




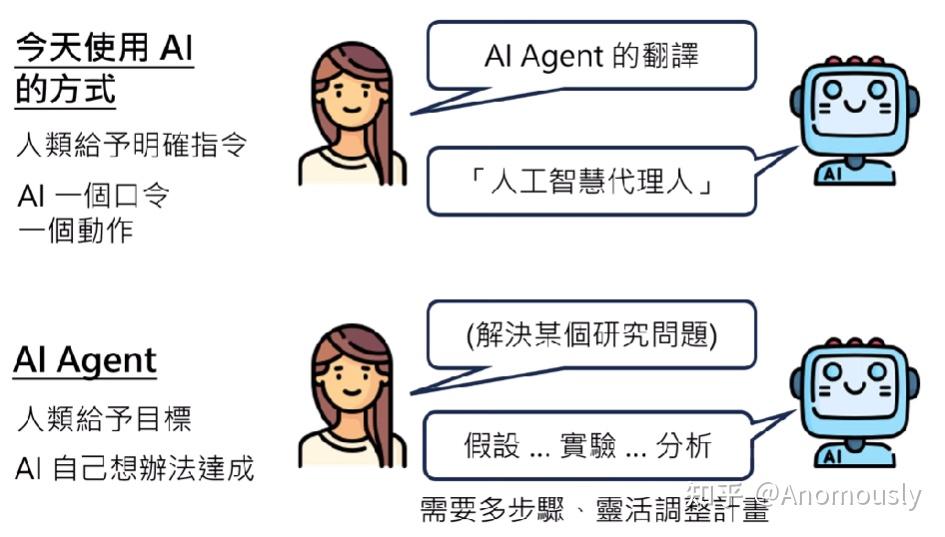
AI Agent:人类不提供明确的行为或步骤的指示,人类只提供明确的目标,至于怎么达成目标。AI自己想办法去达成目标。(而达成的目标是需要多个步骤,与环境做很复杂的互动,才能完成。而环境有许多不可预估的地方,所以AI Agent需要根据环境灵活的调整他的计划。)
AI Agent定义
目前agent没有统一的定义,有人认为有物理实体的机器人才是AI agent,这没问题,李老师的课程将AI agent的定义限定为能自主完成人类目标的AI。
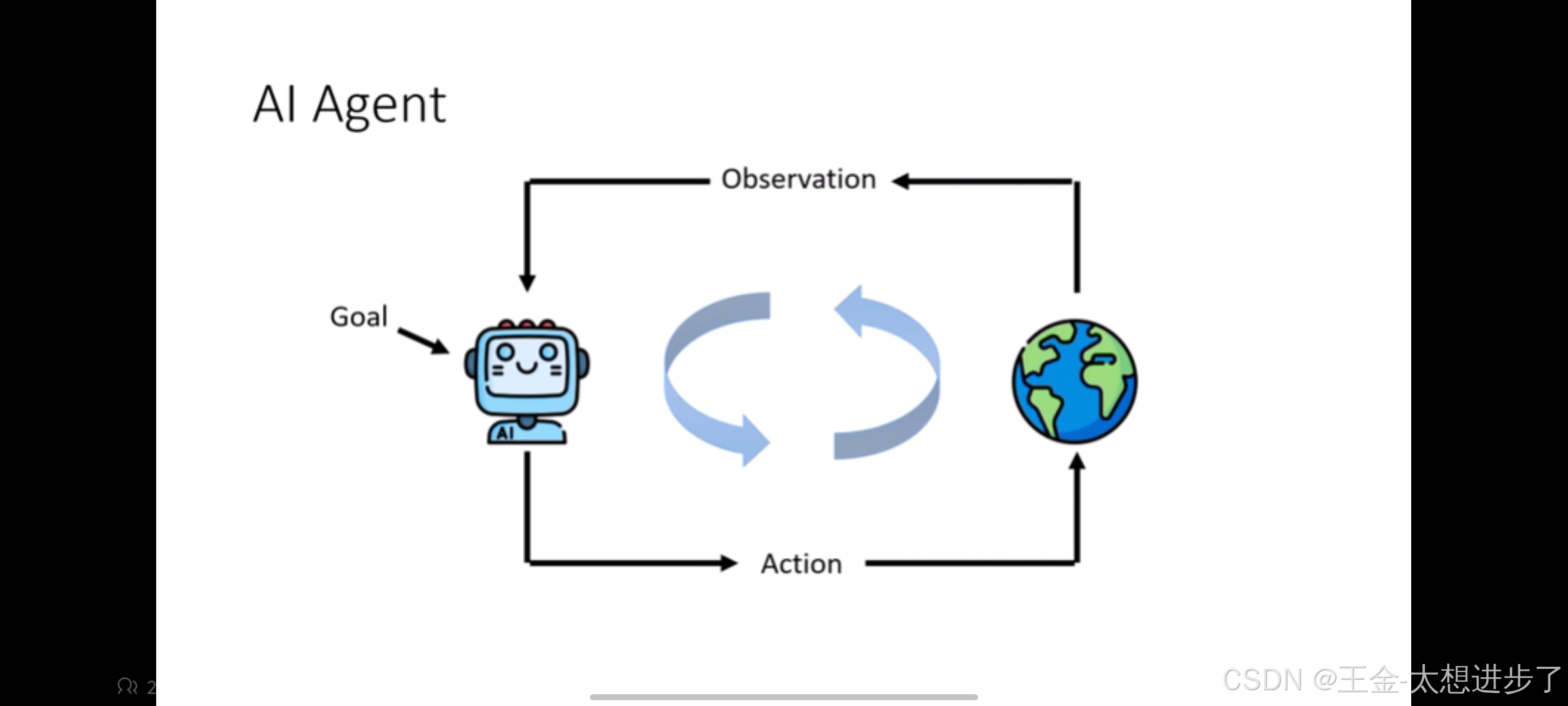
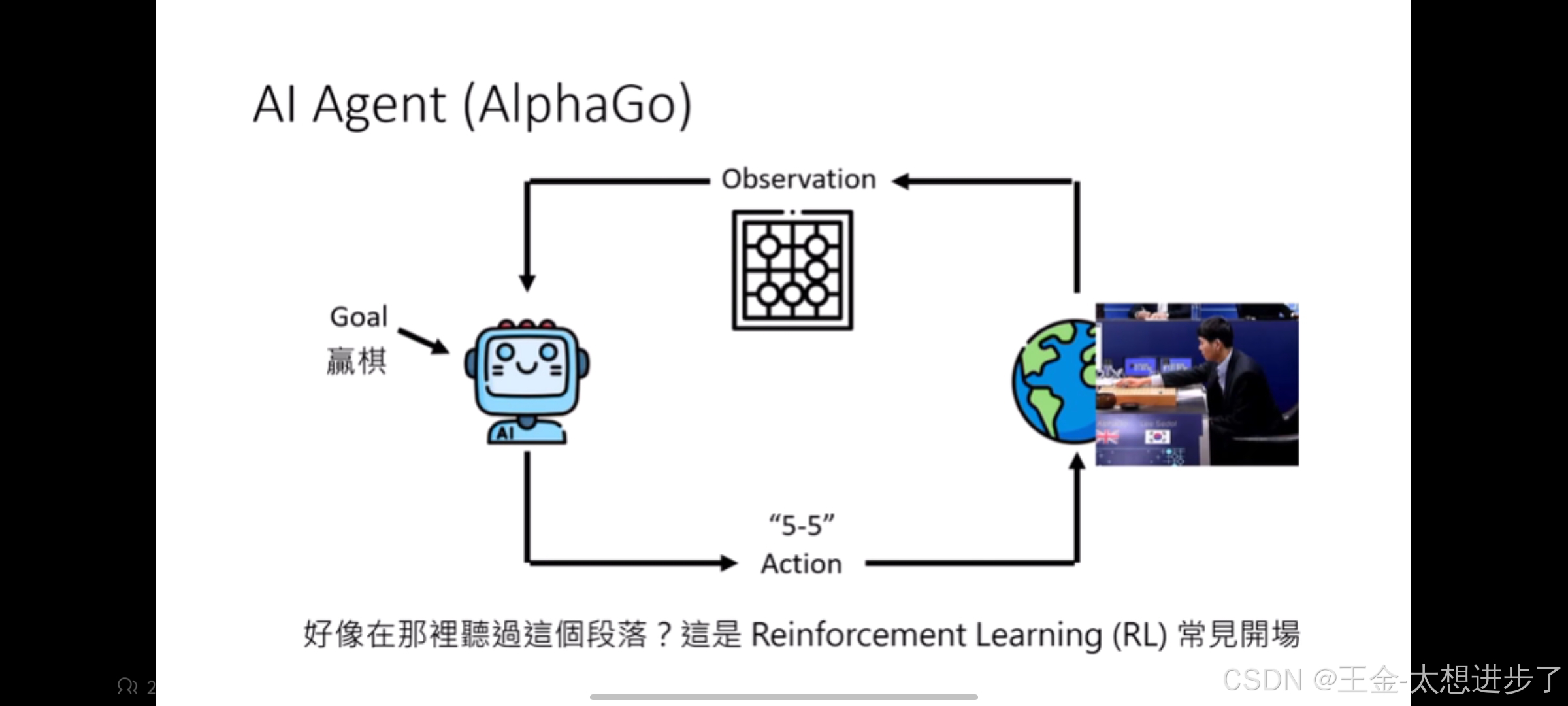
人给一个目标,agent根据环境对目标做出行为,然后环境发生变化,agent再根据环境的变化做出决策,直到结束。举个例子:阿尔法狗
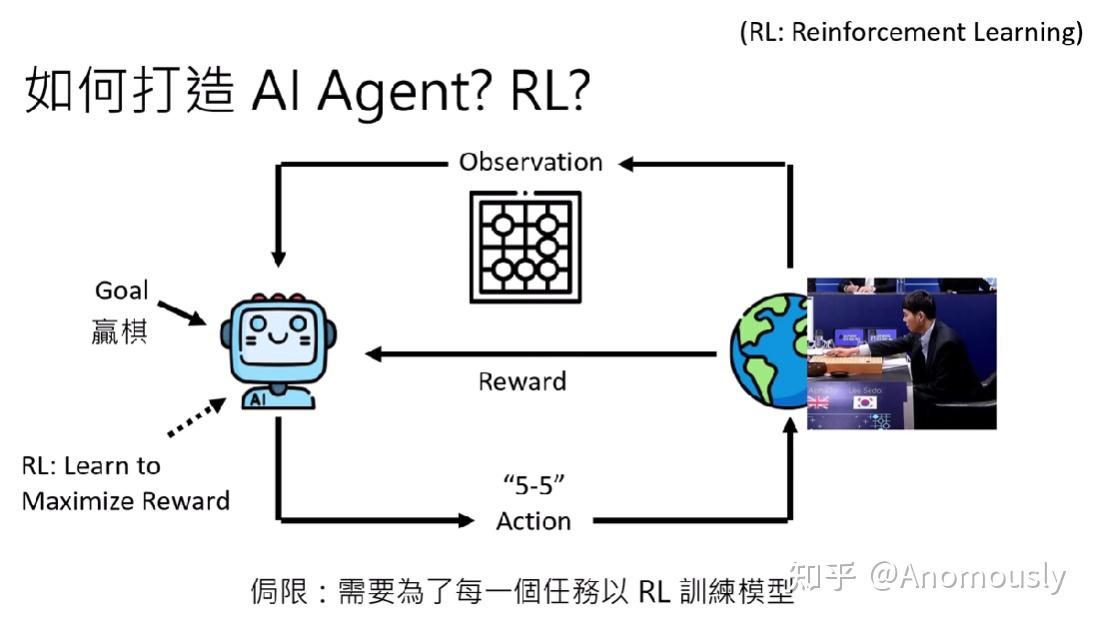
Agent与强化学习
强化学习框架的一个核心就是设计一个reward函数,以实现累积奖励最大化。
过去就是透过RL的演算法打造AI agent。
怎么做呢?RL的演算法就是去learn一个agent,这个agent可以max这个reward,把目标转发为一个reward的东西,目标越接近,reward越大。
但是这种透过RL的演算法打造AI agent有一个局限,需要为每个任务用RL的演算法训练模型。(阿尔法狗只能下围棋,别的棋子不行)。
做别的任务还需要RL的演算法再去训练模型。
人们有了新的想法,所以AI agent又再一次被讨论:把LLM直接当成一个AI agent来使用?
Agent与LLM
LLM时代,直接将LLM设计为agent(agent被讨论,主要是由于LLM变强了,所以有直接将LLM设计为agent这样的想法)
现在多模态LLM可以直接读图,因此下图“以文字描述”变得不那么必要了
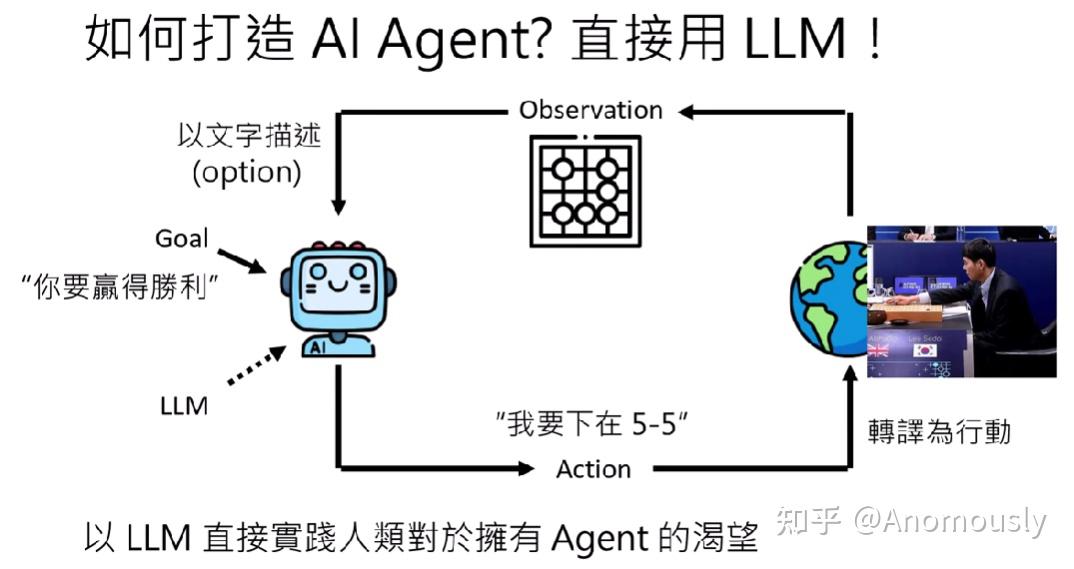
LLM距离理想的agent还差多少?
现在的LLM能不能下棋?
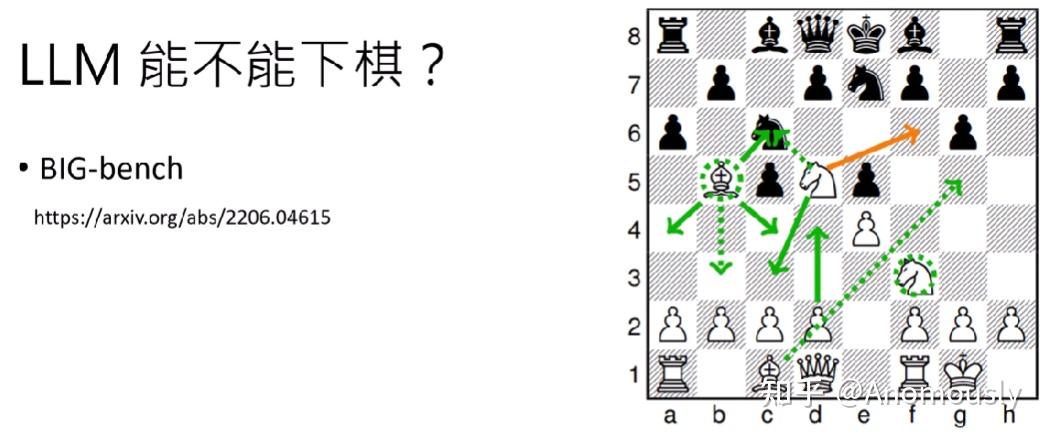
2022年的一个big-bench,LLM之前的语言模型表现地不好(橙色的代表正确答案,绿色的代表当时的大语言模型给出的结论。绿色实线是当时比较强的模型给的答案,因为这符合西洋棋的规则。)
下面这个是现在的大语言模型
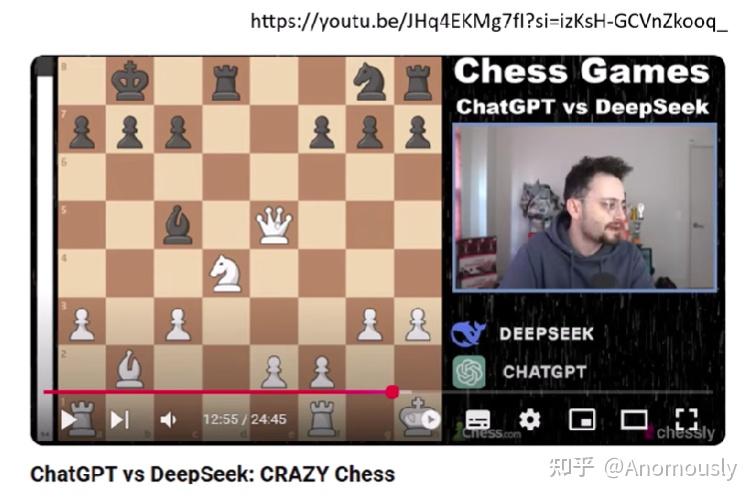
deepseek-r1 vs. chatgpt-o1,离谱对决。有很多不符合西洋棋的规则。最后deepseek赢了
大语言模型距离会下棋 还有一段距离,但可以作为agent做其他的一些事情。
举例:现在的语言模型可有做什么事情?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









