




 本文深入探讨了聚类分析的基本概念和重要用途,特别是在精细化运营和个性化服务中的作用。文章列举了五种聚类方法,包括划分法、层次法、基于密度的方法、基于网格的方法和基于模型的方法,并重点介绍了K-Means和高斯混合模型(GMM)算法。K-Means通过迭代优化聚类中心,而GMM利用混合高斯分布对数据建模。此外,文章还讨论了如何选择合适的K值,并给出了聚类算法在文档分类、犯罪分析、客户细分等多个领域的应用实例。
本文深入探讨了聚类分析的基本概念和重要用途,特别是在精细化运营和个性化服务中的作用。文章列举了五种聚类方法,包括划分法、层次法、基于密度的方法、基于网格的方法和基于模型的方法,并重点介绍了K-Means和高斯混合模型(GMM)算法。K-Means通过迭代优化聚类中心,而GMM利用混合高斯分布对数据建模。此外,文章还讨论了如何选择合适的K值,并给出了聚类算法在文档分类、犯罪分析、客户细分等多个领域的应用实例。
关注“金科应用研院”,回复“优快云”
领取“风控资料合集”
聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。
聚类分析的一个重要用途就是针对目标群体进行多指标的群体划分。对目标群体的分类是为了精细化经营,个性化运营的基础和核心,只有进行了正确的分类,才可以有效进行个性化和精细化的运营,服务及产品支持等。
聚类分析的算法可以分为五类:划分方法、层次方法、基于密度方法、基于网格方法和基于模型方法。以下是常用聚类算法分类图:
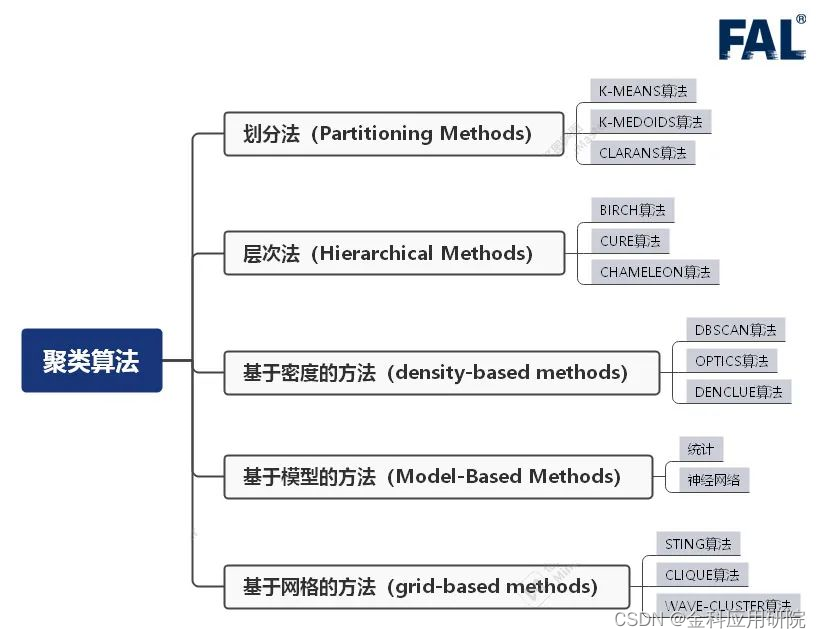
一、划分法
原理:首先要确定一堆散点最后聚成几类,然后挑选几个点作为初始中心点,再然后依据预先定好的启发式算法给数据点做迭代重置,直到最后到达“类内的点都足够近,类间的点都足够远”的目标效果。
K-MEANS算法
是一种典型的划分聚类算法,它用一个聚类的中心来代表一个簇,即在迭代过程中选择的聚点不一K-MEANS定是聚类中的一个点,该算法只能处理数值型数据
K-MEDOIDS算法
K-MEDOIDS是以集群点中最中心(中位数)的对象为参考进行聚类
CLARANS算法
CLARANS是分割方法中基于随机搜索的大型应用聚类算法。在分割方法中最早提出的一些算法大多对小数据集合非常有效,但对大的数据集合没有良好的可伸缩性。

以K-MEANS算法为例:
K-MEANS算法流程:
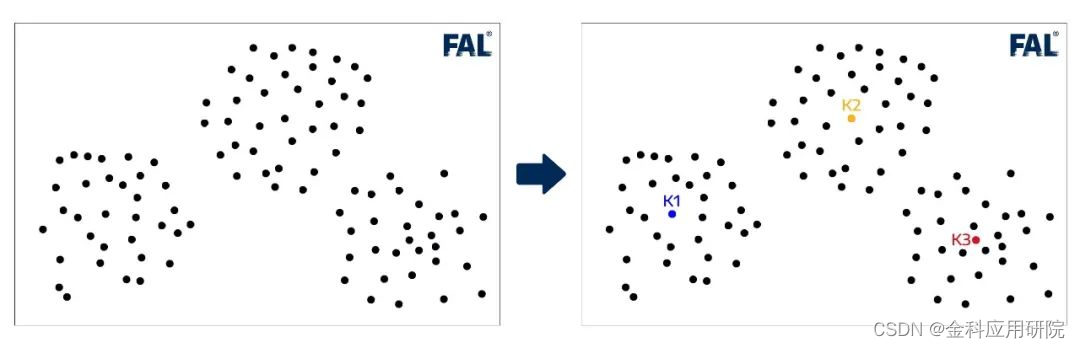
(1)假如S区域有100个客户,1个黑点表示1个客户;我想在S区域开3家奶茶店,那我就随机在地图上选择3个开店位置,三家奶茶店可以分别表示为K1,K2,K3;
如图所示:
为了更快捷的给100个客户配送奶茶,奶茶店必须开在中心位置,每家奶茶店的初始地代表了一个的中心位置;对剩余的客户,根据其与奶茶店中心的距离,将客户分配给最近的奶茶店管理配送;
如图所示:
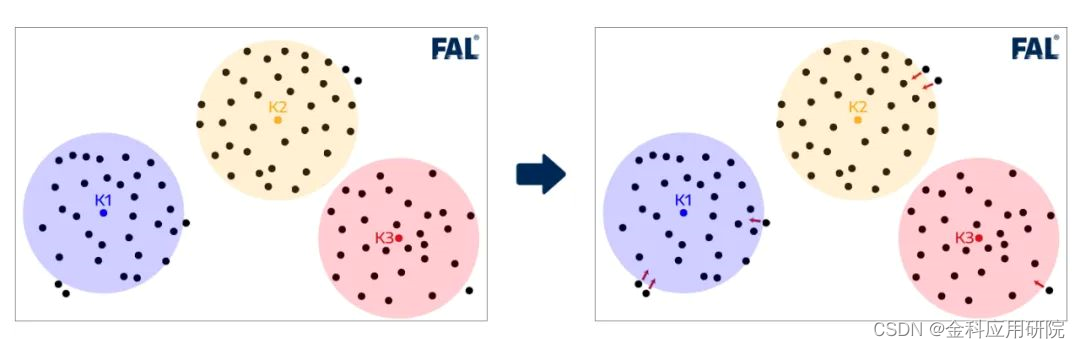
(3)重新计算每个客户距离奶茶店的平均值,更新为新的中心点,即奶茶店的位置;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4841
4841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









