




CVPR 2025 | Alias-Free LDM: 从本质上提升潜扩散模型生成稳定性
潜扩散模型 (Latent Diffusion Models, LDM) 常因生成过程不稳定而备受诟病:哪怕模型的输入只是受到了一点微小的扰动,模型的最终输出也会截然不同。以视频逐帧风格化任务为例,哪怕对每帧使用同样的 Stable Diffusion ControlNet 图生图编辑方法,同样的随机种子,生成的风格化视频会有明显的闪烁现象。
为了找出这一现象的原因,我们设计了一种配置简单的扩散模型编辑实验:平移扩散模型的初始噪声,观察去噪输出。理想情况下,平移输入噪声,输出图片也应该会平滑地平移。然而,实验结果却显示,直接平移输入噪声会大幅改变输出图片;使用了提升内容一致性的 Cross-frame Attention (CFA) 技术后,虽然图片的主体内容不再变化,可是输出图像在平移时还是有不自然的「抖动」现象。
为什么 LDM 的生成过程这么不稳定呢?为什么 CFA 技术又能提升生成的一致性呢?在我们团队近期发表于 CVPR 2025 的论文 Alias-Free Latent Diffusion Models: sImproving Fractional Shift Equivariance of Diffusion Latent Space 中,我们从平移同变性 (shift equivariance) 的角度分析了 LDM 的生成稳定性,并提出了一种能够提升平移同变性的 Alias-Free LDM (AF-LDM) 模型。我们在无约束人脸生成、视频编辑、超分辨率、法向量估计等多个任务上验证了该模型的有效性。

在这篇博文中,我将系统性地介绍一下这篇论文。我会先简单回顾背景知识,让对信号处理不太熟悉的读者也能读懂本文;再介绍论文的方法、实验、贡献;最后从本工作出发,探讨新的科研方向。
项目网站:https://zhouyifan.net/AF-LDM-Page/
背景知识回顾
本节我会先回顾 LDM,再回顾对平移同变性做了深入研究的 StyleGAN3。由于理解 StyleGAN3 需要了解信号处理的基本概念,我会在尽量不用公式的前提下讲清楚图像频率、混叠等概念。为了简化文字,我会省略理论推导,并使用一些易懂却不见得严谨的叙述。对这些原理感兴趣的读者可以系统性地学习一下 StyleGAN3 论文。
潜扩散模型
扩散模型是一种图像生成模型。生成算法的输入是一张纯噪声图,输出是一张清晰图像。算法执行 步,每一步都会调用一个去噪网络来去除图像中的部分噪声。

由于扩散模型运算较慢,我们可以借助一个变分自编码器 (VAE) 来压缩要生成的图像,减少要计算的像素数。简单来讲,VAE 由一个编码器 (encoder) 和一个解码器 (decoder) 组成。编码器负责压缩图像,解码器负责将压缩图像重建。网络的学习目标是让重建图像和输入图像尽可能相似。训练结束后,我们可以单独使用编码器或解码器,实现压缩图像和真实图像之间的相互转换。论文里通常会把压缩图像称为潜图像 (latent image 或者 latent)。
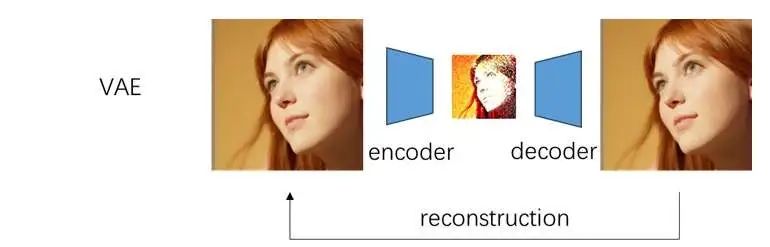
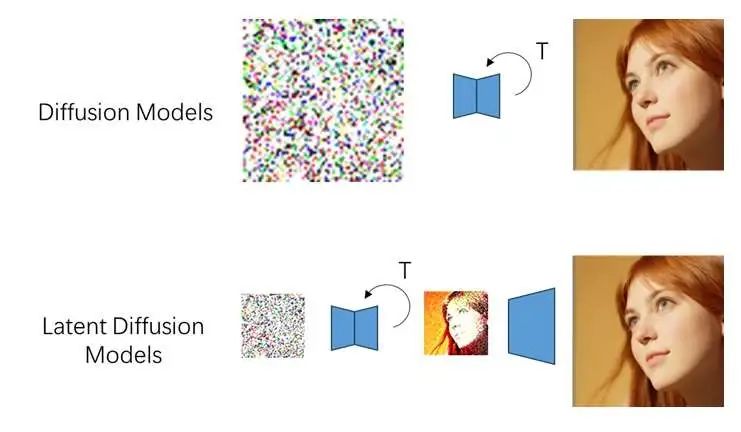
潜扩散模型 (Latent Diffusion Models, LDM) 是一种借助 VAE 加速的两阶段扩散模型。普通的像素级扩散模型会生成一张同样大小的清晰图像。而 LDM 会先生成一张潜图像,再用解码器把潜图像还原成真实图像。我们可以把解码操作简单看成一个特殊的上采样。比如在 Stable Diffusion 中,潜图像的边长被压缩了 8 倍,即解码器会对潜图像上采样 8 倍。
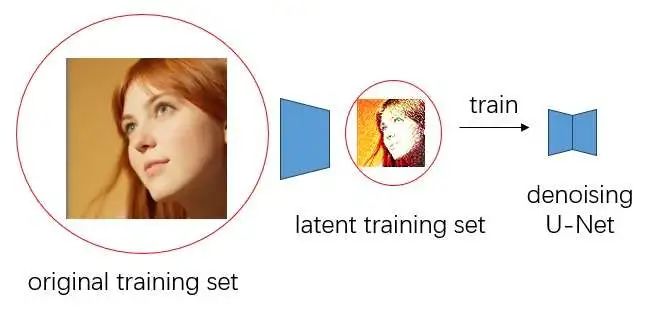
训练 LDM 时,我们需要获取训练图像的潜图像。因此,为了构建训练集,我们会用编码器把训练图像转换为潜空间的图像。
图像的频域表示
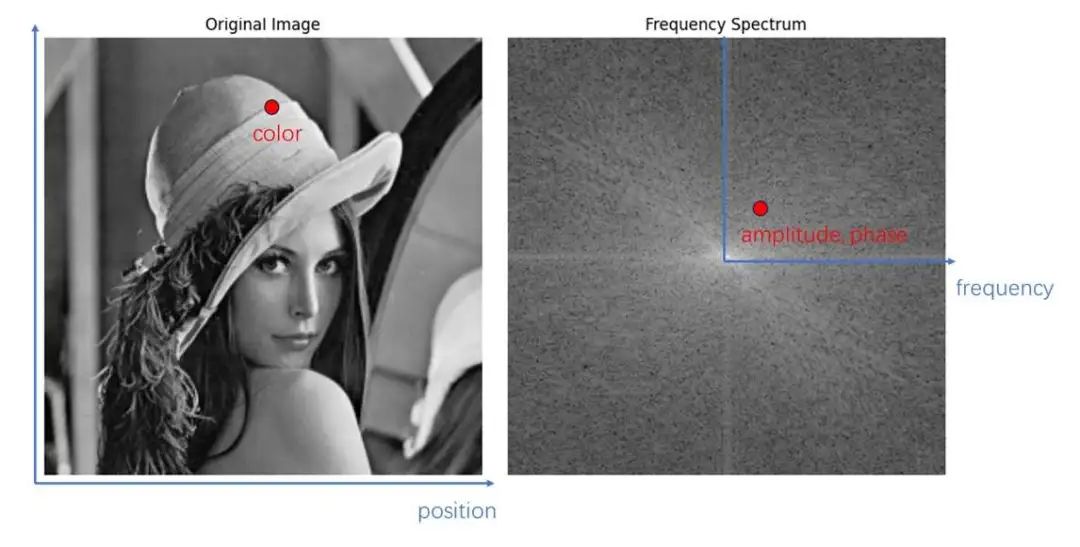
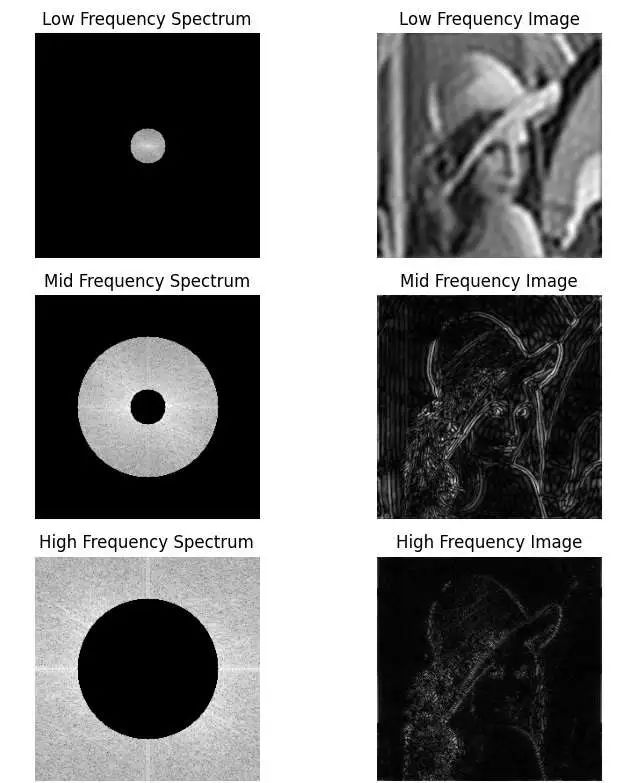
在计算机中,图像有很多种表示形式。最常见的形式是空域图像:图像由一个像素矩阵表示,每个像素存储了图像在某个位置的颜色值。此外,还可以把图像表示为频域图像:我们认为图像是由许多不同频率的正弦函数叠加而成的,频域图像的每个像素存储每个频率的正弦函数的振幅和相位。直观来看,图像在空域和频域的可视化结果如下所示:

具体来说,我们可以把空域图像和频域图像都看成二维数组。对于空域图像来说,数组的索引是二维位置坐标,值是此位置的颜色值;对于频域图像来说,数组的索引是横向和纵向的一对频率,值是该频率下的正弦函数的振幅和相位。
为什么我们要大费周章地在频域里表示一张图像呢?这是因为图像的各个频率分量从另一个维度拆分了图像中的信息,这种拆分方式有助于我们分析图像。一张空域图像可以通过 FFT 操作变换成频域图像,而频域图像又可以通过 IFFT 操作变回空域图像。那么,我们可以用如下操作可视化不同频率分量的作用:
-
把输入空域图像用 FFT 转换到频域
-
对频域图像滤波,分别得到低频、中频、高频三张频域图像
-
用 IFFT 在空域中可视化三张频域图像
该操作的结果如下所示。可以看出,图像的低频分量描述了图像的全局结构,而中频分量和高频分量进一步完善了图像的细节。
混叠
假设有一根时针在顺时针匀速旋转。现在,我每秒拍一次照片,一共拍下了时针的三张照片。请问,时针的旋转速度是每秒多少度呢?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









