



参考文献
verl (Volcano Engine Reinforcement Learning, HybridFlow)
一、简介
- 相关链接:
- verl 官方文档:https://verl.readthedocs.io/en/latest/index.html
- verl(HybridFlow)论文链接(arxiv):HybridFlow: A Flexible and Efficient RLHF Framework
- GitHub 仓库:https://github.com/volcengine/verl
- verl(Volcano Engine Reinforcement Learning)是一个由字节跳动 Seed 团队发起,并由社区共同维护的专为大语言模型(LLM)设计的强化学习训练库。它旨在提供灵活、高效且可用于生产环境的解决方案,帮助研究人员和开发者更有效地进行 LLM 的后训练调优,例如基于人类反馈的强化学习(RLHF)
二、论文笔记(HybridFlow)
摘要总结
- 问题:
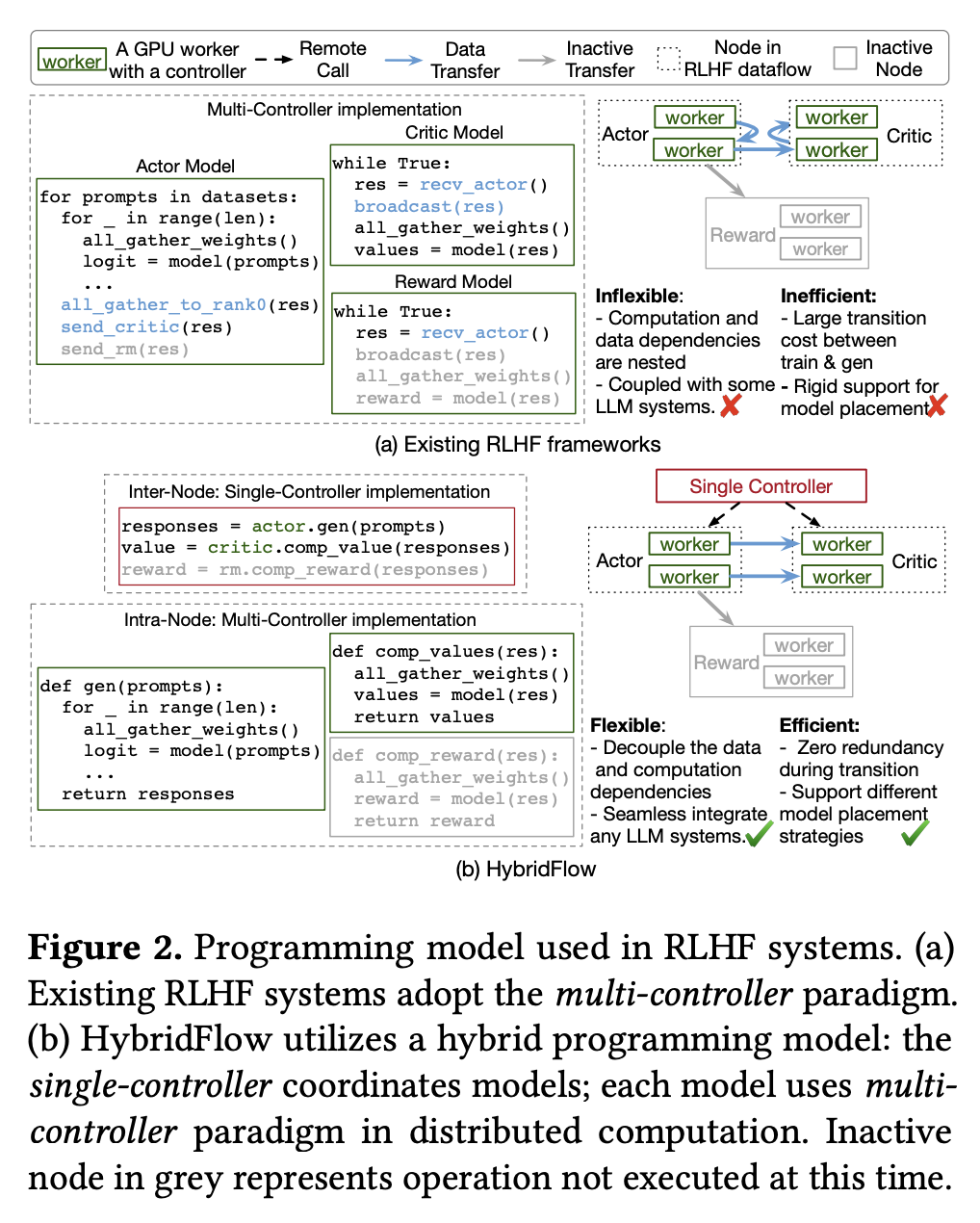
- RLHF 被广泛应用于大语言模型的 alignment 任务中。传统的 RL 训练过程可以被建模为一个 dataflow,其中每个节点代表神经网络的计算,每条边代表神经网络之间的数据依赖关系。传统的 RL 训练框架采用单控制器范式来执行这个 dataflow,该控制器同时负责节点内计算和节点间通信,这会产生较大的控制调度开销,不适用于大规模 RLHF 训练
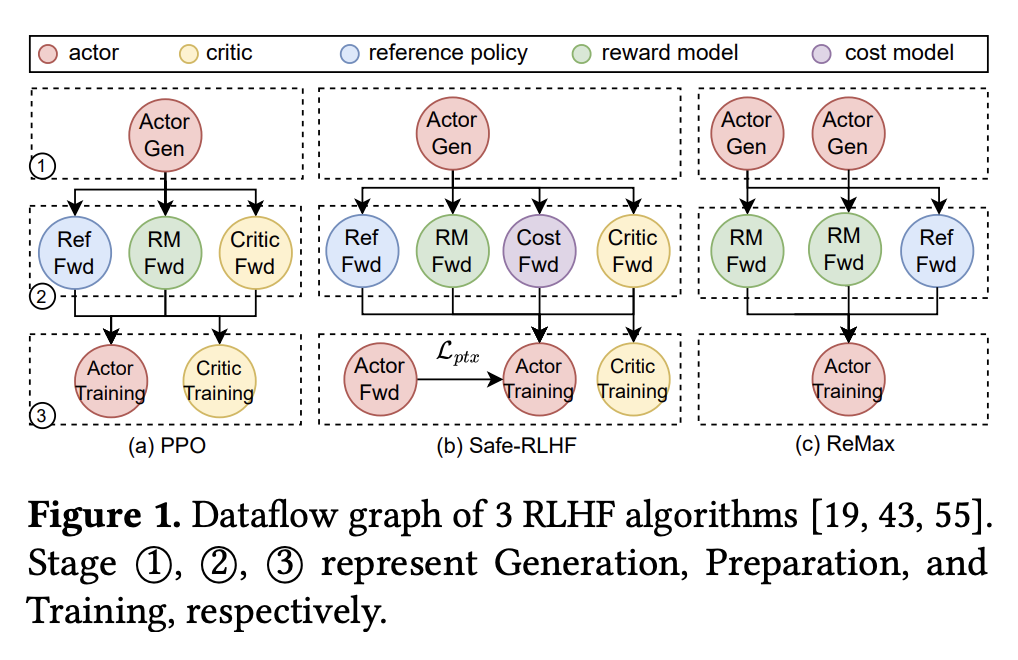
- 而现有的 RLHF 训练框架(如 OpenRLHF、NeMo-Aligner)大多采用多控制器范式,这会引起分布式计算和数据通信的相互耦合,因而可能不够灵活
- RLHF 被广泛应用于大语言模型的 alignment 任务中。传统的 RL 训练过程可以被建模为一个 dataflow,其中每个节点代表神经网络的计算,每条边代表神经网络之间的数据依赖关系。传统的 RL 训练框架采用单控制器范式来执行这个 dataflow,该控制器同时负责节点内计算和节点间通信,这会产生较大的控制调度开销,不适用于大规模 RLHF 训练
- 解决方案:提出了 HybridFlow,采用一种混合方式以结合单控制器和多控制器范式,能够灵活地表示和高效地执行 RLHF dataflow,具体来说:
- 提出了一套分层 API,将 RLHF dataflow 中复杂的计算和数据依赖解耦并封装起来,从而支持高效的操作编排和灵活的设备映射
- 设计了一个 3D-HybridEngine,用于在训练和生成阶段对 Actor 模型进行高效的重新分片,实现零内存冗余并显著降低通信开销
- 实验结果:实验表明,和现有的最优基线相比,HybridFlow 可以在运行各种 RLHF 训练任务时带来 1.53x~20.57x 的吞吐量提升
方案细节
- 下图展示了 HybridFlow 和采用多控制器范式的 RLHF 训练框架(如 OpenRLHF)的差异。与前者相比,后者存在不够灵活(如计算和数据依赖相互耦合)和不够高效(如更高的数据通信开销)的缺点
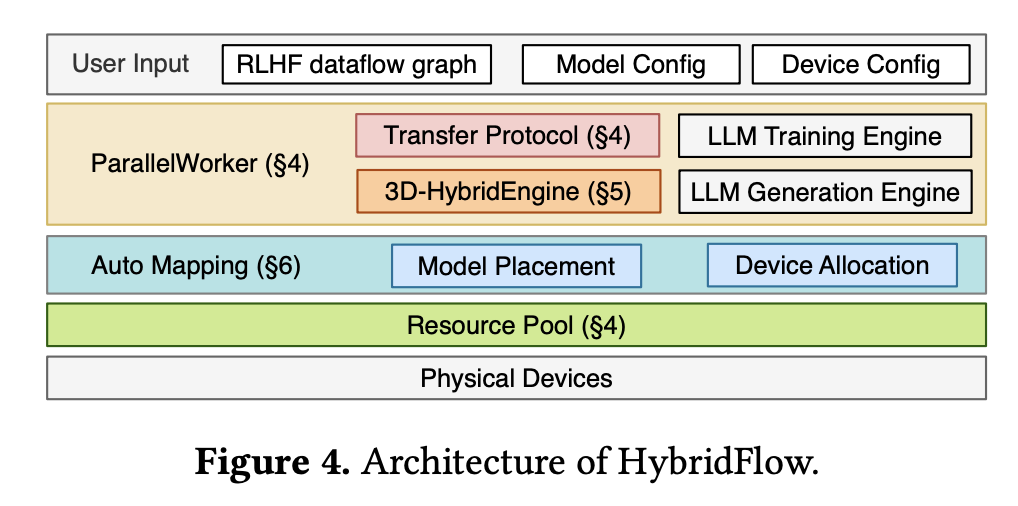
- 下图展示了 HybridFlow 的整体架构,它包含三个主要组件:
- Hybrid Programming Model (混合编程模型):包含一组分层 API,以实现 RLHF 数据流的灵活表达和数据流中模型的高效计算
- 3D-HybridEngine:专为 Actor 模型的高效训练和生成设计,允许在两个阶段中采用不同的 3D 并行配置,从而实现零内存冗余,并在两个阶段之间的转换过程中最大限度地减少通信开销
- Auto Device Mapping algorithm (自动设备映射算法):用于确定每个模型的最佳硬件部署方案,以最大限度地提高 RLHF 的吞吐量
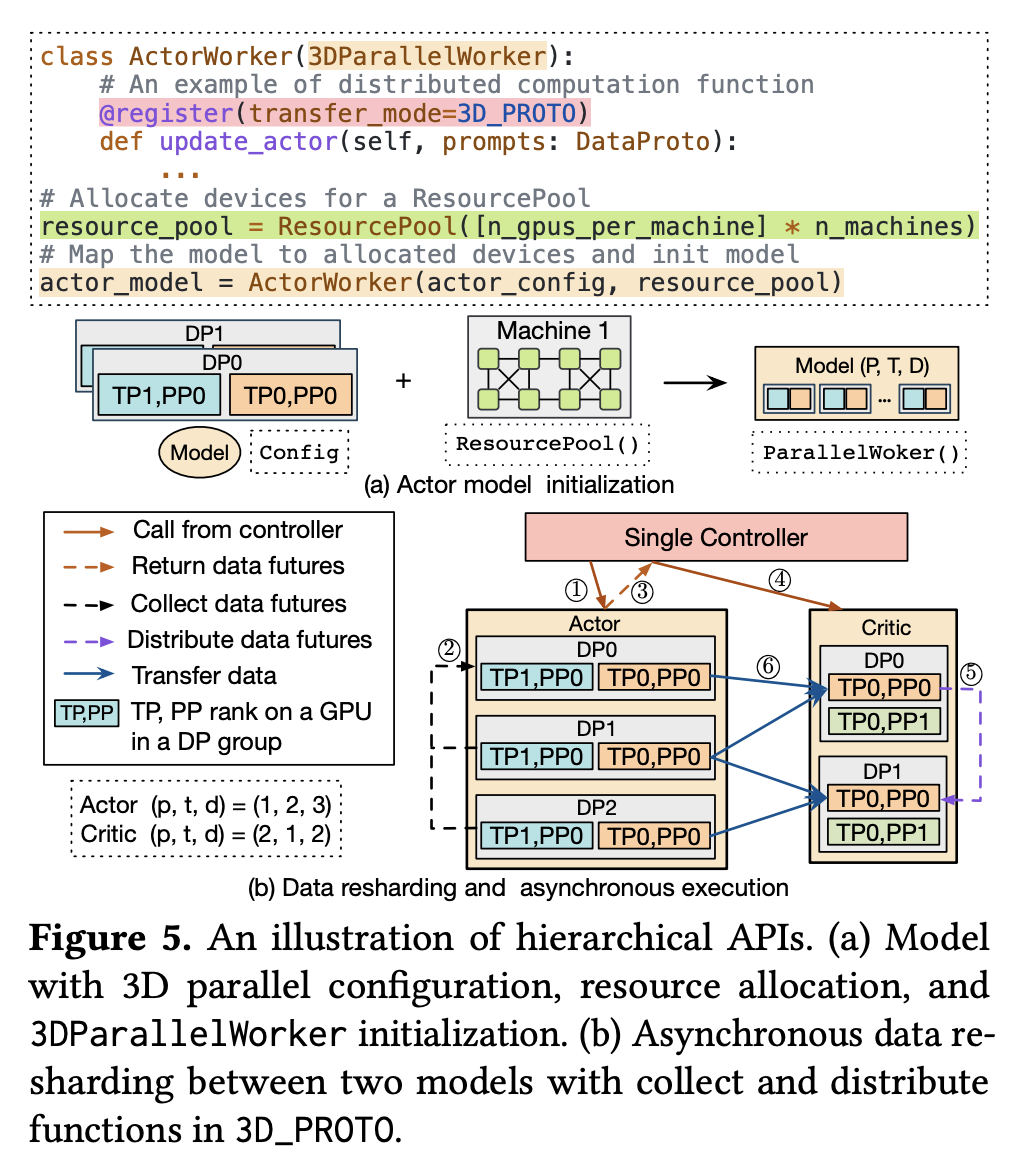
Hybrid Programming Model (混合编程模型)
- Intra-Node(节点内):HybridFlow 在节点内采用多控制器范式,每个节点都能在指定的计算资源上实现单独的分布式计算。HybridFlow 提供了一个 3DParallelWorker 类,作为模型类(如 Actor Model 类)的基类。它支持分布式模型权重初始化,并为每个模型建立 3D 并行 group,每个 group 都和一组计算资源绑定(通过 ResourcePool),用于承载指定的并行维度(例如 TP 中不同的张量分片或 DP 中不同的模型副本)
- 除此以外,HybridFlow 还提供了基于 FSDP 和 DeepSpeed ZeRO 的 Worker 基类(FSDPWorker 和 ZeROWorker)以及继承自这些基类的相应的模型类
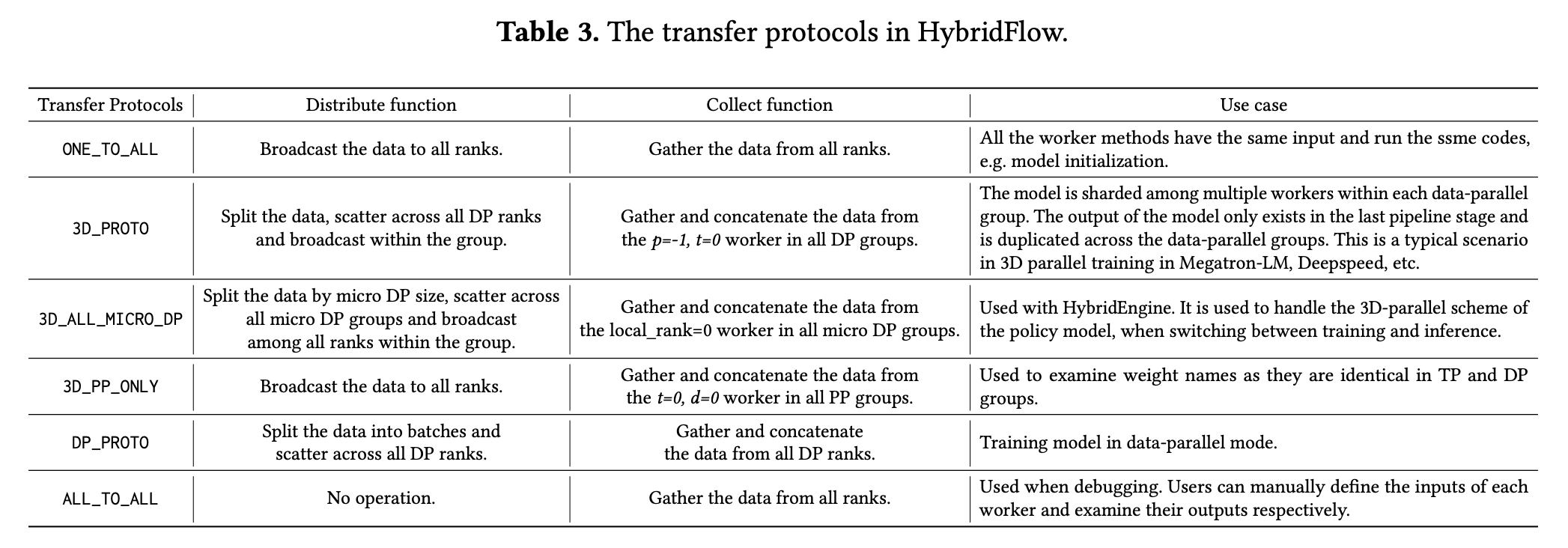
- Inter-Node(节点间):HybridFlow 在节点间采用单控制器范式,通过 @register 装饰器将每个模型类中的具体操作(见 Tab. 4)与一个传输协议关联起来,以在不同设备上使用不同并行策略的模型之间进行数据传输。每个传输协议都包含一个 collect 函数和一个 distribute 函数,用于聚合输出数据和分发输入数据。中心控制节点根据上下游模块的传输协议计算数据重分片策略,实际的数据传输只发生在源 GPU 和目标 GPU 之间,避免了冗余的内存拷贝
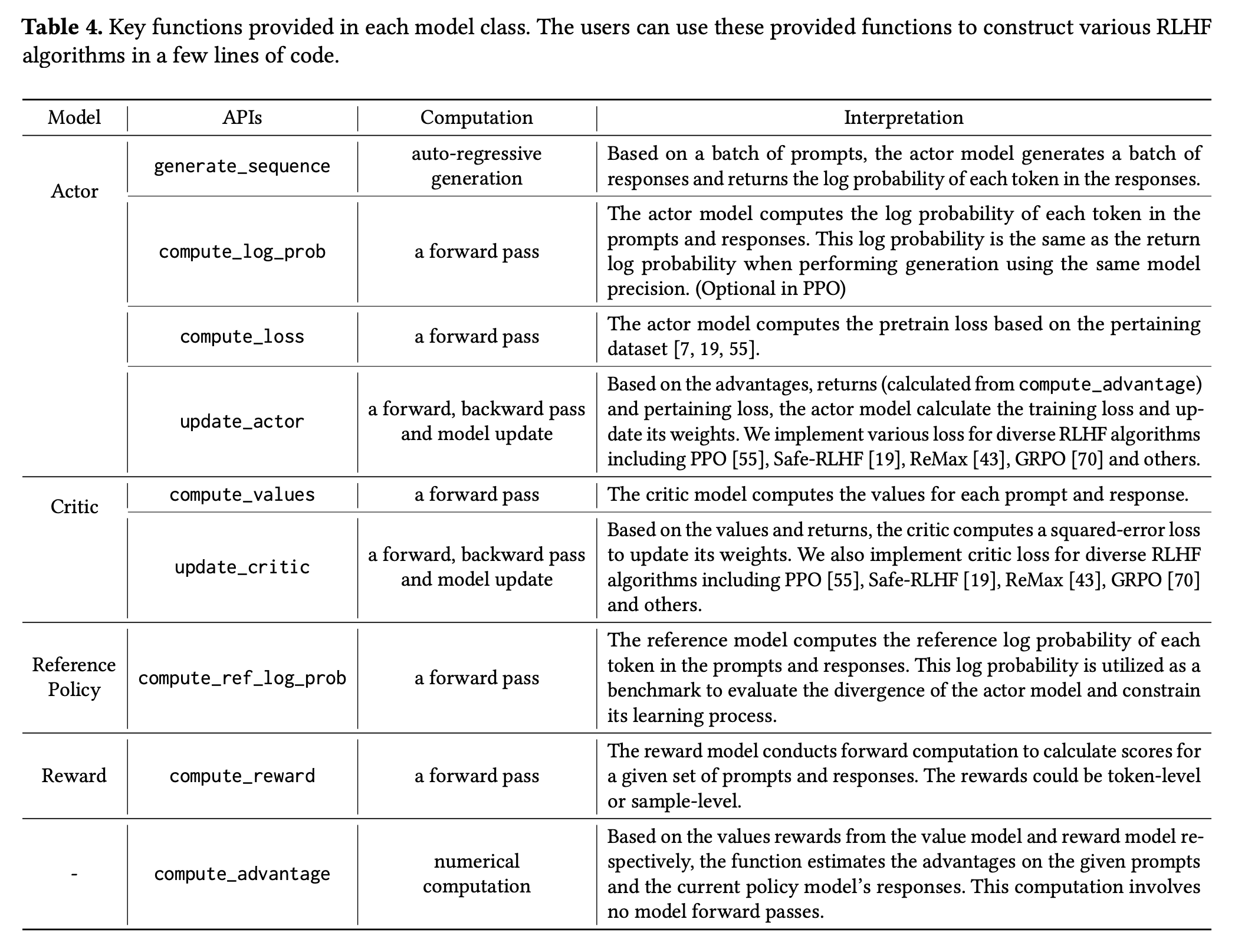
- Tab. 4 展示了 HybridFlow 为每个模型类提供的关键操作(函数):
- 下图展示了 HybridFlow 原生支持的几种数据传输协议:
- ResourcePool:为了支持更加灵活的模型部署,HybridFlow 提供了一个 ResourcePool 类,用于绑定一组 GPU 资源,并建立模型的分布式计算到这些设备的映射。假设不同的 ResourcePool 实例绑定的资源之间没有重叠,那么使用相同的 ResourcePool 实例的模型将共享同一组 GPU 资源,使用不同的 ResourcePool 实例的模型将位于不同的 GPU 上
- Asynchronous:HybridFlow 还提供了异步调用接口。部署在不同 GPU 上的任务节点可以以类似于服务的形式启动,一旦输入可用,就会自动触发该节点的执行函数
- 下图展示了基于 HybridFlow 的分层 API,用户可以通过简单的代码改动适配多种 RLHF 算法

3D-HybridEngine
- 3D-HybridEngine 被设计用于支持 Actor 模型的高效训练和生成,以提高 RLHF 的吞吐量。
- 为了消除冗余的 Actor 模型副本,RLHF 训练框架一般会将训练和生成阶段部署在同一组 GPU 上,并在同一份模型副本上依次执行。但是,训练和生成阶段往往会适配不同的 3D 并行策略,一般来说:
- 训练阶段的核心瓶颈是 GPU 内存容量,因此需要更大的 TP/PP group
- 生成阶段的核心瓶颈是 GPU 计算速度,因此需要更大的 DP group
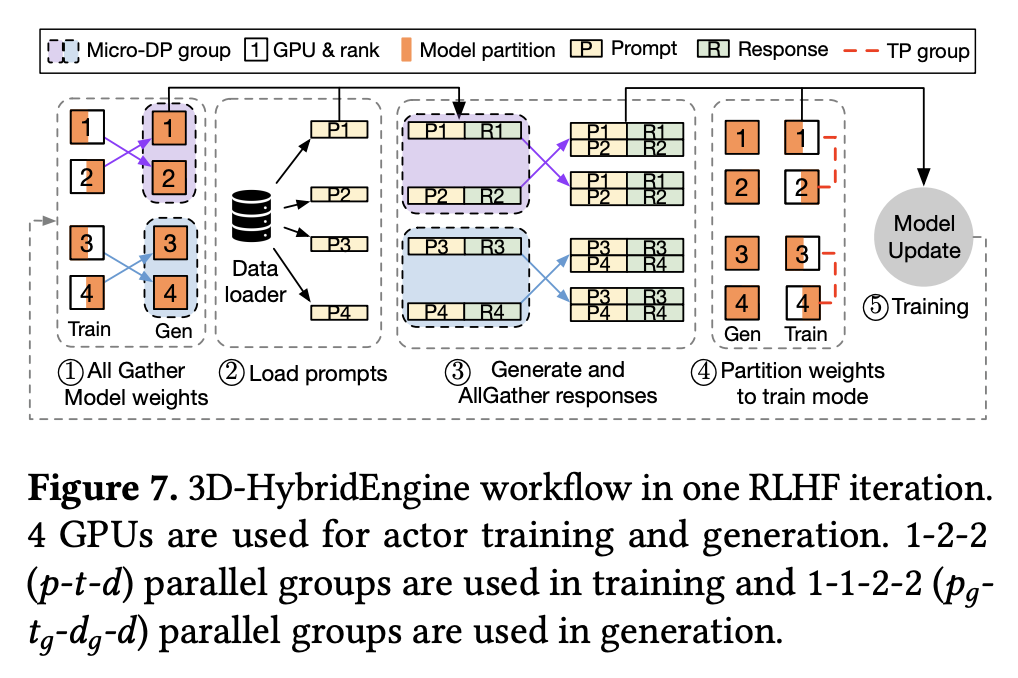
- HybridFlow 提出了一种方法,可以在 Actor 模型的训练和生成阶段之间高效地重分片模型参数。具体来说:假设模型在训练阶段的 3D 并行配置可以用三元组 <PP, TP, DP> 表示。在生成阶段,模型往往会采用更小的 PP/TP group,记为 PPɢ, TPɢ,此时,会有部分 PP/TP group 转换为 DP group,记为 micro DP group,micro DP group 的 group size
,则生成阶段的 3D 并行配置可以描述为四元组 <PPɢ, TPɢ, DPɢ, DP>
- 下图描述了一个训练阶段并行配置为 PP=1, TP=2, DP=2,生成阶段并行配置为 PPɢ=1, TPɢ=1, DPɢ=2, DP=2 的场景:
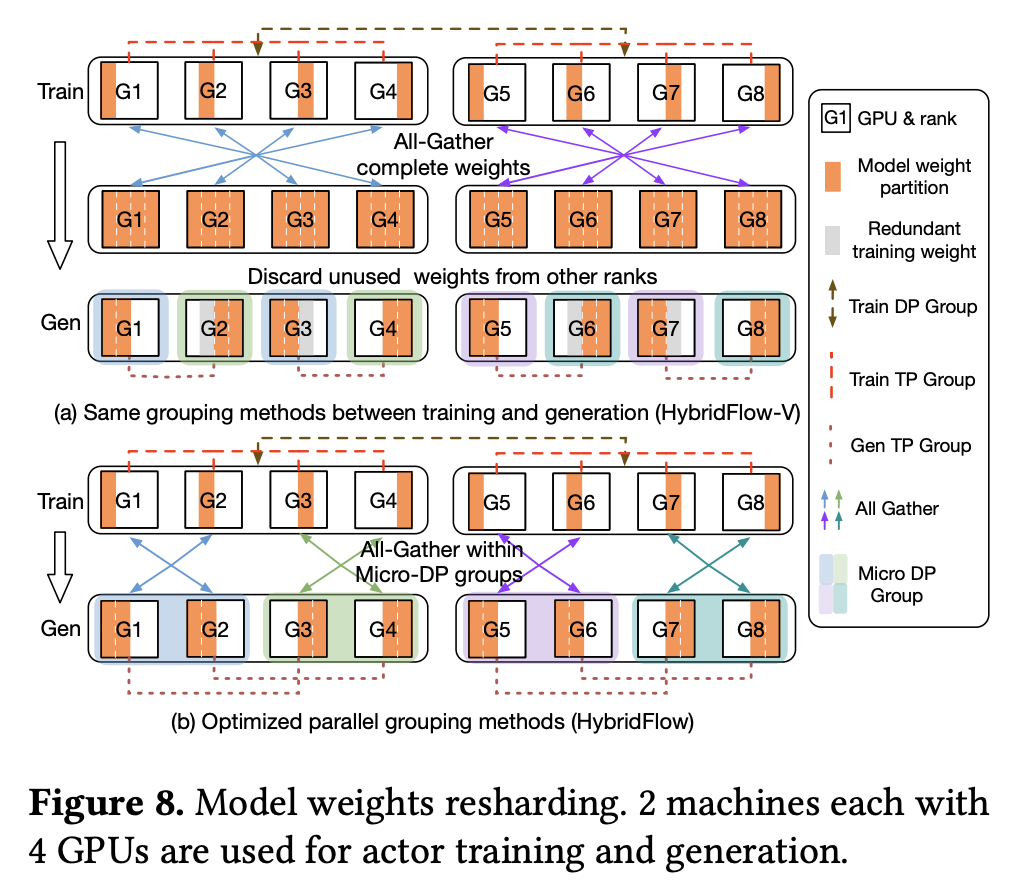
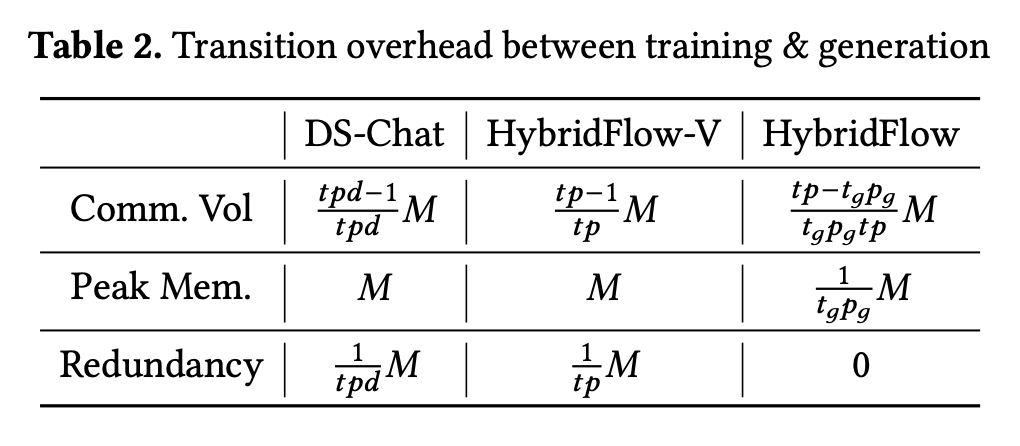
- 此外,对于某些更加复杂的场景(如下图 (a) 所示),传统的并行分组策略(下文称“HybridFlow-V”)可能会导致同一块 GPU 上用于训练和生成的模型权重之间没有重叠,进而需要单独的内存来保存两部分权重。为了解决这个问题,HybridFlow 提出了一种并行分组方法,通过更精密的计算,确保每块 GPU 上的生成阶段都尽可能复用训练阶段的模型权重,实现了零内存冗余的模型重分片,并且显著降低了通信开销
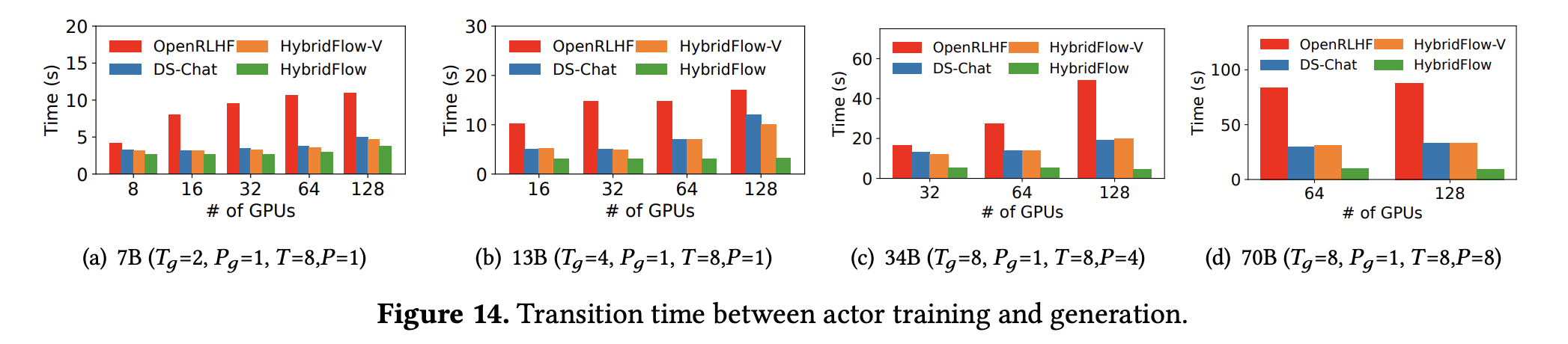
- 下图展示了 HybridFlow、HybridFlow-V 和 DeepSpeed-Chat 在训练/生成阶段转换过程中的通信量(Communication Volume)、峰值内存(Peak Memory)和内存冗余(Memory Redundancy):
Auto Device Mapping algorithm (自动设备映射算法)
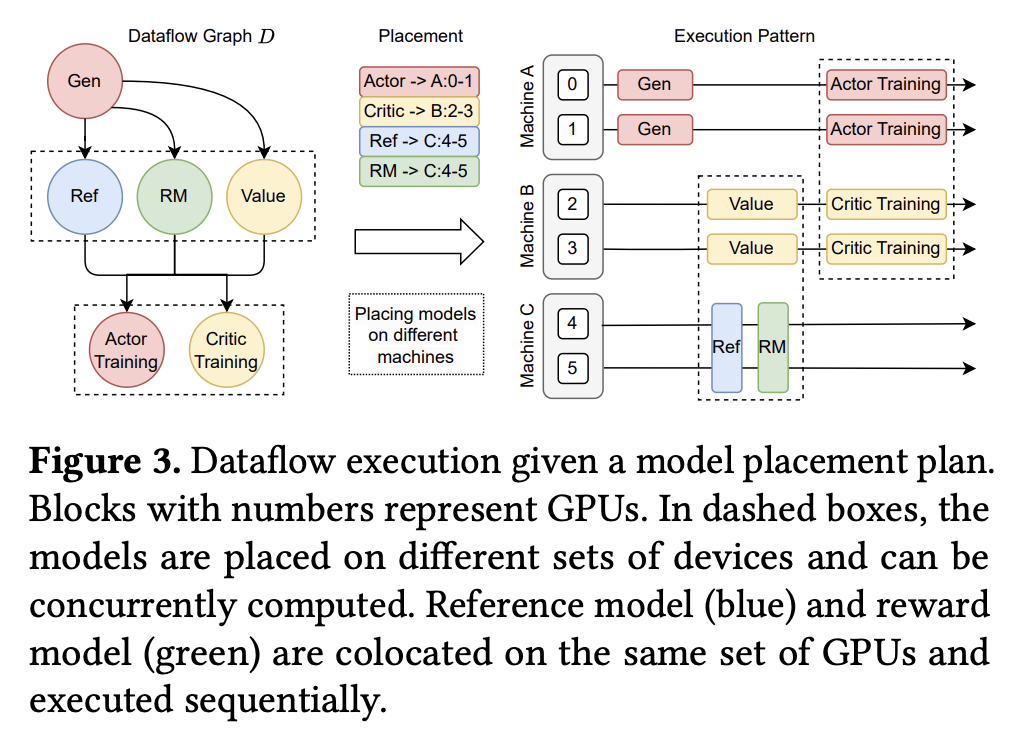
- 下图展示了一个模型硬件部署示例:虚线框内的模型部署在不同的 GPU 上,可以同时运行;其中 Reference Model 和 Reward Model 部署在同一组 GPU 上,并按顺序执行
- HybridFlow 提出了一种高效的算法,帮助在给定的设备集群上确定执行 RLHF 数据流的最佳硬件部署方案
- 首先,对于给定的 RLHF 数据流,HybridFlow 检索所有可能的分组方案。例如,PPO 算法涉及四个模型,由此可以产生 15 种可能的分组方案(基于贝尔数 B(4)=15),涵盖从完全独立的部署方式(所有模型都位于不同的设备上),到所有模型都部署在同一组设备上之间的所有可能性
- HybridFlow 将部署在同一组 GPU 上的模型称为共置模型集(colocated set),共置模型集可以在同一组 GPU 上采用不同的并行策略。HybridFlow 根据每个模型的内存消耗情况确定分配给共置模型集的最小 GPU 数量,以确保不会发生内存溢出
- 接下来,从最小 GPU 分配数量开始,对每个共置模型集枚举所有可行的设备分配方案。然后将所有设备分配方案和模型工作负载(包括各模块的输入输出 shape、任务类型(train、infer 或 generation)和模型计算图)输入 auto_parallel 模块中探索最优的设备分配方案

- 下图展示了 auto_parallel 模块通过 simu 仿真器搜索最优设备分配方案的工作流程。该模块包含 train、infer、generation 三个仿真器,其原理主要来自以下几篇研究:

- 一般来说,train 和 infer 过程的执行效率主要受限于计算资源,generation 过程的执行效率主要受限于内存大小
实验结果
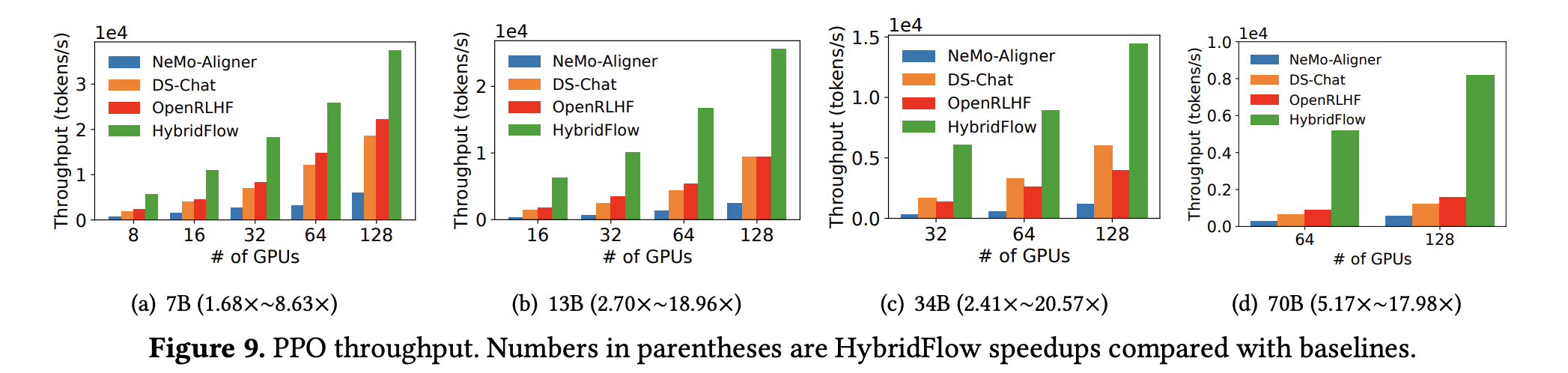
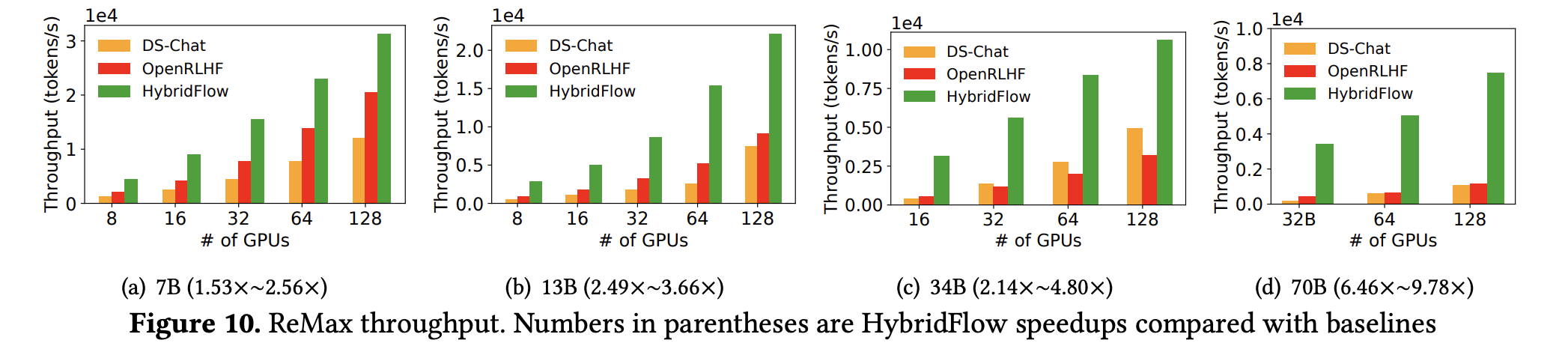
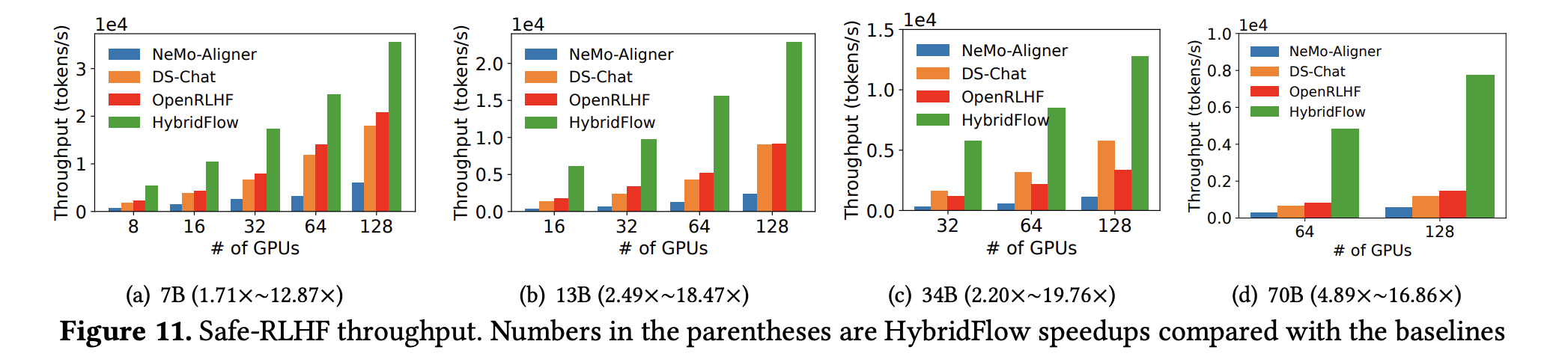
- 下图展示了 HybridFlow 和几种主流框架在不同规模集群上运行 PPO/ReMax/Safe-RLHF 训练任务时的吞吐量对比
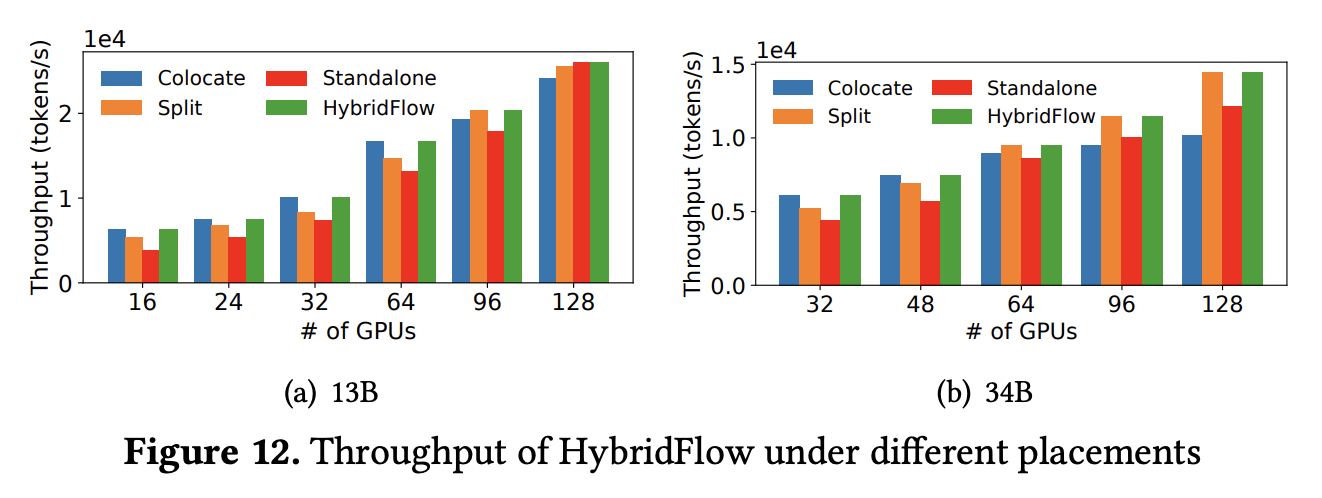
- 下图展示了几种不同的硬件部署策略在不同规模集群上运行训练任务时的吞吐量对比。几种策略包括:
- Colocate:将所有模型部署到同一组 GPU 上
- Standalone:为每个模型分配一组独立且专属的 GPU 设备,彼此隔离
- Split:一种部分共享的策略,将 Actor Model 和 Reference Model 放在一组设备上,将 Critic Model 和 Reward Model 放在另一组设备上
- HybridFlow:基于自动设备映射算法搜索出的最优硬件部署策略
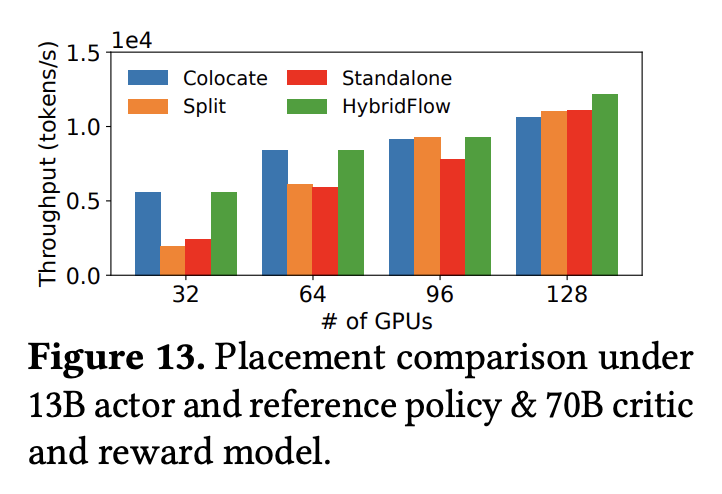
- 下图展示了几种不同的硬件部署策略在不同规模集群上运行包含更大规模的 Critic Model 和 Reward Model 的训练任务时的吞吐量对比
- 下图展示了HybridFlow 和几种主流框架在不同规模集群上运行训练任务时训练和生成阶段转换过程的延迟对比
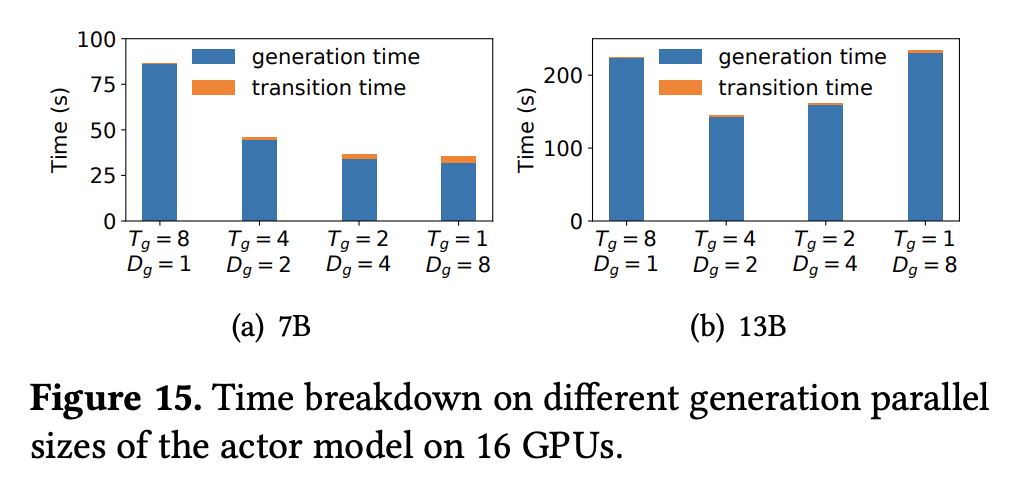
- 其它消融实验

三、Installation
- 在本地环境中安装 verl:
- 从 GitHub 上 clone 源码:
git clone https://github.com/volcengine/verl && cd verl - 运行以下官方脚本安装依赖:
bash scripts/install_vllm_sglang_mcore.sh - 安装 verl:
pip install --no-deps -e .
- 从 GitHub 上 clone 源码:
- 运行 Qwen2.5-0.5B-Instruct + gsm8k dataset + PPO demo 验证全链路能否正常运行(可以在单卡 20GB 显存上稳定运行):
- 下载 gsm8k 数据集:
python examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k - 从 HuggingFace 模型库中下载 Qwen2.5-0.5B-Instruct pretrained model 到本地:
python -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2.5-0.5B-Instruct')" - 参考官方文档,运行以下指令启动训练程序:
set -x PYTHONUNBUFFERED=1 python3 -m verl.trainer.main_ppo \ data.train_files=$HOME/data/gsm8k/train.parquet \ data.val_files=$HOME/data/gsm8k/test.parquet \ data.train_batch_size=256 \ data.max_prompt_length=512 \ data.max_response_length=256 \ actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.actor.ppo_mini_batch_size=64 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.name=vllm \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.rollout.tensor_model_parallel_size=1 \ actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \ critic.optim.lr=1e-5 \ critic.model.path=Qwen/Qwen2.5-0.5B-Instruct \ critic.ppo_micro_batch_size_per_gpu=4 \ algorithm.kl_ctrl.kl_coef=0.001 \ trainer.logger=console \ trainer.val_before_train=False \ trainer.n_gpus_per_node=1 \ trainer.nnodes=1 \ trainer.save_freq=10 \ trainer.test_freq=10 \ trainer.total_epochs=15 2>&1 | tee verl_demo.log - 正常情况下,会打印出如下训练 log:
(TaskRunner pid=34541) step:1 - global_seqlen/min:86471 - global_seqlen/max:86471 - global_seqlen/minmax_diff:0 - global_seqlen/balanced_min:86471 - global_seqlen/balanced_max:86471 - global_seqlen/mean:86471.0 - actor/entropy:0.4333037734031677 - critic/vf_loss:0.7734626512974501 - critic/vf_clipfrac:0.4472669088281691 - critic/vpred_mean:-0.6318991152802482 - critic/grad_norm:440.2209701538086 - perf/mfu/critic:0.07187811295656943 - critic/lr:1e-05 - actor/pg_loss:3.2811580666702866e-05 - actor/pg_clipfrac:0.0012928183041367447 - actor/ppo_kl:3.1984165445919643e-05 - actor/pg_clipfrac_lower:0.0 - actor/grad_norm:2.0488893687725067 - perf/mfu/actor:0.058193844090491775 - perf/max_memory_allocated_gb:16.25859498977661 - perf/max_memory_reserved_gb:19.46484375 - perf/cpu_memory_used_gb:370.43155670166016 - actor/lr:1e-06 - training/global_step:1 - training/epoch:0 - critic/score/mean:0.0078125 - critic/score/max:1.0 - critic/score/min:0.0 - critic/rewards/mean:0.0078125 - critic/rewards/max:1.0 - critic/rewards/min:0.0 - critic/advantages/mean:1.4322458774529423e-08 - critic/advantages/max:4.293451309204102 - critic/advantages/min:-3.7153096199035645 - critic/returns/mean:0.005832956172525883 - critic/returns/max:1.0 - critic/returns/min:0.0 - critic/values/mean:-1.3515625 - critic/values/max:16.5 - critic/values/min:-22.0 - critic/vf_explained_var:-3977.205078125 - response_length/mean:233.05078125 - response_length/max:256.0 - response_length/min:8.0 - response_length/clip_ratio:0.62109375 - response_length_non_aborted/mean:233.05078125 - response_length_non_aborted/max:256.0 - response_length_non_aborted/min:8.0 - response_length_non_aborted/clip_ratio:0.62109375 - response/aborted_ratio:0.0 - prompt_length/mean:104.7265625 - prompt_length/max:189.0 - prompt_length/min:66.0 - prompt_length/clip_ratio:0.0 - timing_s/start_profile:0.00020296871662139893 - timing_s/generate_sequences:5.938582420349121 - timing_s/generation_timing/max:5.938582420349121 - timing_s/generation_timing/min:5.938582420349121 - timing_s/generation_timing/topk_ratio:0.0 - timing_s/gen:8.822729051113129 - timing_s/reward:0.061841510236263275 - timing_s/old_log_prob:5.946002781391144 - timing_s/values:3.688412196934223 - timing_s/adv:0.03226377069950104 - timing_s/update_critic:14.942422717809677 - timing_s/update_actor:18.456213615834713 - timing_s/step:52.054220490157604 - timing_s/stop_profile:5.67510724067688e-05 - timing_per_token_ms/update_actor:0.21343818870875453 - timing_per_token_ms/values:0.04265490392078527 - timing_per_token_ms/adv:0.00037311665991489676 - timing_per_token_ms/update_critic:0.17280270515906693 - timing_per_token_ms/gen:0.14788101190246775 - perf/total_num_tokens:86471 - perf/time_per_step:52.054220490157604 - perf/throughput:1661.1717395009289
- 下载 gsm8k 数据集:
- 运行以下指令可以启动一个 GRPO 训练 demo(基于官方 example:examples/grpo_trainer/run_qwen3-8b.sh 修改,可以在单卡 16GB 显存上稳定运行。该目录下也可以找到其它官方模版):
set -x python3 -m verl.trainer.main_ppo \ algorithm.adv_estimator=grpo \ data.train_files=$HOME/data/gsm8k/train.parquet \ data.val_files=$HOME/data/gsm8k/test.parquet \ data.train_batch_size=256 \ data.max_prompt_length=512 \ data.max_response_length=256 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=64 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=False \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.rollout.tensor_model_parallel_size=1 \ actor_rollout_ref.rollout.name=vllm \ actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \ actor_rollout_ref.rollout.n=1 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen2.5_0.5b_instruct_function_rm' \ trainer.n_gpus_per_node=1 \ trainer.nnodes=1 \ trainer.save_freq=10 \ trainer.test_freq=10 \ trainer.total_epochs=15 2>&1 | tee verl_demo.log
四、源码解析
- Version:0.5.0.dev0
- Branch:main
- Commit:f6b09ace (Thu Sep 11 14:05:02 2025 +0800)
- 显然,上述 PPO 和 GRPO demo 使用相同的程序入口 (verl/trainer/main_ppo),只是指定了不同的 algorithm.adv_estimator 参数。进一步溯源可以发现该参数从以下 enum 中选择:
class AdvantageEstimator(str, Enum):
"""Using an enumeration class to avoid spelling errors in adv_estimator.
Note(haibin.lin): this enum class is immutable after creation. Extending this
enum for new estimators may not be necessary since users can always just call
`verl.trainer.ppo.core_algos.register` with string name for a custom advantage
estimator instead.
"""
GAE = "gae"
GRPO = "grpo"
REINFORCE_PLUS_PLUS = "reinforce_plus_plus"
REINFORCE_PLUS_PLUS_BASELINE = "reinforce_plus_plus_baseline"
REMAX = "remax"
RLOO = "rloo"
OPO = "opo"
GRPO_PASSK = "grpo_passk"
GPG = "gpg"- 这套链路固定使用 ray 负责分布式调度。训练主逻辑以及 PPO 和 GRPO 的差异化实现主要位于 RayPPOTrainer (verl.trainer.ppo.ray_trainer) 类中
- 后面将从这两个 demo 出发,逐步拆解 verl(HybridFlow)的代码逻辑
参数构建
1. verl 通过 hydra 类解析实验 config
- @hydra.main() 装饰器用于标记程序入口
@hydra.main(config_path="config", config_name="ppo_trainer", version_base=None) def main(config): ...- 参数 config_path 和 config_name 共同确定了 config 文件路径(形如 "./config/ppo_trainer.yaml")。解析出的实验 config 会保存为一个 omegaconf.dictconfig.DictConfig 实例,调用方式类似于 easydict
- 此外,hydra 还支持通过命令行传入参数进行局部替换,这在之前的 demo 中已经有应用:
python3 -m verl.trainer.main_ppo \ algorithm.adv_estimator=grpo \ data.train_files=$HOME/data/gsm8k/train.parquet \ data.val_files=$HOME/data/gsm8k/test.parquet \ data.train_batch_size=1024 \ ...
2. config 之间存在嵌套调用关系,形如:
# specify the default per-component configs
defaults:
# <folder_name>@<field_name>.<field_name>: <yaml_file_name>
# actor_rollout_ref.actor: trainer/config/actor/dp_actor.yaml
- actor@actor_rollout_ref.actor: dp_actor
# data: trainer/config/data/legacy_data.yaml
- data@data: legacy_data
...以 "actor@actor_rollout_ref.actor: dp_actor" 为例,其含义为:从 ./actor/dp_actor.yaml 文件中解析 config,赋值给 config.actor_rollout_ref.actor。经统计,PPO/GRPO 任务的实验 config 需要从以下模块中获取:
- Base config:verl/trainer/config/ppo_trainer.yaml
- data:verl/trainer/config/data/legacy_data.yaml
- actor_rollout_ref.actor:verl/trainer/config/actor/dp_actor.yaml
- actor_rollout_ref.ref:verl/trainer/config/ref/dp_ref.yaml
- actor_rollout_ref.rollout:verl/trainer/config/rollout/rollout.yaml
- actor_rollout_ref.model:verl/trainer/config/model/hf_model.yaml
- critic:verl/trainer/config/critic/dp_critic.yaml
- reward_model:verl/trainer/config/reward_model/dp_reward_model.yaml
- 从命令行传入的局部替换 config
3. 也就是说,除了之前从命令行传入的参数以外,PPO 和 GRPO 的基础 config 是完全相同的。当然,如果是 GRPO,实际不需要使用 Critic Model 的相关配置
Worker
1. verl 的基本任务执行单元,通常和 RL dataflow 中的一个或多个任务节点(如 Rollout、Actor Model、Critic Model、Reward Model 等)对应,包含该节点完整的初始化和分布式计算逻辑
2. verl 根据用户指定的底层架构(如 FSDP、Megatron)等为每个任务节点提供了不同的 worker 类,worker 类的选择在 TaskRunner (verl.trainer.main_ppo.TaskRunner) 的 run() 函数中完成(但不会实例化),结果保存为一个 dict(self.role_worker_mapping),它的 key 从枚举 Role (verl.trainer.ppo.utils.Role) 中选取,而 value 则是对应 worker 类的 ray Actor
class Role(Enum):
"""
To create more roles dynamically, you can subclass Role and add new members
"""
Actor = 0
Rollout = 1
ActorRollout = 2
Critic = 3
RefPolicy = 4
RewardModel = 5
ActorRolloutRef = 63. 对于 PPO/GRPO,它需要通过以下 worker 构建完整的 dataflow:
-
Role.ActorRollout -> ray.remote(ActorRolloutRefWorker) (verl.workers.fsdp_workers.ActorRolloutRefWorker)
-
在 add_actor_rollout_worker 函数中根据 config 中指定的 actor_rollout_ref.actor.strategy 和 actor_rollout_ref.rollout.mode 选择对应的类,默认 strategy="fsdp"、mode="sync"
if config.actor_rollout_ref.actor.strategy in {"fsdp", "fsdp2"}: from verl.workers.fsdp_workers import ActorRolloutRefWorker, AsyncActorRolloutRefWorker actor_rollout_cls = ( AsyncActorRolloutRefWorker if config.actor_rollout_ref.rollout.mode == "async" else ActorRolloutRefWorker ) ray_worker_group_cls = RayWorkerGroup elif config.actor_rollout_ref.actor.strategy == "megatron": from verl.workers.megatron_workers import ActorRolloutRefWorker, AsyncActorRolloutRefWorker actor_rollout_cls = ( AsyncActorRolloutRefWorker if config.actor_rollout_ref.rollout.mode == "async" else ActorRolloutRefWorker ) ray_worker_group_cls = RayWorkerGroup else: raise NotImplementedError from verl.trainer.ppo.ray_trainer import Role self.role_worker_mapping[Role.ActorRollout] = ray.remote(actor_rollout_cls)
-
-
Role.Critic -> ray.remote(CriticWorker) (verl.workers.fsdp_workers.CriticWorker)
-
根据 config 中指定的 critic.strategy 和 trainer.use_legacy_worker_impl 选择对应的类,默认 strategy="fsdp"、use_legacy_worker_impl="auto"
-
-
Role.RefPolicy -> ray.remote(ActorRolloutRefWorker)(和 Role.ActorRollout 相同)
-
Role.RewardModel -> ray.remote(RewardModelWorker) (verl.workers.fsdp_workers.RewardModelWorker)
-
根据 config 中指定的 critic.strategy 和 trainer.use_legacy_worker_impl 选择对应的类,默认 strategy="fsdp"、use_legacy_worker_impl="auto"
-
4. role_worker_mapping 要被传入 RayPPOTrainer 类,并在其中通过 RayClassWithInitArgs 类实例化
# Initialize the PPO trainer.
trainer = RayPPOTrainer(
config=config,
tokenizer=tokenizer,
processor=processor,
role_worker_mapping=self.role_worker_mapping, # <- Here
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn,
train_dataset=train_dataset,
val_dataset=val_dataset,
collate_fn=collate_fn,
train_sampler=train_sampler,
)5. worker 类中并没有显示地定义 __call__() 或者 forward() 函数,它的关键操作通过 @register 装饰器声明并关联到一个指定的传输协议,形如:
@register(dispatch_mode=make_nd_compute_dataproto_dispatch_fn(mesh_name="rollout"))
def generate_sequences(self, prompts: DataProto):
....6. @register 装饰器主要做了如下操作:
def register(dispatch_mode=Dispatch.ALL_TO_ALL, execute_mode=Execute.ALL, blocking=True, materialize_futures=True):
"""Register a function with distributed execution configuration.
This decorator registers a function with specific dispatch and execution modes
for distributed computation. It handles both synchronous and asynchronous
functions, and optionally materializes futures before execution.
Args:
dispatch_mode:
Dispatch mode for computation distribution. Default: Dispatch.ALL_TO_ALL.
execute_mode:
Execute mode for computation distribution. Default: Execute.ALL.
blocking:
Whether the execution should be blocking. Defaults to True.
materialize_futures:
Whether to materialize the data before dispatching. Defaults to True.
Returns:
A decorator that wraps the original function with distributed execution
configuration.
"""
_check_dispatch_mode(dispatch_mode=dispatch_mode)
_check_execute_mode(execute_mode=execute_mode)
def decorator(func):
@wraps(func)
def inner(*args, **kwargs):
if materialize_futures:
args, kwargs = _materialize_futures(*args, **kwargs)
return func(*args, **kwargs)
@wraps(func)
async def async_inner(*args, **kwargs):
if materialize_futures:
args, kwargs = _materialize_futures(*args, **kwargs)
return await func(*args, **kwargs)
wrapper = async_inner if inspect.iscoroutinefunction(func) else inner
attrs = {"dispatch_mode": dispatch_mode, "execute_mode": execute_mode, "blocking": blocking}
setattr(wrapper, MAGIC_ATTR, attrs)
return wrapper
return decorator- 首先,它为函数添加了一个 MAGIC_ATTR 属性(MAGIC_ATTR = "attrs_3141562937"),以标记“关键操作”
- 然后,它在 MAGIC_ATTR 属性中储存了该函数在分布式计算时的传输协议,这是一个 dict,其中:
- dispatch_mode 包含了函数在分发输入数据和聚合输出数据时的行为模式
- execute_mode 包含了函数在执行时的行为模式
- blocking 表示是否要等待多进程同步
def dispatch_all_to_all(worker_group, *args, **kwargs):
return args, kwargs
def collect_all_to_all(worker_group, output):
return output
attrs = {
"dispatch_mode": {
"dispatch_fn": dispatch_all_to_all,
"collect_fn": collect_all_to_all,
},
"execute_mode": {
"execute_fn_name": "execute_all", # <- 函数定义在 WorkerGroup 中
},
"blocking": True,
}
- 最后,它在函数执行前调用 DataProtoFuture.get() 函数,以执行实际的数据传输操作,获取函数输入
7. 经过 @register 装饰器声明的函数,之后会绑定到 WorkerGroup,并通过 WorkerGroup 调用
8. 对于 PPO/GRPO 的相关 worker,有以下函数需要声明并绑定到 WorkerGroup
- ActorRolloutRefWorker (verl.workers.fsdp_workers.ActorRolloutRefWorker)
- generate_sequences():执行 rollout 操作
- compute_log_prob():计算重要性采样
- compute_ref_log_prob():计算 KL 散度
- compute_ref_log_prob():更新策略网络
- init_model()、save_checkpoint()、load_checkpoint() ...
- CriticWorker (verl.workers.fsdp_workers.CriticWorker)
- compute_values():计算状态价值
- update_critic():更新价值网络
- init_model()、save_checkpoint()、load_checkpoint() ...
- RewardModelWorker (verl.workers.fsdp_workers.RewardModelWorker)
- compute_rm_score():计算 reward score
- init_model() ...
9. 由于 RLHF dataflow 并不是单一的分布式程序,它需要多个分布式任务节点协同配合,并且每个分布式节点都可能和不同的计算资源绑定,因此 verl 通过 WorkerGroup 进一步封装了节点内资源调度以及分布式运算的相关操作(对应论文中的 Intra-Node),这里还需要 ResourcePool 和 ClassWithInitArgs 两个类的支持
ResourcePool
1. RayResourcePool (verl.single_controller.ray.base.RayResourcePool) 的底层是 ray 的 PlacementGroup (ray.util.placement_group.PlacementGroup)
PlacementGroup
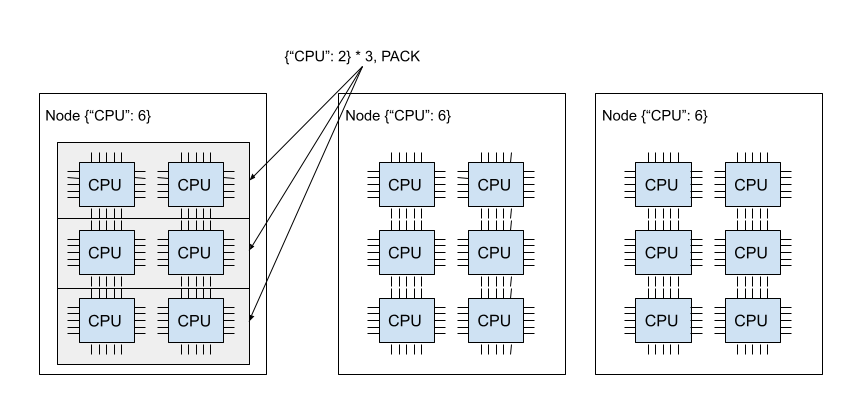
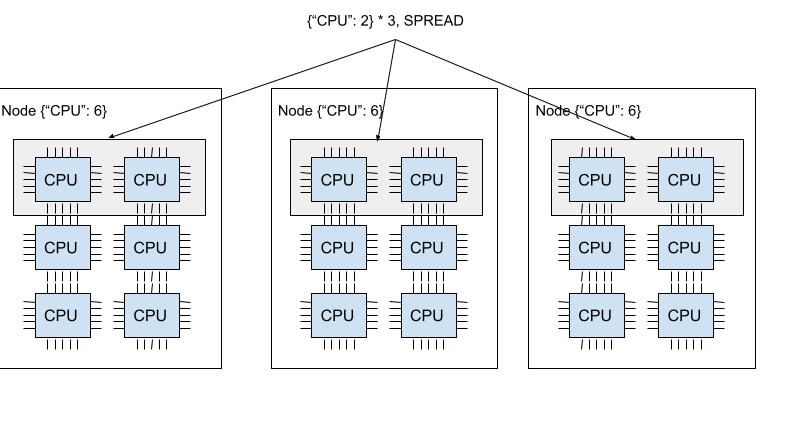
- ray 的 PlacementGroup 允许用户以原子化的形式跨设备节点预留计算资源,并将资源和 ray Task 或 Actor 绑定。PlacementGroup 支持多种跨设备节点资源调度策略:
- PACK:默认策略。优先将所有 bundle 调度到单个设备节点上;如果无法满足条件,则调度到其它设备节点
- SPREAD:优先将所有 bundle 均匀分散到不同设备节点上;如果无法满足条件,则多个 bundle 可能会被调度到同一设备节点上
- STRICT_PACK:必须将所有 bundle 调度到单个设备节点上;如果无法满足条件,则创建失败
- STRICT_SPREAD:必须将所有 bundle 均匀分散到不同设备节点上;如果无法满足条件,则创建失败
- 一个 placement group 由一组 bundle 组成。每个 bundle 都包含一定数量的 CPU 和 GPU,代表一组需要预留的资源,需要注意 bundle 内的资源不能跨设备节点调度。下面的代码创建了一个包含一个 bundle 的 placement group,这个 bundle 中包含一个 CPU 和一个 GPU:
from pprint import pprint import time # Import placement group APIs. from ray.util.placement_group import ( placement_group, placement_group_table, remove_placement_group, ) from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy # Initialize Ray. import ray # Create a single node Ray cluster with 2 CPUs and 2 GPUs. ray.init(num_cpus=2, num_gpus=2) # Reserve a placement group of 1 bundle that reserves 1 CPU and 1 GPU. pg = placement_group([{"CPU": 1, "GPU": 1}], strategy="PACK")
- placement group 只能由使用 PlacementGroupSchedulingStrategy 的 Task 或 Actor 使用。下面的代码分别在 placement group 上部署了一个占用 1CPU 和占用 1GPU 的 ray Actor:
@ray.remote(num_cpus=1) class Actor: def __init__(self): pass def ready(self): pass # Create an actor to a placement group. actor = Actor.options( scheduling_strategy=PlacementGroupSchedulingStrategy( placement_group=pg, ) ).remote() # Verify the actor is scheduled. ray.get(actor.ready.remote(), timeout=10)@ray.remote(num_cpus=0, num_gpus=1) class Actor: def __init__(self): pass def ready(self): pass actor2 = Actor.options( scheduling_strategy=PlacementGroupSchedulingStrategy( placement_group=pg, placement_group_bundle_index=0, ) ).remote() # Verify that the GPU actor is scheduled. ray.get(actor2.ready.remote(), timeout=10)
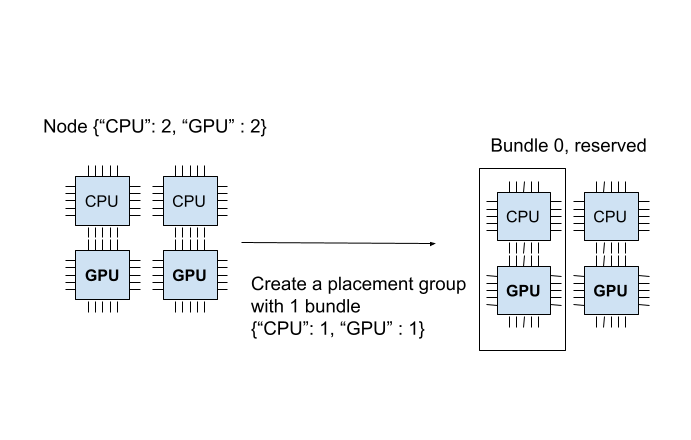
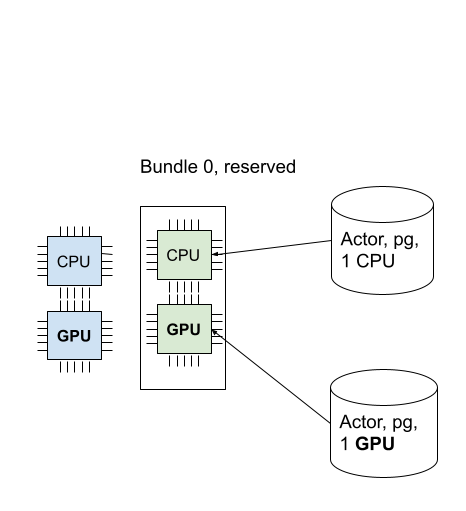
2. RayResourcePool 在 PlacementGroup 的基础上做了一层封装:它接收当前 resource pool 可用的设备节点数量和每个设备节点包含的 GPU 数量,为每个设备节点构建了一个 placement group,其中每个 bundle 包含一块 GPU。RayResourcePool 拦截了 PlacementGroup 的跨设备节点资源调度策略,并在 WorkerGroup 的 _init_with_resource_pool 函数中手动管理 worker 和 bundle 的绑定,从而实现细粒度的资源管理
3. RayResourcePool 的调用入口在 TaskRunner (verl.trainer.main_ppo.TaskRunner) 的 init_resource_pool_mgr 函数中,这个函数定义了 Role 到资源池的映射(使用相同资源池的任务节点共享计算资源,即共置模型集),并通过一个 ResourcePoolManager (verl.trainer.ppo.ray_trainer.ResourcePoolManager) 实例对多个资源池进行管理
resource_pool_spec = {
"global_pool": [8, 8, 8, 8, 8, 8, 8, 8] # <- 64 GPU
}
mapping = {
Role.ActorRollout: "global_pool",
Role.Critic: "global_pool",
Role.RefPolicy: "global_pool",
Role.Reward: "global_pool",
}
resource_pool_manager = ResourcePoolManager(
resource_pool_spec=resource_pool_spec,
mapping=mapping,
)4. ResourcePoolManager 根据 resource_pool_spec 参数构建 RayResourcePool (verl.single_controller.ray.base.RayResourcePool) 实例
resource_pool_dict = {
"global_pool" = <verl.single_controller.ray.base.RayResourcePool object at 0x7f2981481000>
}5. RayResourcePool 对 resource_pool_spec 中的每个设备节点构建了一个 PlacementGroup,每个 PlacementGroup 又由 1GPU 和 1CPU 的 bundle 构成
pgs = [
<ray.util.placement_group.PlacementGroup object at 0x7f2968574550>,
...
]ClassWithInitArgs
1. 现在我们已经得到了 ray Actor 和 ray PlacementGroup,RayClassWithInitArgs (verl.single_controller.ray.base.RayClassWithInitArgs) 的作用就是将 worker 绑定到给定的计算资源上,其核心逻辑是调用 ray.actor.ActorClass.options 函数,指定 PlacementGroupSchedulingStrategy 策略并传入设备参数
def __call__(...):
...
options = {
"scheduling_strategy": PlacementGroupSchedulingStrategy(
placement_group=placement_group,
placement_group_bundle_index=placement_group_bundle_idx
)
}
...
return self.cls.options(**options).remote(*self.args, **self.kwargs)2. RayClassWithInitArgs 的调用入口在 RayPPOTrainer 类的 init_workers 函数中,它接收之前构建的 ray Actor,并将其保存为 self.cls 类变量
# create actor and rollout
if self.hybrid_engine:
resource_pool = self.resource_pool_manager.get_resource_pool(Role.ActorRollout)
actor_rollout_cls = RayClassWithInitArgs(
cls=self.role_worker_mapping[Role.ActorRollout],
config=self.config.actor_rollout_ref,
role="actor_rollout",
)
self.resource_pool_to_cls[resource_pool]["actor_rollout"] = actor_rollout_cls
else:
raise NotImplementedError3. 对于所有 worker,构建 RayResourcePool 到 RayClassWithInitArgs 实例的映射
self.resource_pool_to_cls = {
<verl.single_controller.ray.base.RayResourcePool object>: {
"actor_rollout": <verl.single_controller.ray.base.RayClassWithInitArgs object>,
"critic": <verl.single_controller.ray.base.RayClassWithInitArgs object>,
"ref": <verl.single_controller.ray.base.RayClassWithInitArgs object>,
"rm": <verl.single_controller.ray.base.RayClassWithInitArgs object>,
},
}4. 之后遍历所有 resource pool,这里会调用一个 create_colocated_worker_cls() 函数,它的作用是将部署在同一 resource pool 上的 worker 统一构建为一个共置 worker
for resource_pool, class_dict in self.resource_pool_to_cls.items():
worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
wg_dict = self.ray_worker_group_cls(
resource_pool=resource_pool,
ray_cls_with_init=worker_dict_cls,
**wg_kwargs,
)
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
all_wg.update(spawn_wg)5. 然后将这个共置 worker 绑定到一个公用的 WorkerGroup(包括对应的 ResourcePool 和 ClassWithInitArgs)。最后,为了增强代码可读性,又利用 WorkerGroup 的 spawn 函数,将这个公用的 WorkerGroup 拆解为原本的多个 WorkerGroup,这样就可以在接口不变的情况下共享多个 worker 的资源池
WorkerGroup
1. RayWorkerGroup (verl.single_controller.ray.base.RayWorkerGroup) 负责根据上述 Worker、ResourcePool、ClassWithInitArgs,完成计算和设备资源的绑定,确保中心控制节点可以不考虑资源分配及调度问题,直接调用 WorkerGroup 暴露出来的接口,就可以串联起整个训练流程,形如:
batch: DataProto = DataProto.from_single_dict(batch_dict)
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
batch = batch.union(gen_batch_output)
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
batch = batch.union(old_log_prob)
ref_log_prob = self.actor_rollout_wg.compute_ref_log_prob(batch)
batch = batch.union(ref_log_prob)
critic_output = self.critic_wg.update_critic(batch)
critic_output_metrics = reduce_metrics(critic_output.meta_info["metrics"])
metrics.update(critic_output_metrics)
actor_output = self.actor_rollout_wg.update_actor(batch)
actor_output_metrics = reduce_metrics(actor_output.meta_info["metrics"])
metrics.update(actor_output_metrics)2. RayWorkerGroup 的核心参数是 resource_pool 和 ray_cls_with_init,后者已经和 worker 建立绑定关系。RayWorkerGroup 的 __init__ 首先调用类函数 _init_with_resource_pool,该函数的核心逻辑是调用 ray_cls_with_init 的 __call__ 函数,将 ray_cls_with_init 和指定的 resource_pool 绑定
3. 显然,ray_cls_with_init 的 __call__ 函数只能接受一个 placement group 作为参数,因此,ray_cls_with_init 通过循环调用,对每个 placement group 生成一个 ray Actor 实例,从而构建了一个 worker 组
for pg_idx, pg in enumerate(sort_placement_group_by_node_ip(pgs)):
...
# create a worker
worker = ray_cls_with_init(
placement_group=pg,
placement_group_bundle_idx=local_rank,
use_gpu=use_gpu,
num_gpus=num_gpus,
device_name=self.device_name,
)
self._workers.append(worker)
self._worker_names.append(name)4. 然后,RayWorkerGroup 的 __init__ 调用 super()._bind_worker_method 函数,这个函数的作用是:(1) 将 worker 类中的关键操作(即前文通过 @register 装饰器声明过的函数)绑定 MAGIC_ATTR 属性中指定的传输协议。func_generator() 函数接收函数 method_name 作为参数,输出新的可执行对象,在函数执行前后分别调用 dispatch_fn 和 execute_fn 函数,以实现数据的分发和收集
def func_generator(self, method_name, dispatch_fn, collect_fn, execute_fn, blocking):
class Functor:
def __call__(this, *args, **kwargs):
args, kwargs = dispatch_fn(self, *args, **kwargs)
padding_count = kwargs.pop(_padding_size_key, 0)
output = execute_fn(method_name, *args, **kwargs)
if blocking:
output = ray.get(output)
output = collect_fn(self, output)
if padding_count > 0:
if isinstance(output, DataProto):
indices = [i for i in range(len(output))][:-padding_count]
output = output.select_idxs(indices)
elif isinstance(output, list):
output = output[:-padding_count]
return output
# use class type to pass the method_name to get a better observability
return type(method_name, (Functor,), {})()同样在上述函数中,WorkerGroup 通过 execute_fn 指定分布式执行策略,通过之前定义的 worker 组(self._workers)调用 worker 类函数以实现分布式调用
def _execute_remote_single_worker(self, worker, method_name: str, *args, **kwargs):
"""Execute a method on a single worker remotely.
Args:
worker: The worker actor handle
method_name: Name of the method to execute
*args: Positional arguments for the method
**kwargs: Keyword arguments for the method
Returns:
Remote object reference to the method execution
"""
if self.fused_worker_used and method_name not in self.method_names:
remote_call = getattr(worker, self.fused_worker_execute_fn_name)
return remote_call.remote(f"{self.sub_cls_name}_fwmn_{method_name}", *args, **kwargs)
# fused worker not used
remote_call = getattr(worker, method_name)
return remote_call.remote(*args, **kwargs)
def execute_all_async(self, method_name: str, *args, **kwargs):
"""Execute a method on all workers asynchronously.
Args:
method_name: Name of the method to execute
*args: Positional arguments for the method
**kwargs: Keyword arguments for the method
Returns:
List of remote object references to the method executions
"""
# Here, we assume that if all arguments in args and kwargs are lists,
# and their lengths match len(self._workers), we'll distribute each
# element in these lists to the corresponding worker
# print(f"execute_all_async: method {method_name}({args}, {kwargs})")
length = len(self._workers)
if all(isinstance(arg, list) for arg in args) and all(isinstance(kwarg, list) for kwarg in kwargs.values()):
if all(len(arg) == length for arg in args) and all(len(kwarg) == length for kwarg in kwargs.values()):
# print(f"splitting args and kwargs into {length} shards")
result = []
for i in range(length):
sliced_args = tuple(arg[i] for arg in args)
sliced_kwargs = {k: v[i] for k, v in kwargs.items()}
result.append(
self._execute_remote_single_worker(self._workers[i], method_name, *sliced_args, **sliced_kwargs)
)
return result
return [self._execute_remote_single_worker(worker, method_name, *args, **kwargs) for worker in self._workers](2) 将这个可执行对象添加为 WorkerGroup 的类变量,这样就可以通过 WorkerGroup 类直接调用分布式的 worker 类函数
for method_name in dir(user_defined_cls):
...
if hasattr(method, MAGIC_ATTR):
# this method is decorated by register
attribute = getattr(method, MAGIC_ATTR)
...
# bind a new method to the RayWorkerGroup
func = func_generator(
self,
method_name,
dispatch_fn=dispatch_fn,
collect_fn=collect_fn,
execute_fn=execute_fn,
blocking=blocking,
)
...
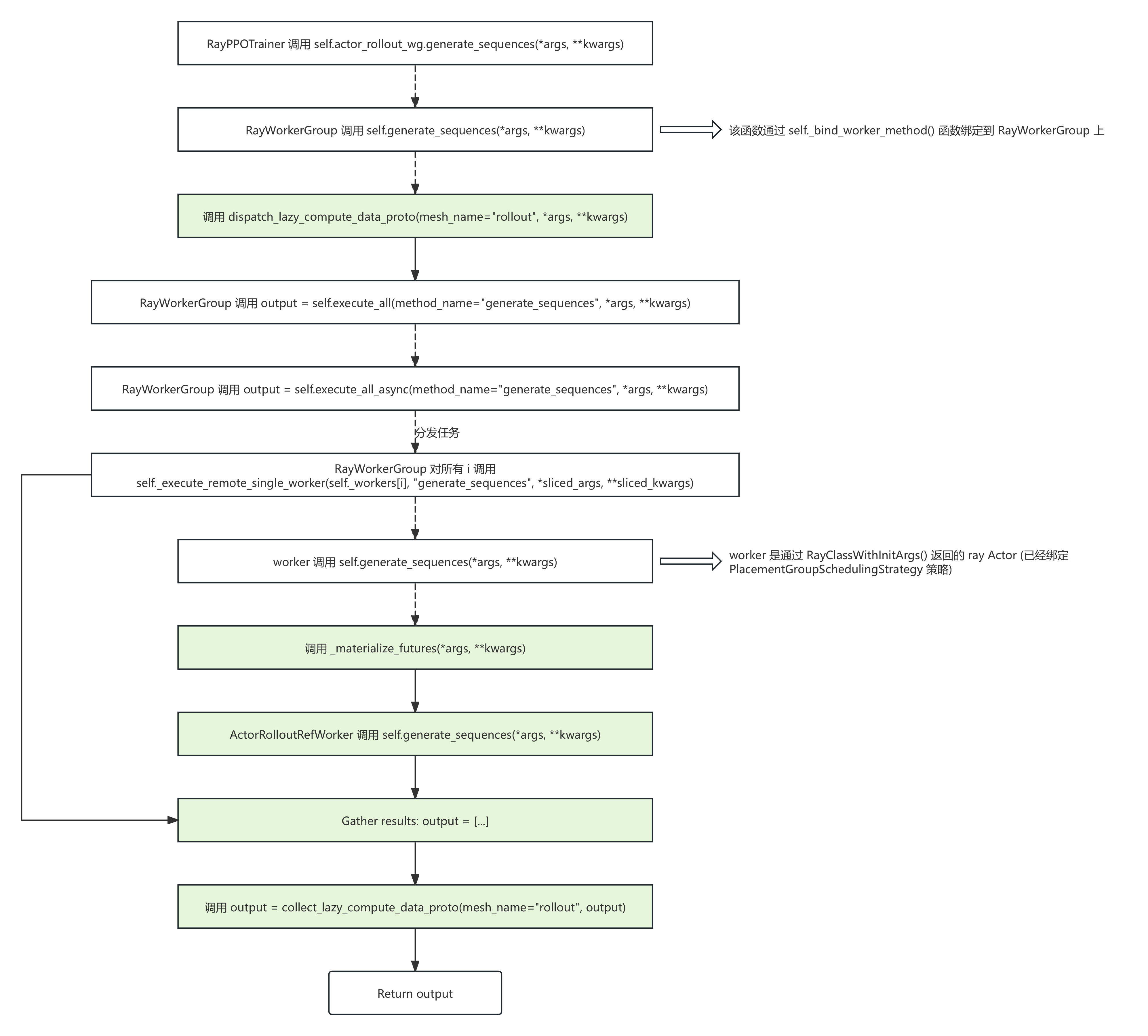
setattr(self, method_name, func)5. 最后梳理一下当 RayPPOTrainer 调用一个函数(以 generate_sequences() 为例)时,整个训练框架都做了什么,已知 generate_sequences() 的 register 配置为:
- dispatch_fn: partial(dispatch_lazy_compute_data_proto, mesh_name="rollout")
- collect_fn: partial(collect_lazy_compute_data_proto, mesh_name="rollout")
- execute_fn: "execute_all"
ActorRolloutRefWorker (verl.workers.fsdp_workers.ActorRolloutRefWorker)
1. 这个类中包含共置的 Rollout、Actor Model 和 Reference Model 的定义,支持 FSDP 分布式部署
DeepSpeed ZeRO
- ZeRO-1:将 optimizer 状态(如 Adam 的 momentum 和 variance)分区到不同 GPU 上,每个 GPU 只负责更新自己分区对应的参数部分
- ZeRO-2:将 optimizer 状态和梯度分区到不同 GPU 上,每个 GPU 只负责更新自己分区对应的参数部分
- ZeRO-3:将 optimizer 状态、梯度和模型参数分区到不同 GPU 上,每个 GPU 只负责存储和更新自己分区对应的参数部分
- DeepSpeed ZeRO 虽然也从模型层面将训练过程拆分到不同卡上,但它本质上还是属于 DP,而不是 TP。因为每个 GPU worker 都要跑完模型的完整 infer 流程,并且仍然保持每个 GPU 处理不同的数据批次
- 由此可知 DP 和 TP 的根本区别:每个 GPU worker 是否包含完整的模型副本,TP 时各 GPU 获取的是对相同数据完整 infer 过程中的某些片段
2. rollout 在 _build_rollout 函数中构建
self.rollout = get_rollout_class(rollout_config.name, rollout_config.mode)(
config=rollout_config, model_config=model_config, device_mesh=rollout_device_mesh
)根据 rollout_config 中的 name 和 model 选取指定的类
_ROLLOUT_REGISTRY = {
("vllm", "sync"): "verl.workers.rollout.vllm_rollout.vLLMRollout",
("vllm", "async"): "verl.workers.rollout.vllm_rollout.vLLMAsyncRollout",
("sglang", "sync"): "verl.workers.rollout.sglang_rollout.sglang_rollout.SGLangRollout",
("sglang", "async"): "verl.workers.rollout.sglang_rollout.sglang_rollout.SGLangRollout",
}在本例中使用的 rollout 类是 vLLMRollout (verl.workers.rollout.vllm_rollout.vLLMRollout)。在该类中可以看到 vLLM 的构建代码:
self.inference_engine = LLM(
model=model_path,
enable_sleep_mode=config.free_cache_engine,
tensor_parallel_size=tensor_parallel_size,
distributed_executor_backend="external_launcher",
dtype=config.dtype,
enforce_eager=config.enforce_eager,
gpu_memory_utilization=config.gpu_memory_utilization,
disable_custom_all_reduce=True,
skip_tokenizer_init=False,
max_model_len=max_model_len,
max_num_seqs=config.max_num_seqs,
load_format=load_format,
disable_log_stats=config.disable_log_stats,
max_num_batched_tokens=max_num_batched_tokens,
enable_chunked_prefill=config.enable_chunked_prefill,
enable_prefix_caching=config.enable_prefix_caching,
trust_remote_code=trust_remote_code,
seed=config.get("seed", 0),
**compilation_config,
**self.lora_kwargs,
**engine_kwargs,
)以及 vLLM 的调用代码:
outputs = self.inference_engine.generate(
prompts=vllm_inputs, # because we have already convert it to prompt token id
sampling_params=self.sampling_params,
lora_request=lora_requests,
use_tqdm=False,
)其它
- StatefulDataLoader:增强实验可复现性

















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









