



参考文献
- 查询 NVIDIA 驱动和 CUDA 版本兼容性:CUDA Toolkit 12.9 Update 1 - Release Notes — Release Notes 12.9 documentation
- NVIDIA 官方在 Docker Hub 上维护的 CUDA 基础镜像:https://hub.docker.com/r/nvidia/cuda/tags
- NGC (NVIDIA GPU Cloud) 提供的 pytorch 镜像:PyTorch | NVIDIA NGC
一、安装 Docker
- 参考 docker 官方提供的安装引导文档,选择 apt 安装
- step1:设置 apt 仓库
# Add Docker's official GPG key: sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc # Add the repository to Apt sources: echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update
- step2:安装 docker 包
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
- 运行官方提供的 hello-world 镜像验证 docker engine 是否安装成功:
sudo docker run hello-world- 如果打印出以下 log,则表示安装成功:
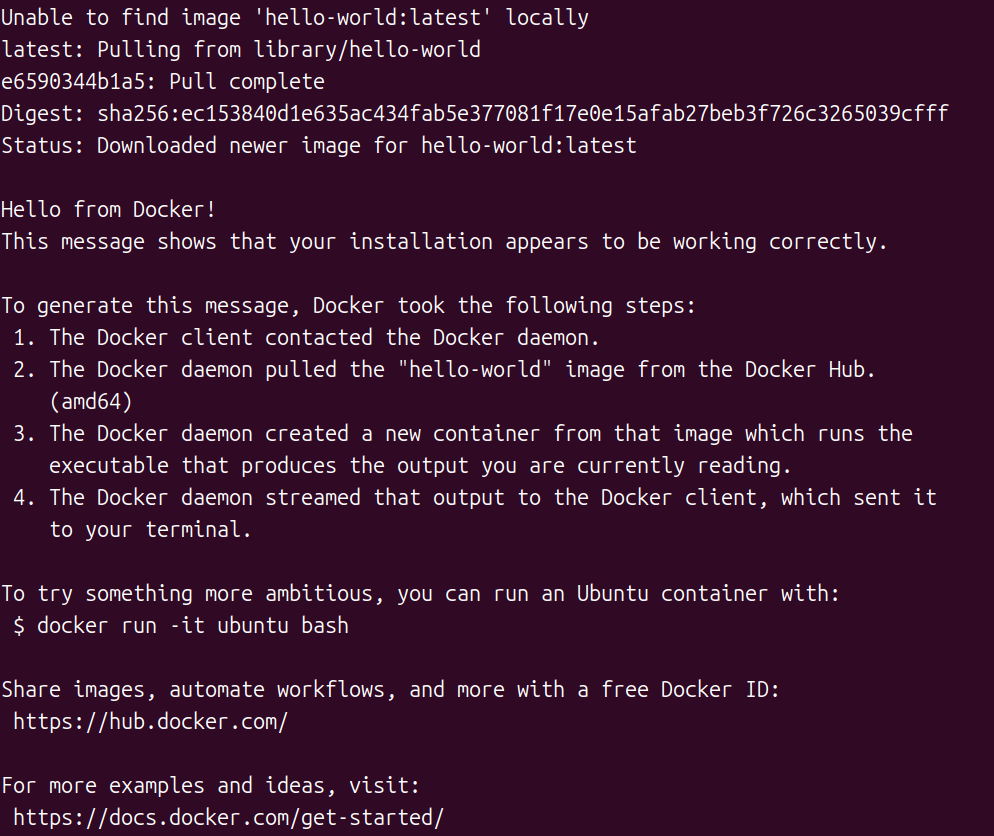
- 如果打印出以下 log,则表示安装成功:
- 验证 docker compose 是否安装成功
sudo docker compose version
Tips:将当前用户加入 docker 用户组避免强依赖 sudo 权限
- 创建 docker 用户组(通常安装 docker 时会自动创建)
sudo groupadd docker # 若已存在会提示“组已存在”,可忽略
- 将当前用户加入 docker 用户组
sudo usermod -aG docker $USER # “-a”表示追加(避免覆盖已有组),“-G”指定要加入的组名“docker”
- 重启系统刷新用户组权限
Tips:更换国内 docker 镜像源解决 hello-world 镜像无法拉取的问题
- 运行以下指令:
sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": [ "https://docker.m.daocloud.io" # 更换为任一可用镜像源均可 ] } EOF sudo systemctl daemon-reload sudo systemctl restart docker
- 重启 docker 服务后可以执行 docker info,并在输出信息中查找“Registry Mirrors”以验证 docker 镜像源是否更换成功
二、安装 NVIDIA Container Toolkit
- 参考官方安装引导文档:Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit,运行以下指令:
# Configure the production repository curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # Update the packages list from the repository sudo apt-get update # Install the NVIDIA Container Toolkit packages export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1 sudo apt-get install -y \ nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
- 验证 NVIDIA Container Toolkit 是否安装成功
nvidia-ctk --version
- 配置 docker 源
sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
三、配置 NVIDIA 官方 docker 镜像
1. NVIDIA 官方在 Docker Hub 上维护的 CUDA 基础镜像
- 页面:https://hub.docker.com/r/nvidia/cuda/tags
- 根据 Ubuntu 系统版本 + CUDA 版本选择对应的镜像,对每个版本又提供了 5 个细分版本:
- base:仅包含 CUDA 运行所需的最小依赖
- runtime:base + 标准 CUDA 工具(如 nvprof),适用于运行预编译的 CUDA 应用的场景
- devel:runtime + 编译器(nvcc)、头文件、静态库,适用于需要编译 CUDA 代码的场景
- cudnn-runtime:runtime + cuDNN runtime library(libcudnn),适用于运行预编译的 cuDNN 加速应用的场景
- cudnn-devel:devel + cuDNN runtime library 和头文件,适用于需要编译 cuDNN 加速应用的场景
- 以 nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04 为例,运行以下指令拉取 docker 镜像:
docker run --rm --gpus all nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04 nvidia-smi
2. NGC (NVIDIA GPU Cloud) 提供的 pytorch 镜像
- 页面:PyTorch | NVIDIA NGC
- NGC 镜像提供更丰富的机器学习开发环境。 以 PyTorch Release 25.03 - NVIDIA Docs 版本为例,其中包含了以下这些依赖库,基本上可以满足大部分模型训练/部署需求:
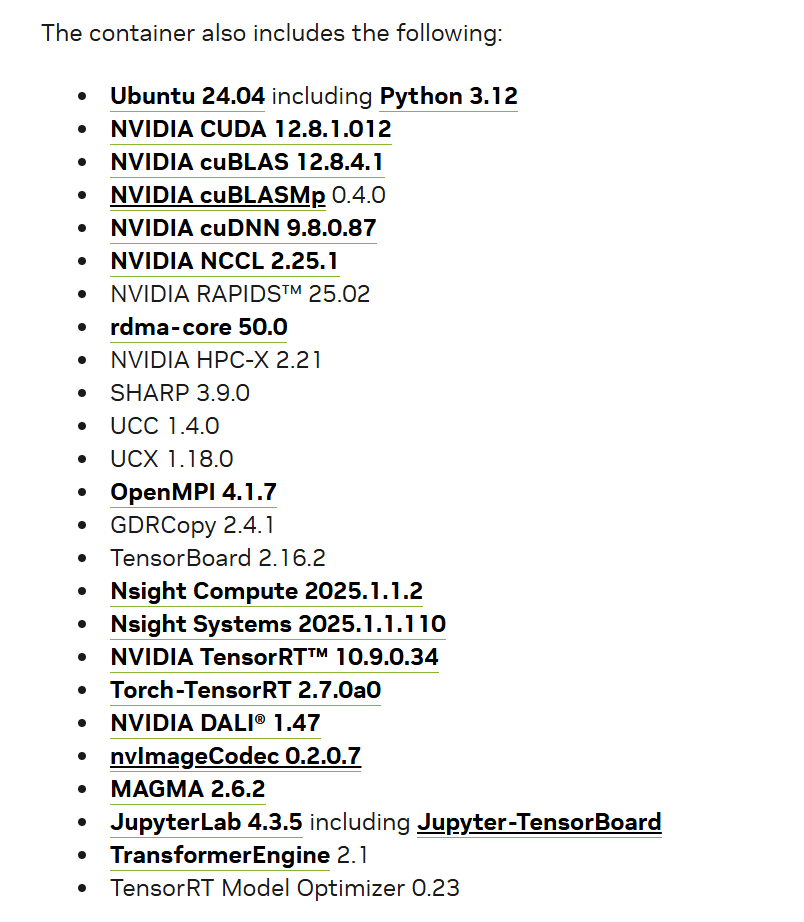
- 运行以下指令拉取 docker 镜像,其中 xx.xx 为 Release Note 中的发布版本号:
docker run --rm --gpus all nvcr.io/nvidia/pytorch:xx.xx-py3 nvidia-smi
Tips
-
查看 Nvidia 官方镜像中的 CUDA 版本
nvcc -V -
查看 Nvidia 官方镜像中的 cuDNN 版本
cat /usr/include/x86_64-linux-gnu/cudnn_version.h | grep CUDNN_MAJOR -A 2- 输出示例:
#define CUDNN_MAJOR 9 #define CUDNN_MINOR 8 #define CUDNN_PATCHLEVEL 0 - 则 cuDNN 版本号为 9.8.0
- 输出示例:
-
docker 容器运行一段时间后找不到 GPU,提示 Failed to initialize NVML: Unknown Error
- 参考文档:Docker容器运行一段时间后GPU无法使用报错Failed to initialize NVML: Unknown Error
- 执行指令:
docker info | grep Cgroup- 如果输出是 Cgroup Driver: cgroupfs,那就寻找其他解决办法(暂时不知道什么办法)
- 如果输出是 Cgroup Driver: systemd,就在 /etc/docker/daemon.json 中增加配置:
"exec-opts": ["native.cgroupdriver=cgroupfs"] - 然后重启 docker 服务并重新构建容器即可:
sudo systemctl restart docker
-
docker 镜像仓库相关命令
- 登录 docker 镜像仓库:
docker login [OPTIONS] [SERVER] # OPTIONS: # -u, --username: 登录用户名 # -p, --password: 登录密码(不推荐在命令行使用) # --password-stdin: 从标准输入读取密码 # SERVER: docker 镜像仓库,默认为 docker.io (DockerHub) - 登出 docker 镜像仓库:
docker logout [SERVER] # SERVER: docker 镜像仓库,默认为 docker.io (DockerHub) - 为本地镜像打上一个符合目标镜像仓库命名规范的标签:
docker tag SOURCE_IMAGE[:TAG] TARGET_IMAGE[:TAG] # SOURCE_IMAGE[:TAG]: 源镜像名称和标签,标签默认为 latest # TARGET_IMAGE[:TAG]: 目标镜像名称和标签,标签默认为 latest,镜像名称通常由 <registry-url>/<username-or-namespace>/<image-name> 组成 - 推送镜像到镜像仓库:
docker push [OPTIONS] IMAGE[:TAG] # IMAGE[:TAG]: 镜像名称和标签,标签默认为 latest,镜像名称通常由 <registry-url>/<username-or-namespace>/<image-name> 组成
- 登录 docker 镜像仓库:
-
常用 docker 指令
- 查看本地 docker 镜像:
docker images - docker run:从指定的 docker 镜像中创建并运行一个新容器,等效于 docker create + docker start [+ docker exec](当本地不存在指定镜像时,docker 会尝试从已配置的镜像仓库中搜索并拉取镜像,等效于 docker pull)
docker run [OPTIONS] IMAGE[:TAG] [COMMAND] [ARG...] # OPTIONS [part]: # --rm: 在容器停止后自动删除容器,避免占用系统资源 # --gpus: 启用容器对 NVIDIA GPU 的访问。"all"表示将所有可用的 GPU 分配给容器 # IMAGE[:TAG]: 镜像名称和标签 # COMMAND [ARG...]: 启动容器后运行的命令 - docker pull:从已配置的 docker 镜像仓库中搜索并拉取镜像到本地
docker pull [OPTIONS] IMAGE[:TAG|@DIGEST] - docker create:从指定的 docker 镜像中创建一个新容器但不运行(当本地不存在指定镜像时,docker 会尝试从已配置的镜像仓库中搜索并拉取镜像,等效于 docker pull)
docker create [OPTIONS] IMAGE[:TAG] [COMMAND] [ARG...] - 查看所有已启动的 docker 容器:
# 查看所有已启动的 docker 容器 docker container ls # 查看所有已启动的 docker 容器(包括已停止的容器) docker container ls -a # 也可以使用: docker ps docker ps -a - 启动/停止/重启 docker 容器
# 启动已停止的容器 docker start CONTAINER # 停止运行中的容器 docker stop CONTAINER # 重启容器 docker restart CONTAINER - docker exec:在运行中的容器内执行一个新的命令
docker exec [OPTIONS] CONTAINER COMMAND [ARG...] # Example: # 1. 以命令行形式打开一个 docker 容器 docker exec -it CONTAINER /bin/bash
- 查看本地 docker 镜像:


















 3522
3522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









