



参考文献
vLLM
一、简介
- 相关链接
- vLLM 官方文档:https://docs.vllm.ai/
- vLLM 中文站:https://vllm.hyper.ai/
- vLLM 论文链接(arxiv):Efficient Memory Management for Large Language Model Serving with PagedAttention, 2023.09
- GitHub 仓库:https://github.com/vllm-project/vllm
- vLLM 是一个由加州大学伯克利分校(UCB)的研究团队研发,专为大语言模型(LLM)高性能推理任务设计的开源框架。它以 PagedAttention 算法为核心,同时整合了一系列先进技术方案,包括:
- 连续批处理 (Continuous Batching)
- 多种模型量化技术,包括 GPTQ、AWQ、INT4、INT8、FP8
- 优化的 CUDA 内核,包括 FlashAttention 和 FlashInfer
- 推测解码 (Speculative Decoding)
- 分块预填充 (Chunked Prefill)
- 对 HuggingFace 模型的无缝支持
- 面向多种解码场景(如并行解码、beam search 等)的高吞吐量服务
- TP/PP/DP/EP 分布式部署架构
- 流式输出 (Streaming Outputs)
- 兼容 OpenAI API server
- 基于哈希查找的自动前缀缓存 (Automatic Prefix Caching)
- 支持 Multi-LoRA
- 等,显著提升了模型推理的吞吐量和内存使用效率,特别适合高并发、低延迟的应用场景
- 如无特殊强调,下文中的“内存”均指显卡内存,即显存
二、论文笔记
摘要总结
- 问题:现有的 LLM 推理框架(如 FasterTransformer、Orca)在批处理请求时,由于每个请求的 KV cache 都要占用大量内存且存在动态变化,如果不能有效管理内存,容易出现内存碎片和冗余拷贝,严重限制系统吞吐量
- 解决方案:
- vLLM 提出 PagedAttention:这是一种受到操作系统中虚拟内存和分页技术启发的 attention 工程实现方案,它将内存空间划分为更小的块,称为“block”,从而实现 KV cache 的非连续存储和按需分配,有效消除了内存碎片
- 在此基础上,构建了 vLLM,一个面向大语言模型的服务系统,其关键优势包括:
- 实现了接近零浪费的 KV cache 内存管理
- 支持在请求内部和跨请求之间灵活共享 KV cache,进一步减少内存占用
- 实验结果:实验表明,vLLM 和现有的 LLM 推理框架相比,在相同延迟水平下,能实现 2-4x 的吞吐量提升,尤其在处理长序列、大模型或复杂解码问题时,vLLM 的优势更为明显
方案细节
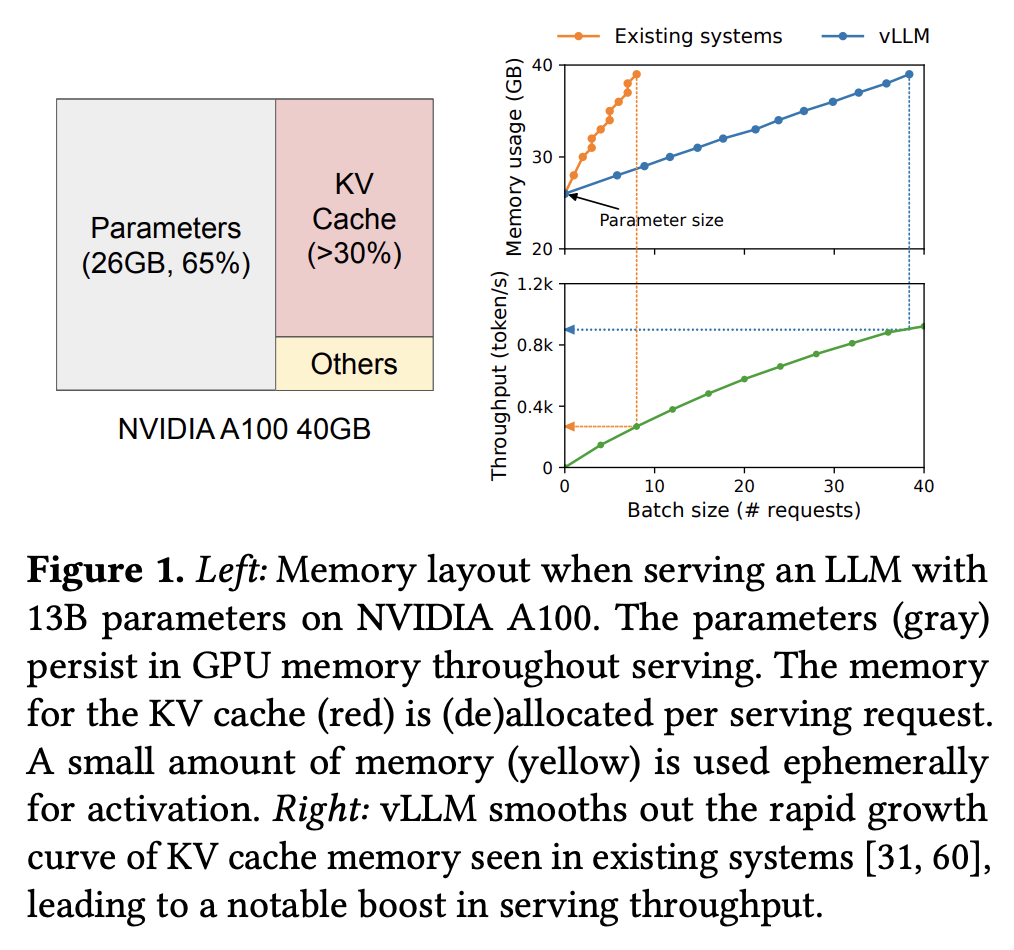
- 下图展示了将一个 13B 语言模型部署到 NVIDIA A100 40G 显卡上时的内存分配情况,其中模型权重在内存中占比 ~65%,这部分占用在整个服务过程中保持不变;余下的大部分内存空间(~30%)都用于保存每个请求的中间状态,即 KV cache,因此 KV cache 的管理方式对于决定最大的批处理大小至关重要
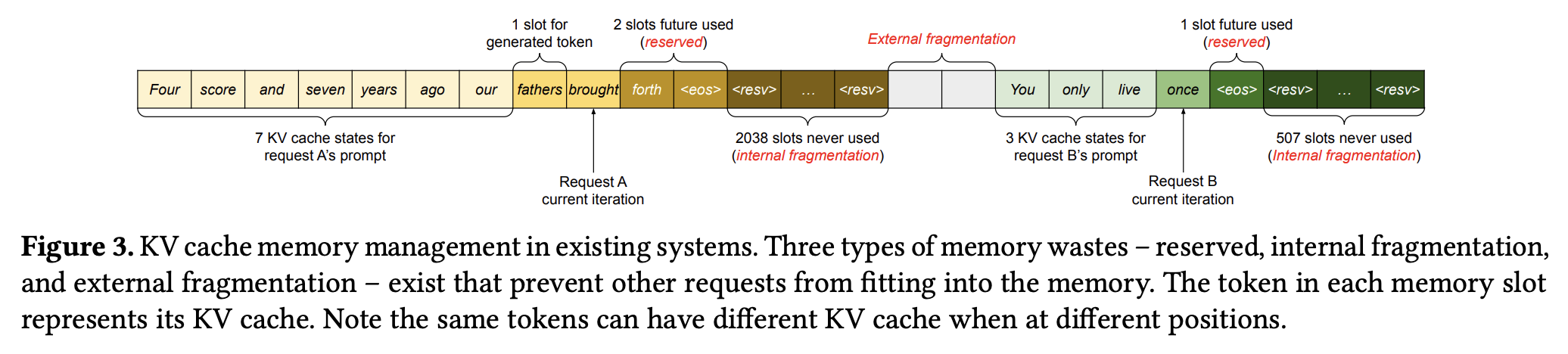
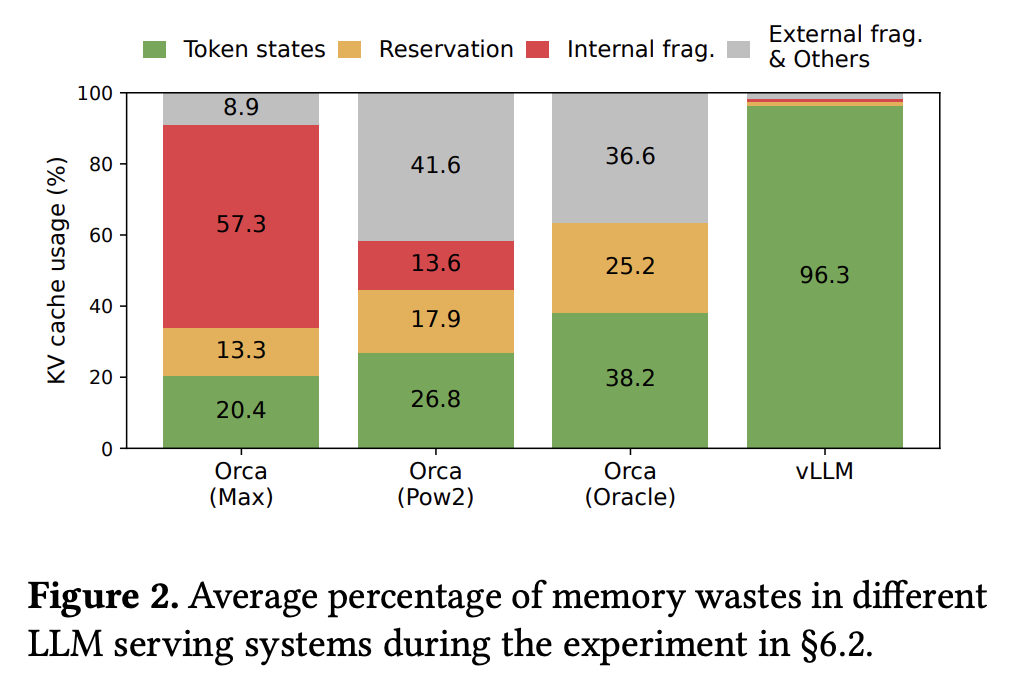
- 现有的 LLM 推理框架可能会产生以下三种内存浪费:
- reserved:系统为每个请求的未来 token 预留的内存空间中最终会被占用的部分
- internal:系统按照可能的最大序列长度为每个请求的未来 token 预留的内存空间中最终未被占用的部分
- external:由于内存分配器(如 Buddy Allocator)的问题产生的内存碎片
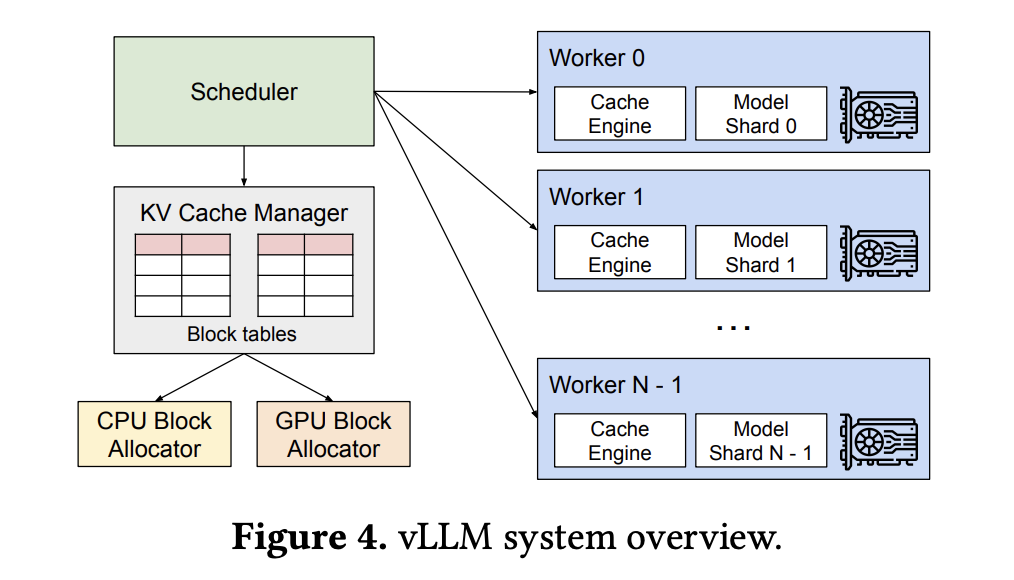
- 下图展示了 vLLM 的整体架构,vLLM 采用一个中心调度器来统一协调分布式 GPU 进程,它的后端包含一个基于 PagedAttention 原理实现的 KV cache manager,负责对物理内存的管理和分配
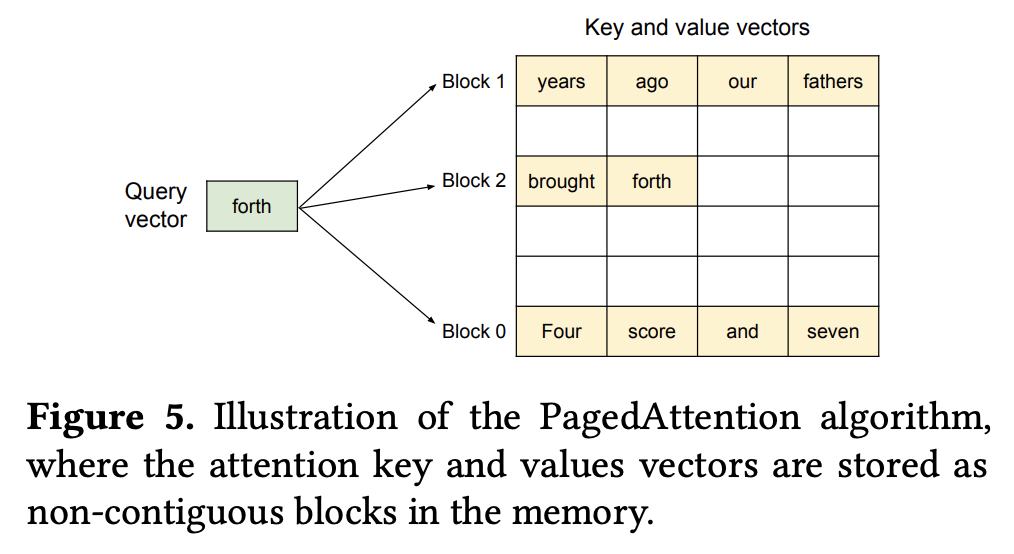
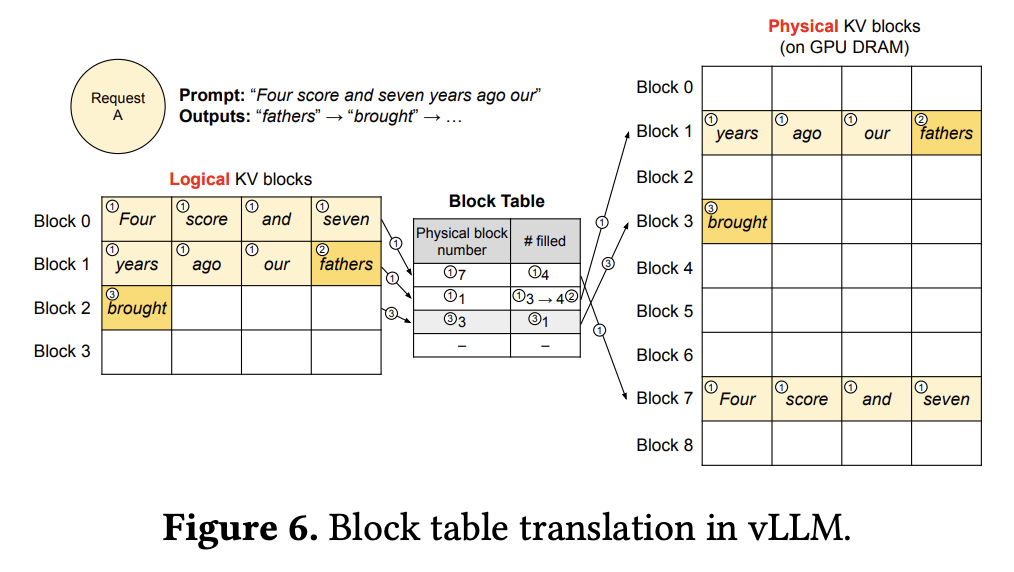
- PagedAttention:PagedAttention 允许在非连续的内存空间中保存连续的 KV cache,具体来说,它将每个序列的 KV cache 划分为包含固定数量 token 的 KV blocks。KV cache manager 负责将这些 block 分配到非连续的物理内存中,并通过 block table 记录从逻辑 block 到物理 block 的映射,以供执行器调用。通过这种方法,PagedAttention 不需要在序列初始化时为可能的最大序列长度预留内存空间,它只保留必要的 block,从而消除了现有系统中大部分的内存浪费
- 下图展示了 block table 的工作原理,它通过记录逻辑 block 对应的物理 block 位置和该 block 已被填充的长度来管理 KV cache
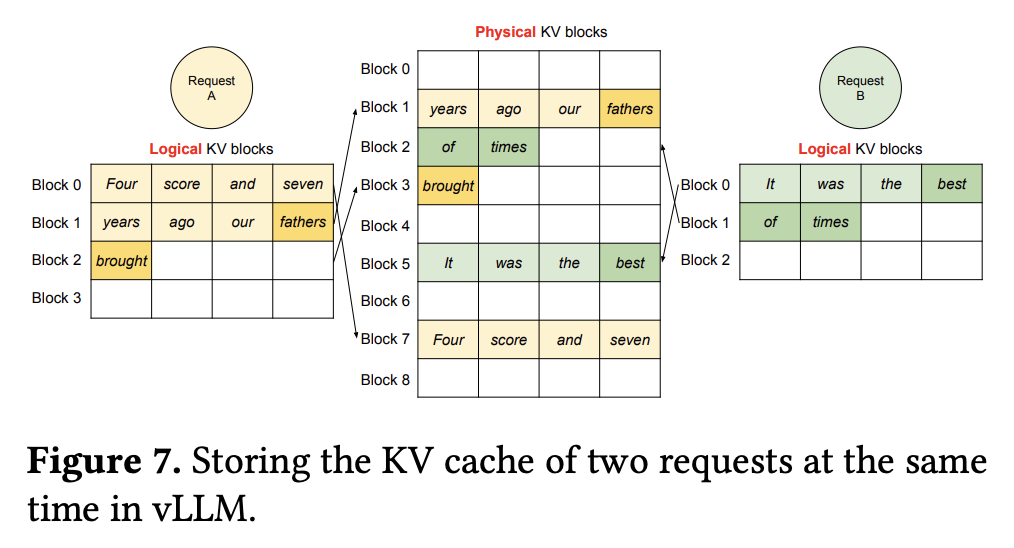
- 下图展示了 KV cache manager 管理多个请求的方式,其中不同的请求不会在同一个 block 内部共享空间
- 论文介绍了 vLLM 在三个复杂解码场景中的应用:Parallel Sampling、Beam Search 和 Shared Prefix
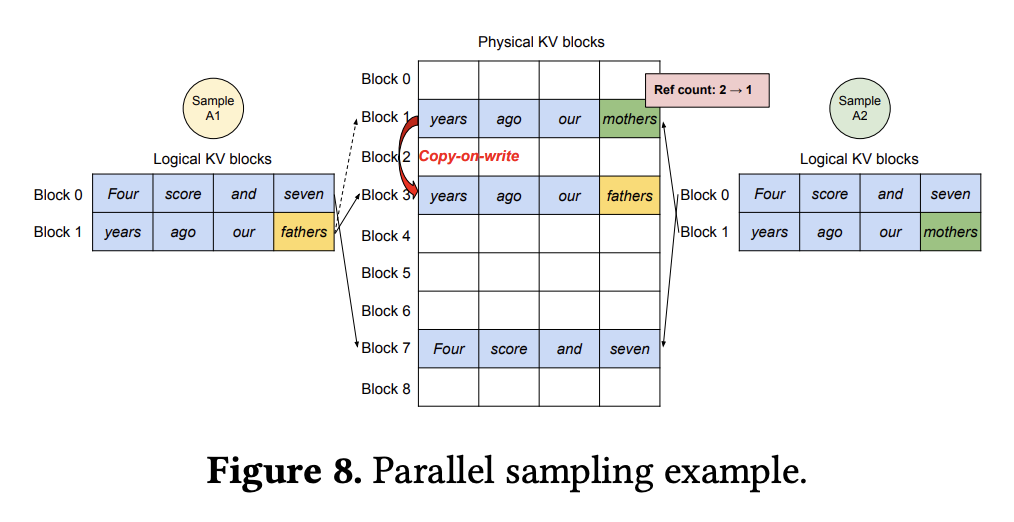
- Parallel Sampling:针对单个输入 prompt 采样多条输出序列,此时 vLLM 可以在多条序列之间共享 prompt 部分的 block,无需执行完整的内存拷贝
- 有一种特殊情况需要考虑,即:prompt 部分的最后一个 block 可能是未被填满的,而这个 block 的剩余部分无法被多个请求同时写入
- 为了解决这个问题,vLLM 为每个 block 添加了一个 reference count 参数来记录引用次数。在生成阶段,如果有请求要将 token 写入一个 block,vLLM 会先检查这个 block 的 reference count 参数,如果该参数大于 1,vLLM 会先执行一次 copy-on-write 建立副本,然后将该请求的这个逻辑 block 重定向到新的物理 block 上
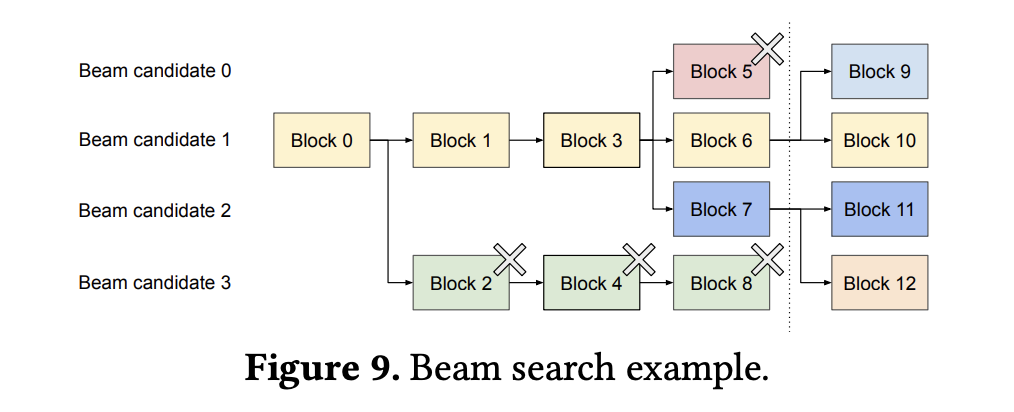
- Beam Search:借助 reference count,vLLM 还可以应用于借助 beam search 的 sampling 场景中,此时多条候选序列之间不仅会共享初始 prompt,还会共享不同候选序列的其它 block,并且共享模式还会随着采样过程发生变化。
- vLLM 使用 reference count 参数记录每个 block 被候选序列命中的次数,当 reference count 降至 0,vLLM 会释放并回收该 block 的内存,重新分配给新的 block 使用
- Shared Prefix:很多 LLM 应用会提供一段较长的任务描述,通常包含任务介绍和示例输入输出,称为 system prompt。system prompt 和实际的任务输入组合起来构成完整的 prompt,此时,system prompt 需要在不同的请求之间共享。vLLM 可以通过为预定义的共享前缀预留一组物理 block 的方式来很方便地实现这一点,带有共享前缀的 prompt 只需要将这部分的逻辑 block 映射到对应的物理 block 上即可
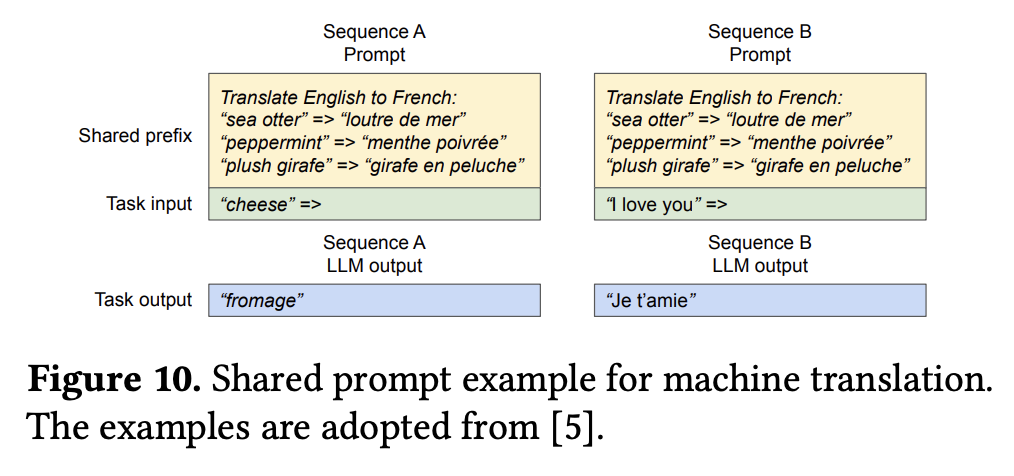
- 资源调度和抢占:当并行处理的请求数量超过系统设定的最大容量时,vLLM 遵循 FCFS (First-Come-First-Serve) 策略依次处理每个请求。但是,由于每条序列的最终输出长度事先未知,因此可能会出现高优先级序列的物理 block 被其它序列挤占耗尽的情况。此时,vLLM 需要处理 block 的驱逐与恢复问题:
- Evicting:vLLM 采用 All-or-Nothing 驱逐策略,即要么驱逐一条序列的所有 block,要么保留所有 block。其中,一个 beam search 请求的所有候选序列会作为一个序列组处理
- 此外,vLLM 还提供了两种方法可以用于恢复这些 block:
- Swapping:对于被驱逐的 block,vLLM 会将其暂时拷贝到 CPU 内存中管理起来,并暂停接收新请求,直到所有被抢占的请求处理完毕。因此,除了 GPU Block Allocator 以外,vLLM 还包含一个 CPU Block Allocator,用于管理交换到 CPU 内存上的物理 block
- Recomputation:在这种情况下,当被抢占的序列重新调度时,vLLM 直接选择重新计算这部分 KV cache
- 兼容 4D 并行技术:vLLM 工程框架可以支持 Megatron-LM 的 TP 策略,该策略遵循 SPMD (Single Program Multiple Data) 调度原理,线性层被划分到不同的 GPU 上执行分块矩阵乘法,再通过 all_reduce 操作不断同步中间结果。TP 策略下每个模型分片仍然使用相同的输入序列,由 vLLM 中心调度器通过单一 KV cache manager 向所有 GPU worker 分发任务,并在 all_reduce 操作执行之后将 next token 的 KV cache 写入内存
实验结果
- 下图展示了 vLLM 对于 KV cache 内存利用率的优化效果:显著降低了三种内存浪费,将内存利用率提高到 96
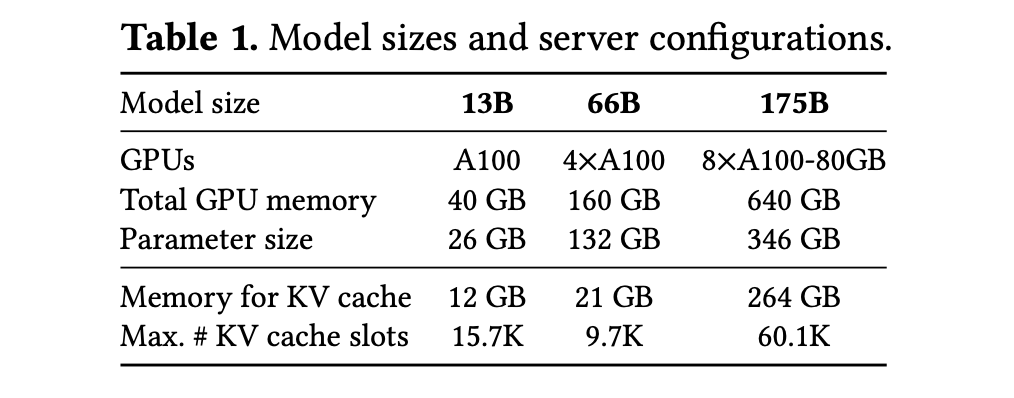
- 作者在以下环境中分别测试了 13B、66B 和 175B 三种规模的模型:
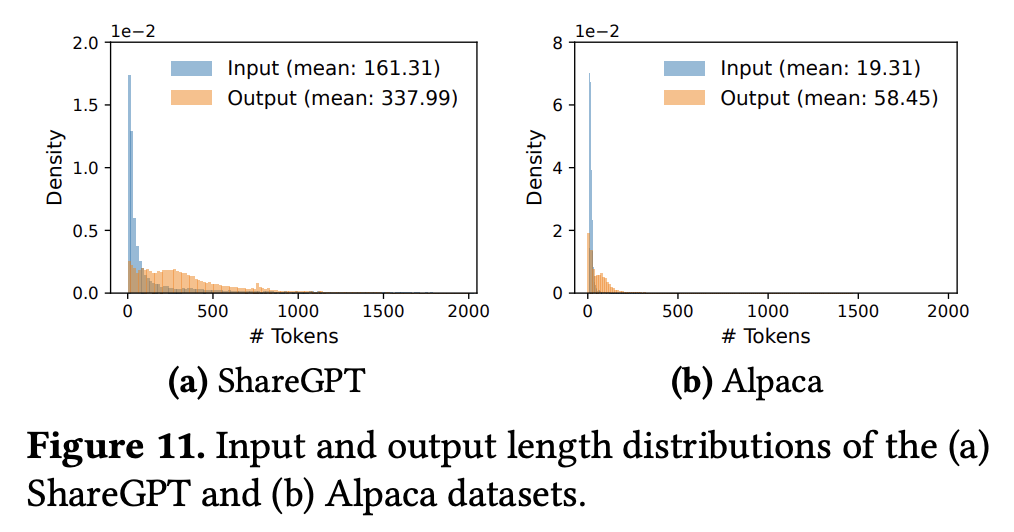
- 测试数据主要是 ShareGPT 和 Alpaca 数据集
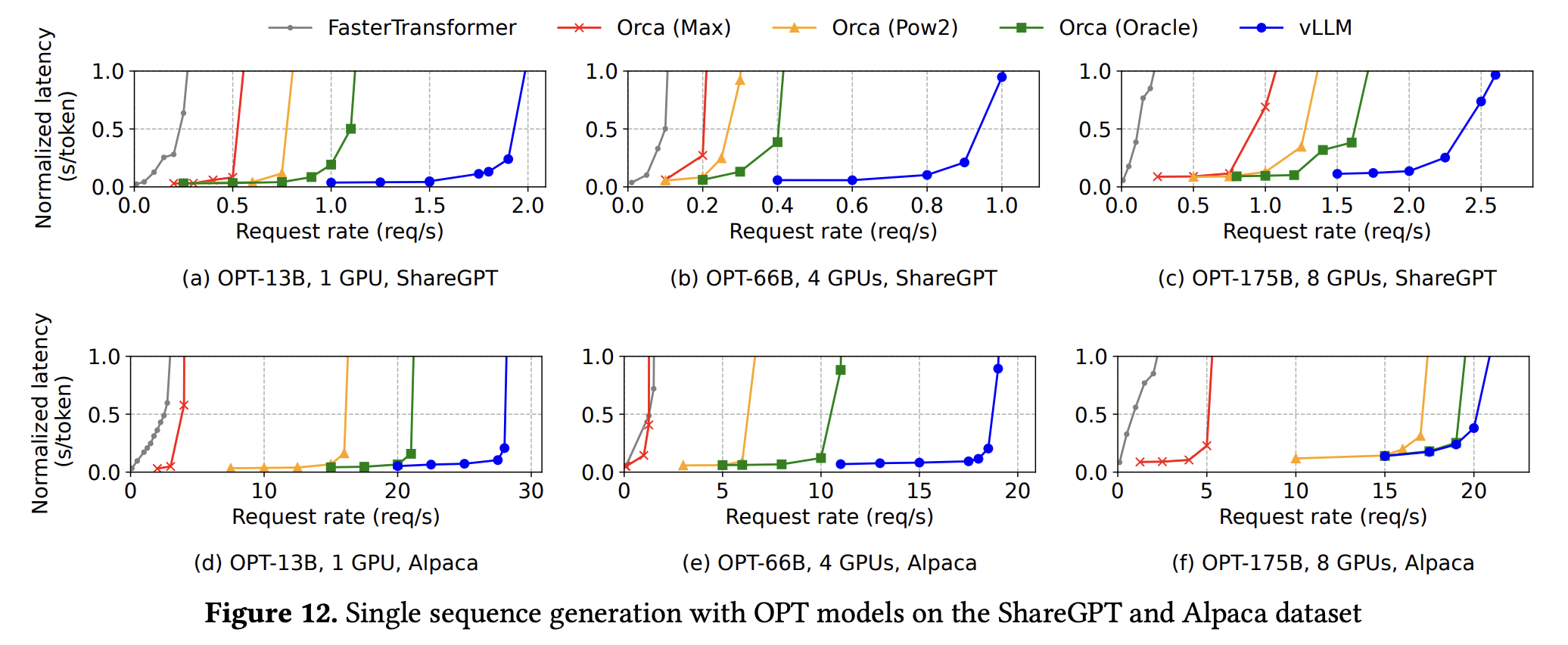
- 下图展示了 vLLM 和几种主流框架在两种数据集上运行 OPT-13B 模型生成单序列时,延迟随系统负载的变化情况:
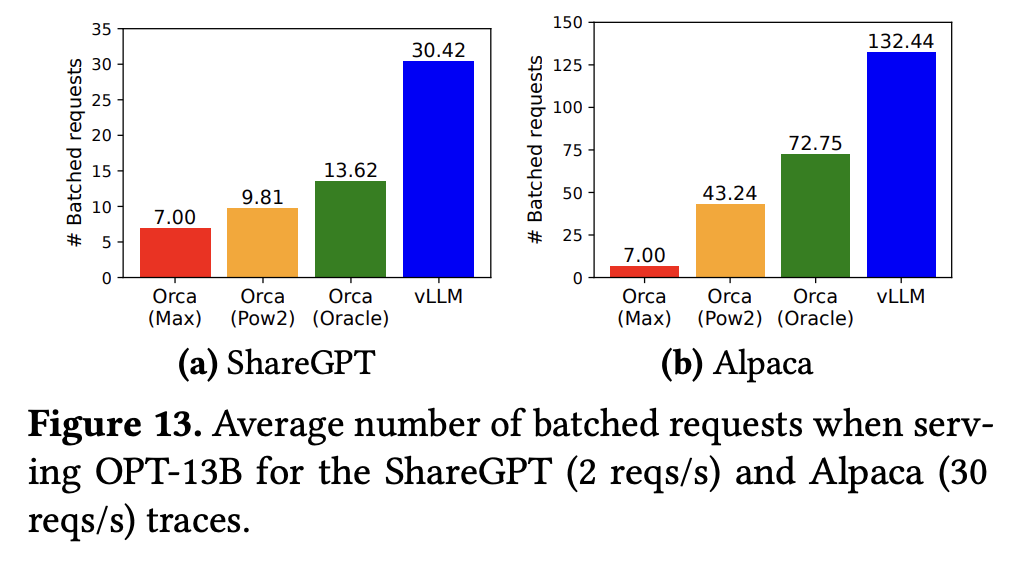
- 下图展示了 vLLM 和几种主流框架在两种数据集上运行 OPT-13B 模型的平均批处理请求数对比:
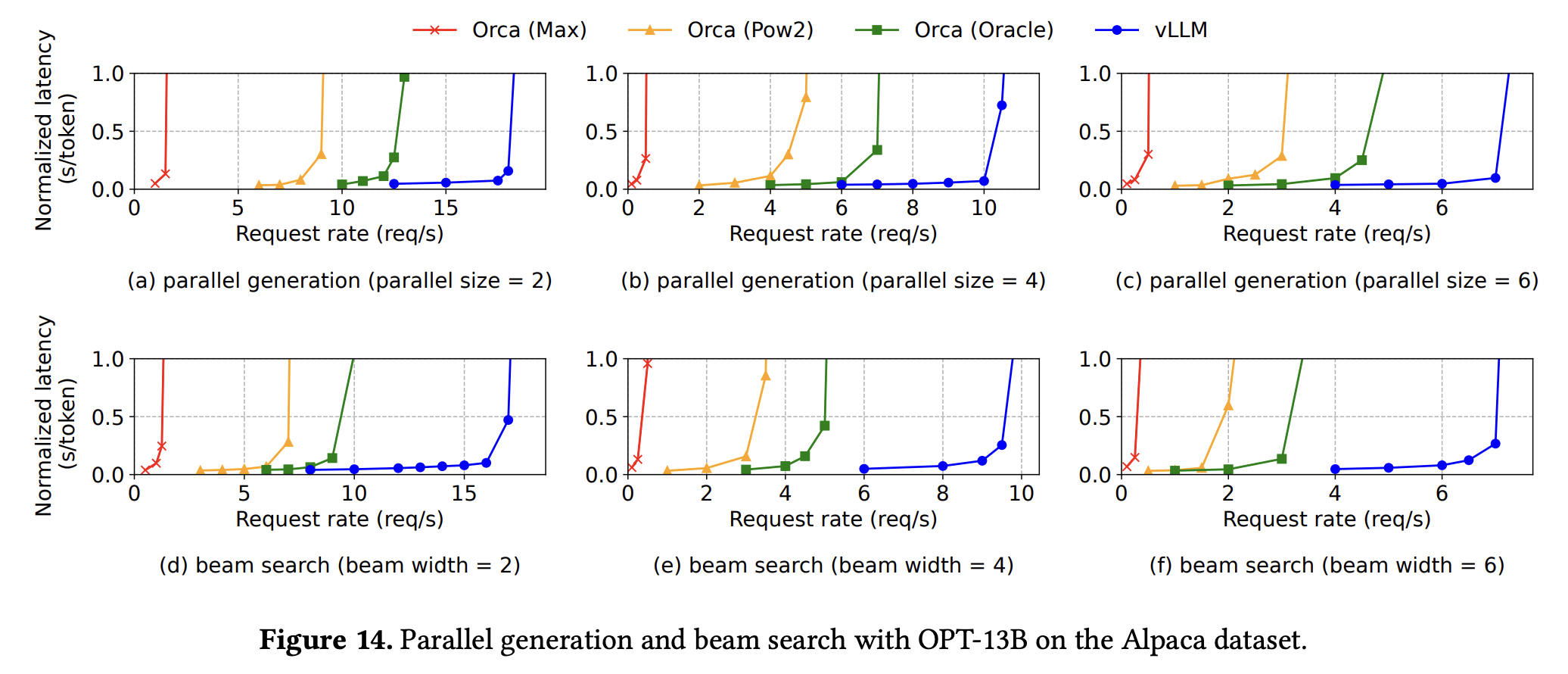
- 下图展示了 vLLM 和几种主流框架在 Alpaca 数据集上运行 OPT-13B 模型处理并行采样和 beam search 问题时,延迟随系统负载的变化情况:
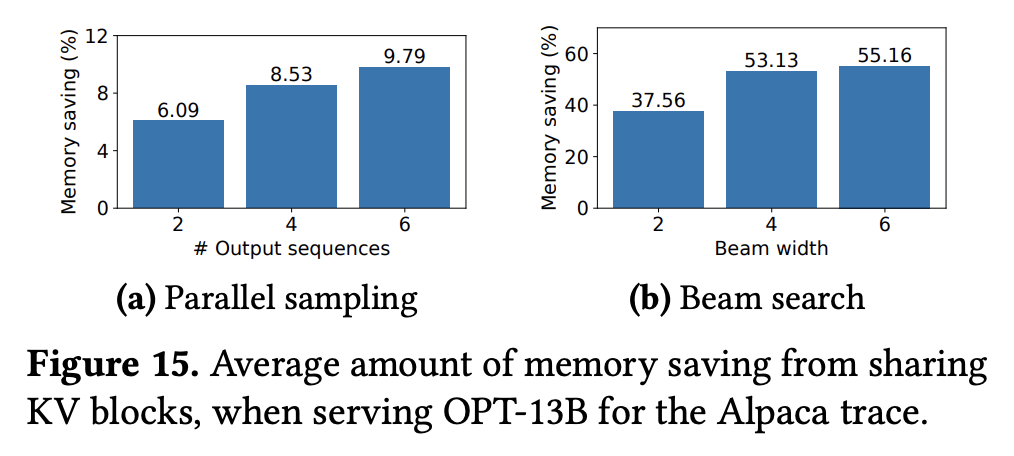
- 下图展示了 vLLM 在处理并行采样和 beam search 问题时,节省的内存空间随并行数/束宽的变化情况:
- 下图展示了 vLLM 和 Orca 在处理不同规模的 shared prefix 问题时,延迟随系统负载的变化情况:

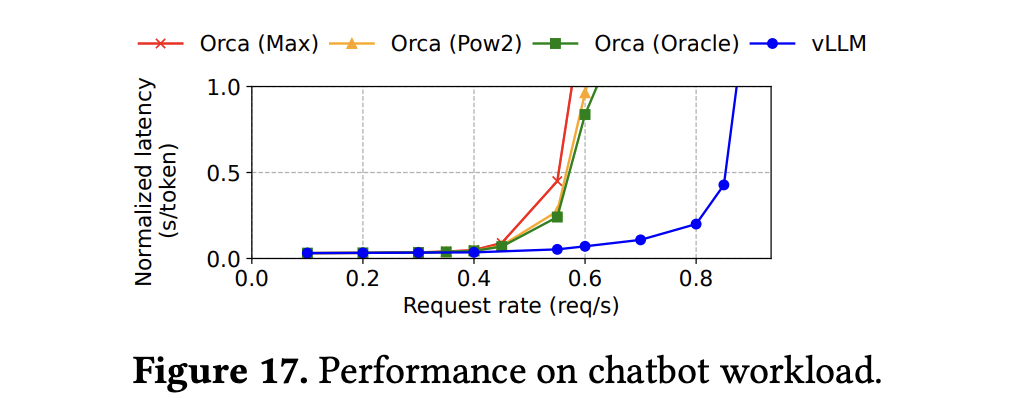
- 下图展示了 vLLM 和几种主流框架在用于聊天机器人场景时,延迟随系统负载的变化情况:
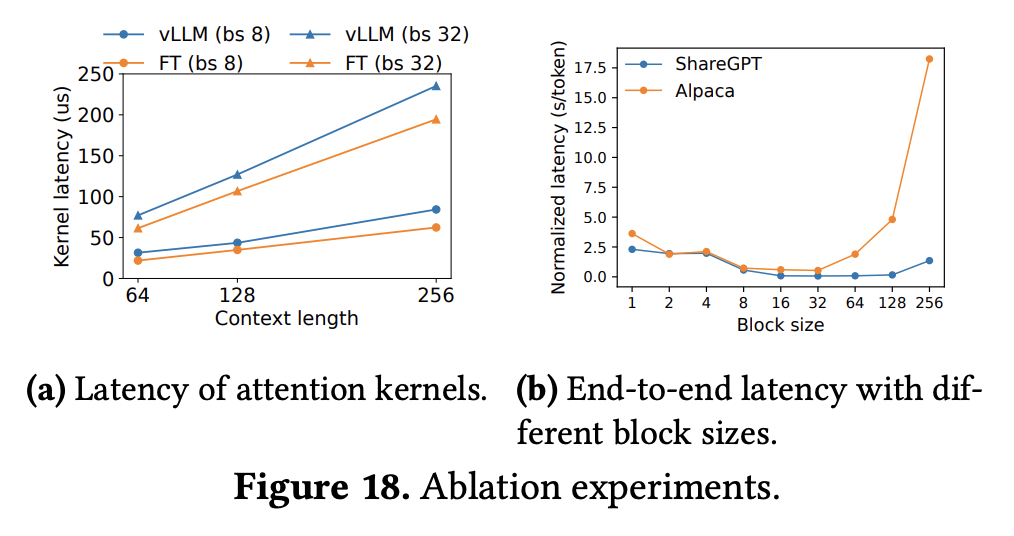
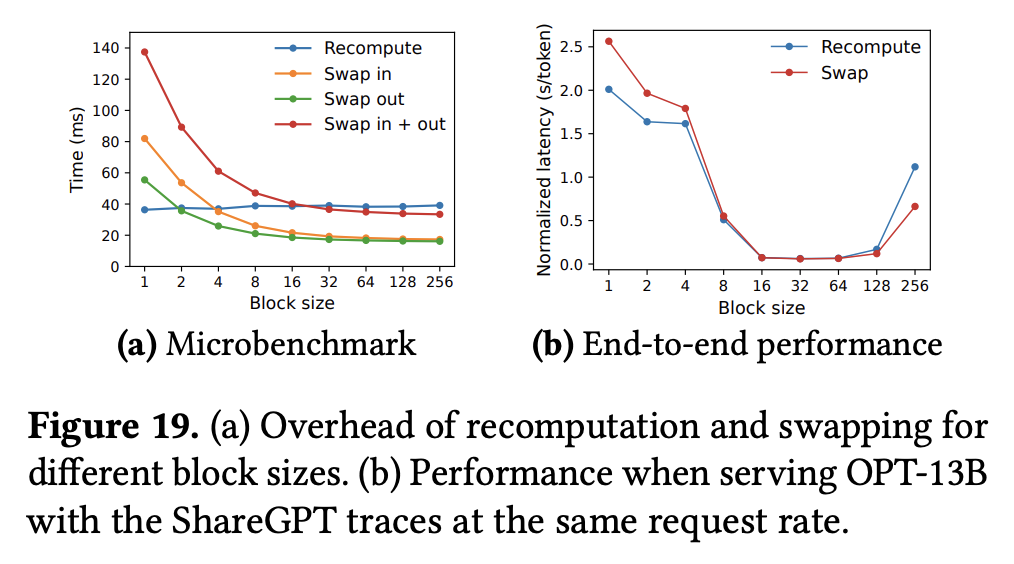
- 其它消融实验:
三、Installation
- 安装 vLLM:
pip install vllm - 参考官方文档,可以运行以下 demo 验证安装是否成功:examples/offline_inference/basic/basic.py
# SPDX-License-Identifier: Apache-2.0 # SPDX-FileCopyrightText: Copyright contributors to the vLLM project from vllm import LLM, SamplingParams # Sample prompts. prompts = [ "Hello, my name is", "The president of the United States is", "The capital of France is", "The future of AI is", ] # Create a sampling params object. sampling_params = SamplingParams(temperature=0.8, top_p=0.95) def main(): # Create an LLM. llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct") # Generate texts from the prompts. # The output is a list of RequestOutput objects # that contain the prompt, generated text, and other information. outputs = llm.generate(prompts, sampling_params) # Print the outputs. print("\nGenerated Outputs:\n" + "-" * 60) for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}") print(f"Output: {generated_text!r}") print("-" * 60) if __name__ == "__main__": main()- 如果 LLM 的 model 参数传入的是 HuggingFace 模型名称,那么 vLLM 后端会尝试从 HuggingFace 模型库中直接拉取模型;当然,这里也可以传入本地 HuggingFace 模型路径
四、源码解析
Todo.
- vLLM 内部实现了一整套针对主流大语言模型的重构代码,替换其中的部分算子为 vLLM 专用算子,以适配 PagedAttention 和 Tensor Parallel 等新技术
- 这意味着如果希望用 vLLM 部署这些已经得到了良好适配的主流模型,那么只需要很少的代码就可以启动一个服务(例如 demo 中的 Qwen2.5-0.5B-Instruct 模型);但是如果目标模型存在自定义架构,那么就需要仿照 vLLM 范式重构模型代码才能很好地利用 vLLM 的加速功能
- 以 Qwen2 模型为例,以下是 Qwen2Attention 模块在 HuggingFace 官方库中的实现:
class Qwen2Attention(nn.Module): def __init__(...): ... self.q_proj = nn.Linear( config.hidden_size, config.num_attention_heads * self.head_dim, bias=True ) self.k_proj = nn.Linear( config.hidden_size, config.num_key_value_heads * self.head_dim, bias=True ) self.v_proj = nn.Linear( config.hidden_size, config.num_key_value_heads * self.head_dim, bias=True ) self.o_proj = nn.Linear( config.num_attention_heads * self.head_dim, config.hidden_size, bias=False ) ... def forward(...): ... query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2) key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2) value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2) cos, sin = position_embeddings query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin) if past_key_values is not None: # sin and cos are specific to RoPE models; cache_position needed for the static cache cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position} key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs) attention_interface: Callable = eager_attention_forward if self.config._attn_implementation != "eager": attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation] attn_output, attn_weights = attention_interface( self, query_states, key_states, value_states, attention_mask, dropout=0.0 if not self.training else self.attention_dropout, scaling=self.scaling, sliding_window=self.sliding_window, # main diff with Llama **kwargs, ) attn_output = attn_output.reshape(*input_shape, -1).contiguous() attn_output = self.o_proj(attn_output) return attn_output, attn_weights - 以下是该模块在 vLLM 中的实现:
from vllm.model_executor.layers.linear import QKVParallelLinear class Qwen2Attention(nn.Module): def __init__(...): ... self.qkv_proj = QKVParallelLinear( hidden_size, self.head_dim, self.total_num_heads, self.total_num_kv_heads, bias=True, quant_config=quant_config, prefix=f"{prefix}.qkv_proj", ) self.o_proj = RowParallelLinear( self.total_num_heads * self.head_dim, hidden_size, bias=False, quant_config=quant_config, prefix=f"{prefix}.o_proj", ) self.attn = Attention( self.num_heads, self.head_dim, self.scaling, num_kv_heads=self.num_kv_heads, cache_config=cache_config, quant_config=quant_config, prefix=f"{prefix}.attn", attn_type=attn_type, ) ... def forward(...): ... qkv, _ = self.qkv_proj(hidden_states) q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1) q, k = self.rotary_emb(positions, q, k) attn_output = self.attn(q, k, v) output, _ = self.o_proj(attn_output) return output - 由此可以分析一些 HuggingFace(pytorch)算子到 vLLM 算子的映射关系
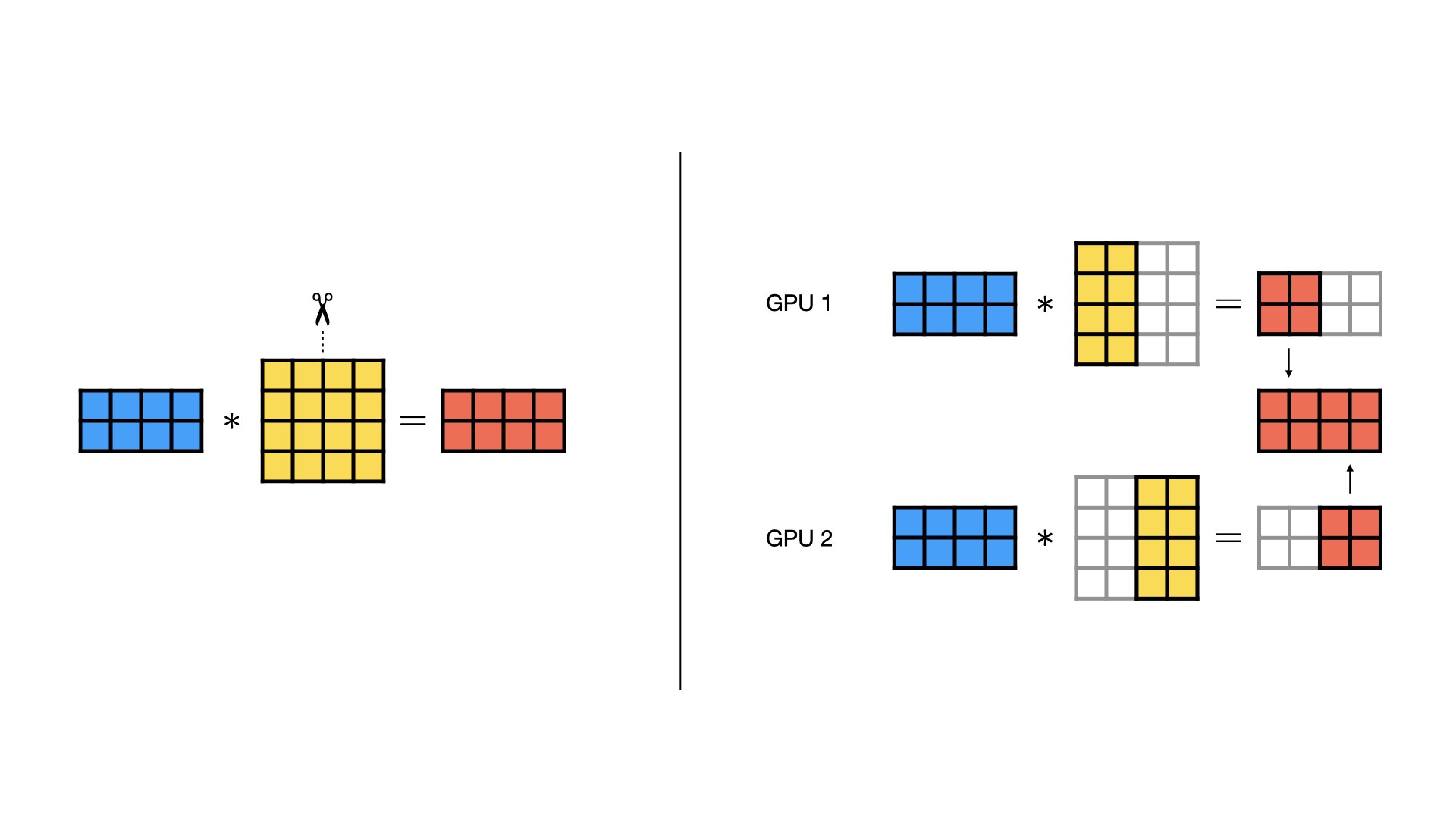
关于 TP (Tensor Parallel) 的三种实现方案
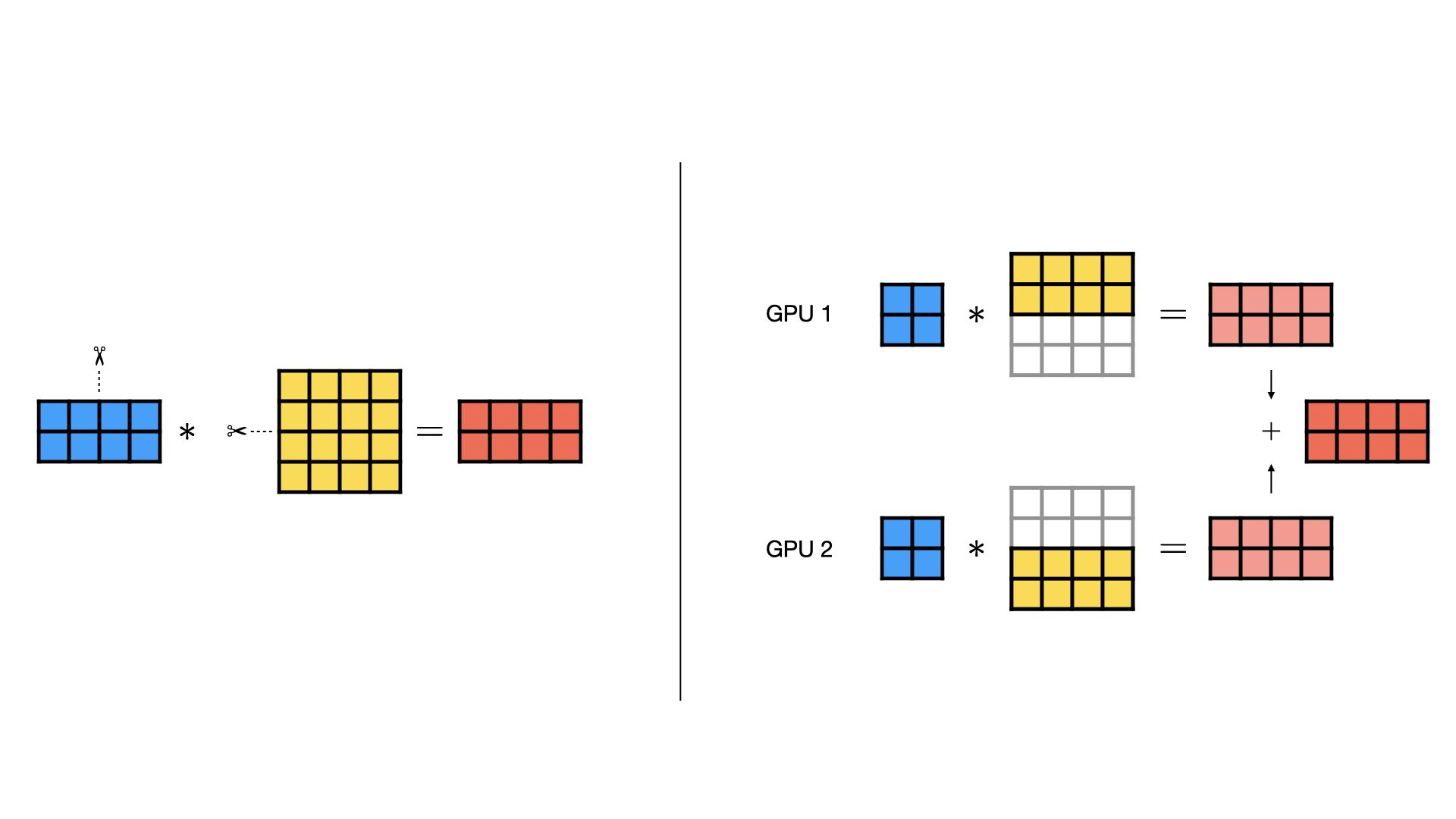
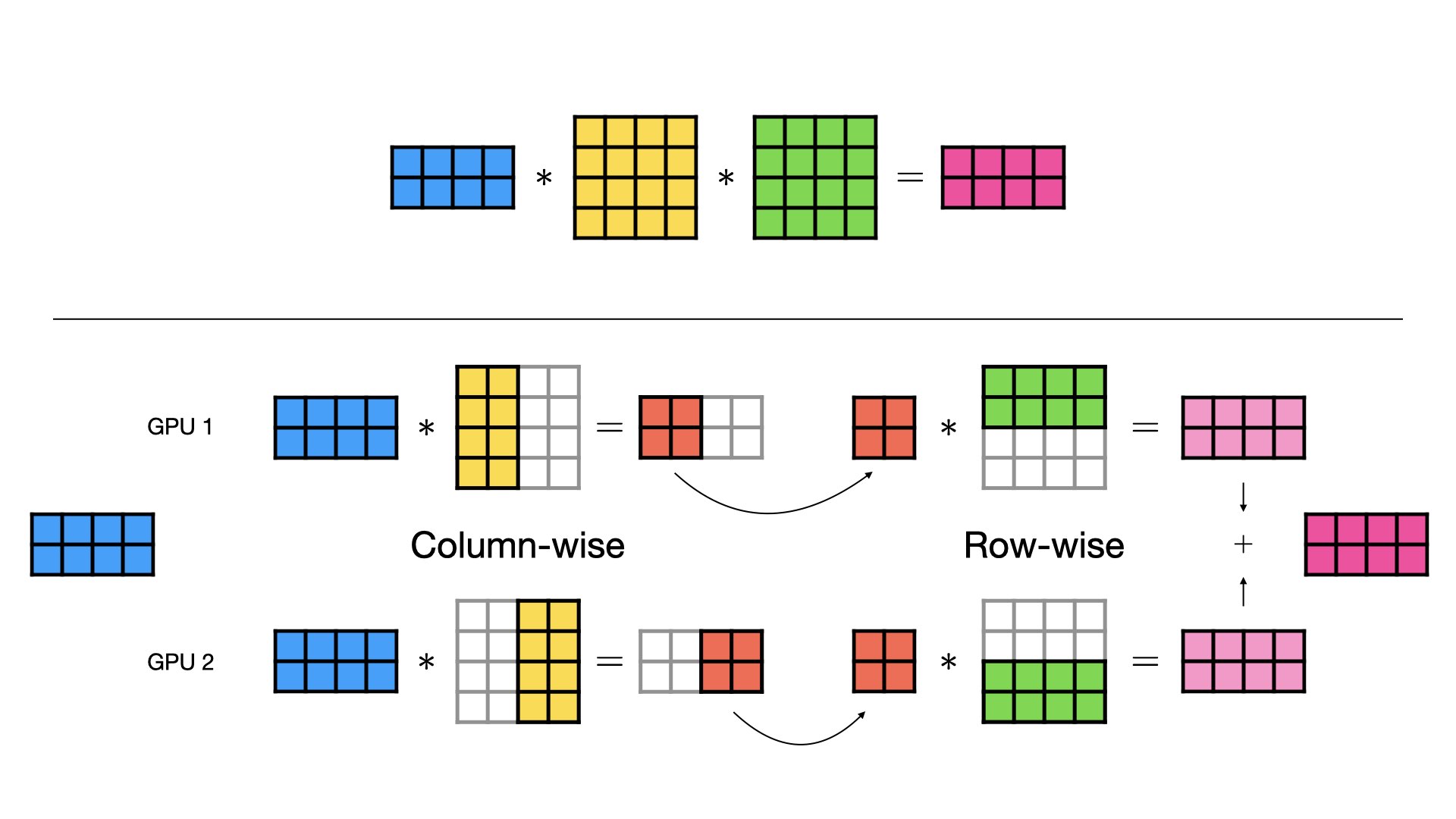
- 按列切分(Column-wise Parallel)
- 按行切分(Row-wise Parallel)
- 混合切分(Combined Column- and Row-wise Parallel)
SGLang (Structured Generation Language)
一、简介
- 相关链接
- SGLang 官方文档:https://docs.sglang.ai/
- SGLang 论文链接(arxiv):SGLang: Efficient Execution of Structured Language Model Programs
- GitHub 仓库:https://github.com/sgl-project/sglang
- SGLang 是一个由 LMSYS Org (Large Model Systems Organization,由加州大学伯克利分校、斯坦福大学等高校联合成立) 开发,专为大语言模型和视觉语言模型设计的高性能推理框架,旨在为各种场景的 LLM 应用(从单 GPU 到大型分布式集群)提供高吞吐量和低延迟的推理方案。其核心特性包括:
- 高效的后端 runtime,支持:
- 基于 RadixAttention 的自动前缀缓存 (Automatic Prefix Caching)
- 零开销的 CPU 调度器
- Prefill-Decode 解耦
- 推测解码 (Speculative Decoding)
- 连续批处理 (Continuous Batching)
- 兼容 vLLM 的 PagedAttention 技术
- TP/PP/EP/DP 分布式部署架构
- 结构化输出 (Structured Outputs)
- 分块预填充 (Chunked Prefill)
- 多种模型量化技术,包括 GPTQ、AWQ、INT4、INT8、FP8
- 支持 Multi-LoRA
- 广泛的模型和硬件平台支持
- 灵活的前端语言
- 活跃的开发者社区
- 高效的后端 runtime,支持:
二、论文笔记
摘要总结
- 问题:大语言模型(LLM)正日益广泛地应用于包括批处理请求、高级 prompt 技术、控制流和结构化输入/输出在内的各种复杂任务中。然而,当前缺乏高效的系统来编程和执行此类应用
- 解决方案:提出了 SGLang,一个用于高效执行复杂语言模型应用的系统。SGLang 包含前端语言和后端 runtime:
- 前端语言提供用于生成和并行控制的函数接口,简化复杂应用的编程;
- 后端 runtime 通过创新的优化技术来加速执行,例如:
- RadixAttention:用于实现跨请求的 KV cache 复用
- Compressed FSM:用于加快结构化输出时的解码速度
- 实验结果:实验表明,在智能体控制、逻辑推理、小样本学习 benchmark、JSON 解码、RAG (Retrieval-Augmented Generation) 管道和多轮对话等任务中,SGLang 在各类大语言模型和多模态模型上的吞吐量比现有最优推理系统(如 vLLM)提升最高达 6.4 倍,延迟降低最高达 3.7 倍。
方案细节
- SGLang 系统由前端语言和后端 runtime 组成:其中前端语言简化了 LLM 程序的编写,后端 runtime 则提供了高效的程序执行接口

- 下图展示了基于 SGLang 前端语言实现的运行 demo,这是一种嵌入在 python 中的领域特定语言 (Domain-Specific Language, DSL)。图中代码的功能是使用 BSM (Branch-Solve-Merge, 分支-求解-合并) 方法,从“Clarity”、“Originality”,“Evidence”三个角度评估一篇针对特定图像所做的文章(图像和文章均由用户输入)
- 在这个 demo 中,作者调用了以下关键接口:
- system():输入系统提示
- user():输入用户提示
- image()、video():获取多模态输入
- assistant():获取语言模型输出
- select("related", choices=["yes", "no"]):让语言模型在给定的选项中选择概率更高的答案,并保存在指定的字段中
- gen("judgment", stop="END"):让语言模型生成文本,直到输出 stop 参数指定的结束符,并将输出结果保存在指定的字段中
- regex:指定语言模型输出的正则表达式
- fork():创建多个并行生成的分支,提高推理速度

dimensions = ["Clarity", "Originality", "Evidence"]
@function
def multi_dimensional_judge(s, path, essay):
s += system("Evaluate an essay about an image.")
s += user(image(path) + "Essay:" + essay)
s += assistant("Sure!")
# Return directly if it is not related
s += user("Is the essay related to the image?")
s += assistant(select("related", choices=["yes", "no"]))
if s["related"] == "no": return
# Judge multiple dimensions in parallel
forks = s.fork(len(dimensions))
for f, dim in zip(forks, dimensions):
f += user("Evaluate based on the following dimension:" + dim + ". End your judgment with the word 'END'")
f += assistant("Judgment:" + gen("judgment", stop="END"))
# Merge the judgments
judgment = "\n".join(f["judgment"] for f in forks)
# Fetch generation results
# Generate a summary and a grade. Return in the JSON format.
s += user("Provide the judgment, summary, and a letter grade")
s += assistant(judgment + "In summary," + gen("summary", stop=".")+ "The grade of it is" + gen("grade"))
schema = r"\{"summary" : [\w\d\s]+\.", "grade" : "[ABCD][+-]?"\'}
s += user("Return in the JSON format.")
s += assistant(gen("output", regex= schema))
state = multi_dimensional_judge.run(...)
print(state["output"])- LLM 编程框架可以分为 high-level 和 low-level 两大类,其中:
- high-level system 以 LangChain、DSPy 为代表,通常提供预定义或自动生成的 prompt
- low-level system 以 LMQL、Guidance 为代表,通常不会主动修改 prompt;SGLang 也属于 low-level(底层)系统
- 下表对比了 SGLang 和几种主流的 low-level system,其中 SGLang 专注于运行时效率,并自带协同设计的后端 runtime,可以支持后续引入的新优化策略

- RadixAttention:这是 SGLang 的核心贡献之一,它的目标是解决在 vLLM 等框架中尚未解决的跨请求共享 KV cache 问题:vLLM 虽然通过 PagedAttention 共享物理 block 提供了一定的 shared prefix 能力,但是它依赖预设的共有前缀,仅能为一个特定服务提供支持,不能实现系统级的前缀共享
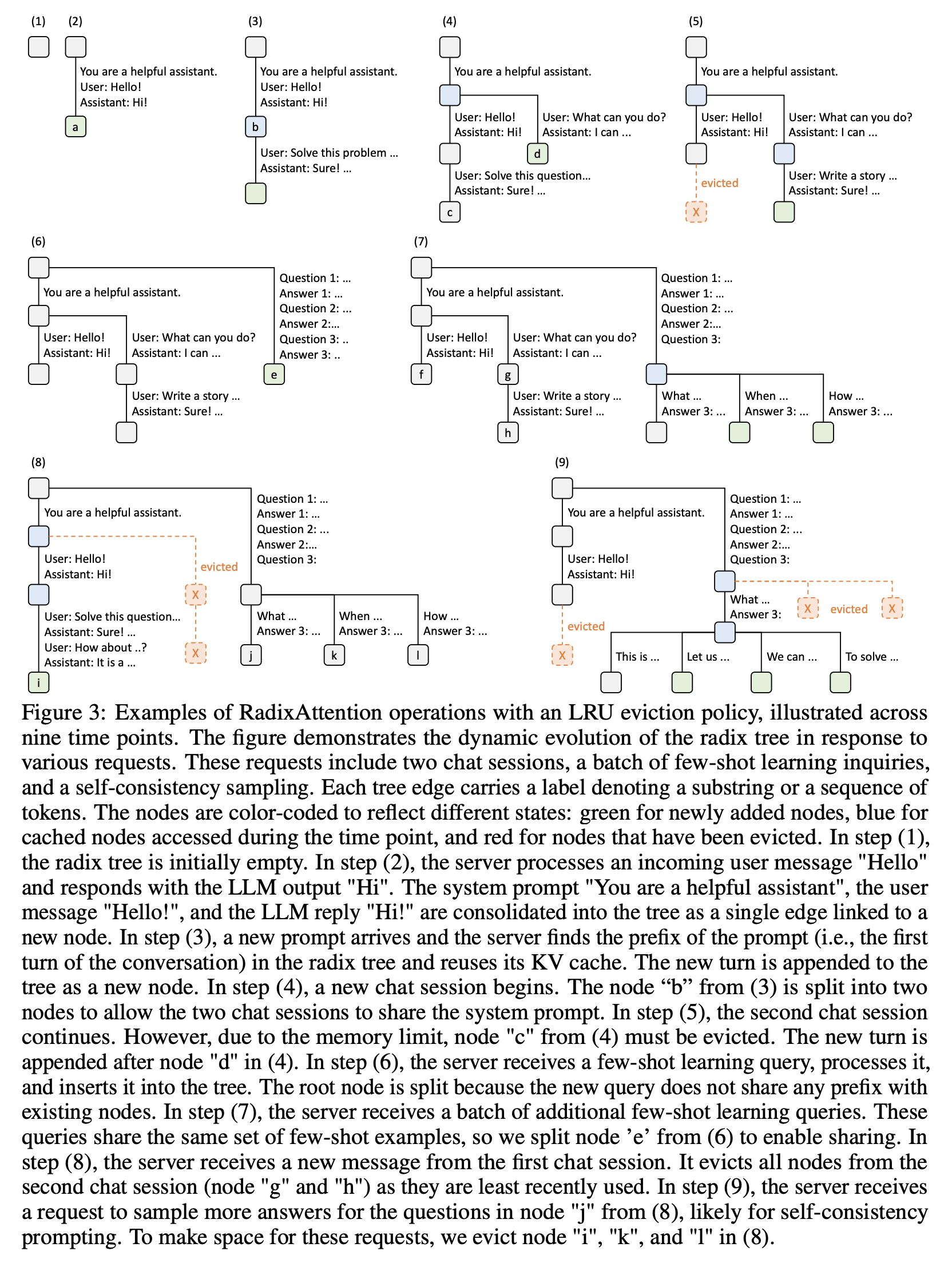
- RadixAttention 选择将所有的 prompt 和生成结果以 Radix 树的形式储存下来,并通过 LRU (Least Recently Used) 驱逐策略和 cache-aware 调度策略管理跨请求优先级,实现了跨请求的 token 级自动前缀复用,支持高效的前缀搜索、复用、插入和驱逐
- RadixAttention 在 CPU 内存上维护 Radix 树,并在节点和对应的 KV cache 之间建立映射关系,这些 KV cache 以非连续空间上的分页布局(PagedAttention)存储在 GPU 内存上。在 SGLang 中,每个 block 仅对应一个 token,可能是为了便于树的插入和驱逐
- LRU 驱逐策略:当内存空间被新增的 KV cache 占满时,SGLang 优先驱逐最近最少使用的子节点。类似于 vLLM,SGLang 为每个节点添加一个 reference counter 用来记录节点被引用的次数,当节点的 reference counter 降为 0,SGLang 会将该节点标记为“可被驱逐”的状态,直到有大量请求挤占内存,系统会将所有的缓存节点释放,一边容纳更大的批处理大小
- cache-aware 调度策略:定义缓存命中率为已缓存的 token 数量在总 token 数量中的占比,可以认为当等待队列中存在大量请求时,缓存命中率的大小对系统吞吐量的影响很大。而缓存命中率又和调度器的执行顺序有关,例如,如果调度器频繁地在不相关的请求之间切换,就可能会造成缓存抖动,从而降低缓存命中率。为了解决这个问题,SGLang 会按照前缀命中缓存的长度对请求进行排序,并优先处理命中缓存较长的请求,以取代 vLLM 的 FCFS 策略
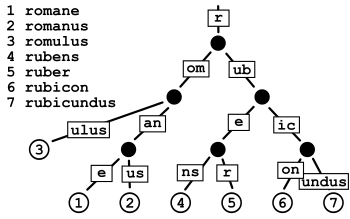
- Trie 树:一种多叉搜索树,和一般的二叉搜索树不同,它的节点中并不保存完整的 key,而是只保存单个字符。要获取节点对应的 key,需要从根节点出发,遵循深度优先原则,遍历到该节点,并将路径上所有节点的字符拼接起来
- Radix 树:Trie 树的优化版,它将 Trie 树中的那些只有一个子节点的中间节点进行合并,从而减少了节点数量,节省内存空间
- 下图演示了 RadixAttention 中 LRU 驱逐策略的实例
- Compressed FSM:在许多 LLM 应用中,结构化输出 (Structured Outputs) 是一项被广泛支持的功能,它允许用户指定模型输出特定格式的文本(例如 JSON 格式)。现有的推理框架接收一个正则表达式参数作为输入,并将正则表达式抽象为一个 FSM (Finite State Machine, 有限状态机) 来支持这项功能。在解码过程中,它们检索 FSM 的当前状态,然后在被允许的 token 中选择下一状态,将无效 token 的概率置为 0。这种方法在有机会一次性输出更多确定性文本时效率低下
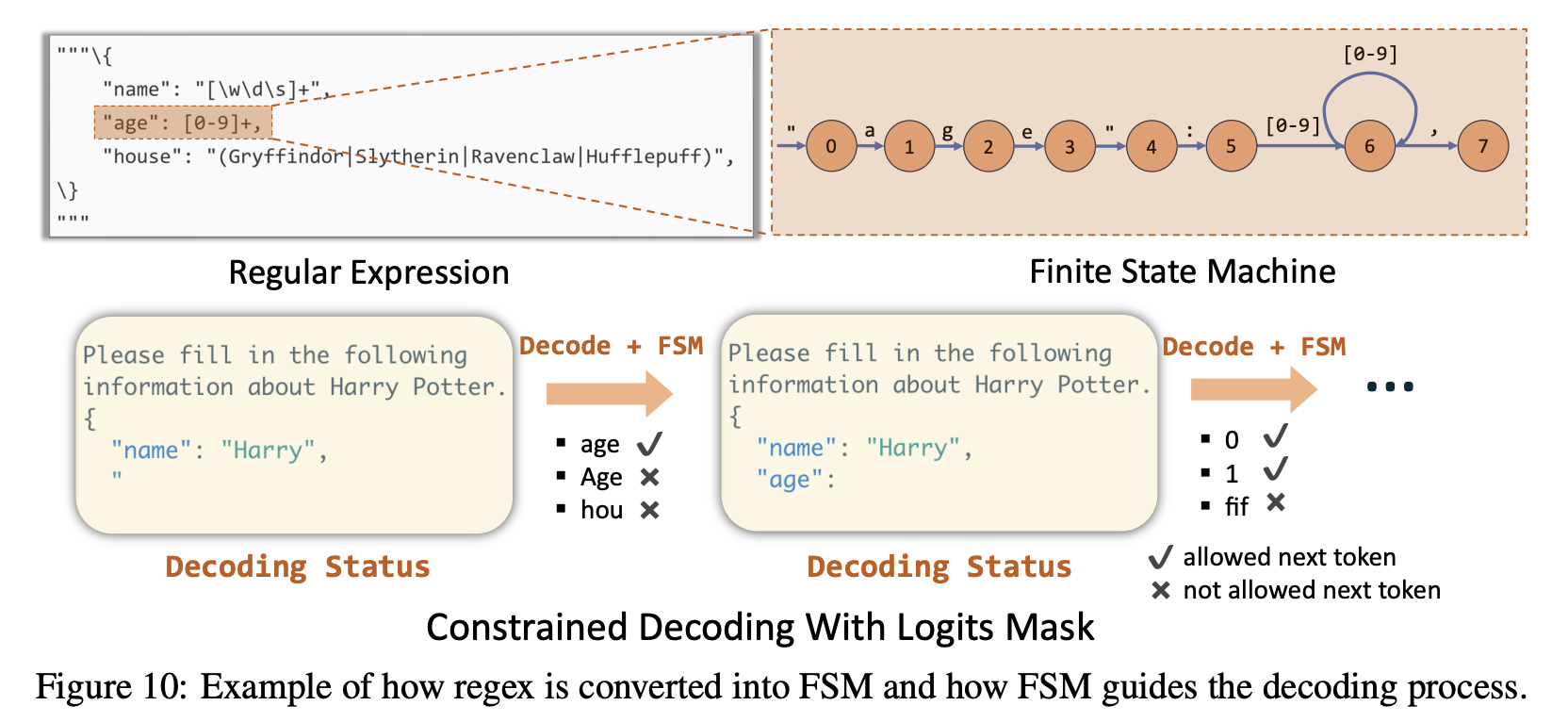
- RadixAttention 所采用的 Radix 树结构天然具有将单一、无分叉的节点压缩为一条长边的优势。在解码时,模型每生成一个 token,系统都会将其和 FSM 上下一条可能的边的起始字符进行对比,一旦匹配成功,就会直接跳转到这条边的末尾(这个过程称为“jump forward”)。这样就可以避免在已知输出的情况下重复调用模型
- 跳转后的边仍然需要按照标准词表重新分词并转换为 token,以便用于下一次 token 生成
- FSM (Finite State Machine, 有限状态机):一种数学模型,用描述有限个状态以及这些状态之间的转移和动作,由三个部分组成:状态(state)、事件(event)、动作(action),其中事件也被称为转移条件(Transition Condition)
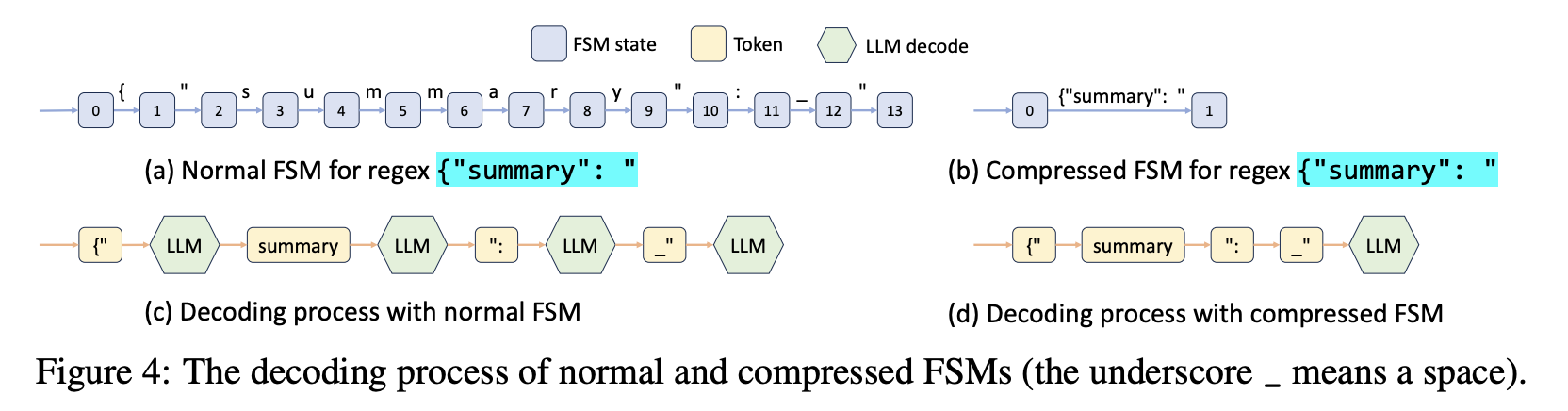
- 下图展示了标准 FSM 和 Compressed FSM 在构建时的差异
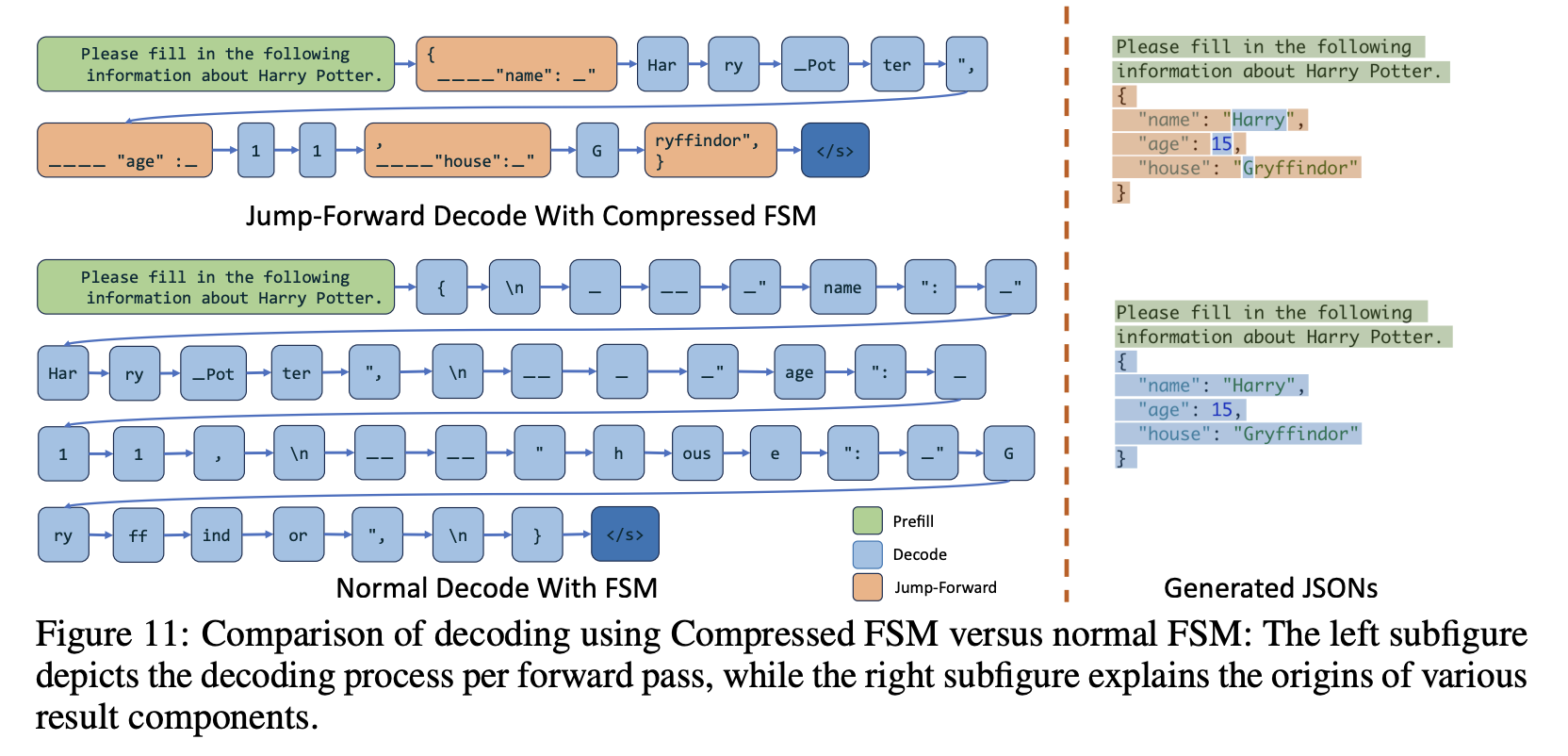
- 下图展示了两种 FSM 在解码过程中的差异,包括 jump forward 的工作原理
实验结果
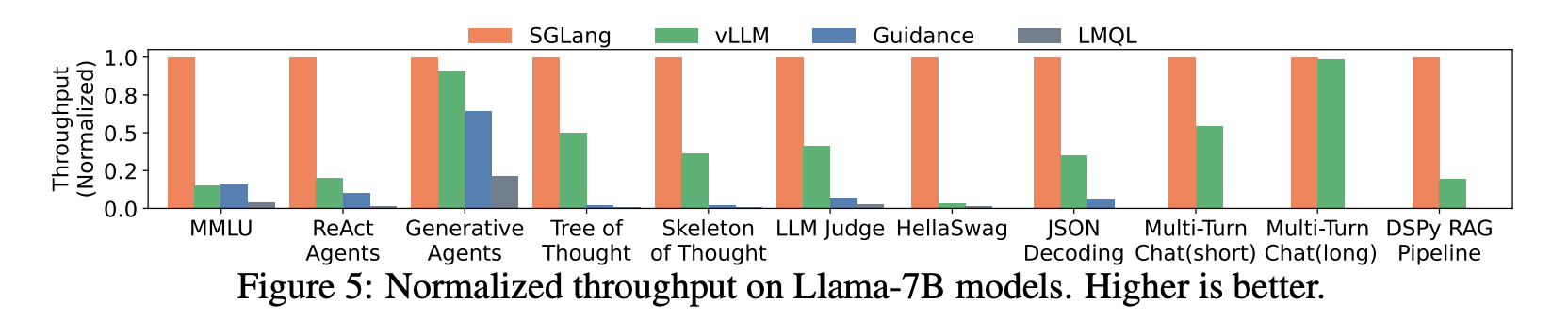
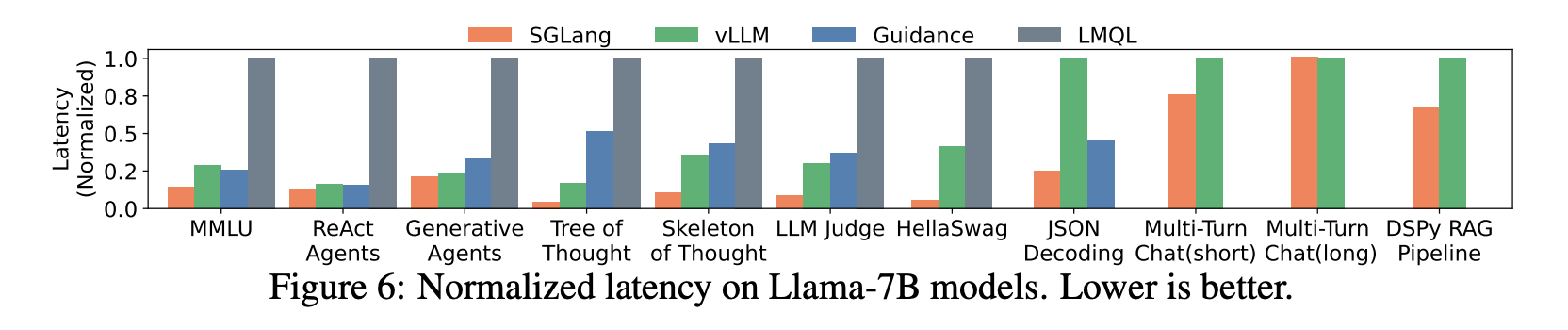
- 下图展示了 SGLang 和几种主流框架在 NVIDIA A10G 24G 显卡上运行 Llama-7B 模型的延迟和吞吐量对比。结果显示,SGLang 最多可以将系统吞吐量提高至 baseline 的 6.4x,并将延迟降低至 baseline 的 3.7x
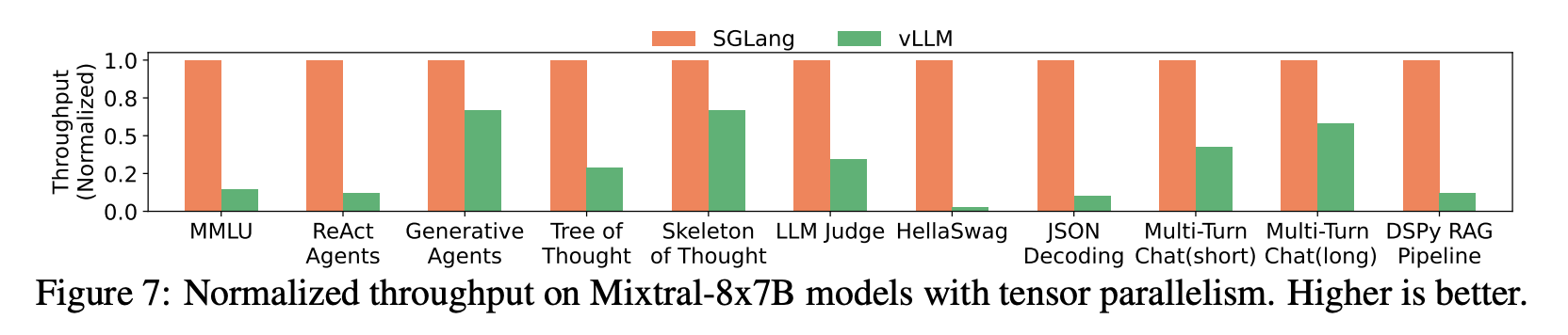
- 下图展示了 SGLang 和 vLLM 在 TP 部署大模型(Mixtral-8x7B)时的系统吞吐量对比
- 下图展示了 SGLang 和 Hugging Face 原版实现在运行多模态大语言模型时的系统吞吐量对比

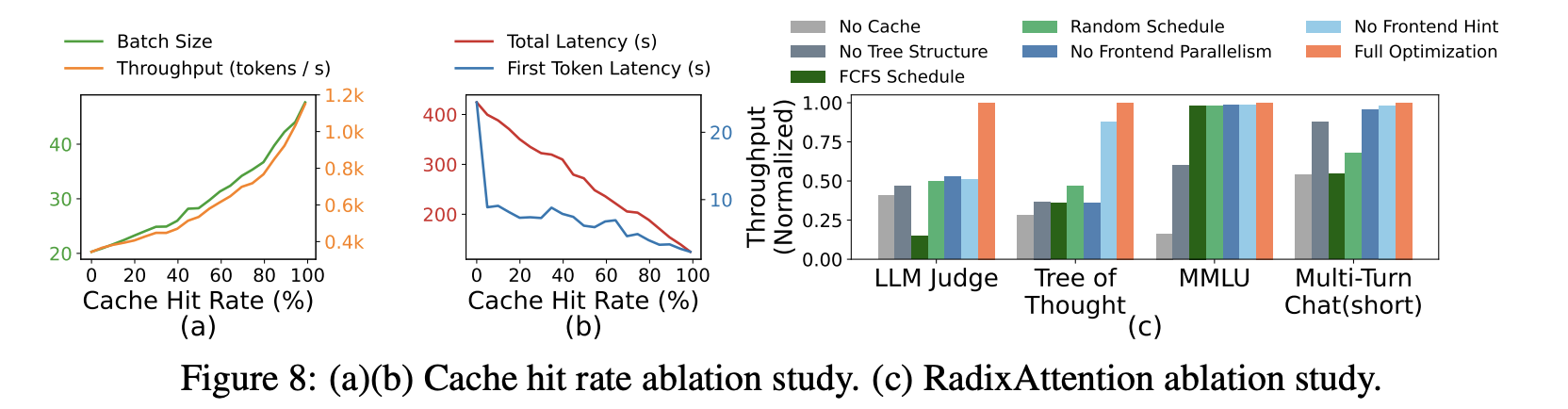
- 其它消融实验
SGLang 和 vLLM 对比
SGLang 的优势
- SGLang 设计时以 vLLM 作为 baseline,在论文和工程实践 [1] 中,均有比 vLLM 更高的性能上限,特别是在高并发任务上,RadixAttention 在跨请求缓存上的优势可以带来更明显的吞吐量提升
- SGLang 原生支持多模态应用(例如 VLM),相对于 vLLM,SGLang 的接口设计更加自然
vLLM 的优势
- vLLM 的社区规模庞大,对 HuggingFace 模型的兼容性高,鲁棒性强;相较而言,SGLang 的开发者需要更多处理如内存越界之类的框架设计问题
- vLLM 开发简单且易于上手,通常只用几行代码就可以部署起一个 LLM 应用;SGLang 的前端基于领域特定语言 (Domain-Specific Language, DSL) 开发,学习成本更高
附:KV cache 内存占用推导
- 多头注意力 (Multi-Head Attention, MHA) 在批处理请求时的 KV cache 内存占用峰值为:
- key cache:
- value cache:
- total:
- key cache:
- 其中:
表示批处理大小
表示最大序列长度
表示 attention layer 层数
表示注意力头数
表示每个注意力头的特征向量维度
表示 KV cache 的数值精度,通常和模型权重的精度一致
- 相对于 Multi-Head Attention,分组查询注意力 (Grouped Query Attention, GQA) 可以显著降低 KV cache 内存占用,其峰值为:
- key cache:
- value cache:
- total:
- key cache:
- 其中,GQA 相对于 MHA 的 KV cache 内存优化倍率为


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









