




 本文介绍了一种实时图像生成方法,通过模型小型化和单步训练技术,利用知识蒸馏优化VAE和UNet结构,实现在单GPU上高帧率的推理。研究关注于图像条件控制,提出了一种结合特征匹配和分数蒸馏的训练策略,显著减少了模型延迟。
本文介绍了一种实时图像生成方法,通过模型小型化和单步训练技术,利用知识蒸馏优化VAE和UNet结构,实现在单GPU上高帧率的推理。研究关注于图像条件控制,提出了一种结合特征匹配和分数蒸馏的训练策略,显著减少了模型延迟。
SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
sign: 2024-4-28 💡
在看这个文章之前,首先要对 consistency model ,score-based model要有一定了解,以及相应的知识蒸馏,怎样去做单步生成的等等
扩散模型由于其迭代采样过程而导致显著的延迟。为了减轻这些限制,作者引入了一种双重方法,包括 模型小型化 和 减少采样步骤 ,旨在显著降低模型延迟。还是利用知识蒸馏来简化U-Net和图像解码器架构,并引入了一种利用特征匹配和分数蒸馏的创新的单步DM训练技术。
作者提出了两种模型,SDXS-512和SDXS-1024,分别在单个GPU上实现了大约100 FPS(比SD v1.5快30倍)和30 FPS(比SDXL快60倍)的推理速度。此外,我们的训练方法在图像条件控制中提供了有前途的应用,促进了有效的图像到图像的翻译。

1. Introduction
这是一篇小米的工作,实时进行图像到图像的生成。因为是要更多考虑手机的部署,所以要潜在解决的就是模型的大规模和多步骤采样的问题。
首先介绍一下什么是
NFE,即 Number of Function Evaluations,模型评估次数。对于常见的文生图模型,成本可以近似地计算为总延迟,其中包括文本编码器、图像解码器和去噪模型的延迟,乘以函数评估次数(NFEs)。
这里是直观的一个对比:

本文主要考虑减小 VAE解码器 和 UNet 的规模,两者都是资源密集型组件。作者还是通过蒸馏的 Loss 和 GAN Loss 来轻量化。
🤔这应该是和 stability 的那个 Turbo,UFO-Gen 的原理差不多
另外,为了减少 NFEs, 作者提出了一个快速和稳定的训练方法:
- 首先,我们建议通过将蒸馏损失函数替换为所提出的特征匹配损失函数,调整采样轨迹并将多步模型快速微调为一步模型。
- 然后,拓展了 Diff-Instruct 训练策略,利用特征匹配损失的梯度取代分数蒸馏在时间步长的后半部分提供的梯度。
💡 从预训练的扩散模型进行知识蒸馏(分数蒸馏) 都是 来自于 DreamFusion 这篇工作,感兴趣可以看看。
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.
2. Preliiminaries
Score-based Model
所使用的损失函数的核心是分数匹配(SM)损失,其目的是使模型估计的分数与数据的真实分数之间的差异最小化:
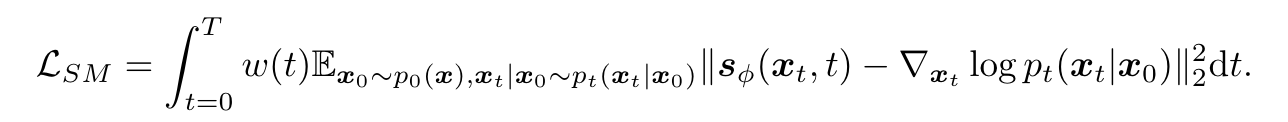
Diff-Instruct
Diff-Instruct 通过 Integral Kullback-Leibler (IKL)散度,将分数蒸馏引入到图像的生成过程,扩散模型其实实在拟合 p , q p, q p,q两个分布之间的差异。这里我们可以定义优化目标为:
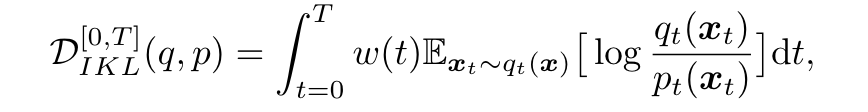
其中 q t q_t qt 和 p t p_t pt 代表 t t t 时刻扩散过程的边缘概率密度, q 0 q_0 q0 和 p 0 p_0 p0 之间的 IKL 梯度可以表示为:
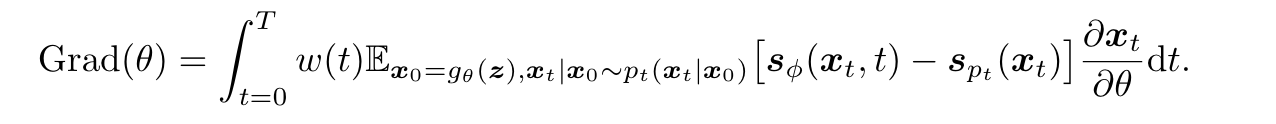
其中 x 0 = g θ ( z ) \boldsymbol{x}_0=g_\theta(\boldsymbol{z}) x0=gθ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









