







李哥的深度学习篇5
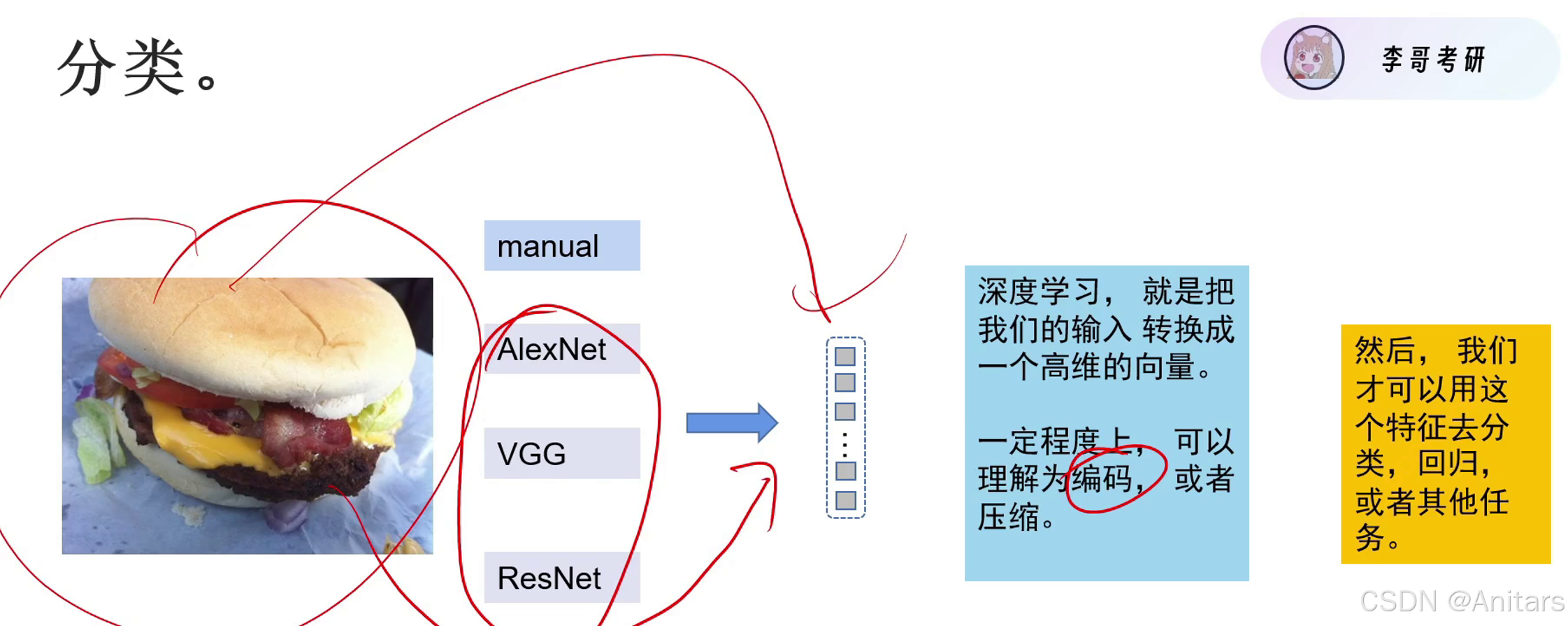
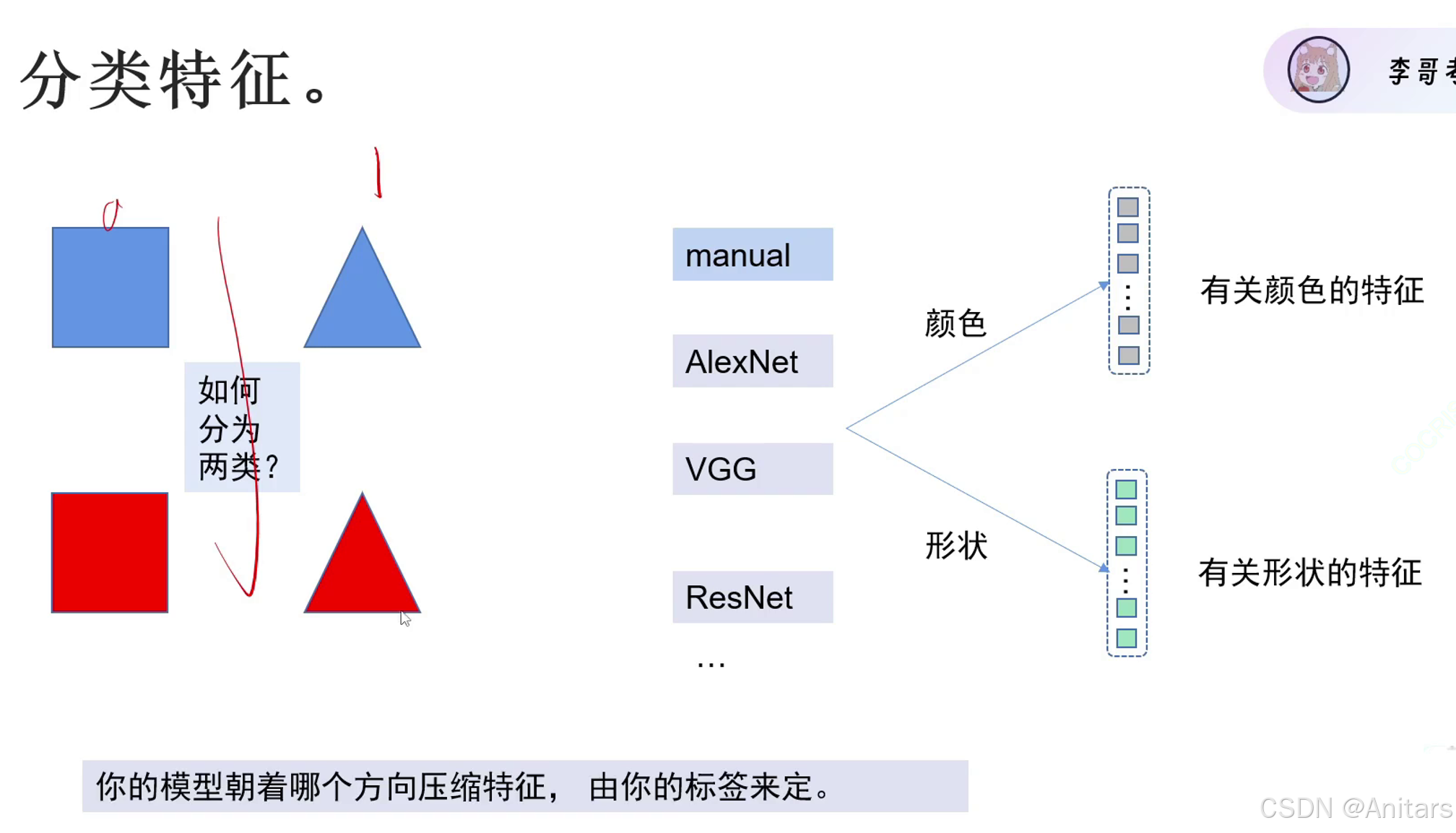

无监督学习是一种机器学习方法,其核心目标是从未标记的数据中发现潜在的结构、模式或关系,不需要人工干预提供标签。
无监督学习意义:
- 降低数据标注成本:无需依赖大量人工标注的数据,使得数据采集和处理更加高效。
- 适应小样本数据:在标注数据不足或缺乏的情况下,无监督学习能够有效地进行分析和模型构建。
- 自动特征提取:能够从原始数据中自动发现和提取重要的特征,这对于处理高维或复杂数据尤为重要。
- 数据可视化:降维技术使得高维数据可以在低维空间中进行可视化,从而更直观地分析和理解数据。
- 自适应学习:无需预先定义类别,能够根据数据本身的特征进行分类或聚类,从而适应不同的应用场景。
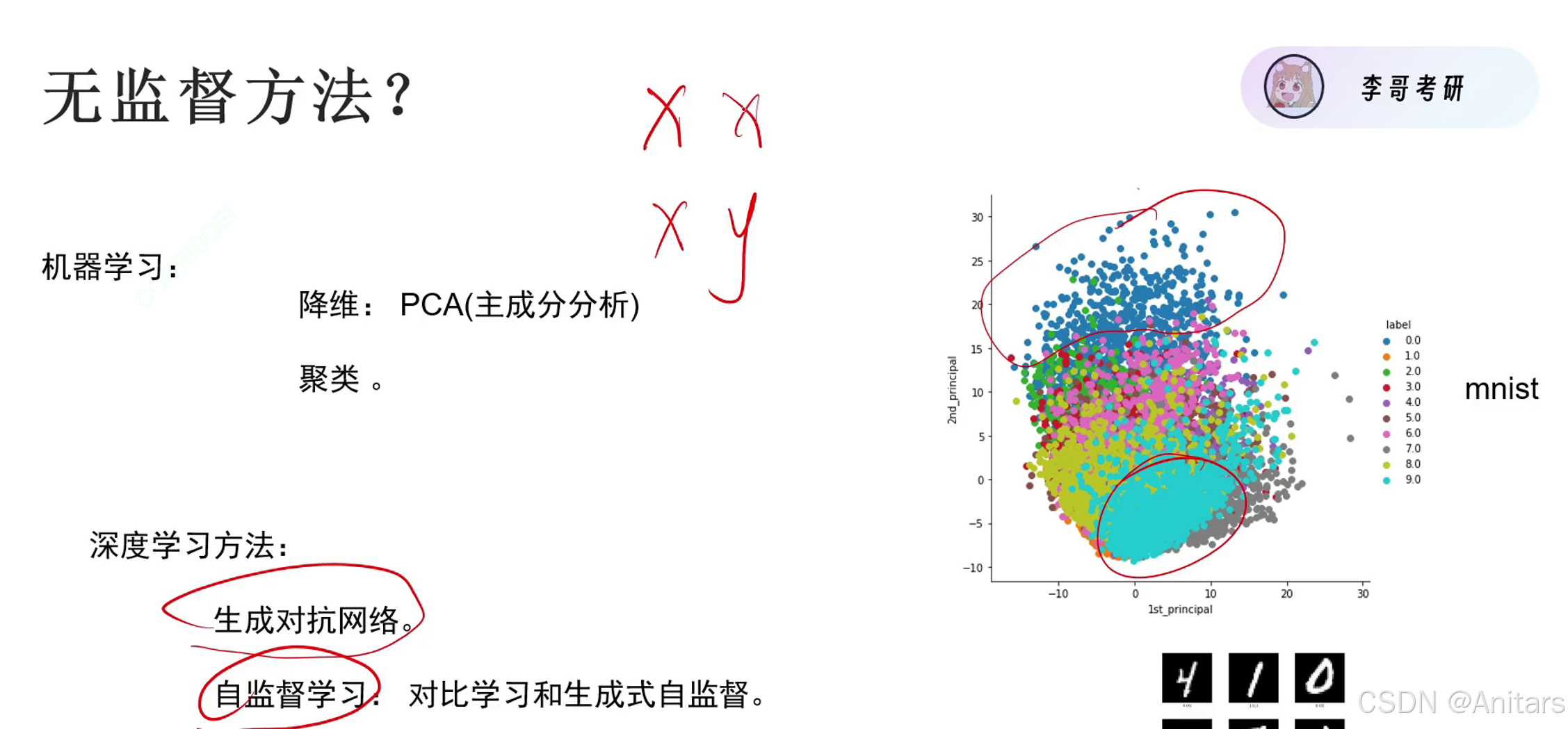
无监督学习是一种机器学习方法,其核心目标是从未标记的数据中发现潜在的结构、模式或关系,不需要人工干预提供标签。
常见的无监督学习方法:
- 聚类算法
目标:将相似的数据点聚集到同一类别中,而不同类别中的数据尽可能不相似。
实现方法:- K-means算法:通过优化中心的距离计算数据簇。常用的优化方法有K-means++和EM算法。
- DBSCAN算法:基于密度概念,找出高密度区域(cluster)。
- 降维技术
目标:将高维数据映射到低维空间中,以便更直观地分析数据或减少计算复杂度。
常见方法:- 主成分分析(PCA):通过线性变换将数据投影到主要轴上,保留最大变异性信息。
- t-SNE(t-distributed Stochastic Neighbor Embedding):一种非线性降维技术,适合处理高维数据。
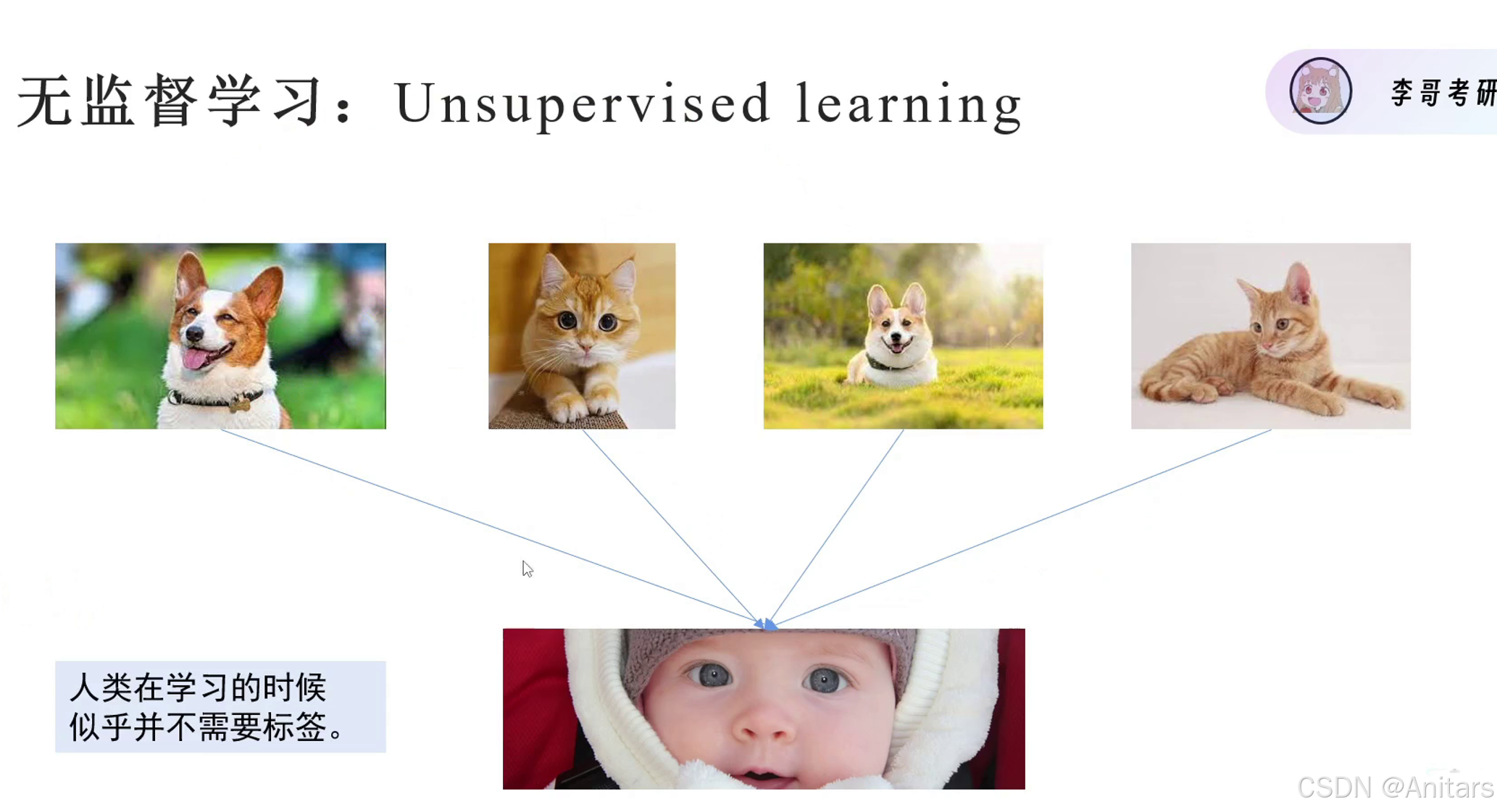


自监督学习(Self-Supervised Learning)是无监督学习的一个分支,专注于在没有标签的情况下,通过生成伪标签来训练模型。这些伪标签通常来自数据增强或特定的生成过程,旨在帮助模型更好地捕捉数据的内部结构和分布。
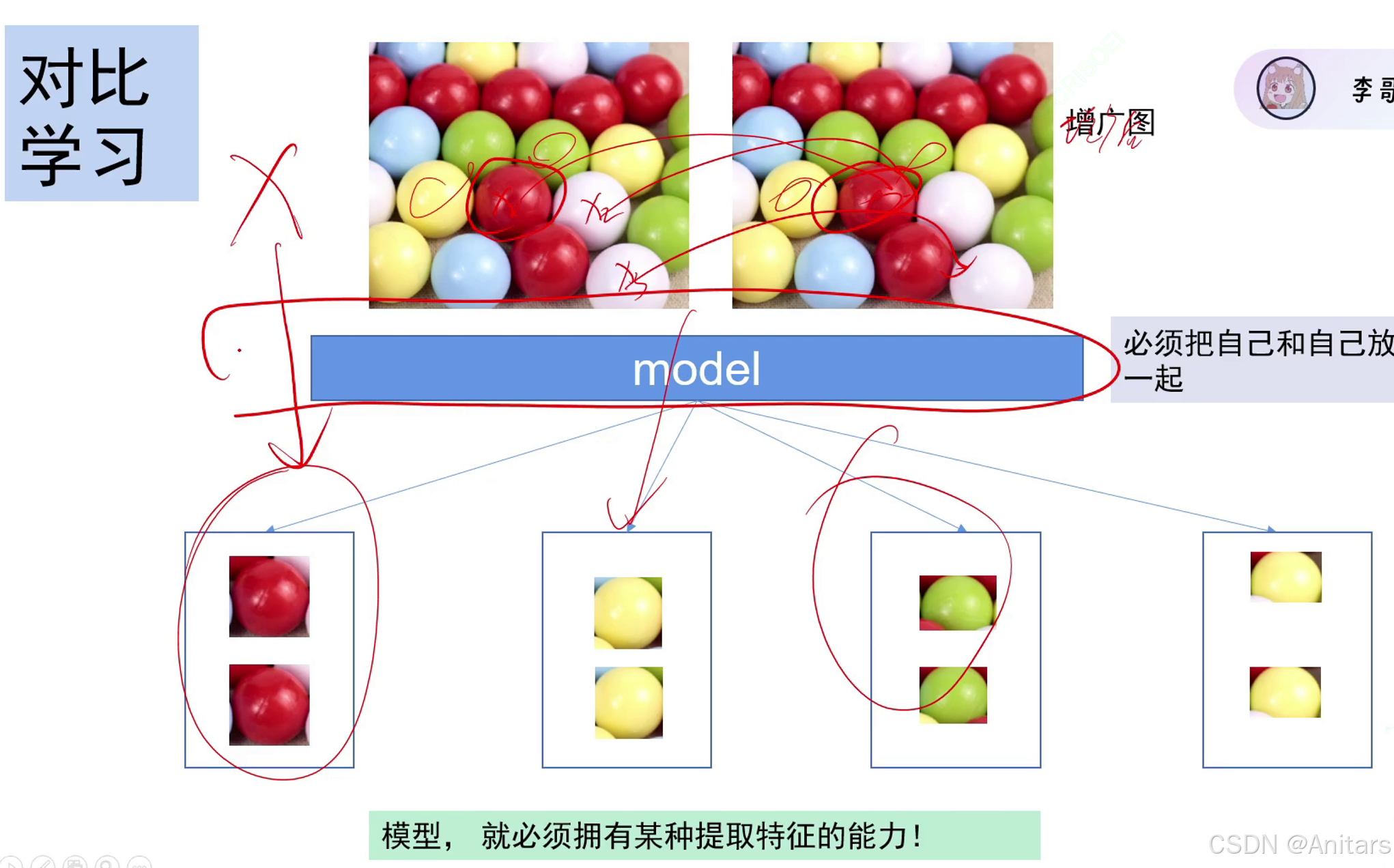
对比学习(Contrastive Learning)是自监督学习中的一种技术,通过比较同一批次中的正样本与负样本来学习有用的表示。模型试图使得同一批次内的正样本更为相似,而不同类别或数据点之间则尽可能地不太相似。
自监督学习通常依赖伪标签,而对比学习通过对比信息增强模型的表达能力。两者结合使用,可以帮助模型在没有标签的情况下更好地学习数据分布,并生成有意义的特征表示。
自监督学习与无监督学习的区别
- 依赖伪标签:自监督学习使用生成的或变换过的数据作为伪标签,帮助模型理解数据分布。
- 目标不同:无监督学习更注重将数据分组,而自监督学习则通过对比学习捕捉深层次特征关系。
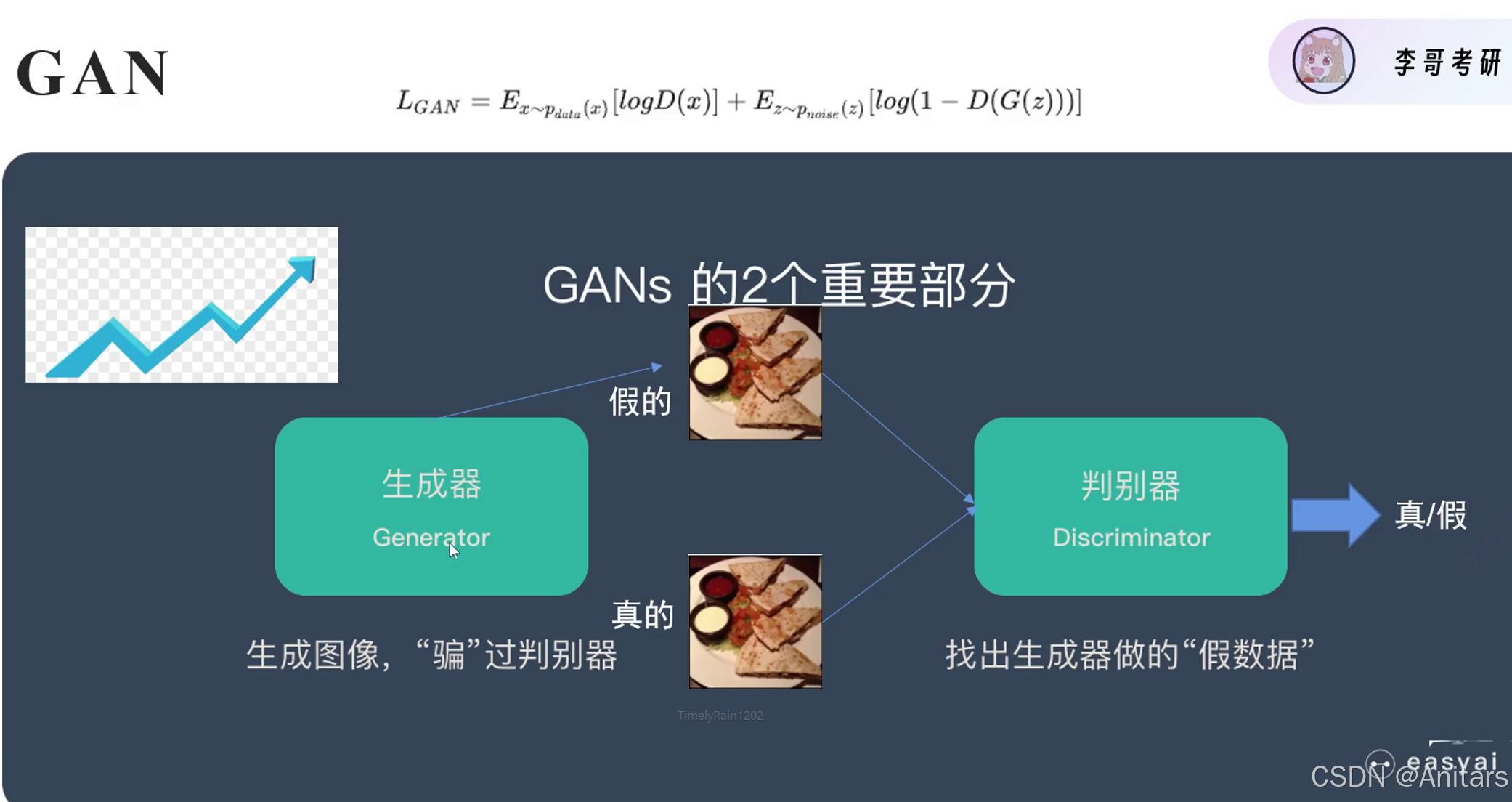
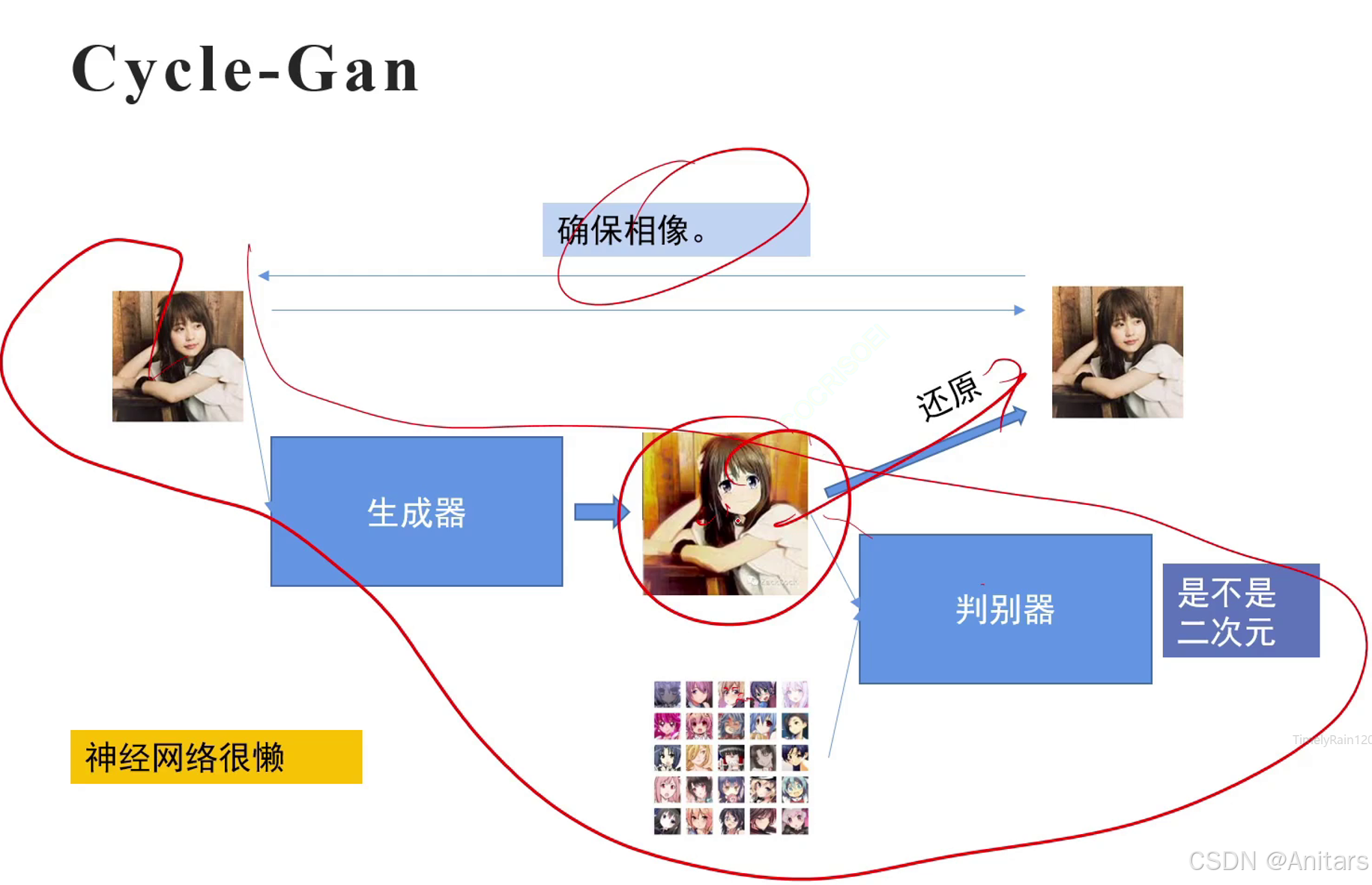
生成对抗网络(GANs)是一种在机器学习和深度学习领域中广泛应用的自主学习方法,由两部分神经网络组成:生成器(Generator)和判别器(Discriminator)。以下是关于生成对抗网络的详细介绍:
-
基本概念:
- 生成器:负责根据输入噪声或随机数据生成新的样本,使其尽可能接近真实的数据分布。
- 判别器:被训练来区分生成器生成的伪样本和真实的数据样本,起到监督的作用。
-
对抗训练过程:
- 生成器试图欺骗判别器,使得生成的样本难以区分于真实样本。
- 判别器则试图识别出这些伪样本,并最大化识别正确率。
-
目标函数:
- 通常采用对数似然损失函数,判别器优化使其更好地区分真假样本,而生成器则希望减少这种区分能力。
-
与其他自主学习方法的对比:
- 自监督学习(SSL):通过预训练模型在未标记数据上学习特征表示。
- GANs和SSL在目标上有所不同,GANs更注重生成真实样本,而SSL关注特征提取。
- 对比学习(CL):
- 通过对比正样本和负样本来优化嵌入表示。
- 与GANs相似,但更专注于特征嵌入的学习。
- 自监督学习(SSL):通过预训练模型在未标记数据上学习特征表示。
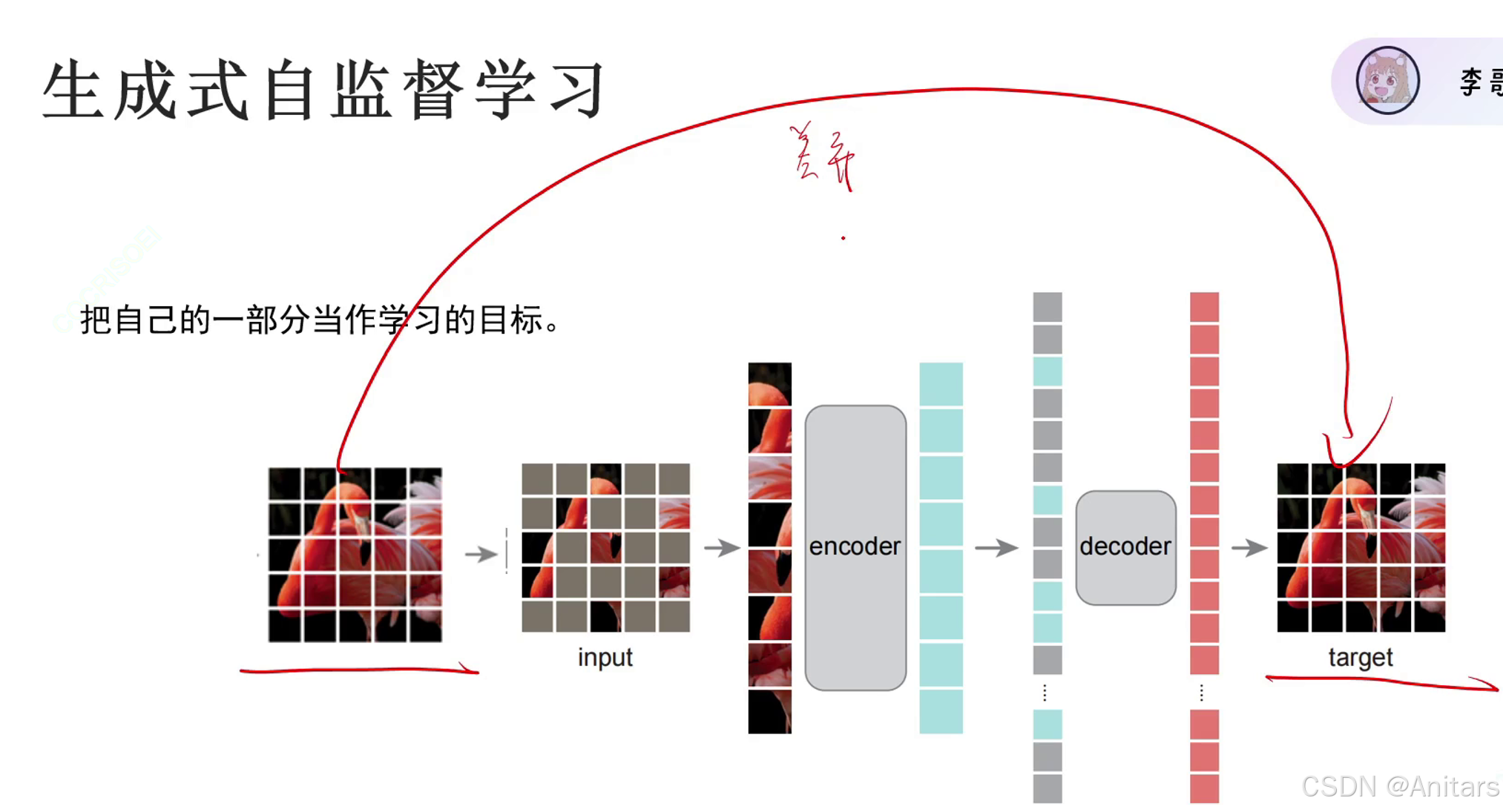
生成式自监督(Generative Self-Supervised Learning)是一种结合了自监督学习和生成模型的技术,旨在通过未标记数据不仅提取特征,还能生成新的内容。以下是对其关键点的详细解释:
-
基本概念:
- 生成式自监督是在传统的自监督学习基础上引入了生成模型,如GANs(生成对抗网络)或VAEs(变分自编码器),使得模型不仅能够在未标记数据上提取特征,还能生成新的样本。
-
核心思想:
- 自监督学习:通过预训练模型在大规模未标记数据上学习特征,不需要人工标注的数据,节省资源。
- 生成模型:引入生成模型,使得提取到的特征不仅能用于分类、分割等任务,还能用于生成新的内容。
-
实施方法:
- 结合自监督和生成模型,通常采用对抗训练的方式,让生成器生成逼真的样本,而判别器则区分生成的伪样本与真实数据。
- 通过这种对抗机制,模型能够在未标记数据上学习更丰富、更具生成能力的特征表示。
-
与传统自监督学习的区别:
- 传统自监督主要关注特征提取,而生成式自监督不仅如此,还专注于生成能力的增强,使得模型能够创造新的内容。
- 通过引入生成模型,生成式自监督提供了更强大的表达能力和多样性,使其在很多任务中表现优异。
-
总结:
生成式自监督通过结合自监督学习和生成模型,使得在未标记数据上训练出来的模型不仅能够有效地进行特征提取,还能具备强大的内容生成能力。这种方法在多个领域中展现出广泛的应用潜力,提升了模型的表达能力和实用价值。
以下我向deepseek提问给出的思考和答案:
提问:我想搞明白无监督和有监督的关系,我目前的理解是:无监督学习提取出很好的特征,因为无标签的数据很多,可以大量获取用来训练,提取出好的特征之后,在少量的有标签数据上进行分类。是这样的吗
嗯,用户现在想搞明白无监督和有监督的关系。他说,他目前的理解是,无监督学习可以在大量没有标签的数据中提取出好的特征,然后用少量的有标签数据来进行分类。这听起来有点像传统的自监督学习方法,对吗?我记得之前讨论过生成对抗网络(GANs)和生成式自监督,这些都涉及到在未标注的数据上进行训练。首先,无监督学习主要是为了特征提取,因为没有标签,所以模型只能通过数据本身来学习结构、模式等信息。传统的自监督任务,比如图片分类中的彩色图像修复,正好就是这种情况。通过未标注的数据,模型自己去发现什么是“树”、“车”或者“猫”。
然后,有监督学习则相反,它需要大量标注的数据来训练模型,然后预测新的数据中存在哪些类别。这通常适用于任务明确、标签可获得的场景,比如识别手写数字。这种方法在分类准确率上可能更高,因为它直接针对目标任务进行优化。
用户提到无监督学习可以用大量没有标签的数据来训练,进而提取好的特征,然后再用少量有标签的数据进行分类。这让我想到联结器(Associative Classifier),一种方法将两个任务结合起来:在一个阶段使用无监督学习提取特征,另一个阶段利用监督学习进行分类。这种方法似乎能够最大化利用大量未标注数据,同时也能利用少量标注数据提高准确率。
不过,这里也有一个问题:特征提取的质量是否真的比完全依赖有监督学习更好?传统上,无监督方法可能会遗漏一些重要信息,因为它们没有针对具体任务来训练。而有监督学习,特别是在大规模标注数据下,可以更准确地捕捉任务相关的特征。
另外,生成式自监督又是怎么回事呢?它结合了生成模型和自监督学习,让模型不仅在提取特征,还能生成新的内容。这对于数据稀缺或任务多样化的情况可能非常有用。但这也意味着需要额外的计算资源来生成这些内容,是否值得还需要进一步探讨。
总结一下,用户的理解基本上是正确的:无监督学习在大量没有标签的数据中提取特征,然后有监督学习在少量标注数据上进行分类。但是,实际中可能存在如何平衡两者的优缺点,以及是否可以通过结合两者来提升模型性能的问题。
我觉得用户需要进一步了解具体的方法,比如联结器、生成式自监督等,以及它们各自的优缺点。此外,还应该探讨在不同领域和任务中,这种无监督与有监督结合的方式是否真的有效,以及面临哪些挑战。
最后,可能还要提到一些实际案例,比如在自然语言处理中的文本分类,或者图像识别中的物体检测,说明无监督和有监督是如何协同工作的,这样用户能更好地理解两者的关系。
无监督学习与有监督学习的关系及解答
无监督学习和有监督学习是人工智能领域中两个核心的训练方法,它们在数据处理和模型训练中的作用各不相同。以下是对这两者关系的详细分析:
- 定义与目标
-
无监督学习:主要目标是从大量没有标签的数据中自动发现数据中的结构、模式或本征。通过这种方法,模型能够学习到数据的内在特征和分布规律,而不依赖于人工标注。典型应用包括聚类分析、降维技术(如PCA)和生成模型训练。
-
有监督学习:目标是根据已知的标签对模型进行训练,使其能够预测新数据中的类别或属性。在此过程中,模型需要从标注的数据中学习如何分类或预测目标任务。常见应用包括分类、回归分析和序列建模等。
- 数据需求与特点
-
无监督学习:依赖大量没有标签的数据(未标注数据),适合在数据量丰富但标注成本高昂的情况下使用。优势在于能够从数据中自动提取有用的特征,但可能无法针对具体任务进行优化。
-
有监督学习:需要较少数量的标注数据(标注数据),通常与小规模但精确的任务相关。优势在于可以直接针对目标任务进行模型训练,但依赖高质量且成本较高的人工标注。
- 特征提取与分类
-
在传统的机器学习方法中,无监督学习首先用于从未标注数据中提取特征,这些特征通常被认为能够很好地反映数据的本质。随后,可以利用少量有标注数据进行分类或其他监督任务的训练。这是用户所描述的情况,符合传统的自监督学习流程。
-
例如,在图像分类中,无监督学习可以用于彩色图像修复或风格迁移等任务,而文本分类则可能通过无监督的文本降维(如TF-IDF)来提取特征,然后进行有监督的分类训练。
- 结合方法:联结器与生成式自监督
为了充分利用无监督和有监督数据的优势,研究者开发了结合两者的方法,如联结器(Associative Classifier):
-
联结器:在模型架构中加入一个高效的联结单元,使得特征提取和分类可以并行进行。通过同时利用无监督和有监督数据,联结器能够在未标注数据中学习任务相关的间接特征,同时用少量标注数据进一步优化这些特征。
-
生成式自监督:这种方法结合了生成模型(如GAN、VAE)和自监督学习。在生成过程中,模型通过无监督的方式学习数据分布,在监督任务中则利用标注数据进行精确的分类或预测。这种方法在生成高质量样本方面表现出色,特别适用于数据稀缺或任务多样化的情况。
- 优缺点分析
-
无监督学习:
- 优势:能够充分利用大量未标注数据,发现数据的深层结构和潜在特征。
- 劣势:可能无法针对具体任务,生成的特征可能不够准确或相关。
-
有监督学习:
- 优势:可以直接针对目标任务进行模型训练,生成的特征具有一定任务相关性。
- 劣势:依赖高质量且成本较高的人工标注数据,对小规模数据环境不够鲁棒。
- 应用场景
-
大数据环境:在有大量未标注但难以获得标注的数据时,无监督学习是首选方法,特别是在自然语言处理、图像识别等领域。
-
任务多样化或数据稀缺:生成式自监督能够应对数据稀少的情况,同时通过生成过程保持模型的灵活性和适应性。
- 案例分析
-
文本分类:在小规模标注数据下,可以利用无监督方法进行文本降维,然后结合有监督学习进行分类。例如,使用TF-IDF提取词袋模型特征,再用SVM或 logistic回归进行分类。
-
图像识别:通过无监督的风格迁移生成丰富的数据样本,再利用标注数据训练分类器。这种方法在域适应问题中效果显著。
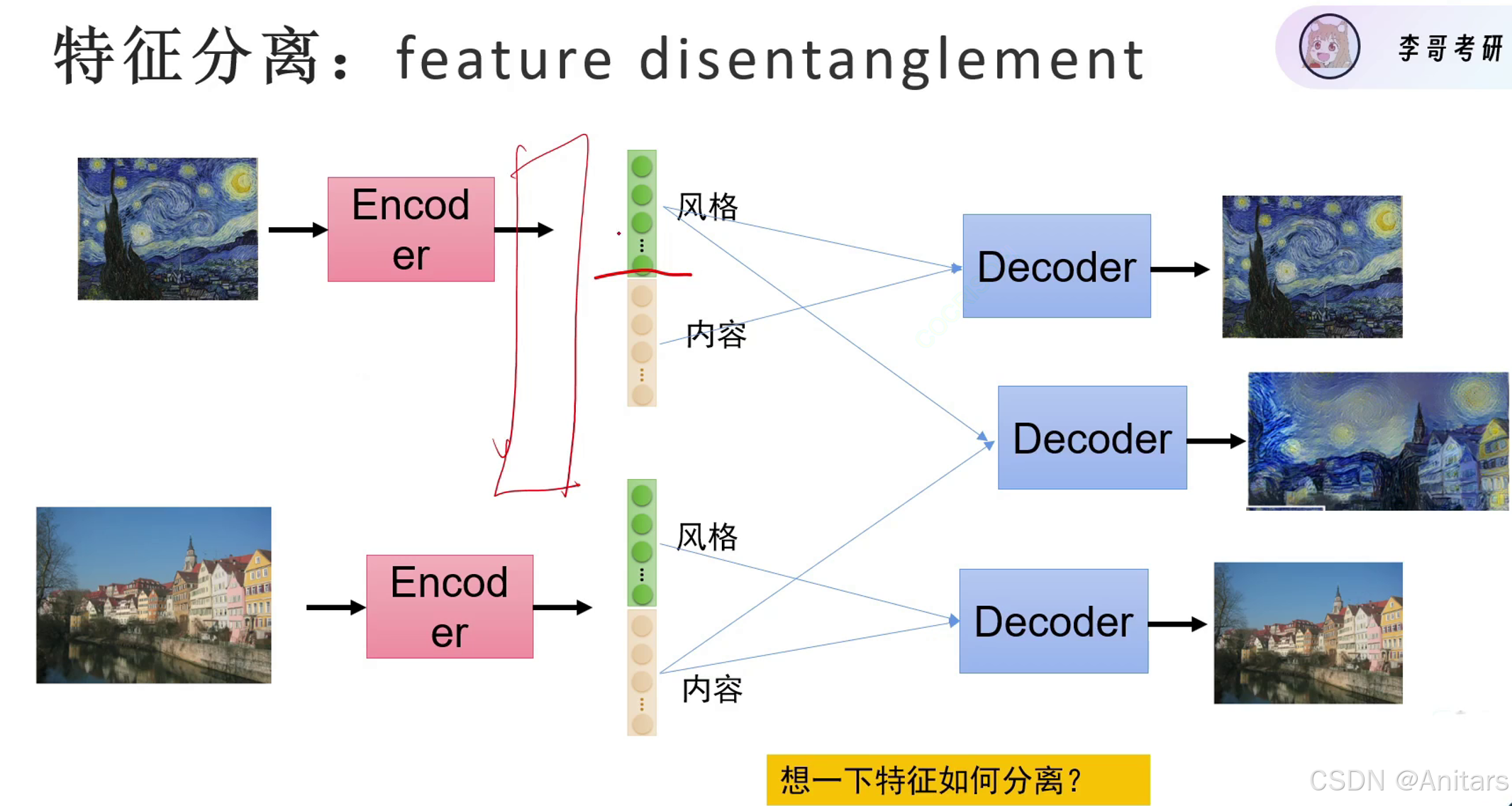
为了通过特征分离分别提取一张图片的风格和内容特征,可以按照以下步骤进行:
-
选择合适的模型架构:
- 选择能够捕捉到图像全局信息和局部细节的深度学习模型,如ResNet、VGG或Inception系列。这些模型在不同层次上提取了丰富的特征。
-
提取特征:
- 全局特征:使用池化层(如Global Average Pooling)来获取图像的一般性表示,包括色彩、纹理和整体结构。
- 局部特征:使用卷积层提取细节信息,如具体物体的形状和位置。这可以通过手动选择不同深度的卷积层来实现。
-
设计特征分离网络:
- 构建一个新的网络结构,结合全局和局部特征。
- 用某种权重调整机制,将特征分割为风格和内容两部分。例如,可以通过加权相加或门控卷积来实现。
-
训练模型:
- 进行预训练以利用大规模图像数据,提取有用的特征。
- 对模型进行微调,以适应具体任务的需求,比如风格和内容分类。
-
实验验证:
- 选择多样化的图片集合进行测试,确保模型能够准确区分出风格和内容特征。
- 手动标注或使用自动化工具对结果进行评估,收集反馈以优化模型性能。
-
优化和改进:
- 根据实验结果调整模型参数,如卷积层的深度、池化层的尺寸等。
- 引入更多数据进行训练,提高模型的泛化能力。
- 探索新技术,如生成对抗网络(GAN),以增强风格特征的生成能力。
通过以上步骤,可以逐步实现对图片风格和内容两种特征的分离,利用深度学习模型的强大特征提取能力,有效地进行特征工程。

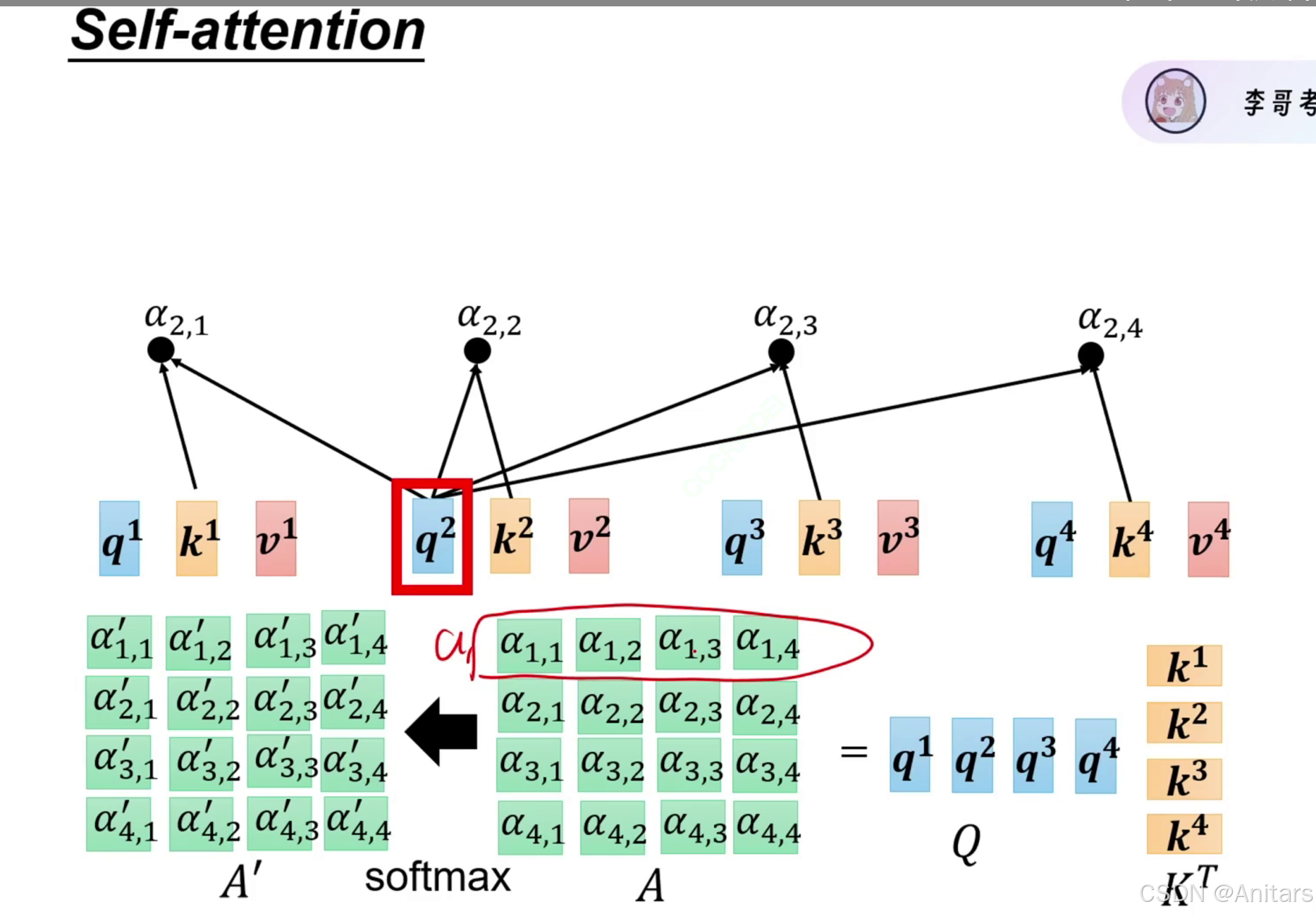
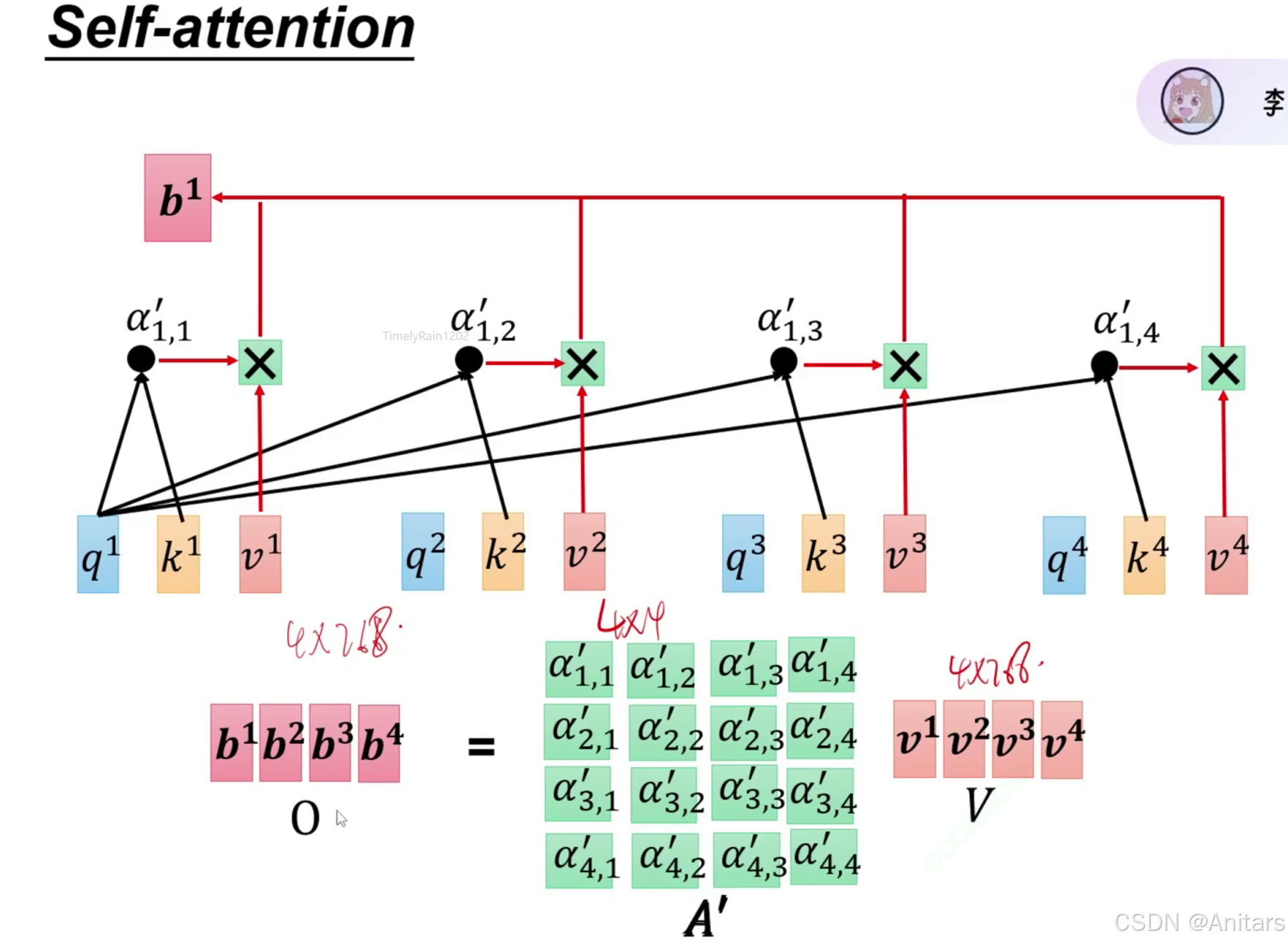
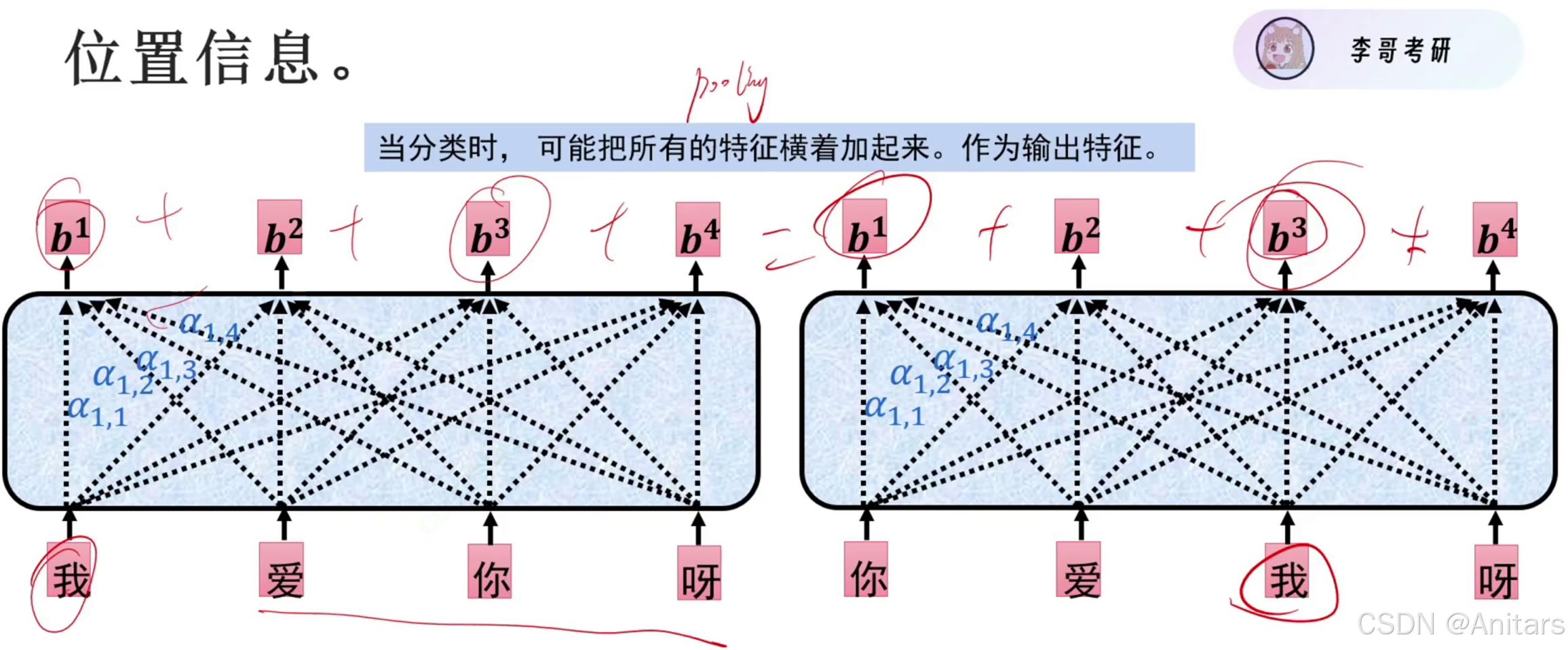
自注意力机制(Self-Attention Mechanism)是一种在自然语言处理和计算机视觉中广泛应用的技术,旨在通过图像或文本中的自身信息自动决定各部分对整体表示的重要程度。 与传统的注意力机制不同,它不依赖于预定义的外部键向量,而是利用图像或序列本身的特征生成自主的权重矩阵。
- 基础概念:
- 自注意力机制最初在自然语言处理中被提出,用于捕捉文本中的上下文关系。
- 它通过多头注意力机制,能够同时处理图像或序列中的不同区域,并生成全局表示。
- 工作原理:
- 模型利用自身特征(如纹理、形状)生成权重矩阵,决定各部分对整体信息的重要性。
- 这种自动化过程使得模型能够灵活地关注关键区域,提高任务完成度。
- 优势:
- 灵活性:根据图像内容自动决定关注点,无需外部干预。
- 适应性:能够处理不同尺度和分辨率的信息,增强鲁棒性。
- 高效性:通过并行计算显著提高推理速度。


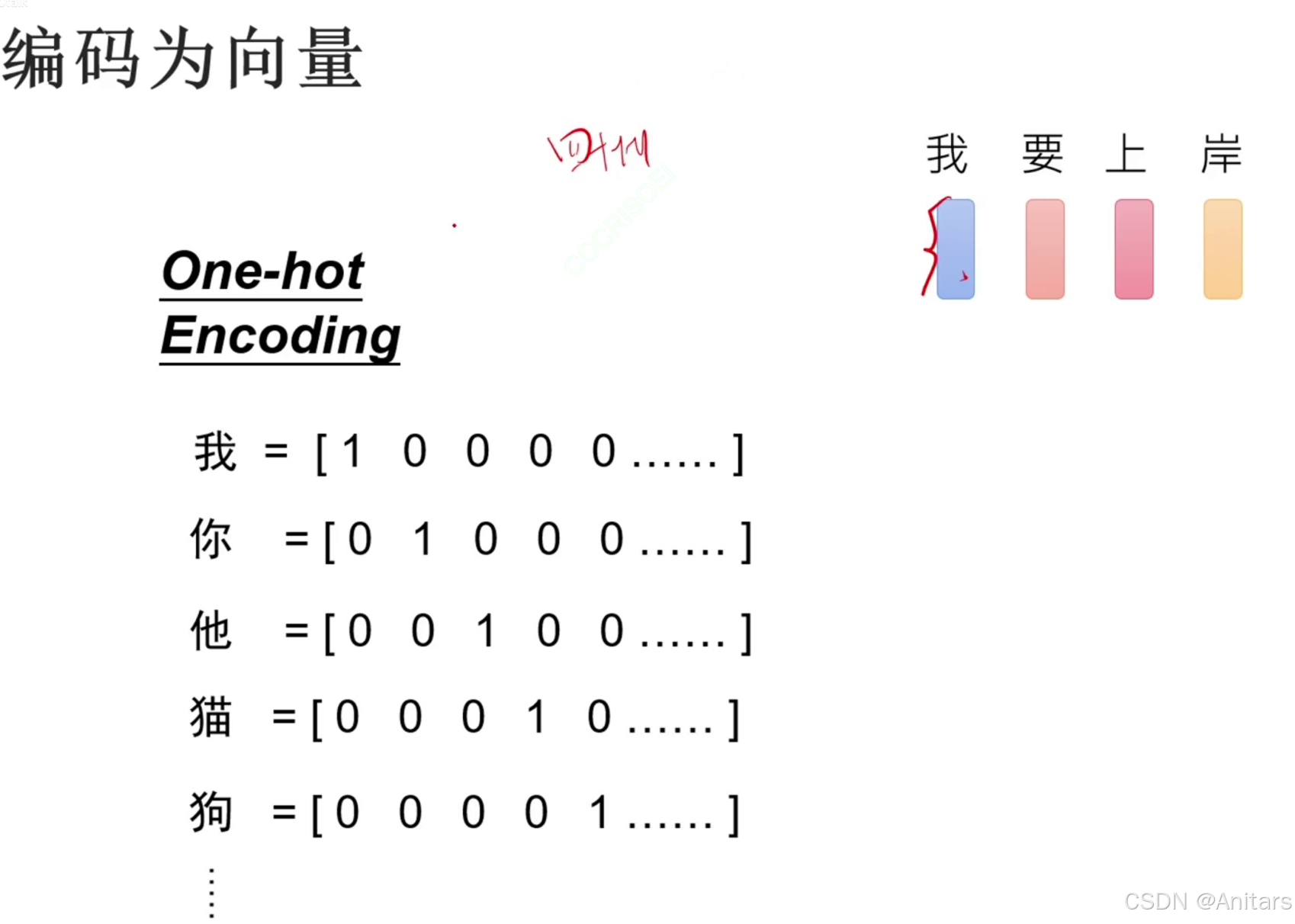
one-hot编码代替汉字缺点:
- 词库规模大时,向量维度高,导致计算资源消耗增加。
- 无法捕捉汉字之间的语义关系或上下文信息。
- One-Hot编码不能体现词性的变化或语法关系。

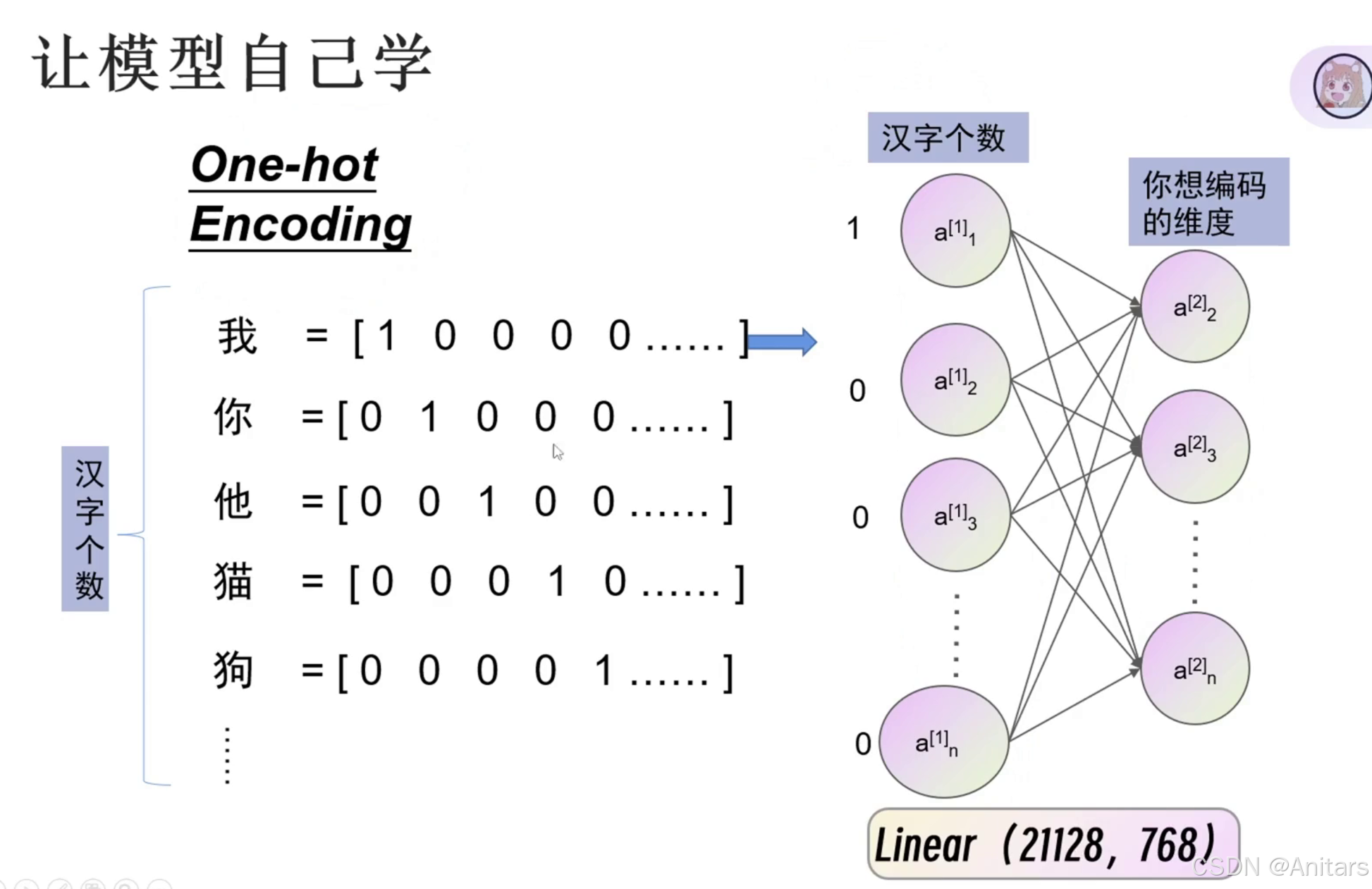
Word Embedding(词嵌入) 是一种将单词映射为高维向量的技术,使得每个单词都可以表示为一个特定的点,这些点在语义空间中反映了单词之间的相似性。通过这种方式,模型可以更好地理解和处理语言中的语义信息。
基本概念
-
词嵌入的基本思想
- 将一个单词(如“猫”、“狗”)映射为一个连续的高维向量。
- 向量中的每个元素表示了该单词在某种语义或特征上的表现。
-
常用的词嵌入方法
-
Word2Vec:
- 通过上下文预测单词(CBOW模型)或通过单词预测上下文(Skip-Gram模型)。
- Word2Vec是最经典的词嵌入技术之一。
-
GloVe(全局词嵌入):
- 基于矩阵分解,捕捉语义信息,生成全局一致性的向量表示。
-
FastText:
- 使用子词(subword)信息构建词嵌入,不需要完整单词的训练数据。
-
BERT(Bidirectional Attention Self-Attention Model, 双向注意力自注意机模型):
- 基于Transformer架构,能够捕捉上下文和长距离依赖关系,是当前最先进的词嵌入方法之一。
-
-
词嵌入的特点
- 语义捕获:词嵌入能够反映单词之间的语义相似性。
- 连续性:词嵌入生成的是连续向量,方便后续计算和训练。
- 稀疏性:通常设计使得词嵌入具有稀疏性,便于词性和语义的区分。
选择词嵌入方法的考虑因素
-
数据量:
- 对于小型数据集,简单且快速的方法(如Word2Vec)可能更合适。
- 对于大型数据集,计算效率高、效果稳定的方法(如BERT)更好。
-
上下文依赖:
- 需要捕捉长距离依赖关系的任务(如自然语言推理),应选择能够处理全局或长距离依赖的模型(如BERT)。
-
预训练词嵌入:
- 使用已经训练好的预训练词嵌入模型(如Word2Vec、GloVe、BERT)可以节省训练时间,尤其是在没有足够标注数据的情况下。
-
计算资源:
- Word2Vec和FastText相对轻量化,而BERT等深度模型需要较多的计算资源。
Word Embedding 是一种强大的工具,能够将语言中的语义信息转化为向量形式,便于模型处理和理解。根据具体任务需求选择合适的词嵌入方法,可以显著提升自然语言处理任务的效果。

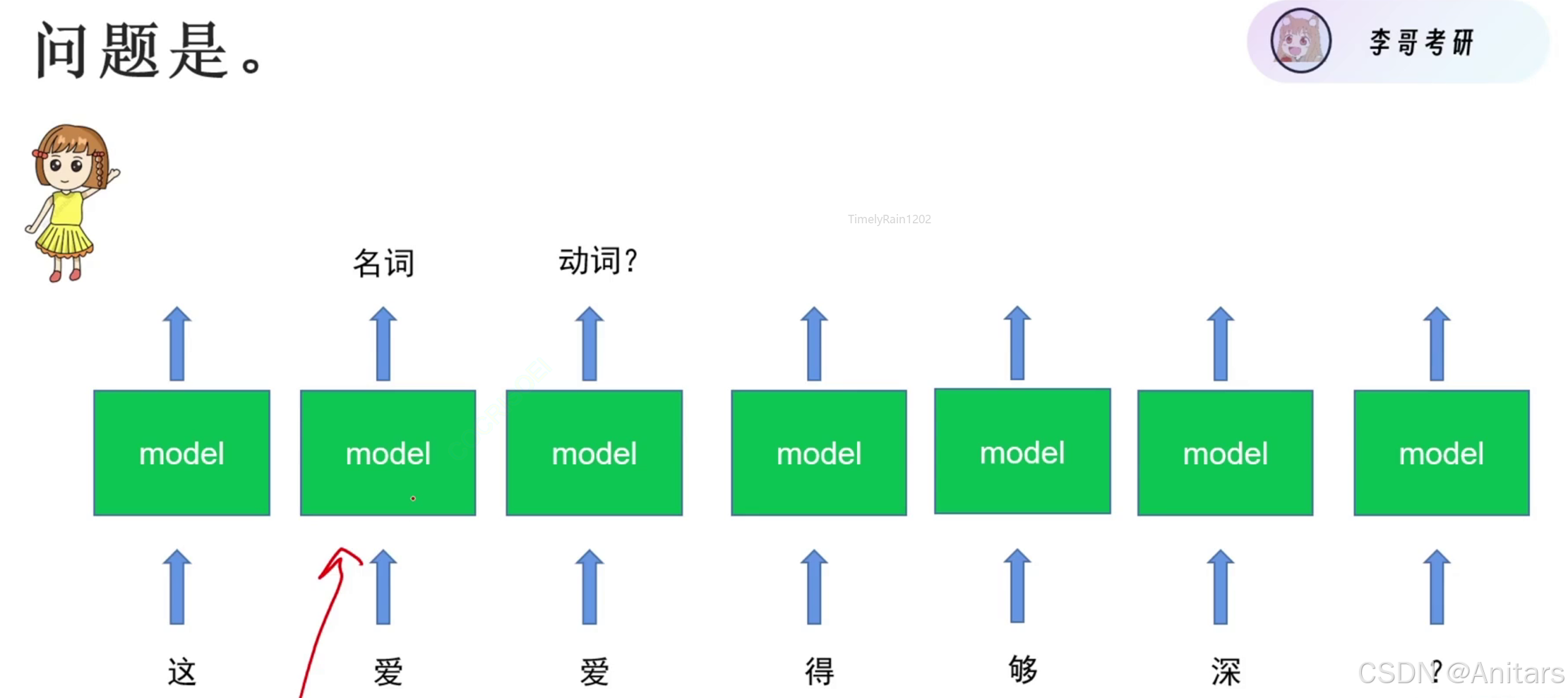
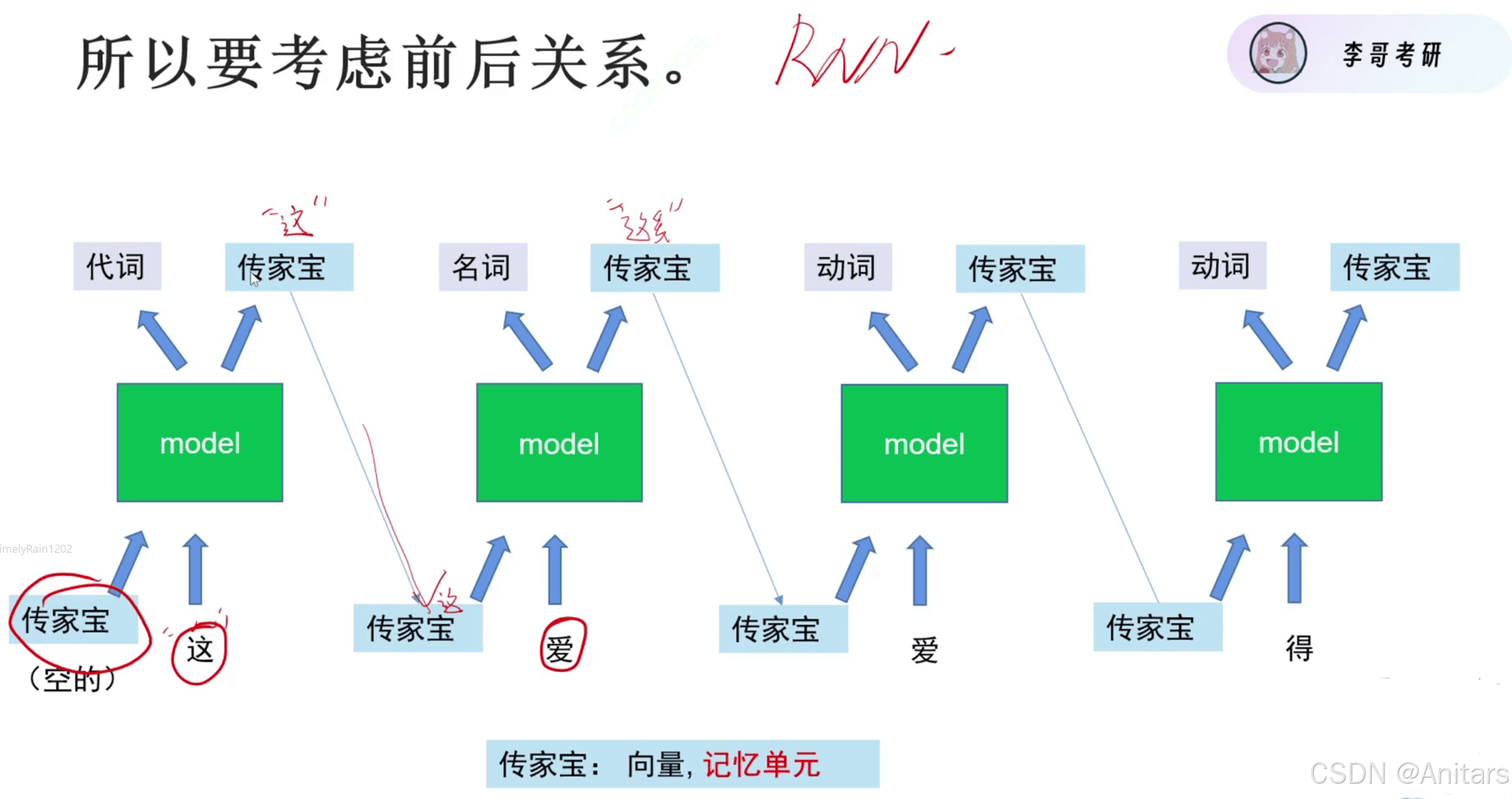
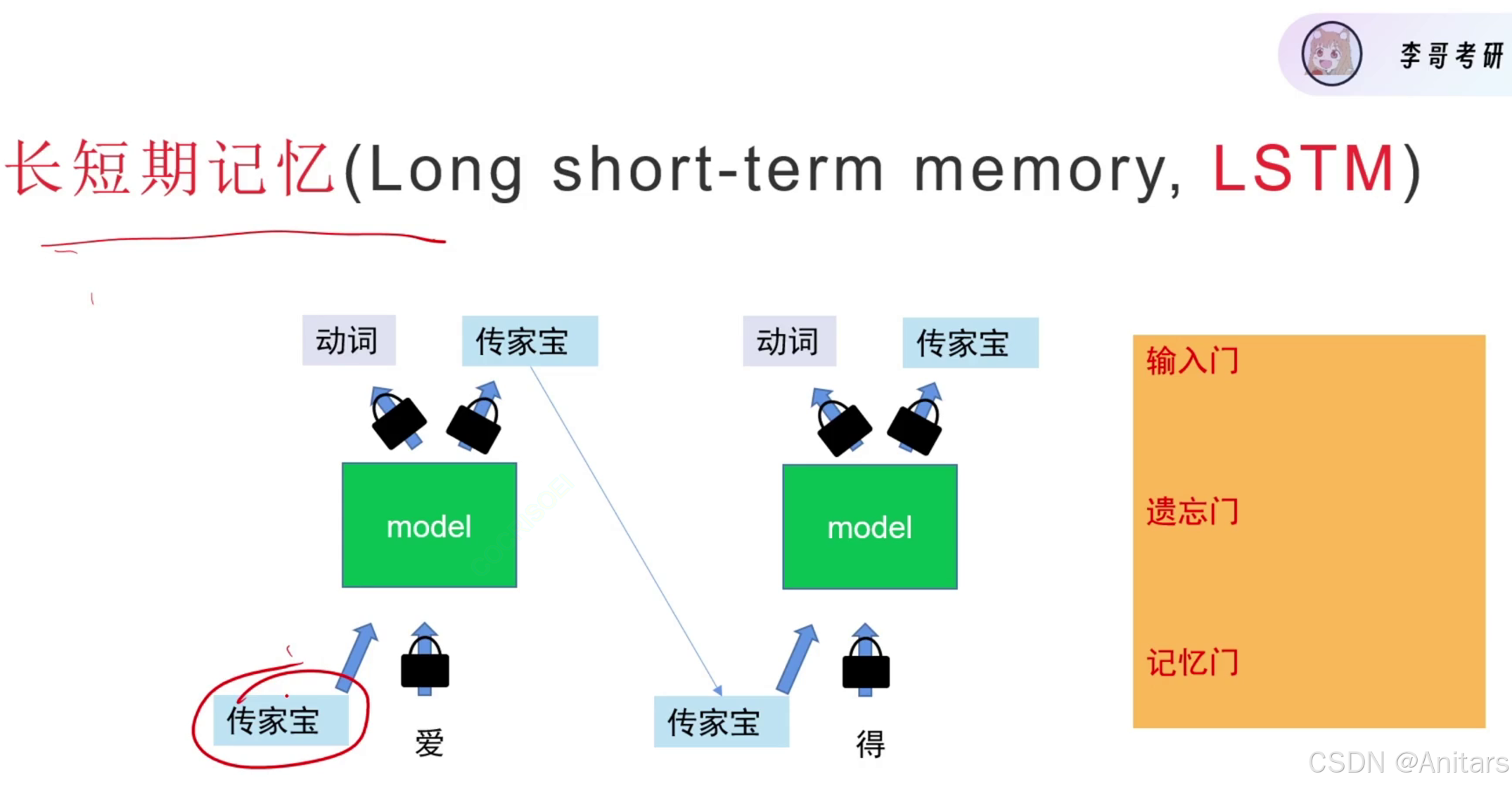
长短期记忆网络(Long Short-Term Memory, LSTM)是一种改进后的循环神经网络(Recurrent Neural Network, RNN),主要用于处理序列数据,能够更有效地捕捉和保持长期依赖信息。以下是关于LSTM的详细介绍:
- 概念与背景
- 传统的RNN在处理长期依赖时存在梯度消失或爆炸的问题,这使得模型难以有效地记住远处的信息。在自然语言处理等任务中,捕捉上下文信息对于模型性能至关重要。LSTM通过引入门控机制,解决了这一问题。
- 结构与工作原理
- 循环结构:LSTM保留RNN的循环结构,但增加了额外的状态。
- 细胞(Cell State):内部有一个新的状态,用于长期记忆。每个时间步,模型可以选择性地更新这个状态。
- 门控机制:通过两个门(Input Gate和Forget Gate)控制信息流动。输入门决定当前输入如何影响细胞状态,而忘却门允许模型取消不需要的信息。
- 动态信息管理
- 短期信息:由隐藏状态处理,通常保留在较短的时间范围内有效。
- 长期信息:由细胞状态持有,可以被动态地访问和更新,无需逐步丢弃。
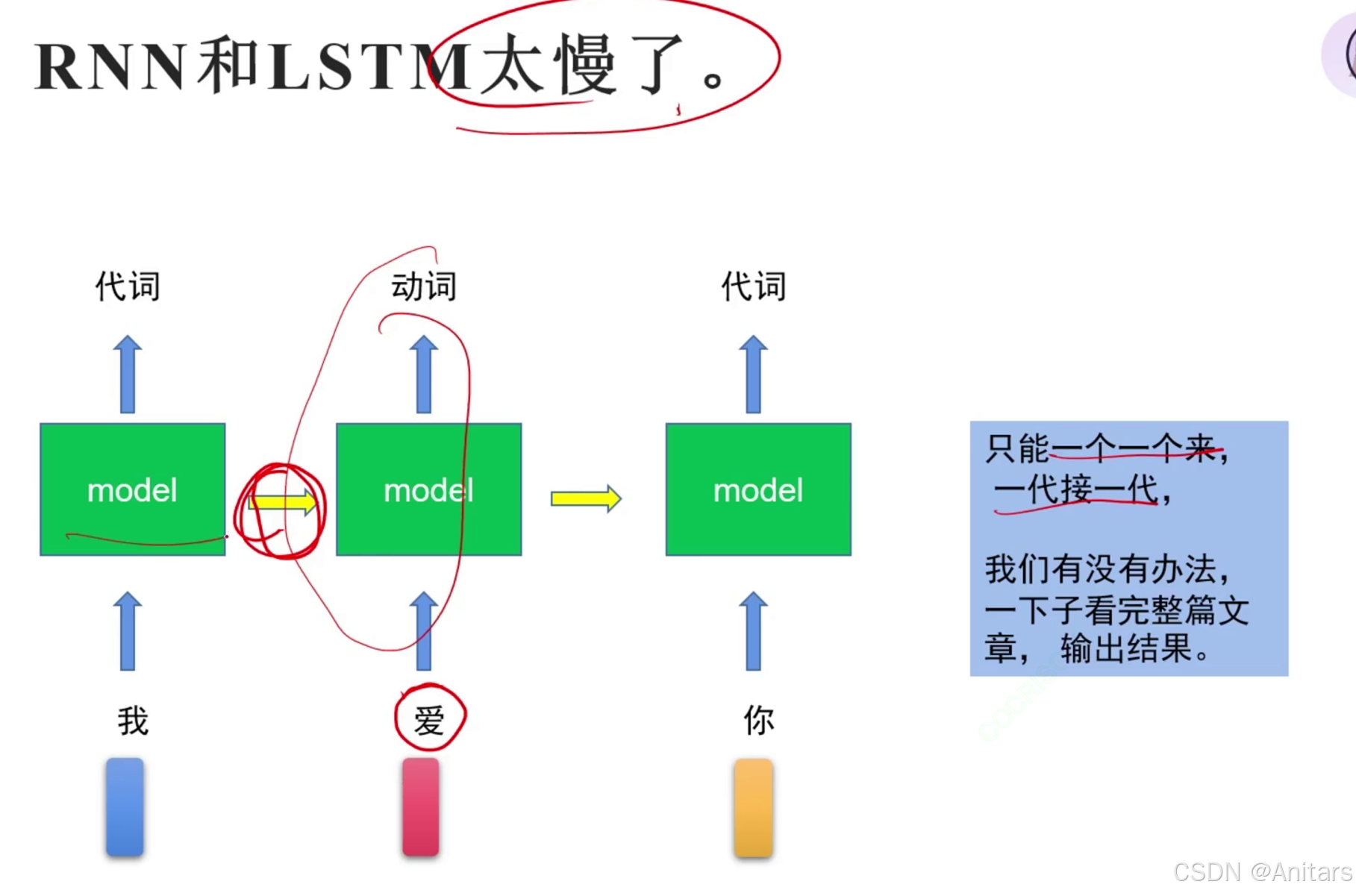
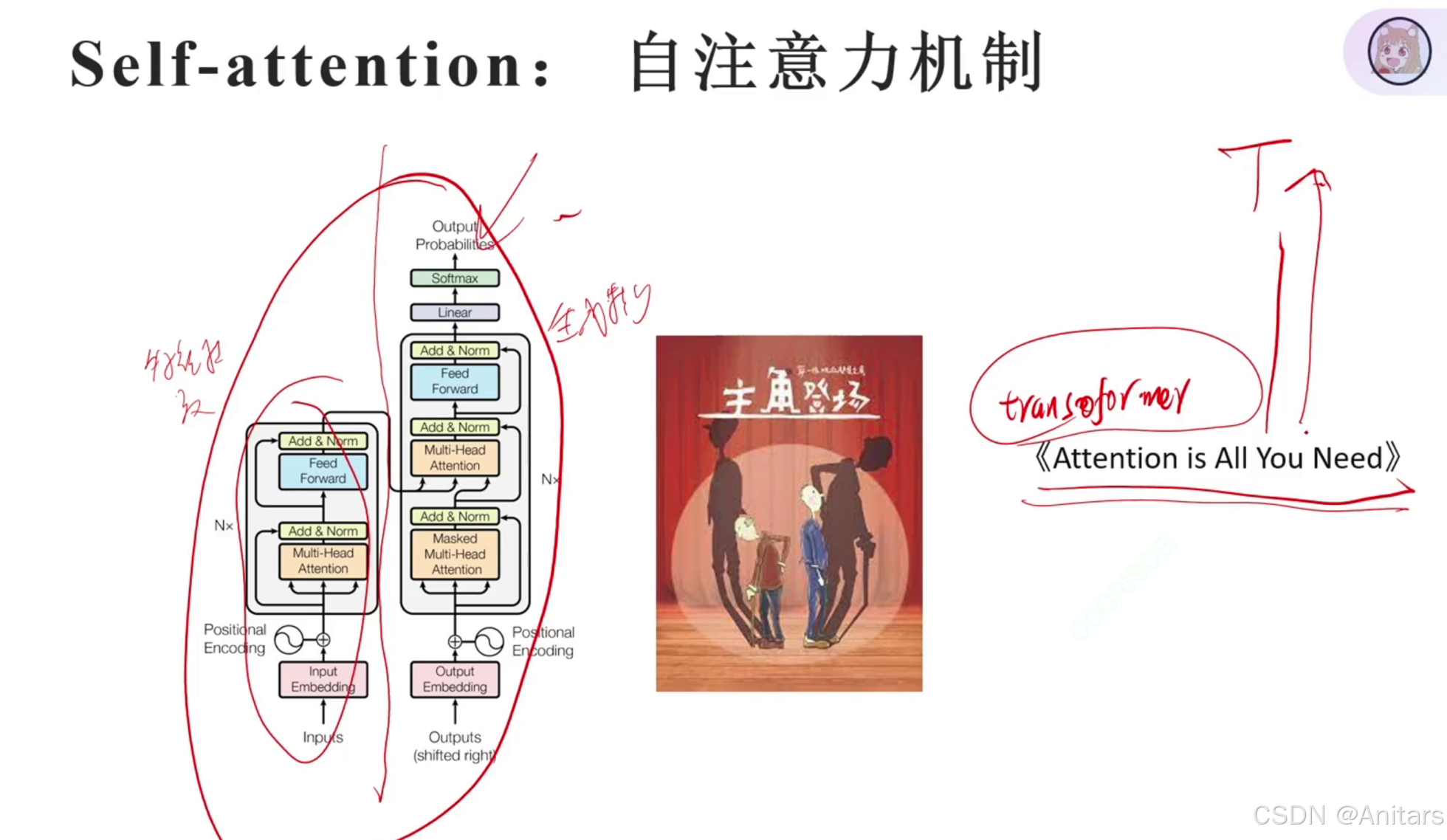

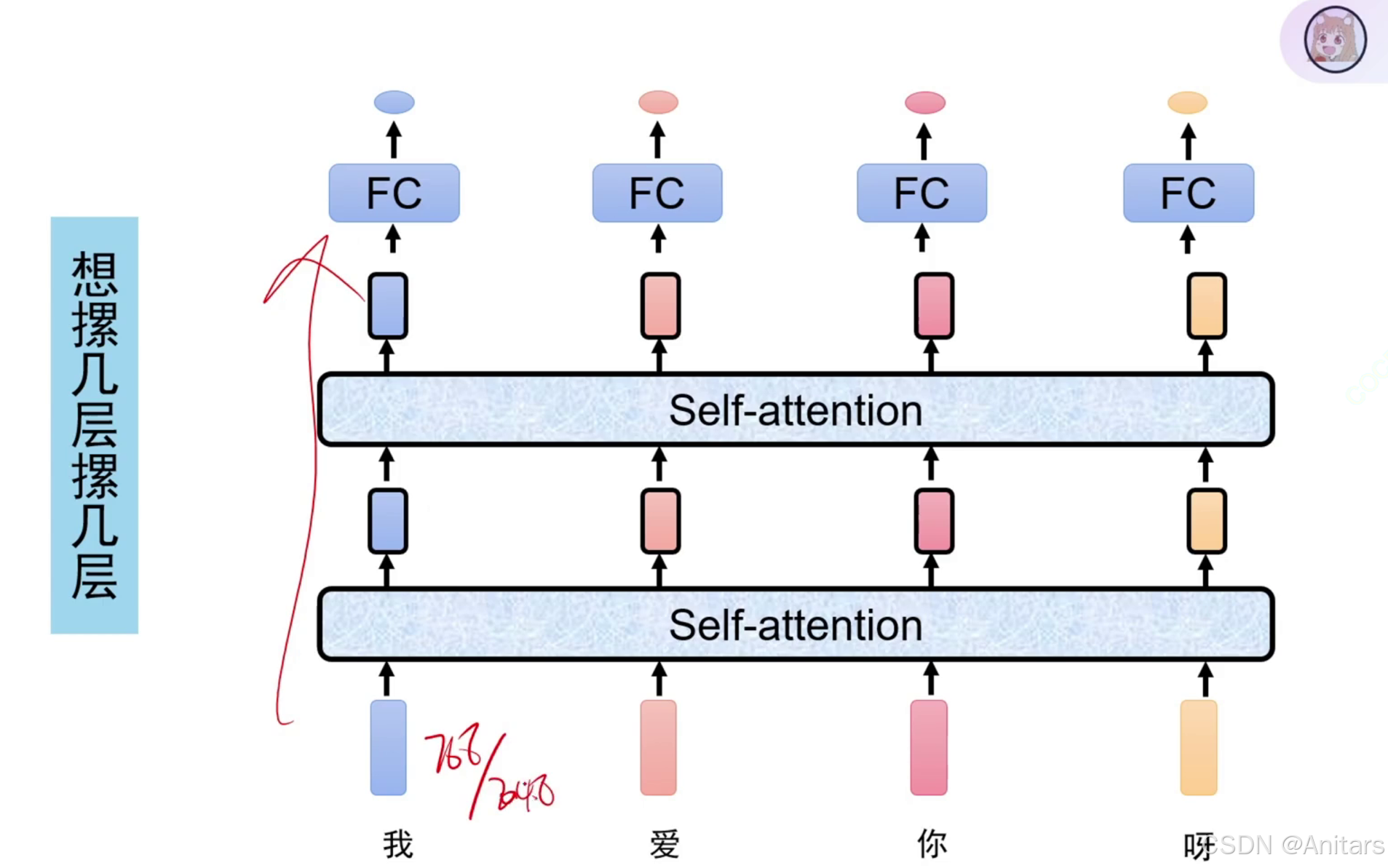
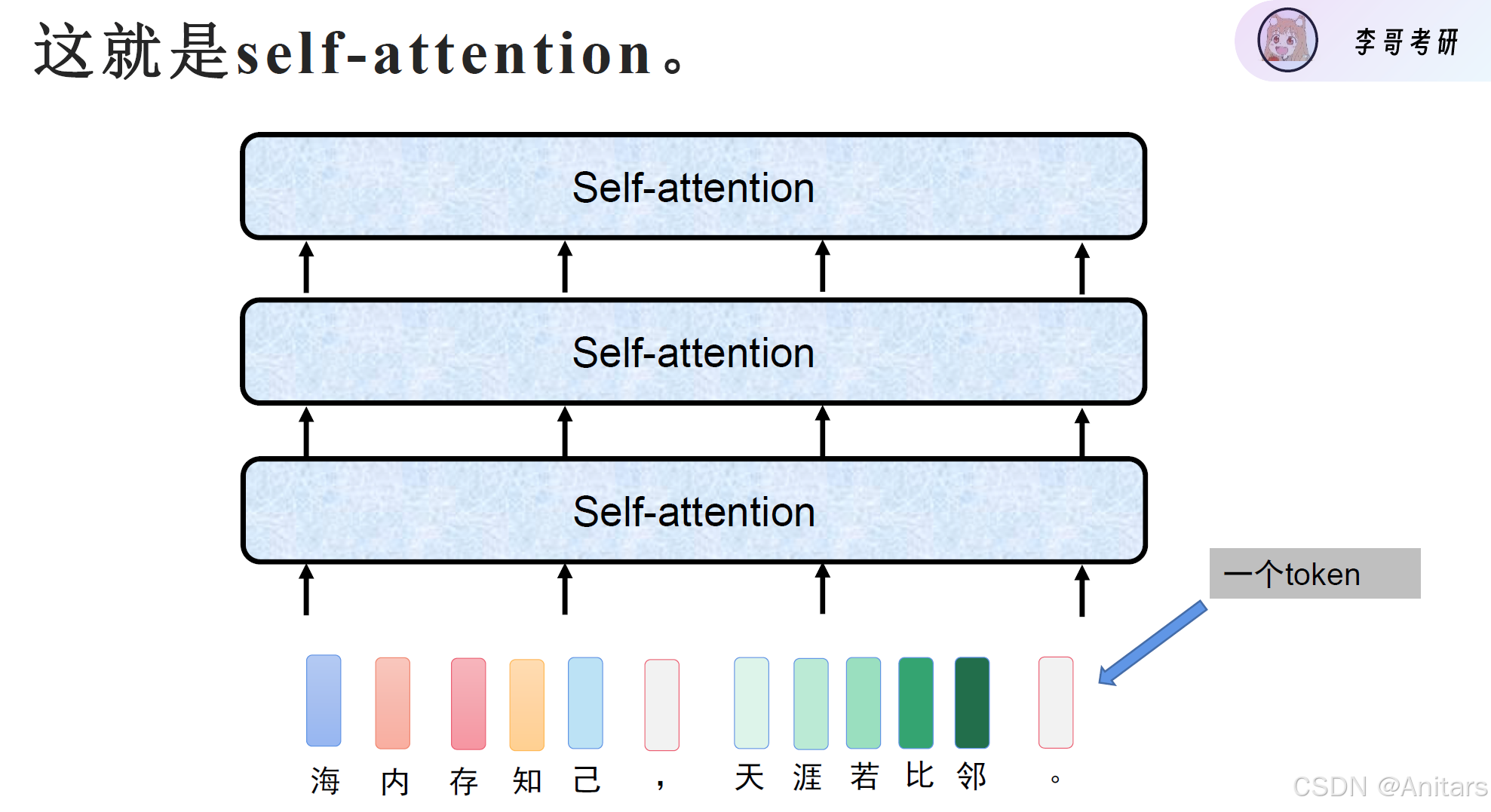
Transformer是一种基于自注意力机制的深度神经网络模型,主要用于自然语言处理任务。其核心思想是通过并行计算逐步捕捉序列中的长期依赖关系,从而在多个任务中取得优异表现。
主要特点:
-
自注意力机制:
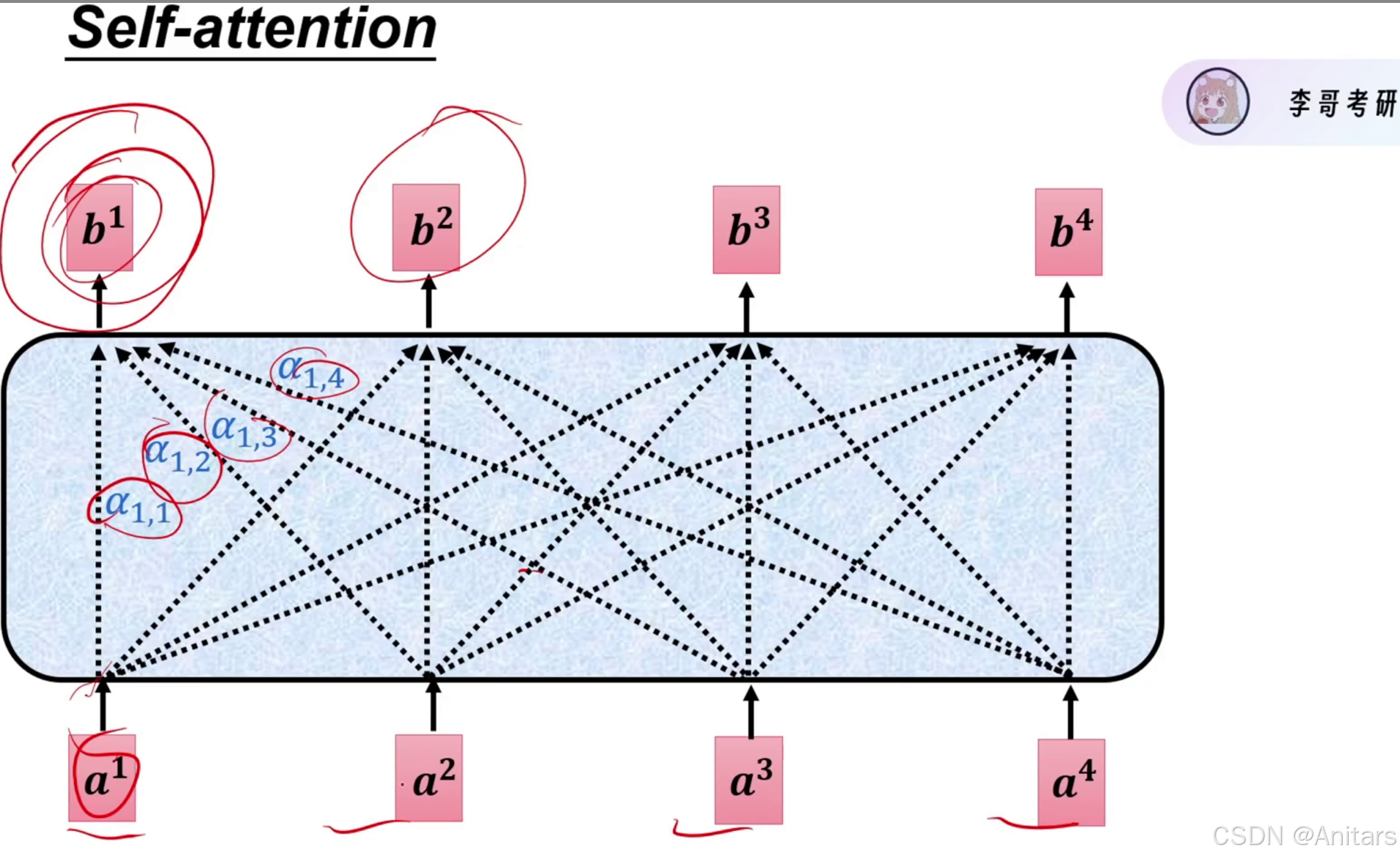
- Transformer采用了多头注意力(Multi-Head Attention),允许模型在处理输入序列时同时考虑所有位置的信息,捕捉长期依赖关系。
- 这种机制通过计算每个位置与其他位置之间的相关性,生成权重矩阵,并加权求和得到最终的注意力表示。
-
并行计算:
- 与传统的循环神经网络(RNN)依赖于序列的逐步处理不同,Transformer采用并行架构,可以同时处理整个序列。
- 这使得Transformer在训练时能够充分利用GPU加速,提高效率。
-
编码器与解码器:
- 编码器(Encoder)负责将输入序列转换为高层次的表示,捕捉输入中重要的特征和上下文信息。
- 解码器(Decoder)使用这些编码表示生成输出序列,通常用于任务如机器翻译、文本摘要等。
-
预训练与微调:
- Transformer模型通常通过在大规模数据集上进行预训练,获得通用能力,然后针对特定任务进行微调。
- 预训练使得模型能够学习语言中常见的模式和关系,为后续任务提供强大的基础。
-
多头机制:
- Transformer通常由多个注意力头组成,每个头处理不同范围或不同类型的信息,丰富了模型的表达能力。
- 这种多头机制能够捕捉到复杂的语义关系和上下文信息。
核心原理:
-
自注意力计算:
- 对于输入序列,自注意力机制通过计算每个位置与其他位置之间的相关性,生成权重矩阵。
- 权重矩阵的加权求和得到最终的注意力表示,这些表示能够捕捉到序列中的重要信息和长期依赖关系。
-
前馈网络:
- 自注意力机制后跟着一个前馈神经网络,用于对注意力表示进行非线性变换,最终生成编码或解码的高层次特征。
-
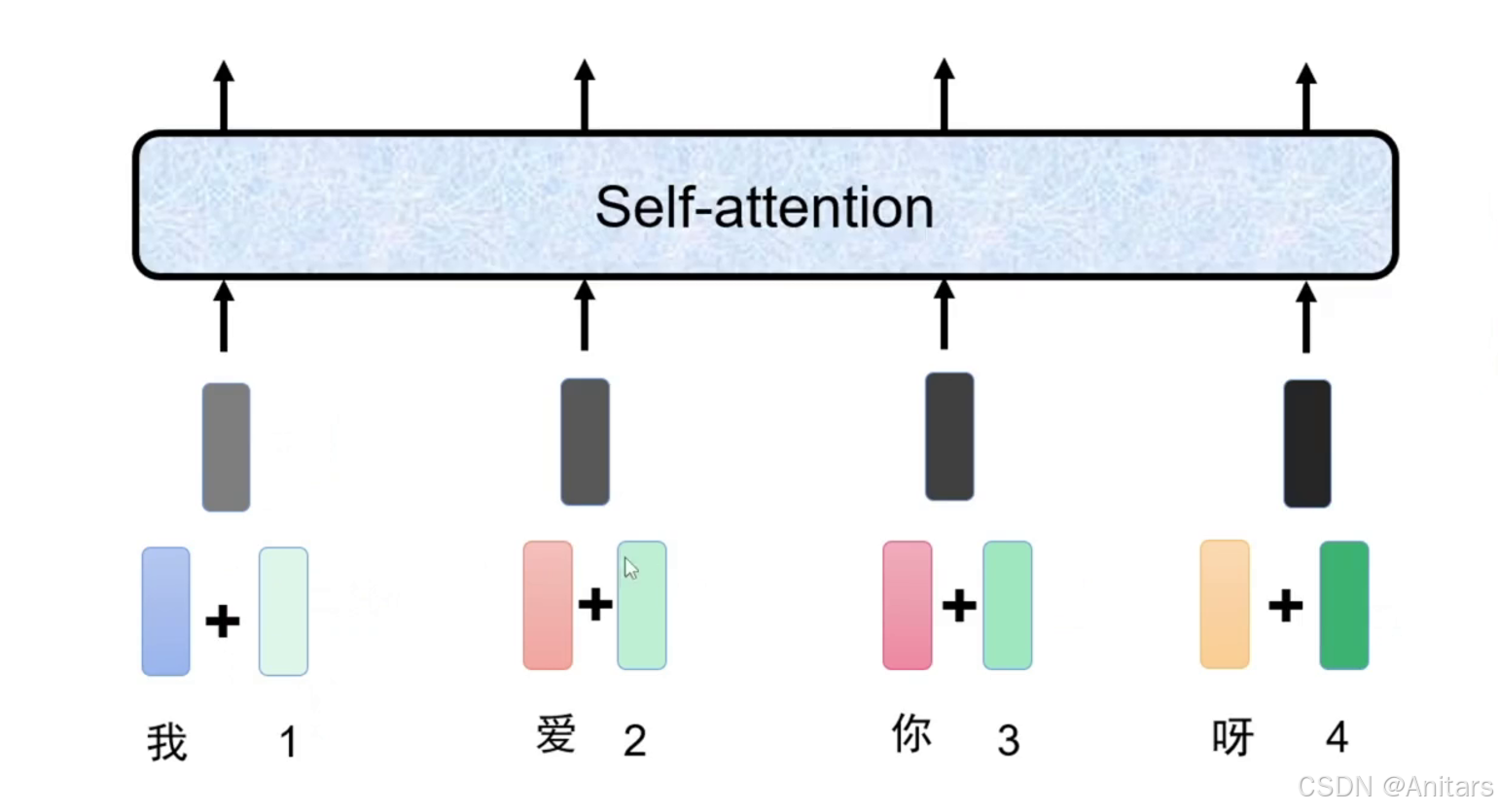
位置编码:
- 在某些实现中,Transformer还引入了位置编码来帮助模型理解序列中的绝对位置信息,这有助于捕捉到序列结构中的重要特征。
Transformer通过其自注意力机制和并行计算架构,使得模型能够高效地捕捉序列中的长期依赖关系。在自然语言处理领域,其应用范围广泛,包括机器翻译、文本摘要、问答系统等任务。通过预训练和微调,Transformer可以在多个任务中表现出色,是当前自然语言处理中的重要技术手段。
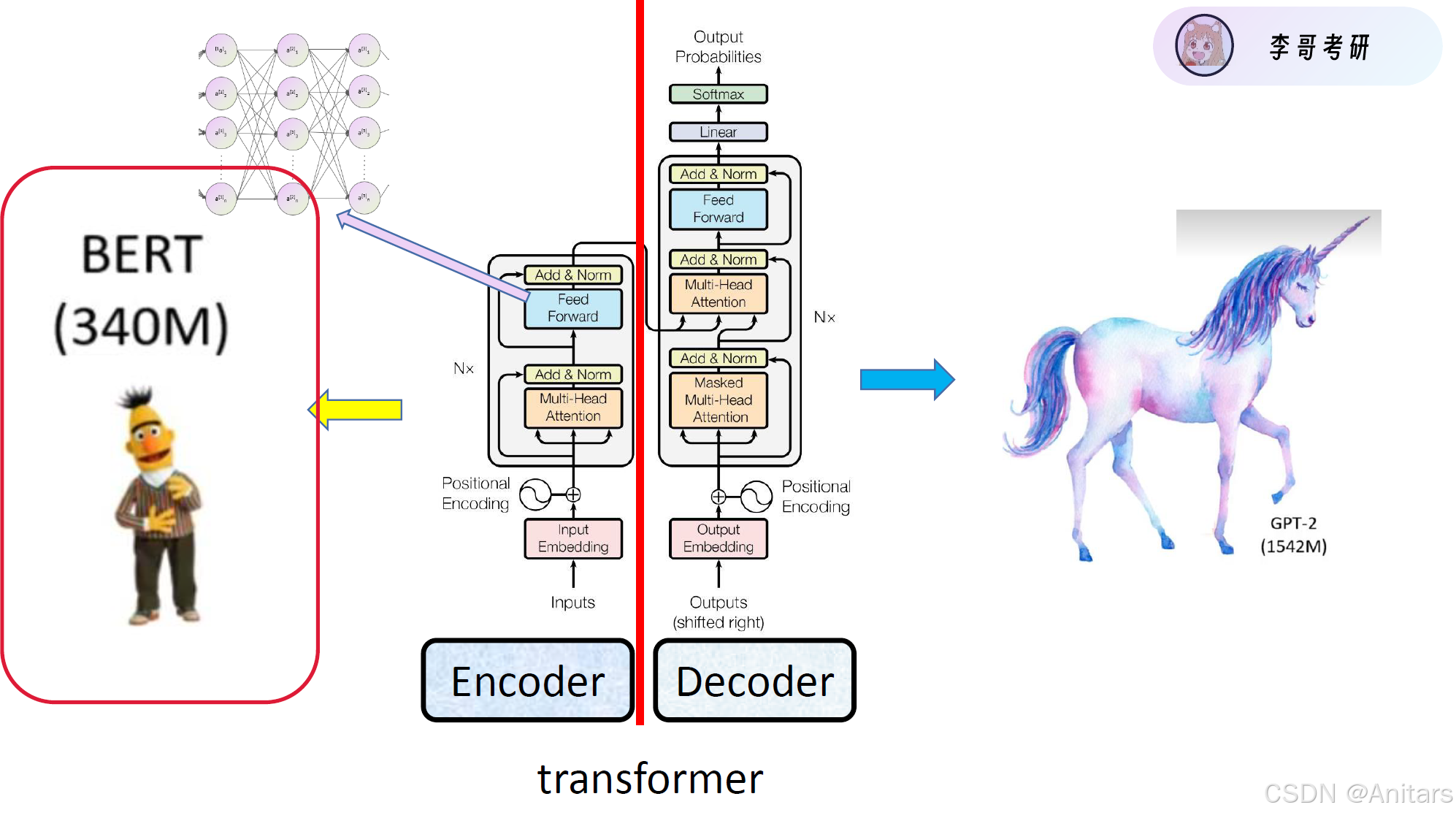
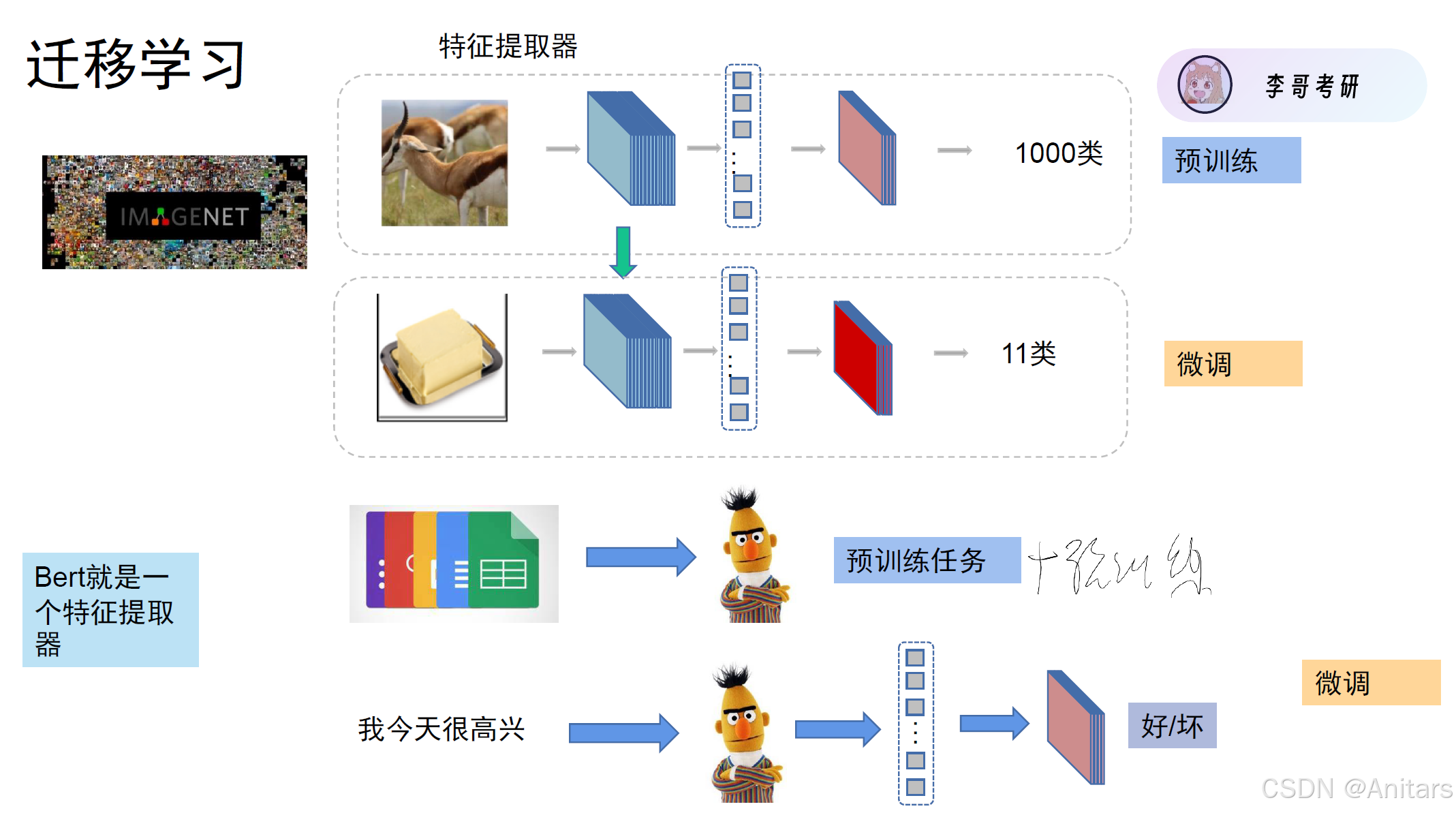
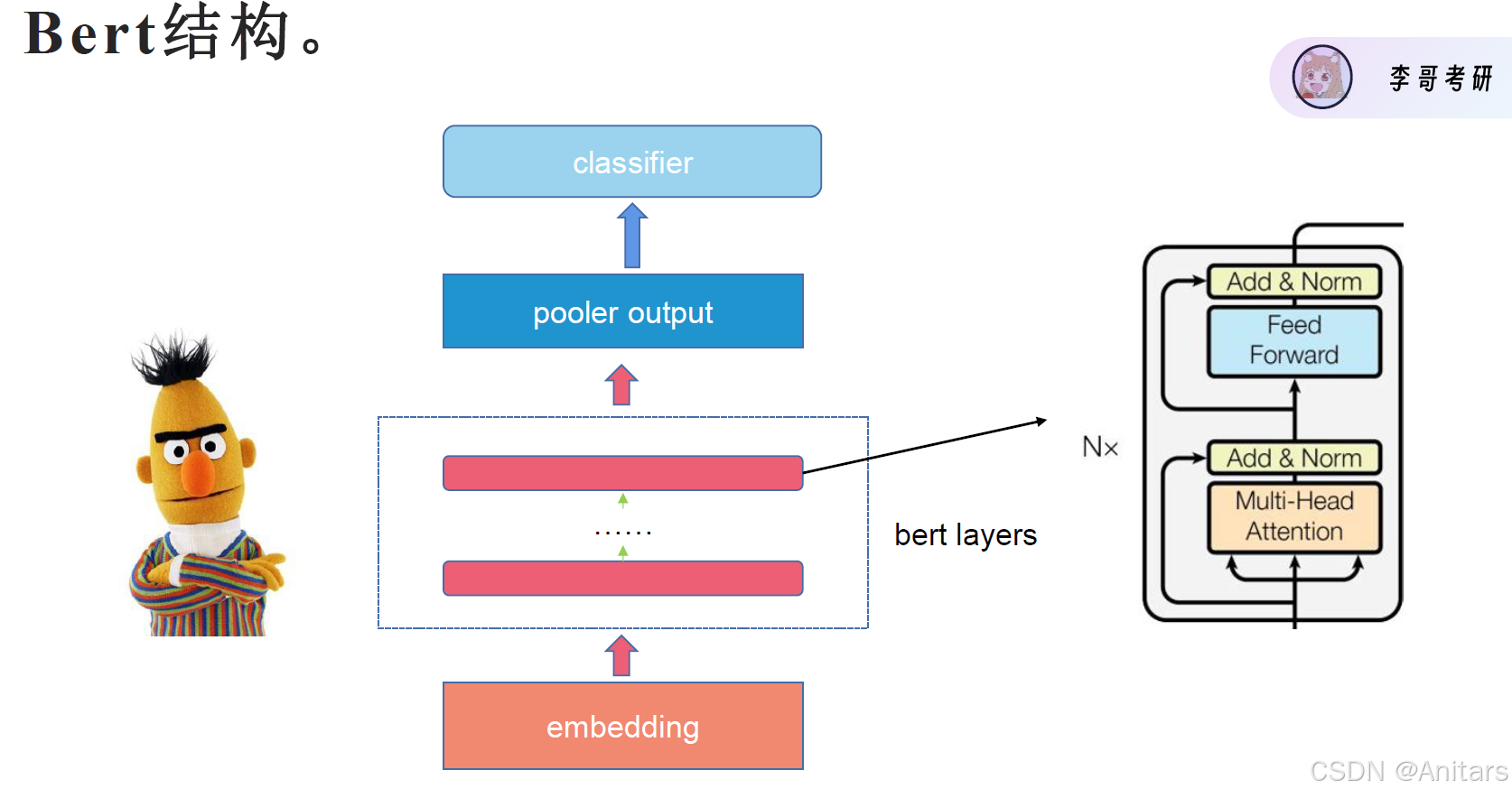
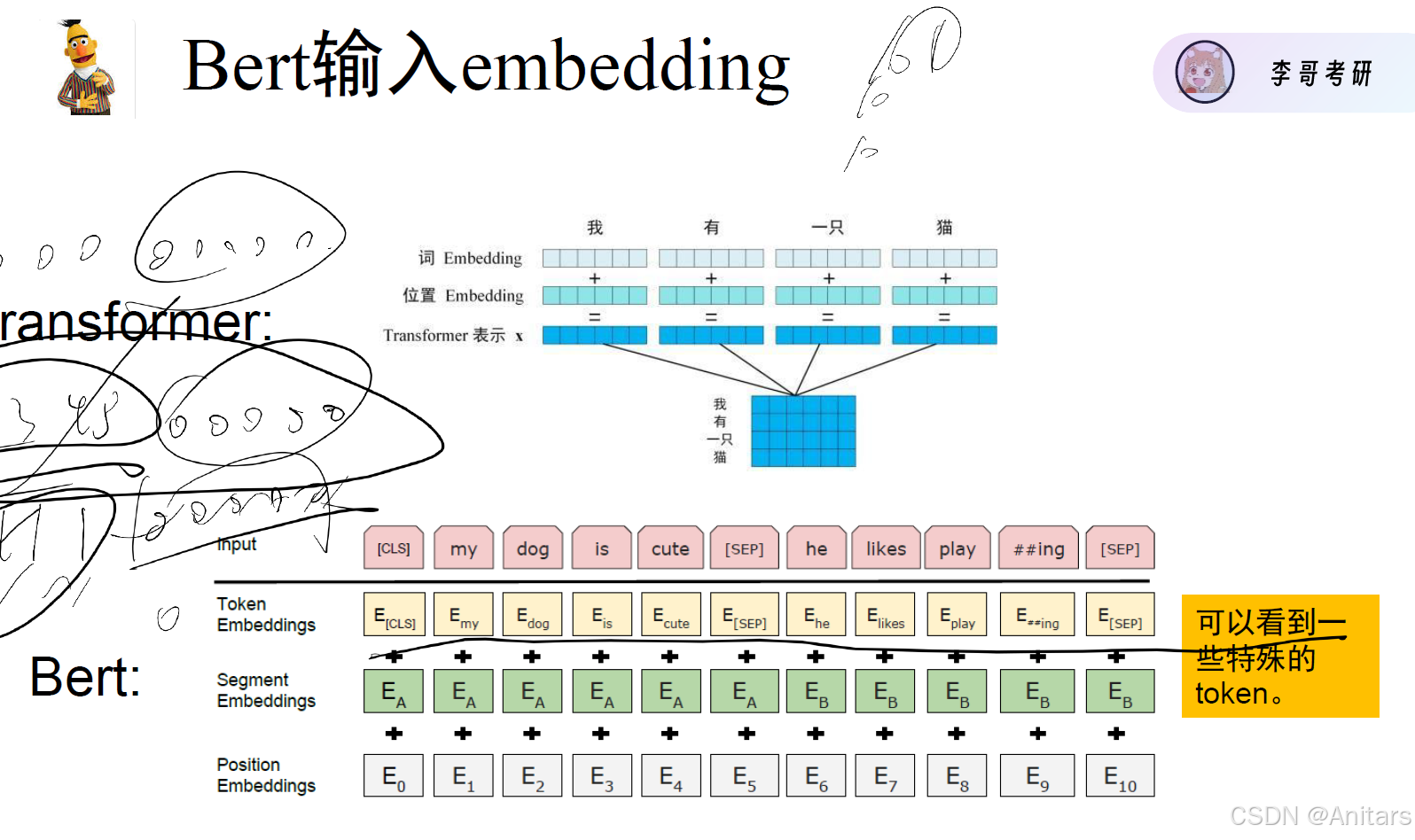
BERT(Bidirectional Encoder Representations from Transformers)是一种由Google于2018年10月发布的预训练语言表示模型,全称为双向编码器表示。它基于Transformer架构,旨在通过深度学习捕捉上下文信息,从而生成更加丰富和相关的语义表示。
BERT的结构
BERT由三个主要模块组成:
- Embedding模块:位于最底层,负责将输入单词转换为向量表示。
- Transformer模块:中间层,处理上下文信息,使模型能够理解周围单词之间的关系。
- 预微调模块:位于最上层,可根据特定任务需求对模型进行微调,以适应不同任务。
BERT的优势
- 双向结构:BERT能够同时考虑上下文信息,使其在语言关系理解方面表现优异。
- 大规模预训练:通过在大量数据上进行预训练,BERT能够捕捉到丰富的语义信息。
- 广泛应用:BERT在多种NLP任务中表现出色,如机器阅读理解、问答系统和语言推断。
Embedding模块与Transformer模块详解
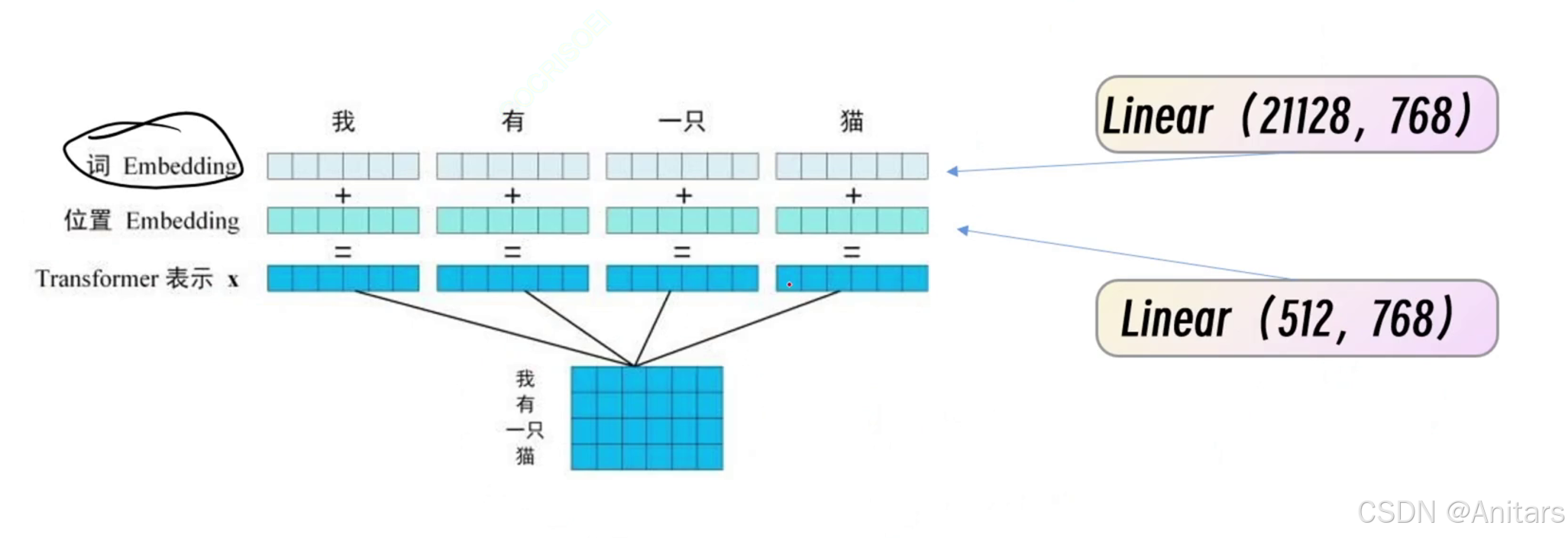
1. Embedding模块
Embedding模块是BERT的最底层组件,负责将输入的单词(token)转换为固定维度的向量表示。具体来说,Embedding模块包含以下几个步骤:
a. Token Embedding(词嵌入)
- 功能:将每个输入单词转换为一个固定维度的向量。
- 细节:
- 每个单词会被映射到一个稀疏向量(sparse vector),表示该单词在整个语料库中的位置。
- 在BERT中,Token Embedding层负责将每个token(如单词或子词)转换为768维的向量表示。
- 输入:一系列单词序列(tokens)。
- 输出:一个矩阵,其中每一行对应一个单词的嵌入向量。
b. Position Embedding(位置嵌入)
- 功能:为每个位置提供额外的信息,帮助模型理解单词在句子中的位置关系。
- 细节:
- 在BERT中,Position Embedding并非直接嵌入到Token Embedding中,而是通过类似于自注意力机制的方式生成位置信息。
- 例如,在处理序列输入时,模型会为每个单词生成一个位置标记(position label),这些标记被用于调整单词嵌入,使其能够捕捉到位置相关的信息。
c. Segment Embedding(段嵌入)
- 功能:将连续的单词组合成一个段(segment),并为段生成一个全局表示。
- 细节:
- 在BERT中,Segment Embedding通常通过前馈网络实现,将一系列单词嵌入转换为一个较小维度的向量。
- 这一步骤的目的是将局部信息(单词之间的关系)转化为全局信息。
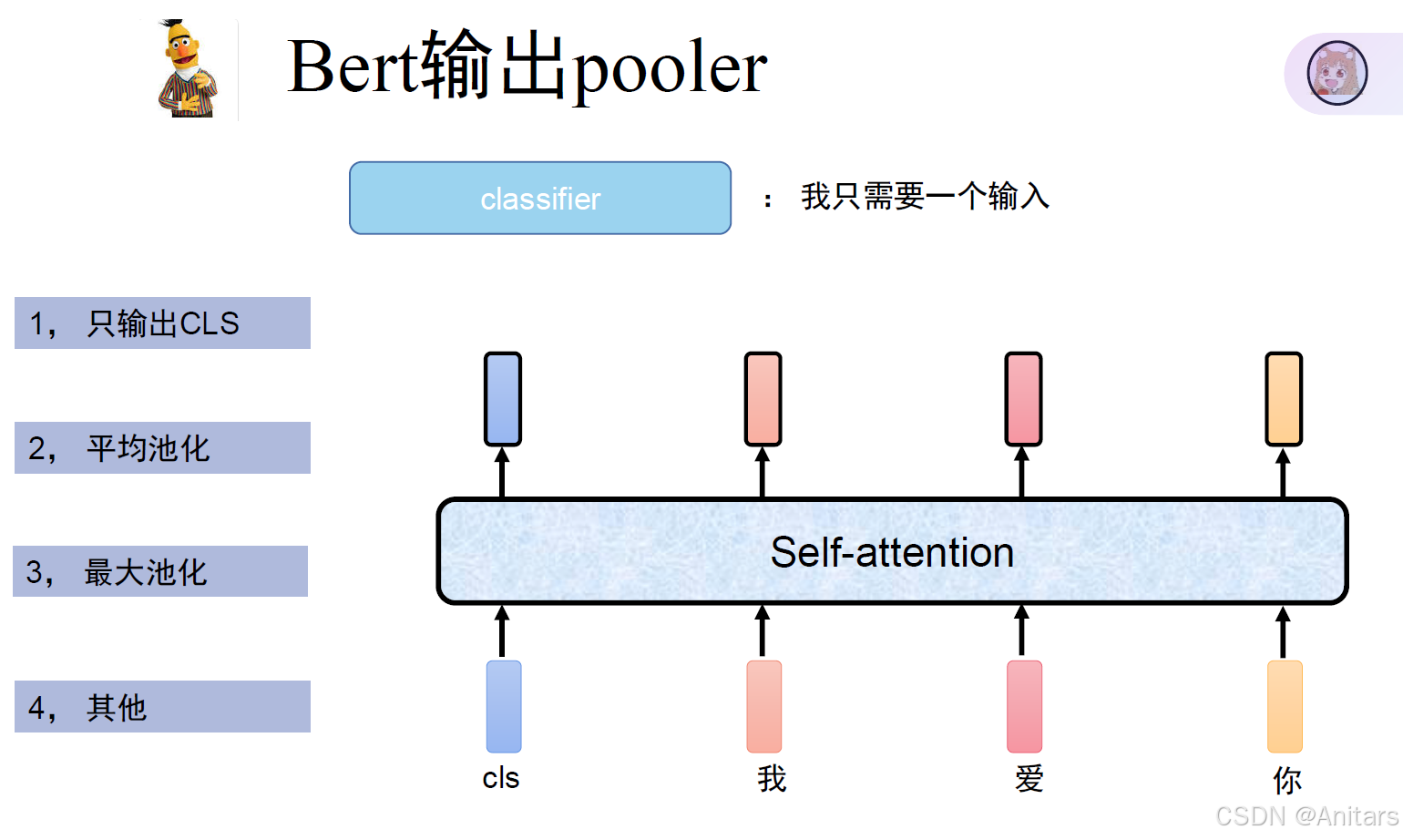
d. pooled embeddings(池化嵌入)
- 功能:将段内的嵌入信息聚合成一个更具代表性的向量。
- 细节:
- BERT中通常采用平均池化或最大池化等方法,将一系列单词嵌入汇总为一个全局表示。
2. Transformer模块
Transformer模块是BERT的核心组件,负责处理序列中的上下文信息,使模型能够理解不同单词之间的关系。Transformer模块的定义基于自注意力机制(self-attention),具体包括以下几个关键步骤:
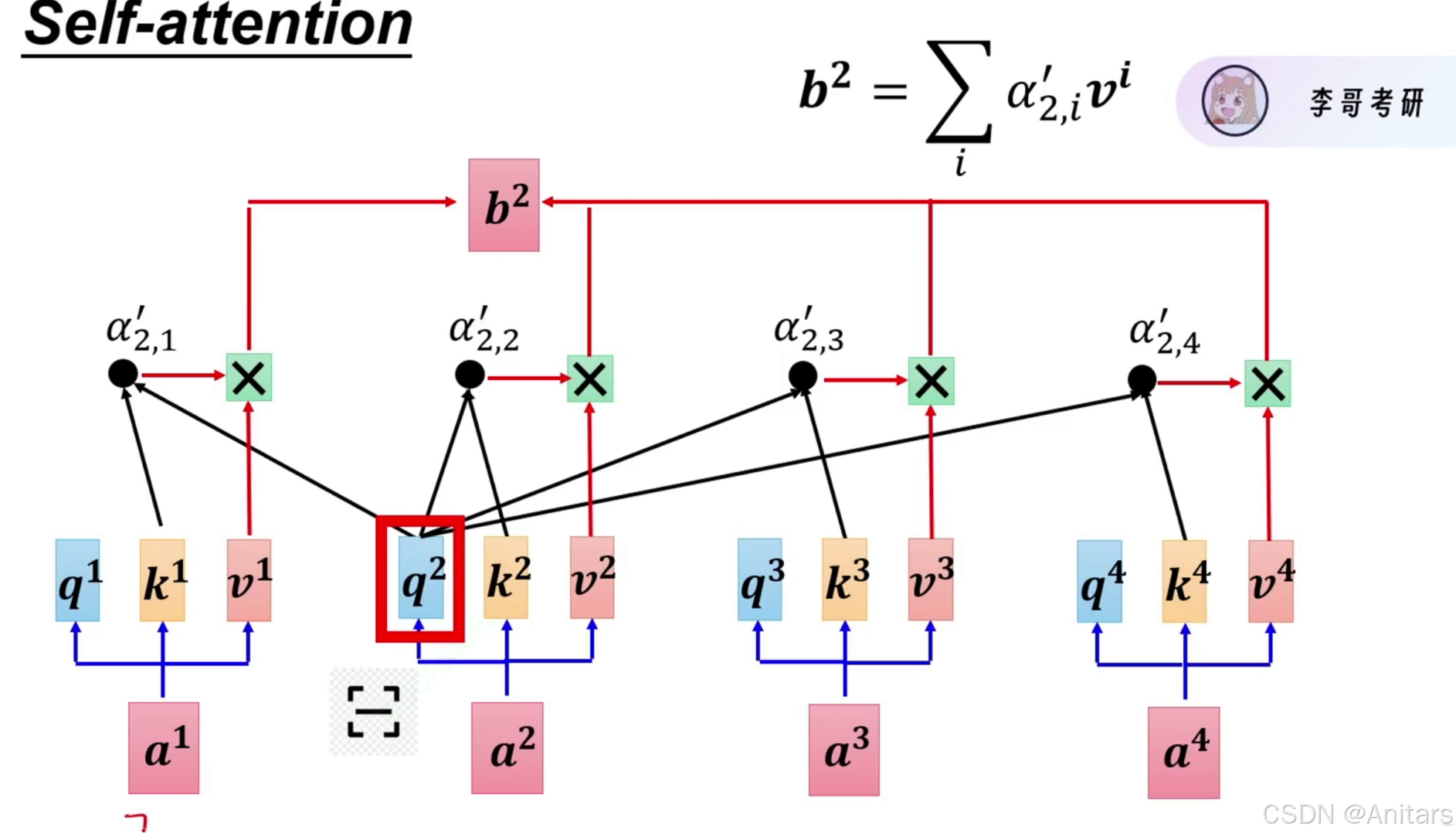
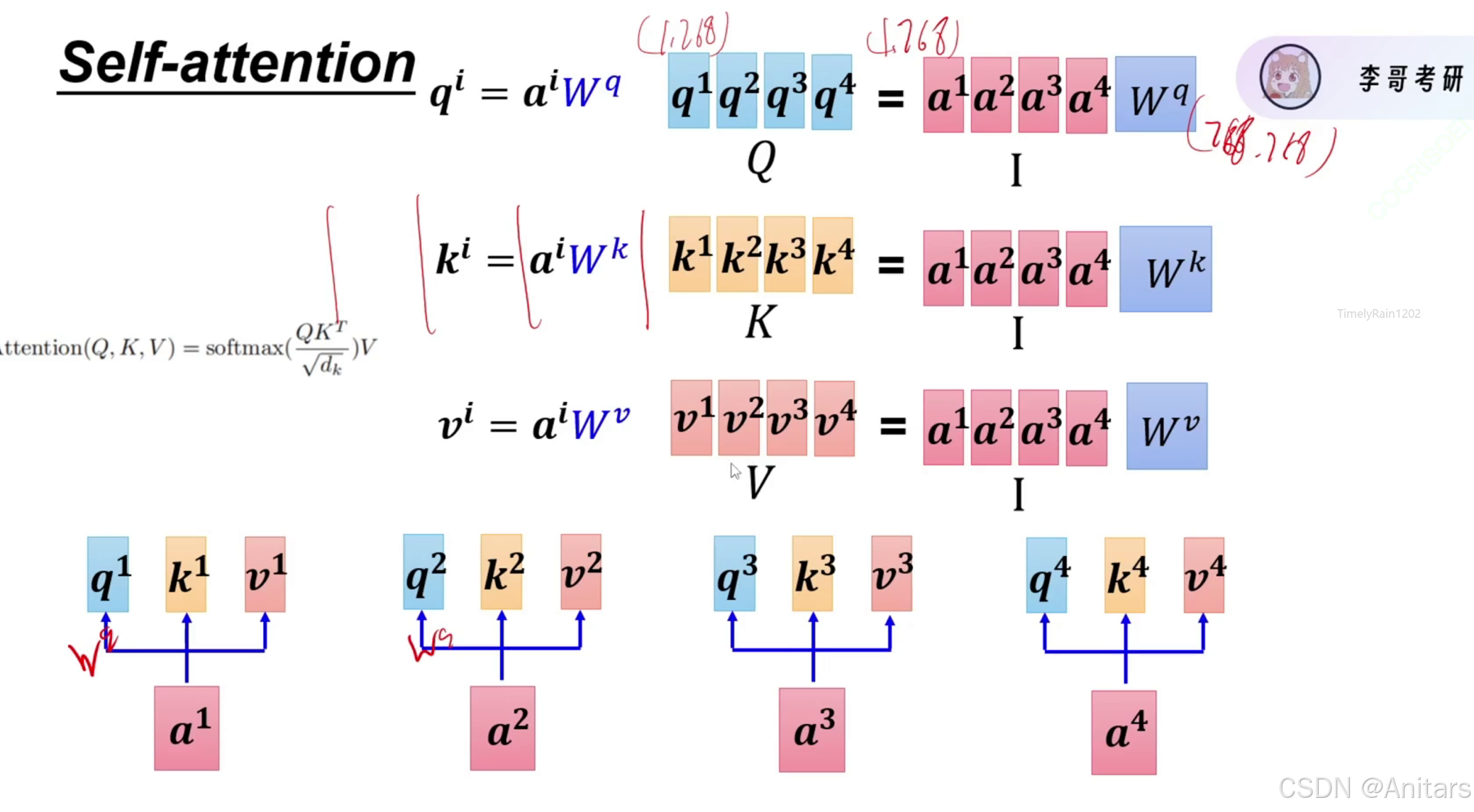
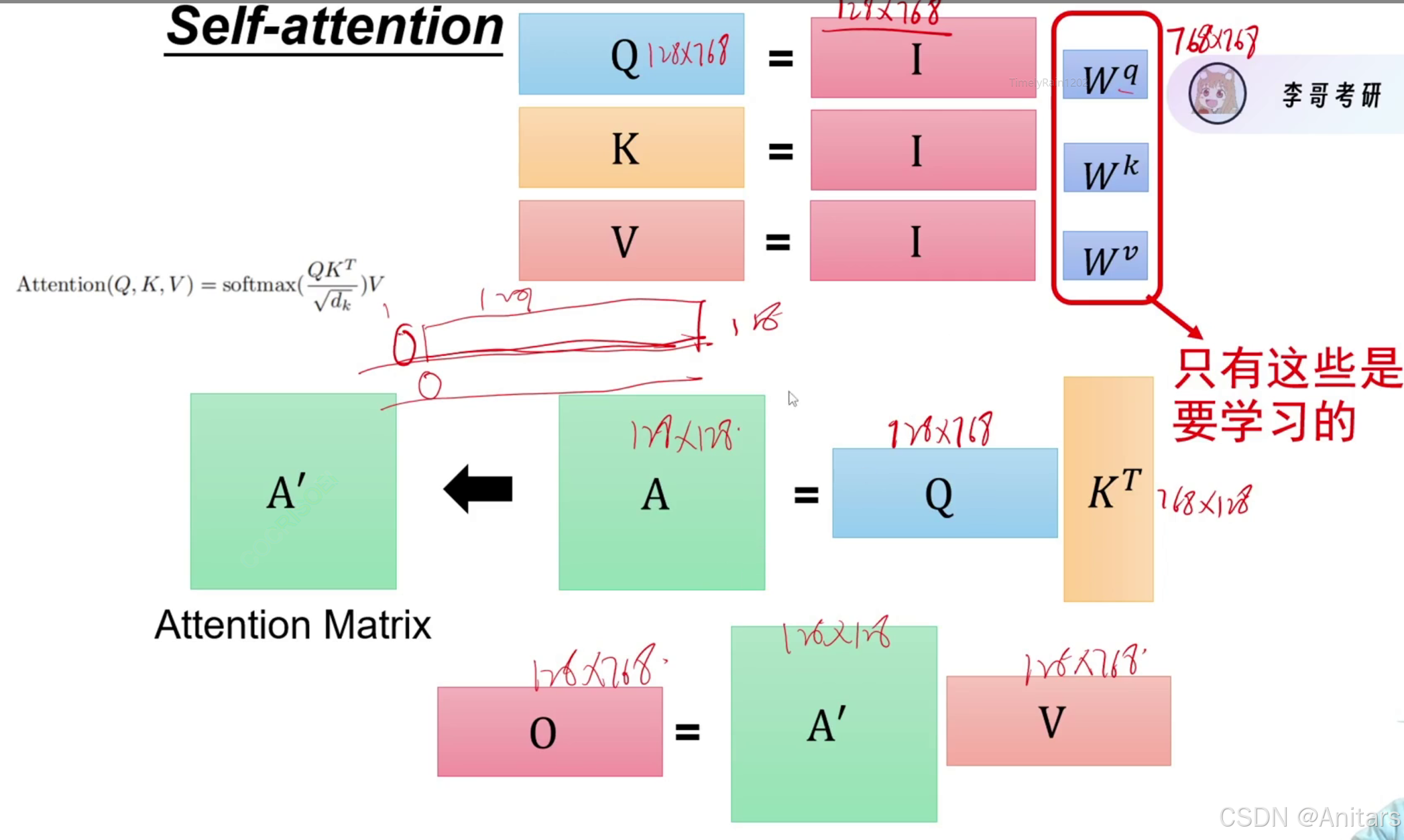
a. Query、Key和Value向量
- 功能:将嵌入后的token表示转换为Query、Key和Value三种向量。
- Query用于捕捉当前单词需要关注的信息。
- Key用于表示与当前单词相关的其他单词。
- Value用于存储与Key相关的具体信息。
b. 自注意力计算
- 功能:通过Query和Key之间的相似性矩阵,确定哪些单词与当前单词有关联。
- 细节:
- 模型会计算所有单词与当前单词的相似性(attention scores),然后通过 softmax函数将这些分数标准化。
- 最终获得一个权重矩阵,其中权重表示不同单词之间的相关程度。
c. 应用自注意力结果
- 功能:根据自注意力得到的权重,重新加权其他单词嵌入,从而聚合上下文信息。
- 细节:
- 对于每个位置,模型会计算一个加权的上下文表示(context-aware representation)。
- 这一步骤使得模型能够捕捉到多层次的关系信息。
d. 前馈网络
- 功能:对自注意力输出进行进一步加工,生成最终的嵌入表示。
- 细节:
- BERT通常采用多个前馈层,通过非线性激活函数(如ReLU)和卷积操作增强特征表达。
3. Embedding模块与Transformer模块的关系
-
协同作用:
- Embedding模块为Transformer模块提供初始的嵌入表示。
- Transformer模块则利用这些嵌入表示,捕捉到单词之间的长距离依赖关系(long-range dependencies)。
-
数据流方向:
- 输入 -> Token Embedding -> Position Embedding -> Segment Embedding -> pooled embeddings -> Transformer模块 -> 最终输出。
4. BERT的整体架构
BERT的整体架构可以简化为以下步骤:
- 输入:一系列单词序列(tokens)。
- Token Embedding:将单词嵌入到高维空间。
- Position Embedding:通过自注意力生成位置信息。
- Segment Embedding:将连续的单词组合为段,并生成全局表示。
- Transformer模块:处理上下文信息,捕捉多层次关系。
- 输出:经过多个前馈网络后,最终生成嵌入表示。
通过以上步骤,可以看出Embedding模块和Transformer模块在BERT中的作用。两者相辅相成,共同提升了模型对复杂语境的理解能力。

















 3873
3873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









