的行为通过各自的状态转移模型p(|,)描述。
单辆车的状态转移概率建模为:
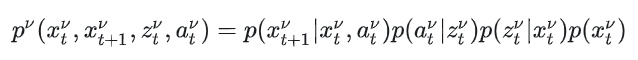
联合概率密度公式为:
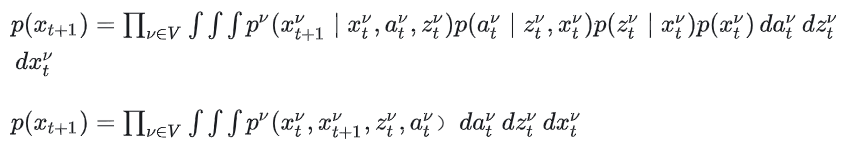
2.2 决策过程的近似
自车与他车按照一定的策略,去做前向传播,其他车是否可以建模为desire的policy?
给定一个policy,用trajectory optimization 的方式或者model-based (IDM方法)去模拟其他车辆的行为,然后对不同的策略进行打分评估,得到当前最优的策略选择。


单车的联合概率表达
单车的联合概率密度可以表示为:
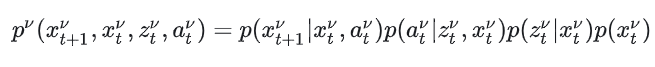
这一公式的意义为:

通过对,,积分,可以得到v车辆在下一时刻的状态分布p()。
考虑策略的引入
MPDM 通过假设每辆车由特定的策略(policy)来进行预测,即:从有限的离散集合中选择策略。策略用表示,其对每辆车的动作分布起决定性作用。在引入策略后,概率公式修改为:
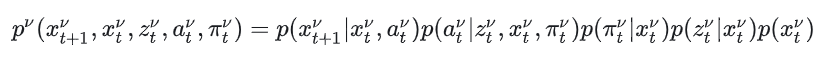
这一公式引入了策略选择的影响:

相较于之前的公式,动作的选择p()由策略控制,这使得 MPDM 可以更精确地模拟其他车辆的行为。
论文中,对这部分的公式有比较详细的推导。具体可参考原文。
2.3 策略选择流程

伪代码的核心步骤
输入输出:
输入:
:包含所有车辆的候选策略集合,包括自车和其他车辆可能的策略。
p():当前的状态概率分布,包括自车和其他车辆的状态信息。
H:决策的规划周期。
输出:选定的最优策略及该策略的得分。


策略选择:
从评分集合C中选出评分最高的策略。


2.4 实验测试
实验比较简单,并且只包含车道保持、左右变道、停车这几个有限的policy。

变道过程:
(e) 初始状态:
当前策略:保持车道(Lane nominal)。
得分:保持车道策略得分较高(3.10),而“左变道”和“右变道”不可用(得分为 N/A)。
(f) 决策过程:
遇到慢速车辆后,系统模拟“左变道”策略(得分为 10.01,远高于保持车道 2.10),选择变道。
(g) 执行超车:
在左车道中,保持车道策略重新成为最优策略(3.11),车辆完成变道并加速。
(h) 回归原车道:
超车完成后,“保持车道”策略优先级更高(1.09),车辆返回右车道。
2.5 补充:MPDM 与 RL的区别:
MPDM:MPDM假设自车和周围车辆都有一个策略集合(policies),并从这些有限的策略集中选择最优策略来实现决策。
自车决策中心化:MPDM直接从自车的角度出发,关注的是如何选择适合当前场景的策略以优化自车的驾驶行为。
通过假设其他交通参与者的策略(如超车、并道、停车等),以及基于这些假设预测周围车辆的状态,MPDM模拟整个交通环境的动态发展。
关注高层策略选择:MPDM重点在于从一个有限的策略集合中选择最佳策略,而不是通过持续交互学习最优行为。
在线决策为核心:MPDM是一种在线算法,不需要通过大量的训练来学习模型,而是基于当前状态和假设的策略,通过前向模拟和cost函数选择最佳策略。
RL(Reinforcement Learning):RL通常将问题建模为一个全局的马尔可夫决策过程(Markov Decision Process, MDP),通过与环境的交互反复学习最优策略,属于全局优化视角。
RL通过奖励函数和状态转移模型学习全局最优解,而不直接假设其他车辆的策略。
关注连续动作和状态空间:RL常用于学习低层的具体动作(如加速、转向等),而不仅仅是高层策略。
RL算法通常需要通过大量的训练来学习策略,例如Q-learning或深度强化学习(DRL)。这种方法需要从环境中收集数据并持续优化。
MPDM存在的问题:
policy的生命周期问题?
即使有先验分布,仍然是个组合爆炸的问题,如何提取出关键场景?
后验更新问题,随着闭环仿真,后验是变化的,决定性能上限,如何引入后验更新?
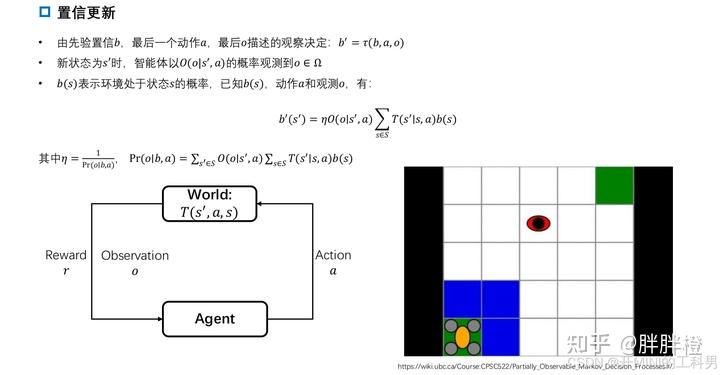
3. 部分观测的马尔可夫决策过程
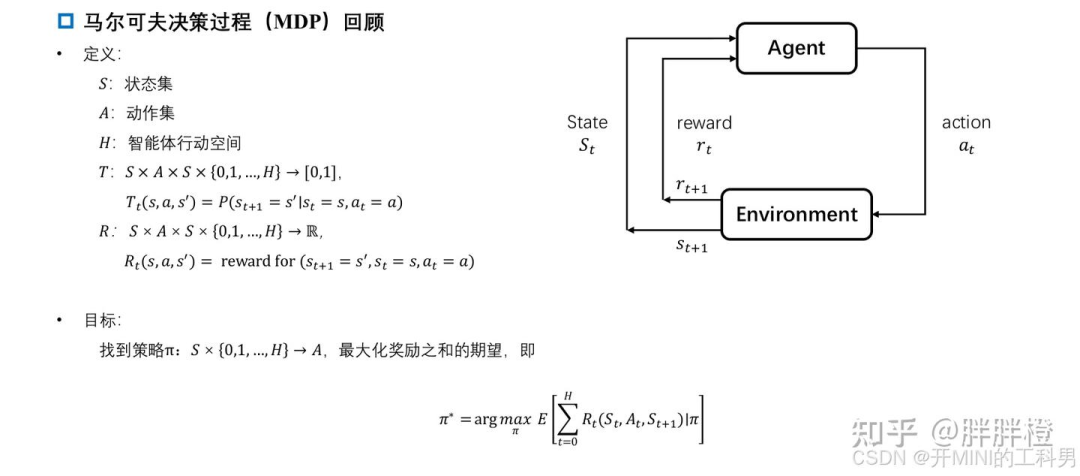
3.1 马尔科夫决策过程(Markov Decision Process,MDP)
MDP定义:
马尔可夫决策过程(Markov Decision Process, MDP)是用于建模决策问题的一种数学框架,广泛应用于强化学习和最优决策的研究中。
MDP决策问题要素
1 状态集合 S:
描述系统可能的状态集合。例如,机器人在不同位置的状态。
2 动作集合 A:描述在每个状态下可供选择的动作集合。例如,机器人可以向左、向右、向上或向下移动。


时间范围 H:
描述问题的时间跨度,可以是有限步数(H)或无限步(长期决策问题)。
MDP 的目标
MDP 的目标是找到一个策略来最大化期望累计奖励:
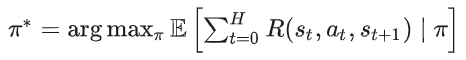
其中,策略 π 是一个映射规则,描述了在每个状态 s 下选择哪种动作 a:
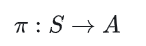
短期目标:最大化下一步奖励。
长期目标:最大化未来累计奖励的期望。
MDP 的关键性质
马尔可夫性:
下一时刻的状态只依赖于当前状态和当前动作,与过去的历史无关。递归性(贝尔曼方程):
累计奖励可以递归表示,便于通过动态规划方法求解最优策略。
3.2 部分观测的马尔科夫决策过程 (Partially Observable MDP, POMDP)
POMDP 的定义
POMDP 是对 MDP 的扩展,解决了状态不可完全观测的问题,通过信念状态和概率模型,帮助智能体在复杂环境中制定最优策略。
POMDP问题要素

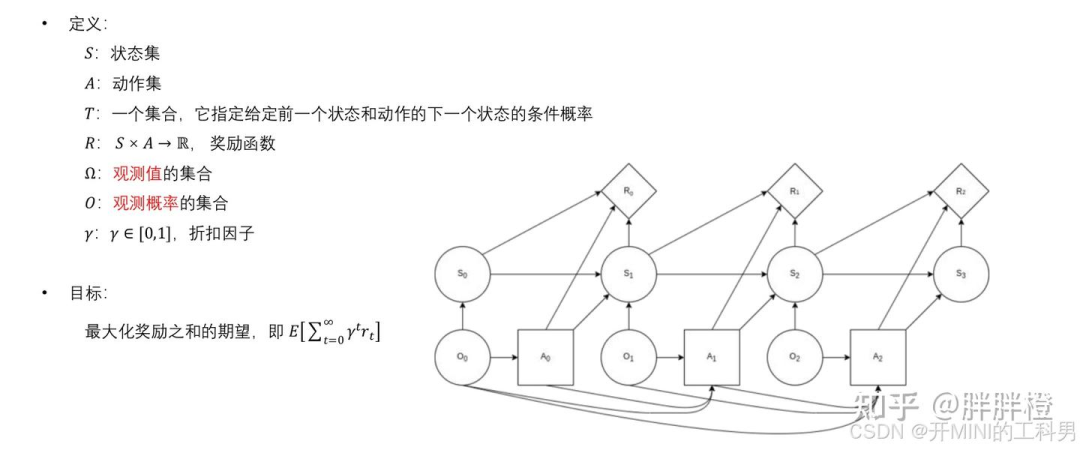
POMDP 的目标
目标是找到一个策略 π ,使得智能体能够在部分观测情况下最大化期望的累计奖励:
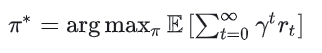
策略:
描述在每一时刻,智能体如何根据观测值(而非状态)来选择动作。信念状态(Belief State):
由于状态不可直接观测,POMDP 通常通过信念状态(一个概率分布)来表示当前可能的真实状态。
3.3 与MDP的联系及区别
MDP 可以看作是 POMDP 的一种特殊情况,即在状态完全可观测的情况下,POMDP 退化为 MDP。(观测 = 转态)
无论是 POMDP 还是 MDP,其状态转移都具有马尔可夫性质,即下一个状态只依赖于当前状态和当前动作,与过去的历史无关。
MDP 中,Agent 直接与环境交互,观察到状态后采取动作并获得奖励。
POMDP 中,Agent 与真实世界交互,只能通过传感器观察到部分信息,因此需要通过观测和先验知识来推断真实状态。(给定当前概率分布,而不是当前状态,应该采取什么action)
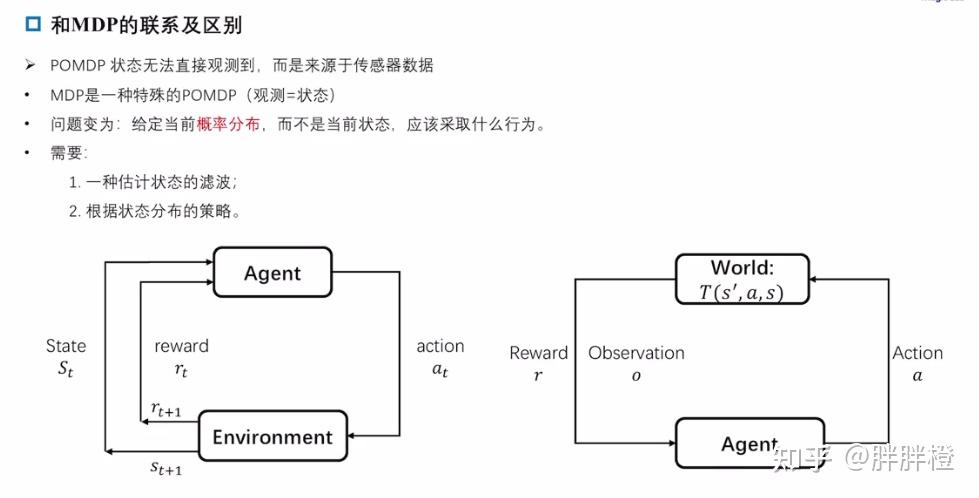
举例说明POMDP 和 MDP 的区别与联系
开门与老虎的例子:
Agent(人)需面对两扇门,一扇门后有老虎,另一扇门是逃生的出口。选取何种策略可以最大可能的逃生。
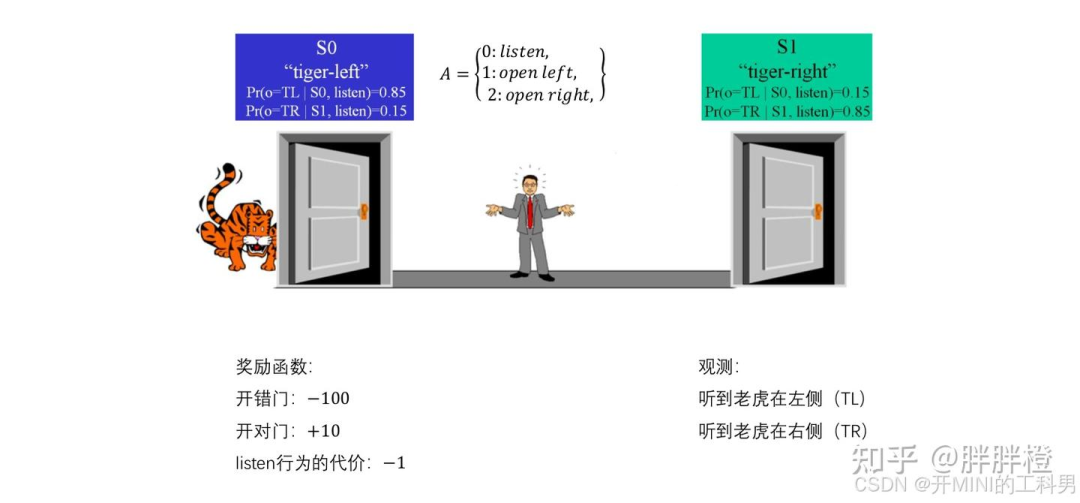
POMDP 视角
Agent(人)无法直接观察门后是什么,必须通过“listen”(听老虎的声音)来推测老虎的位置。
状态(S0 和 S1):老虎可能在左边(S0),或者在右边(S1)。状态的变化依赖于智能体的行为。
动作集(A):智能体可以选择听(listen)或直接开左边门(open left)或右边门(open right)。
观察集:智能体不能直接知道老虎在哪里,但可以通过听老虎的声音获取部分信息。听到左边的声音意味着老虎可能在左边,听到右边的声音则相反。
观察概率(Pr):当老虎在左边(S0)时,听到左边的声音的概率是 0.85,而听到右边声音的概率是 0.15(有一定的不确定性)。同样,老虎在右边时的观察概率是对称的。
奖励:开错门导致 -100 分的惩罚,开对门获得 +10 分的奖励,而“听”的行为有一个代价 -1。
在 POMDP 模型中,智能体只能通过“听”这种部分观察行为来推测当前的状态,它无法直接看到老虎的位置。这种不确定性体现了 POMDP 的核心特点——智能体不能完全观察到环境的真实状态,只能基于观察推测。
MDP 视角
如果我们假设智能体可以直接看到老虎的位置,那么这个问题就变成了一个 MDP 问题:
状态:智能体明确知道老虎的位置。(观测 = 转态)
动作:智能体可以直接选择开哪扇门。
奖励与惩罚:仍然是开错门得到 -100 分,开对门 +10 分。
在 MDP 中,智能体能完全观察到当前状态,因此它可以立即根据观察作出正确的决策,比如看到老虎在左边时就开右边的门,没有不确定性。
如果无法直接观察门后是否有老虎,采取何种策略可以最大可能的逃生?
决策次数对最优解的影响
在“开门与老虎”的 POMDP 问题中,决策次数的不同会影响如何寻找最优解。通过不同的决策时间范围(1次、2次、100次决策)来探索最优策略。
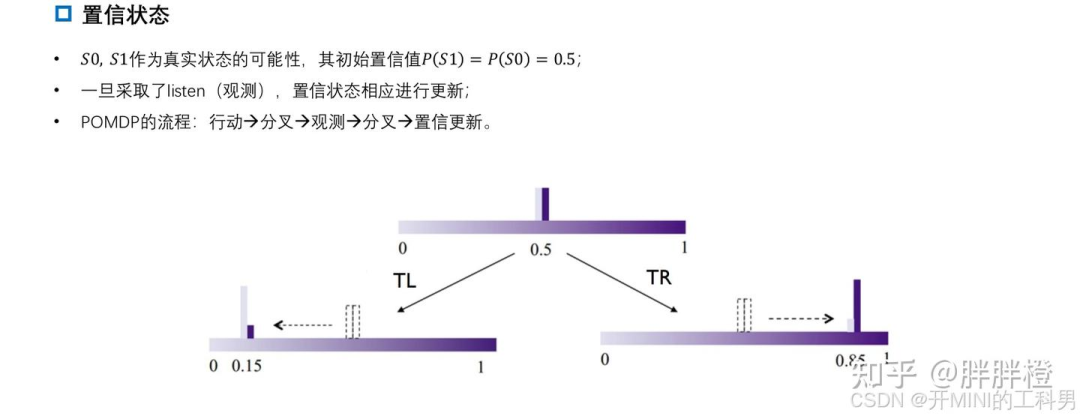
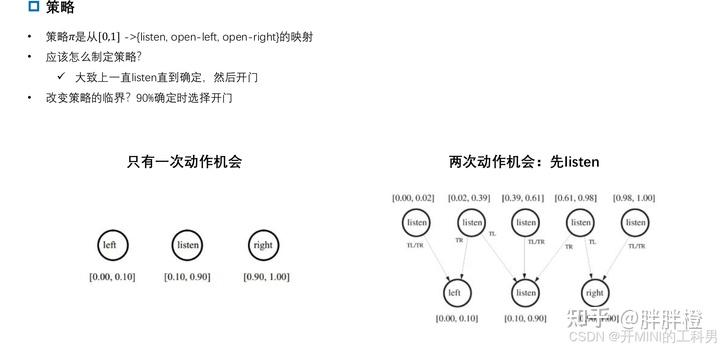
只能做一次决策:
如果只能做一次决策,最优解比较简单,因为你没有时间去“听”并获得更多信息。在这种情况下,你无法改善对状态的认知,只能基于当前的信念状态做出决策。假设初始状态下老虎可能在左边或右边的概率是 50%。
最优策略:此时直接选择开门,因为“听”的行为会消耗 -1 的代价,且你没有足够的回合来平衡这个损失。由于没有任何信息提示,选择任意一扇门的期望是一样的:直接开门会带来 -45 的期望收益(50%概率开对门得到 +10,50%概率开错门得到 -100)。
可以做两次决策:
如果有两次决策机会,策略会更加复杂,因为你可以选择“听”一次,然后根据听到的信息来做更明智的选择。
首先执行“listen”行动,通过听到的老虎位置的信息更新信念状态。
听到老虎在左边时,你推测老虎确实在左边的概率是 85%,在右边的概率是 15%。
听到老虎在右边时,你推测老虎在右边的概率是 85%,在左边的概率是 15%。
最优策略:通过“listen”获得信息后,你的下一步决策(开左门还是开右门)基于更新后的信念状态。如果听到左边的老虎声音,你应开右门(85%的概率成功),听到右边的声音则开左门。
期望收益:
听到老虎在左边:85%概率开对门,期望为:(0.85 x 10 + 0.15 x (-100)= -4)。
听到老虎在右边:同理,期望为:-4。
最终期望收益为:(-4-1=-5)。
相比于不听直接开门(期望收益 -45),听一次然后做决策的期望收益更好。
可以做 100 次决策:
如果有 100 次决策机会,这就变成了长期规划的问题。你可以通过反复“听”来更新信念,并最大化未来决策的累积奖励。在这种情况下,你可以多次选择“listen”来降低不确定性,但每次“听”都有代价,因此需要平衡“听”的次数和总期望奖励。
最优策略:
在较早阶段可以多听几次,但不宜过多,因为每次“listen”都会有 -1 的代价。
在信念足够明确时,停止“listen”,选择开门。如果老虎位置的概率已经非常确定(例如 >95%),继续“听”的收益就不如直接开门的收益高。
在这种长期决策中,POMDP 的策略可以通过动态规划或贝尔曼方程来求解,这样可以在多次决策过程中找到最优的策略。
总结:
1次决策:直接开门,期望收益是 -45。
2次决策:先听一次再开门,期望收益是 -5。
100次决策:先听几次(逐渐增加对老虎位置的确定性),然后开门,期望收益可以更高,具体取决于使用的策略优化算法。
在多次决策问题中,通过不断获取信息来更新信念状态可以大幅提升期望收益,这也是 POMDP 的强大之处。
3.4 POMDP的3种常规解法
3.4.1 连续状态的“Belief MDP”方法


POMDP 的一个核心问题是状态不可直接观测,因此直接优化策略变得困难。为了应对这种情况,通常将 POMDP 转化为一个等价的 MDP 来求解,具体步骤如下:
状态表示:信念状态
POMDP 中的真实状态S不可观测,智能体可以通过信念状态 表示当前对真实状态的概率分布。
信念状态是一个连续分布,表示智能体对系统当前可能处于的状态的概率估计。
从观测值更新信念状态

将信念状态空间作为 MDP 的状态空间
POMDP 中的部分观测问题被转化为在信念状态空间中求解决策问题。
信念状态作为 MDP 的“连续状态空间”,使得问题变得等价于一个高维的 MDP。
价值函数的优化

构造动态模型
通过动态模型预测未来信念状态的演变,将信念状态到未来信念状态的转移看作一个新的“动态系统”。
通过信念状态和奖励的关系,找到最优动作策略。
总结:
将部分可观测问题转化为完全可观测的“信念状态”问题。
计算复杂度高:信念状态是连续分布,可能需要高维空间计算,导致维度灾难问题。
信念更新成本高:每次动作后需要更新信念状态分布,涉及大量的概率计算。
3.4.2 有限前瞻深度策略
有限时域前瞻搜索法是一种高效的在线求解方法,适用于需要实时决策的 POMDP 问题。通过限定搜索深度和剪枝,能够在计算复杂度与解的精度之间找到平衡。
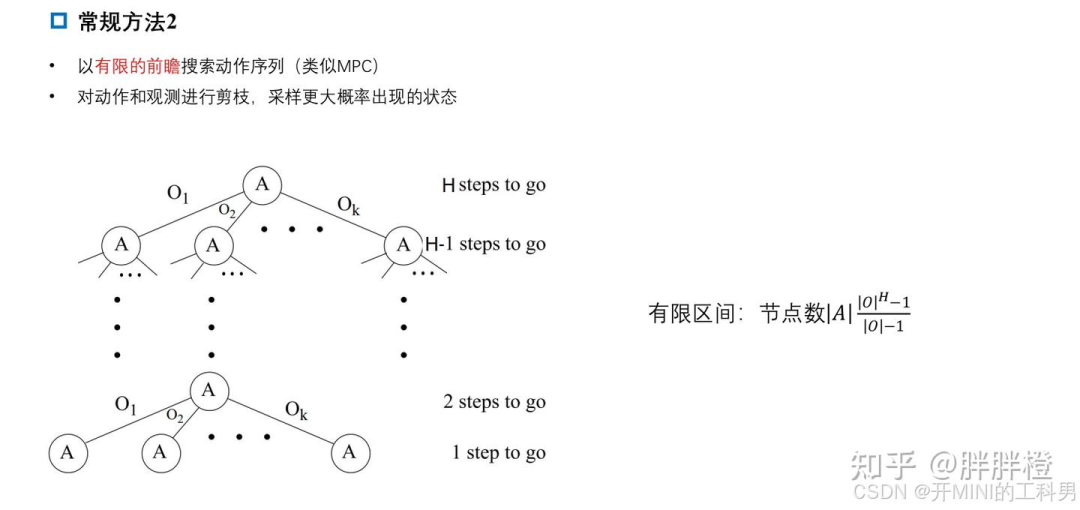
核心思想:
在每个决策时刻,基于当前的信念状态,搜索一个 有限深度 的动作与观测序列(即一个决策树)。
评估每条路径可能带来的总回报,选择当前最优的动作。
通过有限的搜索深度 H 来减少计算复杂度。
主要步骤:
1构建决策树:
从当前信念状态开始,枚举所有可能的动作 A 和观测值 O,构建一个深度为 H 的树形结构。
每个节点表示一个可能的状态,路径由动作和观测值构成。
模拟回报计算:
对每条路径,根据奖励函数R(s,a)和折扣因子,计算累计奖励的期望值。
使用启发式或采样方法对高概率的状态和观测值进行重点计算。
选择最优动作:
在搜索树的根节点(当前信念状态),选择能够最大化期望回报的动作。
剪枝与近似优化:
为减少搜索空间,可以对低概率观测值进行剪枝,专注于高概率路径。
使用启发式方法对节点的未来回报进行估计,而不必完全展开所有可能的节点。
3.4.3 在MDP中规划
在 MDP 中规划是一种简单高效的近似方法,但它忽略了 POMDP 中关于不确定性的全面建模与优化。这类方法适用于那些不确定性较小的场景,但在高度动态且不确定性较大的环境下,可能效果不佳。

该方法将 POMDP 问题近似为完全可观测的 MDP 问题,通过假设当前信念状态的最大概率估计值(最可能状态)即为真实状态来简化计算。这种方法通常被称为 基于最大后验估计(MAP Estimate)的决策方法。
核心思想:
状态假设:假设当前的状态分布中,概率最大的状态就是实际状态。
转化为 MDP:忽略 POMDP 中的不确定性,直接基于假设的确定状态进行规划。
动作选择:根据 MDP 策略选择使即时奖励或累计奖励最大化的动作。
主要步骤:

4. EPSILON 系统概况
论文链接:
https://github.com/HKUST-Aerial-Robotics/EPSILON
EPSILON: An Efficient Planning System for Automated Vehicles in Highly Interactive Environments
Efficient Uncertainty-aware Decision-making for Automated Driving Using Guided Branching
Safe Trajectory Generation for Complex Urban Environments Using Spatio-temporal Semantic Corridor
4.1 自动驾驶决策规划现存问题

多智能体交互的复杂性:
当前决策方法缺乏同时处理多智能体之间多模态交互的能力。
原因在于其他交通参与者的行为具有随机性和交互性,现有方法通常只能处理单一交互模式,无法保证决策的一致性。
多模态预测的局限性:
单轨迹优化方法无法处理多模态预测输出。
多轨迹优化方法对多模态预测输出的处理存在瓶颈(如固定的轨迹数量、分支时间等)。
风险感知的不足:
当前决策规划方法没有充分考虑风险的影响。
不同的驾驶场景中,不同的驾驶员会根据不同的风险偏好做出不同的决策,而现有方法难以兼顾。
4.2 EPSILON系统概述
EPSILON 系统的主要贡献
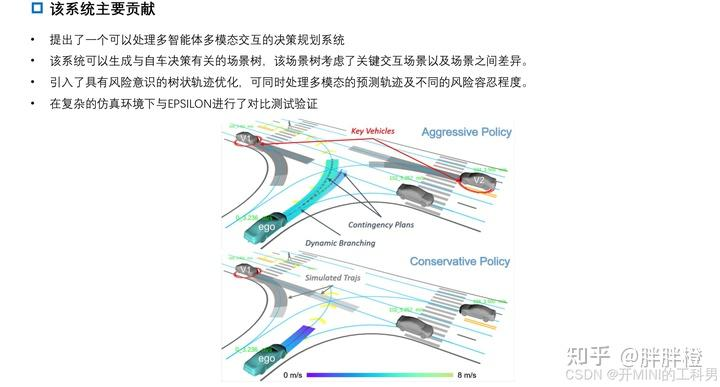
EPSILON 系统架构
EPSILON是一个高效的交互感知规划系统,已在仿真环境和真实的城市密集交通中得到了广泛验证。该系统采用分层架构,包括交互式行为规划层和基于优化的运动规划层。
行为规划层:基于部分可观测马尔科夫决策过程(POMDP)进行建模,但其效率远高于直接将POMDP应用于决策问题的做法。效率的关键在于在动作空间和观测空间中引入的引导分支策略,通过将原问题分解为有限数量的闭环策略评估来实现高效性(EUDM)。此外,文章引入了一种具有安全机制的新型驾驶员模型,以应对由先验知识不完善可能带来的风险。
运动规划层:利用一种时空语义通道(SSC,Spatio-temporal Semantic Corridor)对复杂驾驶环境中的约束进行统一建模。在此基础上,生成了符合行为规划层决策的安全且平滑的轨迹。
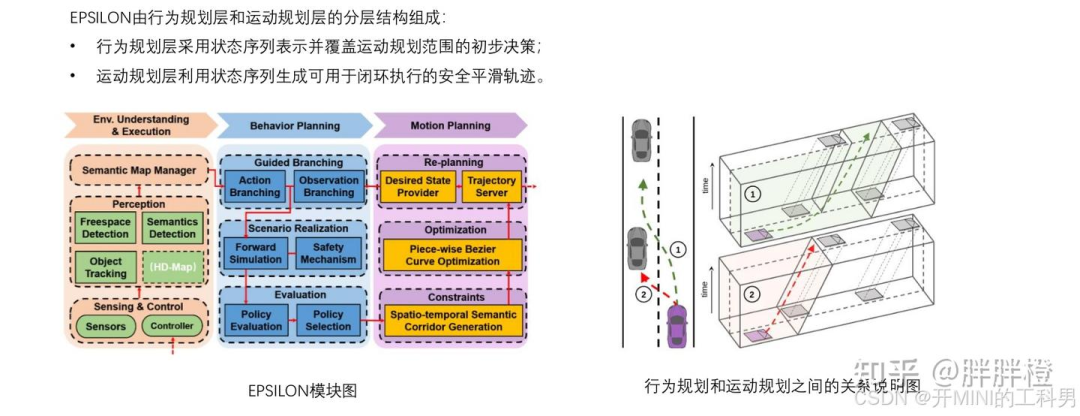
1. 行为规划层
行为规划层主要负责高层次决策,包括动作扩展、意图推断和场景评估,整个过程包含以下关键步骤:
引导分支 (Guided Branching)
根据预定义的策略扩展自车的动作序列(例如加速、减速、变道)。
推断其他交通参与者的可能意图(例如转向或继续直行)。
将自车动作序列和其他交通参与者意图组合生成特定的场景。
场景实现 (Scenario Realization)
采用闭环多智能体的前向仿真逐步模拟场景。
使用扩展的灵活驾驶模型,在面对复杂的现实交通环境和不完全理性行为的参与者时,能够生成安全且类人化的驾驶行为。
场景评估 (Evaluation)
通过仿真对生成的场景进行风险评估和选择,最终决定最优动作序列。
与传统方法不同,EPSILON 将轨迹预测模块与行为规划深度融合,避免了单独的预测模块。
2. 运动规划层
运动规划层负责将行为规划的高层决策转化为具体的、可执行的轨迹规划,具体过程包括:
语义建模
将静态和动态障碍物,以及环境约束建模为“时空语义走廊 (Spatio-Temporal Semantic Corridor, SSC)”。
SSC 提供了统一的约束表示,确保轨迹优化可以处理复杂的驾驶环境。
轨迹优化
使用分段贝塞尔曲线对轨迹进行优化,通过凸包特性确保轨迹的安全性。
采用速度曲线优化,确保轨迹的动态可行性。
轨迹服务器
优化的轨迹被发送到轨迹服务器,用于重新规划调度。
轨迹服务器还向车辆控制器发送控制指令以完成闭环执行。
5.EUDM - Efficient Uncertainty-aware Decision-making 不确定性感知的决策
EPSILON中的行为规划层主要使用的EUDM的方法,参考文献链接如下:
Efficient Uncertainty-aware Decision-making for Automated Driving Using Guided Branching
EPSILON: An Efficient Planning System for Automated Vehicles in Highly Interactive Environments
5.1行为规划问题建模
符号说明

问题:在现实世界中,规划系统总是受到交通参与者之间未知的交互模式的影响?
解决思路:以POMDP的形式对不确定性行为规划问题进行建模。

将驾驶场景转为POMDP形式:

5.2 行为规划整体流程
A. Motivating Example
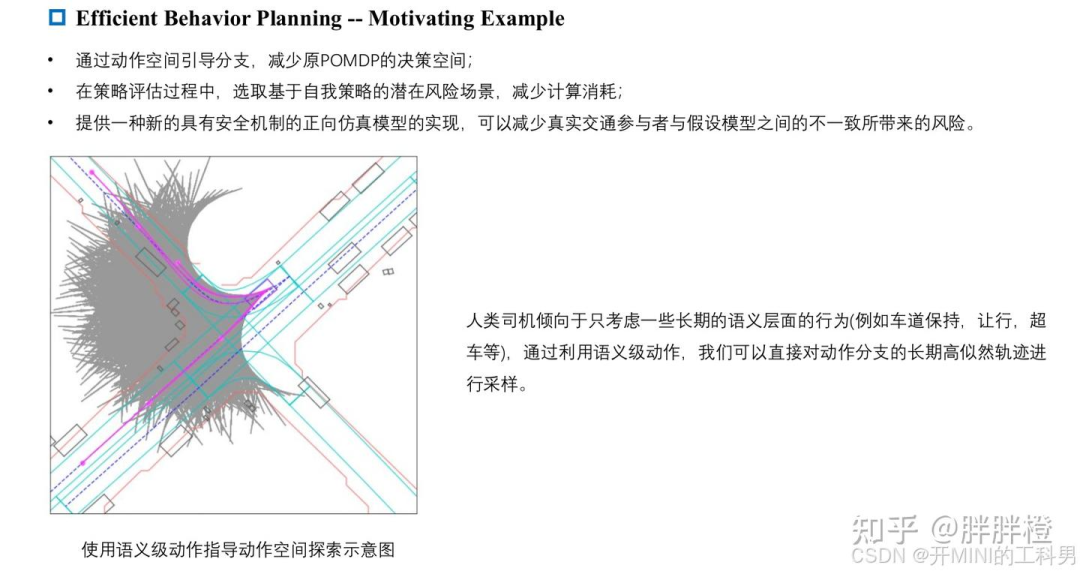
灵活的驾驶策略:通过在动作空间中引导分支,缩小了原始 POMDP 的决策空间。与 MPDM(Multi-Policy Decision-Making)相比,该方法在整个规划范围内考虑了多个未来的决策点,而不是仅使用单一的语义动作,从而实现了更加灵活的运动规划。
高效的策略评估:提出了一种机制,可以根据自车的策略筛选出潜在高风险的场景,而不是直接采样所有可能的交通参与者意图组合(这会导致指数级复杂度),这一机制降低了策略评估过程中的计算开销。
增强的实际交通风险处理:提出供一种新的带有安全机制的新前向仿真模型,能够减少真实交通参与者行为与假设模型之间不一致所带来的风险。
B. Guided Action Branching 动作引导分支
该部分借鉴MPDM的思想(参考第二部分),使用语义级策略,而不是传统的“状态”级别的动作(例如离散化的加速度或速度)。通过使用语义级策略,状态空间的探索由简单的闭环控制器(即领域知识)引导。同时对于MPDM的存在的问题进行了改进。
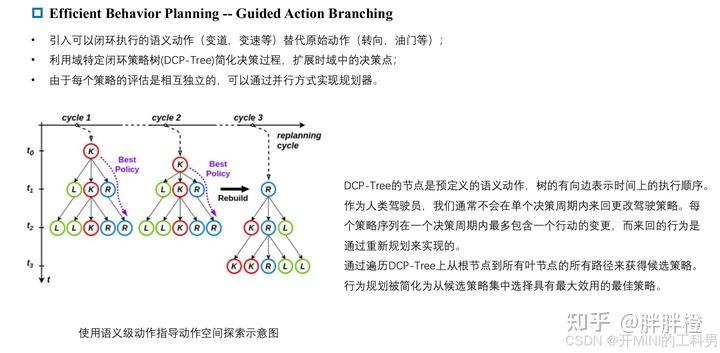
将行为规划器的策略π 定义为一个逐个执行的语义级动作序列。一旦建立了dcp Tree,就确定了自车的整个决策空间。通过遍历DCP-Tree上从根节点到所有叶节点的所有路径,可以获得候选策略。因此,行为规划被简化为从候选策略集中选择效用最大的最佳策略。由于每个策略的评估是相互独立的, 我们可以以并行方式实现规划器,而不需要额外的工作。
引入可以闭环执行的语义
在ESPILON中,预测时域为5s,每1s预测一个行为,纵向可能的行为有保持Maintain(M),加速Accelerate(A),减速Decelerate(D),横向可能的行为有车道保持LaneKeeping(K),向左换道LaneChangeLeft(L),向右换道LaneChangeRight(R)。
利用DCP Tree简化决策过程,扩展时域中的决策点
DCP-Tree的结点是预定义的语义动作,与一定的时间间隔相关联,树的有向边表示时间上的执行顺序。
每当进入一个新的规划周期时,通过将当前正在执行的动作设置为根节点来重新构建DCP-Tree,每个策略序列在一个计划周期内最多包含一个行动的变更。
假设有三个离散的语义级别动作 {K, L, R},分别表示“保持车道”(Keep Lane)、“变道到左车道”(Left Lane Change)和“变道到右车道”(Right Lane Change)。
对于左侧和中间的树,当前执行的动作为 K “保持车道”,最优策略为虚线紫色路径,K-R-R,在执行完 K 后,当前执行的动作切换为 R,,因为每条路径中仅包含一次动作变化,所以DCP-Tree 随之更新为右侧的树。

3.策略评估相互独立
假设当前DCP-Tree的有效行为序列个数为n,则创建n个线程,每个线程针对一条行为序列进行前向仿真。从候选策略集中选取最佳策略。
C. Guided Observation Branching 观测引导分支
在决策过程中处理多智能体交互时,系统必须对可能的未来情景进行预测,这通常涉及到大量的观测值(如其他车辆的位置、速度、意图等)。为了高效地评估这些情景,Guided Observation Branching 机制被引入,通过引导观测空间的分支,结合自车的决策策略,减少无关场景的计算,从而提高了多智能体交互中自动驾驶决策的效率与准确性。
基于自车策略的观测空间引导:自车策略的选择会影响到系统对周围车辆行为的预测,系统通过观察自车当前策略,选择与其最相关的观测空间进行评估。例如,当自车计划进行左变道时,系统会优先关注左车道上其他车辆的意图和轨迹,忽略右车道上的不相关车辆,从而减少计算量。
条件化聚焦分支 (Conditional Focused Branching, CFB):通过 条件化(即基于自车的决策)来引导选择相关的关键场景,避免了全局范围内的繁琐搜索。CFB 机制可以有效减少需要评估的场景数量,只关注与当前自车行为相关的动态变化。
从开环模拟到闭环仿真:
开环模拟:首先生成所有可能的轨迹和场景,然后筛选出潜在风险的情景。闭环仿真:对筛选出来的关键情景进行详细的闭环仿真,确保策略的安全性和可行性。CFB机制的示意图
开环仿真(Open-loop Simulation),为所有交通参与者(包括自车)计算出所有可能的未来轨迹,根据模拟轨迹,判断是否存在潜在的风险。对C1、C2车辆进行各个意图下的开环仿真,左右变道、直行轨迹。
根据风险等级筛选出Critical Agent,C1,展开不同的意图组合 LK、LCR,进行闭环仿真。
对于低风险车辆,选择最大概率的意图行为进行仿真。比如C2车辆在模拟中主要表现为直行,则无需展开其他意图,只选择最有可能的行为。
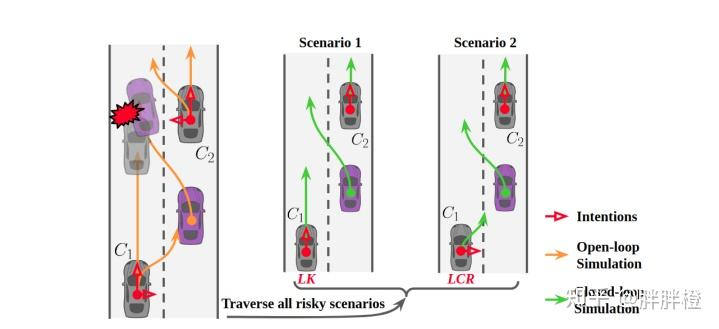
考虑到自车(紫色)计划进行左变道的情况。我们使用开放式模拟来获取所有交通参与者的所有可能未来轨迹。然后,对于每个周围的交通参与者,我们检查模拟轨迹是否会存在潜在的风险。对于关键车辆(C1),我们展开所有可能意图的组合;而对于低风险车辆(C2),我们直接采用最大概率的意图。因此,策略评估转化为对这两种场景的评估。Illustration of the CFB mechanism. Considering a case that the ego vehicle (purple) is considering a left lane-change. We use the open-loop simulation to get all possible future trajectories for all agents. Then, for each surrounding agent, we check whether there would be potential risks according to the simulated trajectories. For the critical agent (C 1 ), we unfold all combinations of the possible intentions, and for the vehicle with low risk (C 2 ), we directly employ the intention with maximum probability. As a result, the policy evaluation turns into an evaluation of the two scenarios. Interested readers may refer to [21] for more details.
D. Multi-agent Forward Simulation
通过前向仿真实现的场景的生成,该仿真以交互方式同时推进环境中的所有智能体。在多智能体的前向传播过程中,自车和其他智能体的所有轨迹都会被生成。

主要包括以下:
将预测耦合到行为规划中,每个潜在的规划所考虑的场景有它自己相对应的未来预期;当预测与规划解耦时,很难准确考虑自车未来运动对其他智能体的影响。
使用情境感知控制器控制自车,使用基于模型的控制器控制其他交通参与者(IDM 速度控制、Pure Pursuit 转向控制);
通过引入新控制器,解决空间得以扩大,生成的决策能够更灵活地适应交通环境。
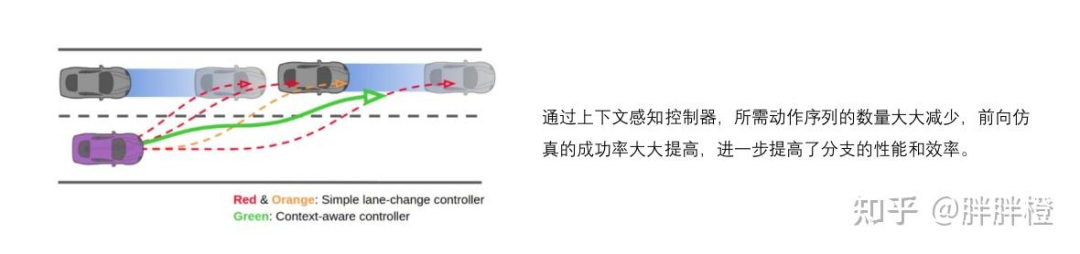
E. Safety Mechanism
安全机制主要在应用在以下三个方面:
环境感知控制器中嵌入安全模块,在一定程度上自动保证控制输出安全,提高前向仿真模型的安全性;
责任与安全方面,利用责任敏感安全数学模型(RSS 模型);
在策略选择中设置安全准则,增强决策层的鲁棒性;
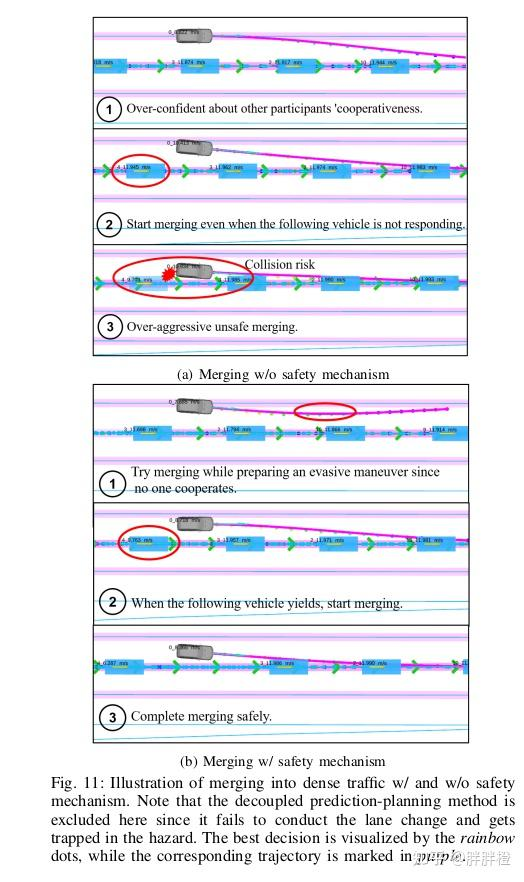
(a)没有安全机制的并入
过于自信于其他参与者的合作性:在没有足够的反应时,车辆依赖于过度的自信,误判了其他车辆的反应。
即使后方车辆没有响应,仍然开始并入:在没有其他车辆让行的情况下,车辆开始并入,存在碰撞风险。
过于激进、不安全的并入:在没有充分评估危险的情况下,车辆以过于激进的方式进行并入,可能导致不安全的行为。
(b)带安全机制的并入
尝试并入,同时准备规避操作,因为无人合作:车辆在没有合作的情况下准备进行规避操作,同时尝试并入。
当后方车辆让行时,开始并入:车辆识别到后方车辆让行后,安全开始并入。
安全完成并入:通过合适的规划,车辆能够安全完成并入操作。
补充:Mobileye的责任敏感安全(RSS)模型
Mobileye RSS | Responsibility-Sensitive Safety - A Model for Safe Autonomous Driving
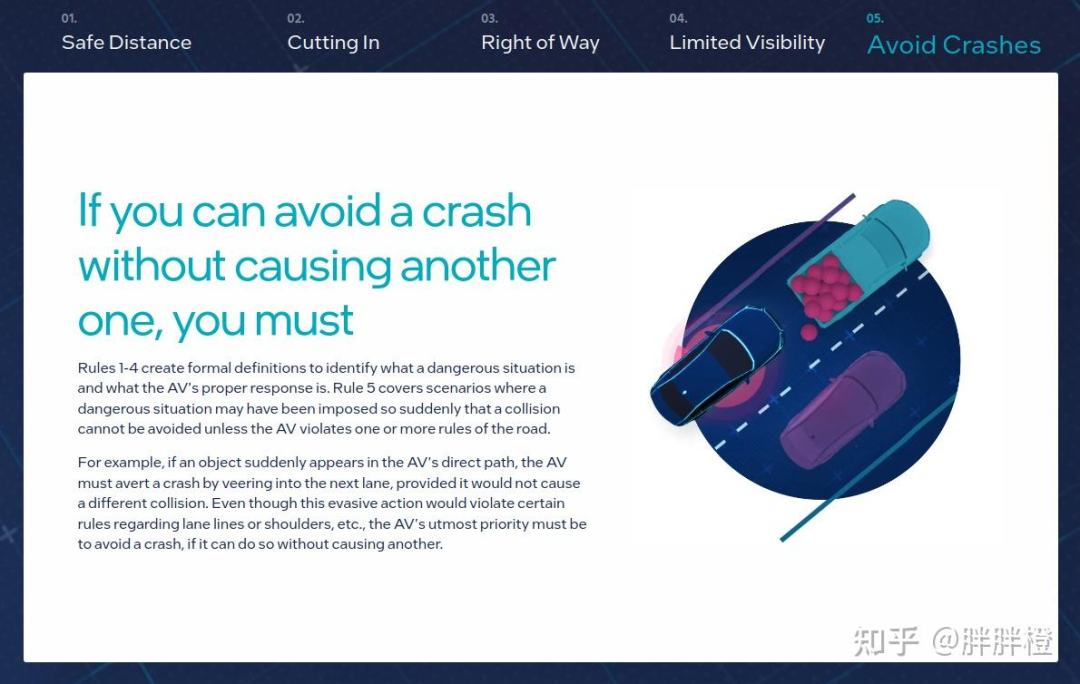
RSS 根据人类驾驶的常识建立了五个安全原则,针对不同的驾驶场景,根据五个安全原则会推导出具体的数学公式,通过这种方式保障自动驾驶汽车的安全。
避免碰撞前面的车
保持横向安全距离
合理使用路权
注意视觉盲区
避免事故发生是首要任务




F. Policy Selection
通过在动作空间和观测空间进行引导分支,并对状态转移和观测进行近似,将行为规划问题简化为有限数量的策略评估问题。
对于每个策略,通过评估规划行为和模拟轨迹来计算每个场景的奖励加权和,奖励函数由效率、安全、导航三部分组成。
行为规划的主要流程:通过 DCP-Tree 和 CFB 机制进行场景选择与策略评估,最终通过选择最优策略和动作来完成规划。具体如下:
每个策略序列的评估可以并行进行(第 5 行到第 11 行);
由 CFB 选择的每个关键场景通过闭环前向仿真(第 8 行到第 10 行)并行进行检查,并且每个策略使用奖励函数进行评估(第 11 行);
最终选择最佳策略(第 13 行);

与MPDM 对比
多策略决策(MPDM) 对一组有限离散的语义级策略(例如,变道(LC)、保持车道(LK)等)进行确定性的闭环前向仿真,适用于受控(自车)和其他交通参与者,而不是对每辆车的每个可能控制输入进行评估。然而,所有参与者的语义行为在整个规划范围内被假设为固定的,这在长期决策中可能并不成立。此外,如果初始行为预测不准确,风险可能会被低估,这可能导致不安全的决策.
It is essential to incorporate domain knowledge to effi- ciently make robust decisions. Multipolicy decision-making (MPDM) [14]–[16] conducts deterministic closed-loop for- ward simulation of a finite discrete set of semantic-level policies (e.g., lane change (LC), lane keeping (LK), etc.) for the controlled (ego) vehicle and other agents, rather than performing the evaluation for every possible control input for every vehicle. However, the semantic behaviors for all the agents are assumed to be fixed in the whole planning horizon, which may not be true in long-term decision-making. More- over, risk can be underestimated if initial behavior prediction is inaccurate [17, 18], which may lead to unsafe decisions.
MPDM的主要存在的问题:
对本车行为的采样单一,一次时间序列的采样中只有一个动作,无法表示先直行后变道的连续变化动作。
时间序列过程中没有交互,特别在起始状态下预测有偏差的时候,这个不交互的假设还是有风险的。
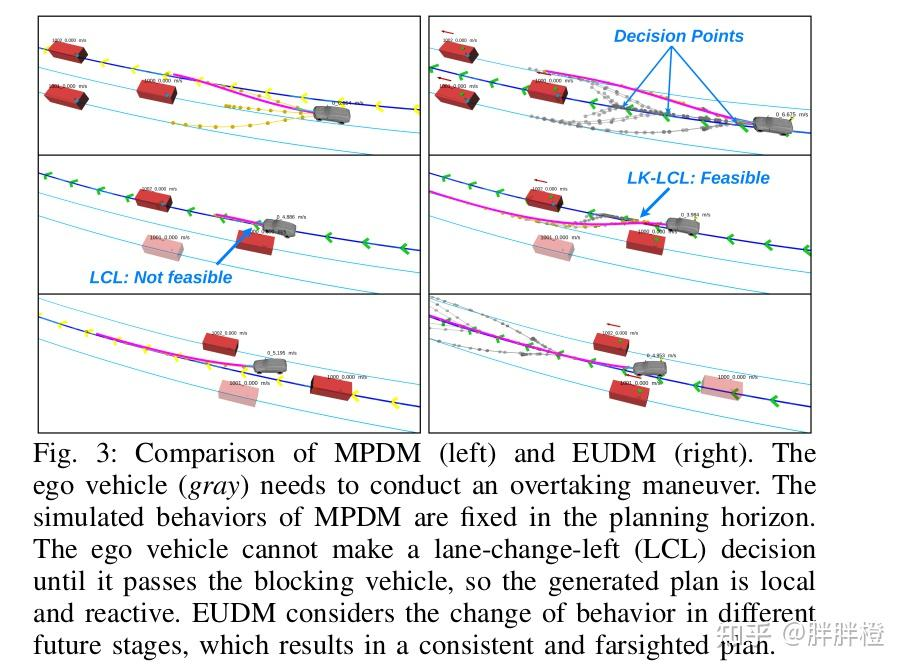
在 MPDM 中,自车需要超车,但由于其决策空间在整个规划范围内是固定的,自车必须等待直到通过阻挡车辆(红车),才可以进行左变道(LCL)。
EUDM 能够考虑在不同阶段变化的行为,通过 DCP-Tree 动态规划生成自车的决策,使得规划既具有远见性,又能根据实时环境做出调整。自车可以在适当的决策点执行左变道(LCL),并灵活调整行为策略。当自车通过当前决策点时,左变道变得可行,规划具有一致性。
EUDM 效果
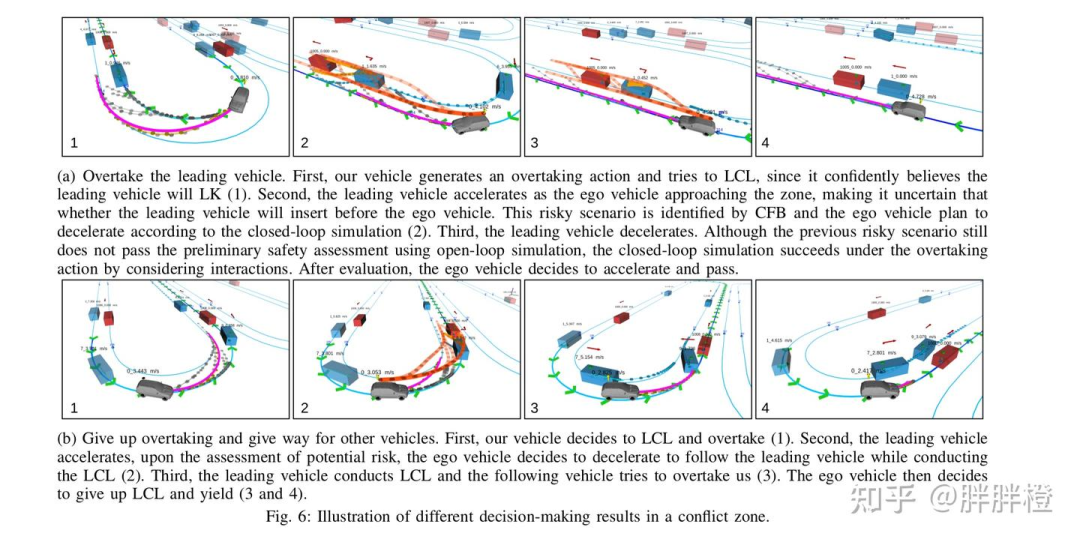
(a)超车前方车辆
决策:首先,自车生成超车动作,并尝试进行左变道(LCL),因为自车自信地认为前方车辆将保持车道(LK)。
前车加速:接着,随着自车接近超车区,前方车辆加速,使得自车不确定是否能够超车。通过 CFB 机制识别这个风险场景,并让自车计划减速。
前车减速:第三,前方车辆减速,尽管前面的风险场景未通过初步安全评估,但通过闭环仿真,超车动作成功。
评估结果:经过评估后,自车决定加速并超车。
(b)放弃超车,给其他车辆让行
决策:首先,自车决定进行左变道并超车,但在评估潜在风险后,自车决定减速并跟随前车。
前车的反应:接着,前方车辆执行左变道,而后方车辆尝试超车。
调整策略:最后,自车决定放弃左变道并让行,避免发生冲突。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









