




硬件内存
在前面的章节中,我们多次提到了“CPU 缓存友好”和“Cache Miss(缓存未命中)”。你说得对,如果不把内存(DRAM)和缓存(SRAM)的物理原理讲清楚,那些概念终究只是空中楼阁。
我们要从物理硬件的最底层,解开“快”与“慢”的秘密。
第一部分:物理上的天壤之别 —— DRAM vs SRAM
你可能听说过“内存是 DRAM,缓存是 SRAM”。这几个字母背后的物理结构,决定了它们命运的不同。
1. 内存:DRAM (Dynamic RAM) —— 漏水的桶
你电脑里插的那根 16GB / 32GB 内存条,学名叫 DRAM(动态随机存取存储器)。
-
微观结构: 每一个比特(0 或 1),是由 1 个电容(Capacitor) 和 1 个晶体管 组成的。
-
电容: 就像一个小水桶。
-
存 1: 桶里有水(有电荷)。
-
存 0: 桶里没水(无电荷)。
-
-
致命弱点: 电容会漏电! 这就像一个破水桶,你刚倒满水(写入 1),过一小会儿水就漏光了(变成了 0)。 为了保住数据,CPU 必须每隔几毫秒就对所有内存进行一次 “刷新”(Refresh) —— 检测哪里有水,赶紧再灌满。
-
速度瓶颈:
-
充放电需要时间。
-
刷新的过程会占用总线,导致无法读写数据。
-
这导致 DRAM 的访问延迟通常在 60ns ~ 100ns(纳秒)级别。对于 CPU 来说,这慢得像蜗牛。
-
-
优点: 结构简单(1电容+1晶体管),哪怕是指甲盖大小的硅片也能塞进几十亿个,所以便宜、容量大。
2. 缓存:SRAM (Static RAM) —— 昂贵的锁扣
CPU 内部集成的 L1/L2/L3 缓存,学名叫 SRAM(静态随机存取存储器)。
-
微观结构: 每一个比特,是由 6 个晶体管 组成的“触发器”(Flip-Flop)电路。
-
它不像水桶,更像是一个机械锁扣。
-
一旦你把它拨到“1”的位置,只要不断电,它就死死地卡在“1”,永远不会漏电,也不需要刷新。
-
-
极速原因:
-
不需要刷新。
-
晶体管开关速度极快,纯电路导通。
-
访问延迟通常在 0.5ns ~ 10ns 级别。比内存快 100 倍。
-
-
致命弱点: 太贵、太占地儿!
-
存 1 个比特,DRAM 只要 1 个晶体管,SRAM 要 6 个。
-
同样的硅片面积,SRAM 的容量只有 DRAM 的几分之一,造价却是 DRAM 的几十倍。
-
总结: 计算机不能全用 SRAM(买不起,也造不出那么大的),也不能全用 DRAM(太慢)。于是,“存储器层级结构” 诞生了。
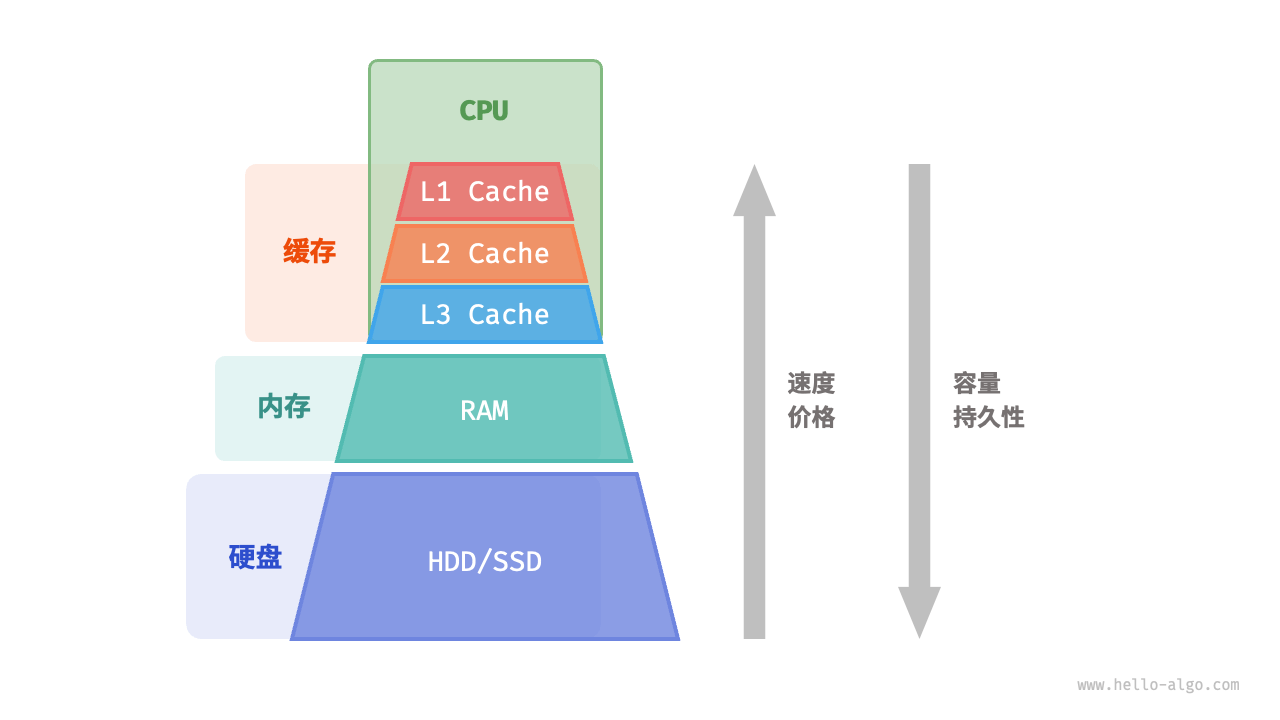
第二部分:金字塔层级 —— CPU 的“厨房哲学”
为了理解层级,我们用一个“大厨做菜”的类比:
-
CPU 核心: 大厨(负责切菜、炒菜)。
-
寄存器 (Registers): 大厨的手。数据就在手里,拿来就用,速度最快,但手里只能拿几个东西。
-
L1 缓存: 案板。就在大厨面前,切好的菜放这里。伸手就够得到,容量很小。
-
L2 缓存: 厨房灶台。离案板很近,能放几个盘子。
-
L3 缓存: 厨房置物架。所有厨师(多核)共享,能放一锅汤。
-
内存 (RAM): 冰箱。在车库里。要去拿食材得走一段路,很慢。
-
硬盘 (SSD/HDD): 超市。远在几公里外。
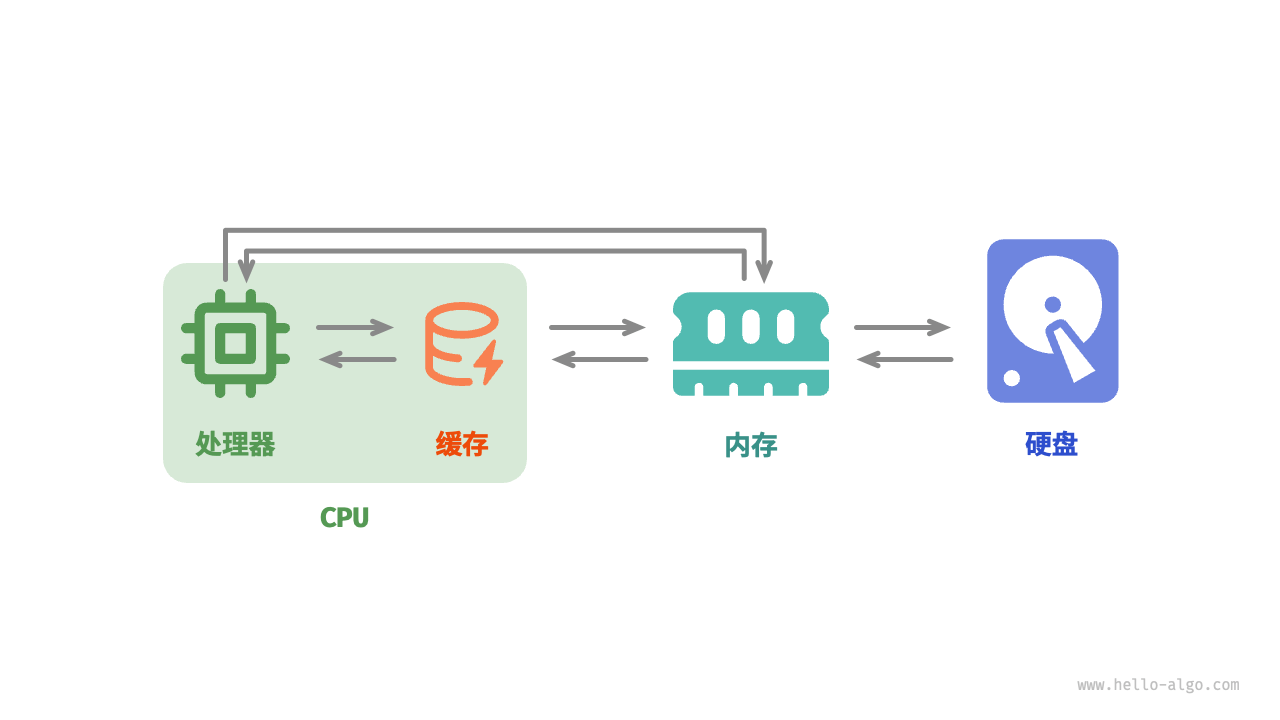
数据在层级中的流动:
当 CPU 需要读取一个数据 x 时:
-
查 L1: 案板上有吗?有Cache Hit (0.5ns)。直接用。
-
查 L2: 案板没有,灶台上有吗?有 拿来放案板上,再用 (7ns)。
-
查 L3: 灶台没有,置物架有吗?有 拿来放灶台,再放案板,再用 (15ns)。
-
查内存: 都没有 Cache Miss。大厨放下刀,走到车库冰箱去拿 (100ns)。注意: 大厨去冰箱不会只拿一根葱,他会把一整筐菜(Cache Line)全搬回厨房。
第三部分:缓存的核心机制 —— 局部性与映射
我们在讲数组时提到了 Cache Line(缓存行),这里从底层详细解释。
1. 批发进货:Cache Line
内存和缓存交换数据,不是按“字节”交换的,而是按“块”交换的。在现代 x86 CPU 中,这个块的大小通常是 64 字节。
-
场景: 你代码里需要读取地址
0x1000的一个int(4字节)。 -
动作: 内存控制器会把
0x1000到0x103F这一段连续的 64 字节全部读入 L1 缓存。 -
原理: 这就是空间局部性(Spatial Locality)。如果你读了数组的第 0 个元素,你大概率马上要读第 1 个。
2. 缓存关联性 (Associativity) —— 东西该放哪?
这是硬件设计中最复杂的地方。 如果你把冰箱(内存)里的东西搬到案板(缓存)上,你应该放在案板的哪个位置?
如果随便放(全关联),找的时候就要把案板翻个底朝天,太慢。 如果只能放固定位置(直接映射),那容易发生冲突。
现代 CPU 使用的是 N-路组相联 (N-way Set Associative)。 比如 8-way,意思是:内存里的某块地址,可以映射到缓存里特定的 8 个位置中的任意一个。
就像你去图书馆还书,虽然不能随便乱放,但你可以放在“计算机科学”这一架子上的任意空位。这既保证了查找速度,又保证了灵活性。
第四部分:多核危机 —— 缓存一致性 (Cache Coherence)
这是多核编程(并发编程)中最头疼的底层问题。
场景: 你的电脑是 4 核 CPU。
-
变量 A 存在内存里,值为
0。 -
核心 1 把 A 读到自己的 L1 缓存,改成
1。 -
核心 2 也把 A 读到自己的 L1 缓存。
问题来了: 核心 2 读到的 A 是多少? 如果不做处理,核心 2 读内存里的 A,还是 0。 这就乱套了!核心 1 改了数据,核心 2 竟然不知道?
解决方案:MESI 协议(总线嗅探)
硬件工程师设计了一套极其复杂的广播协议。
-
Snooping(嗅探): 每个 CPU 核心虽然在干自己的活,但它们的一只耳朵时刻监听着总线(Bus)。
-
M (Modified): 核心 1 说:“变量 A 现在归我管,我改了它!它是脏(Dirty)的。”
-
I (Invalid): 核心 2 听到后,立刻把自己 L1 缓存里的 A 标记为“作废”。
-
后续: 如果核心 2 想要读 A,它发现自己的是废的,就会强制要求核心 1 把最新的值写回内存(或者直接传给核心 2),然后才能读取。
代价: 这种即使沟通(锁竞争)非常消耗性能。这就是为什么在多线程编程中,如果多个线程频繁修改同一个变量(如 volatile 变量),速度会变得极慢——因为 CPU 都在忙着在总线上吵架,同步缓存状态。
虚拟内存:
你可能遇到过这种情况:你的电脑只有 16GB 内存,但你同时开了 50 个 Chrome 标签页、一个 Photoshop、还在跑着一个吃内存的游戏。加起来可能需要 30GB 甚至更多,但电脑居然没崩,只是变慢了。
这是因为操作系统的 虚拟内存 (Virtual Memory)。
第一部分:每个程序都活在“楚门的世界”
在没有虚拟内存的远古时代(DOS 时代),程序是直接操作物理内存的。
-
程序 A 说:“我要用第 1000 号地址。”
-
程序 B 也说:“我也要用第 1000 号地址。”
-
结果: 冲突、崩溃、死机。
为了解决这个问题,现代操作系统给每个程序发了一副“VR 眼镜”。
独占的幻觉: 当你启动一个程序(比如微信)时,操作系统会对它说:“看!这 0x0000 到 0xFFFFFFFF 的 4GB 内存全是你一个人的!哪怕你电脑其实只有 2GB 物理内存。” 微信信以为真,开心地在它认为的 0x1000 地址写数据。
虚拟地址 vs. 物理地址:
-
微信看到的
0x1000是 虚拟地址 (Virtual Address)。 -
这个地址在真实的物理内存条上,可能根本不存在,或者对应的是
0x9999,甚至是硬盘上的一个角落。
第二部分:幕后翻译官 —— MMU 与页表
既然程序用的是假地址,那 CPU 怎么把数据真正存进物理内存呢? 这需要硬件 MMU (Memory Management Unit,内存管理单元) 和软件 页表 (Page Table) 的配合。
1. 分页 (Paging) —— 内存切块
操作系统不会按字节管理内存(太累),而是把内存切成一块一块的,每块通常是 4KB,叫做 一页 (Page)。
2. 页表 (Page Table) —— 寻宝地图
每个程序都有自己的一张私密地图(页表)。这张表记录了虚拟页号到物理页框号的映射关系。
-
微信的地图:
-
虚拟第 1 页 在物理第 500 页。
-
虚拟第 2 页 在物理第 80 页。
-
虚拟第 3 页 空白,在硬盘上。
-
3. 翻译过程
当微信指令说:“读取虚拟地址 0x1005”时:
-
CPU 截获这个指令,把
0x1005扔给 MMU。 -
MMU 查阅微信的页表。
-
MMU 发现虚拟第 1 页对应物理第 500 页。
-
MMU 计算出真实的物理地址(比如
0x500005)。 -
CPU 去物理地址
0x500005读取数据。
整个过程对程序完全透明,程序根本不知道自己被“重定向”了
第三部分:缺页中断 (Page Fault) —— 当内存不够用时
现在回答你的问题:为什么 16GB 内存能跑 30GB 的程序? 因为 硬盘(SSD/HDD) 被强行拉来充当了“慢速内存”。这就是我们常说的 Swap(交换分区) 或 虚拟内存文件。
剧本是这样的:
-
程序贪婪: 微信申请了 1GB 内存,Photoshop 申请了 10GB。物理内存快满了。
-
操作系统拆东墙补西墙: 它发现微信已经最小化了,半天没动静。于是,它悄悄把微信在物理内存里的数据(比如 500MB),搬运(Swap Out) 到硬盘上的一个文件里。 然后在页表里标记:“微信的这些页现在不在内存里,而在硬盘上。” 腾出来的物理内存,立刻分给 Photoshop 用。
-
露馅时刻(缺页中断): 突然,你点开了最小化的微信。
-
微信发出指令:“读取我的数据!”
-
MMU 一查页表,脸色大变:“糟糕!这页数据现在的状态是 Present bit = 0(不在内存中)。”
-
MMU 立刻报错,触发 缺页中断 (Page Fault)。
-
-
亡羊补牢:
-
CPU 暂停执行微信,把控制权交给操作系统内核。
-
内核的中断处理程序说:“别慌,数据在硬盘上。”
-
内核从物理内存里找个倒霉蛋(比如刚刚不活跃的 Photoshop),把它踢到硬盘上去(Swap Out)。
-
然后把微信的数据从硬盘 读回(Swap In) 物理内存。
-
更新页表,告诉 MMU:“数据回来了。”
-
CPU 恢复微信的运行,重新执行刚才那条读取指令。
-
用户体验: 你会感觉点开微信的一瞬间,电脑卡顿了一下,硬盘灯狂闪。那几秒的卡顿,就是操作系统在疯狂地从硬盘倒腾数据回内存。
第四部分:虚拟内存的真正意义
除了“让小内存跑大程序”,虚拟内存还有更重要的安全意义。
内存隔离 (Memory Isolation):
-
每个程序都有独立的页表。
-
程序 A 的页表里,根本就没有程序 B 的物理地址。
-
所以,程序 A 就算有通天的本事,想通过指针越界去读程序 B 的密码,也是不可能的。因为在它的世界里,那个地址根本解析不通(会触发 Segmentation Fault)。
这就是为什么现在的软件崩溃通常只是“这个程序无响应”,而不会像 90 年代那样直接导致整个 Windows 蓝屏(那是因为当时没有完善的内存隔离,一个程序写坏内存,操作系统也跟着挂了)。

















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









