




生成对抗网路(GAN, Generative Adversarial Network)的出现,不仅仅是机器学习领域的一项技术突破,更像是一场创造力革命。它从根本上改变了我们对机器创造能力的认知,为人工智能、计算机视觉、艺术创作乃至科学研究带来了颠覆性的影响。
序章:举例GAN到底干了啥
在进入深入讲解前,我先举个例子,描述一下GAN到底干了什么
现在我们需要一个AI画家,让他画出我们描述的图案,但是一开始这个AI画家并不会画画,画出来的都是歪瓜裂枣的东东。
所以呢,我们训练了一个AI鉴定师,鉴定画家的画,到底画的像不像,和我们要求的符合不符合。
方法就是:我们就给AI鉴定师看了很多我们要的真实图案,于是乎,AI鉴定师就知道了我们需要的图案到底长啥样,有什么特征,这个时候再去看AI画家画的图案,他就可以给出他的评判,画的不像就是分数很低,画的像就分数高,最终这个画家在多次循环后,终于就学会了画这个图案。
以上就是一个生动的例子比喻了GAN到底干了啥工作,就是训练一个可以根据要求生成我们需要的图案的AI画家。
GAN有什么用?
这种能力非常强大,可以应用在很多领域:
图像生成:生成不存在但非常逼真的人脸、风景、艺术品等。
图像修复:自动“脑补”图片中缺失或损坏的部分。
风格迁移:把一张照片变成梵高风格的油画。
超分辨率:将低分辨率的模糊图片变得清晰。
数据增强:在数据量不足时,生成新的训练数据来帮助训练其他模型。
希望这个比喻能帮助大家理解GAN的到底干了啥!
第一章:GAN的网络结构
在之前的比喻中,“画家”和“鉴定师”是抽象的。在实践中,它们都是神经网络。
1.生成器 (Generator, G)
输入:一个随机的噪声,通常就是一个标准正态分布的信号采样而来,这个向量所在的N维空间被称为潜在空间 (Latent Space)。这个随机噪声是创造力的来源,不同的噪声向量会生成不同的图像。这个向量通常就是一维的,比如100维,就是在一个正态分布里面随机采集100个数字。
网络结构:通常是一个反卷积网络 (Deconvolutional Network) 或称为转置卷积网络 (Transposed Convolutional Network)。你可以把它想象成一个标准卷积神经网络(CNN)的逆过程。CNN用于图像分类时,是将一张大图通过卷积层、池化层,逐渐浓缩成一个小的特征向量;而生成器则是将一个小的噪声向量,通过反卷积/上采样层,一步步“放大”和“细化”,最终生成一张指定尺寸的图像。
输出 (Output):一张“假”的图像(或其他数据)。
输入:噪声向量 z (e.g., 100维)
↓
全连接层 (Dense/Linear) :将z拉长成更大的一维特征(如8192维)
↓
Reshape:将一维向量重塑成一个特征图 (e.g., 512个特征图, 4x4尺寸 -> [B, 512, 4, 4])
↓
转置卷积层 (ConvTranspose2d) + BatchNorm + ReLU:
↑ 逐步扩大特征图尺寸
↑ 逐步减少特征图通道数(最终目标:3通道 - RGB)
↓
最后的转置卷积层:输出目标尺寸 (e.g., [B, 3, 64, 64])
↓
激活函数:Tanh (将像素值归一化到[-1, 1])
➡ 输出:生成图像
2.判别器 (Discriminator, D)
输入 (Input):一张图像(真实的或生成器生成的)。
网络结构:一个标准的卷积神经网络 (CNN),就像用于图像分类任务的网络一样。它通过卷积层提取图像特征。
输出 (Output):一个单一的标量值,通常在0到1之间。这个值代表了判别器认为输入图像是“真实”的概率。
1 代表 “绝对是真图片”。
0 代表 “绝对是假图片”。
输入:真实图像/生成图像 (B, 3, 64, 64)
↓
卷积层 (Conv2d) + LeakyReLU:空间尺寸减半,通道数加倍 (e.g., 64 → 32)
↓
重复堆叠:卷积 + BatchNorm + LeakyReLU (每次尺寸减半,通道加倍)
↓
展平层 (Flatten):将特征图拉成一维向量
↓
全连接层 (Dense/Linear) :输出单个标量
↓
激活函数:Sigmoid (输出概率值 ∈ [0,1])
➡ 输出:真/假概率 (或 WGAN-GP 中的评分)
(B, 3, 64, 64)
→ Conv2d(k=4, s=2, p=1) + LeakyReLU ➡ (B, 64, 32, 32)
→ Conv2d(k=4, s=2, p=1) + BN + LeakyReLU ➡ (B, 128, 16, 16)
→ Conv2d(k=4, s=2, p=1) + BN + LeakyReLU ➡ (B, 256, 8, 8)
→ Conv2d(k=4, s=2, p=1) + BN + LeakyReLU ➡ (B, 512, 4, 4)
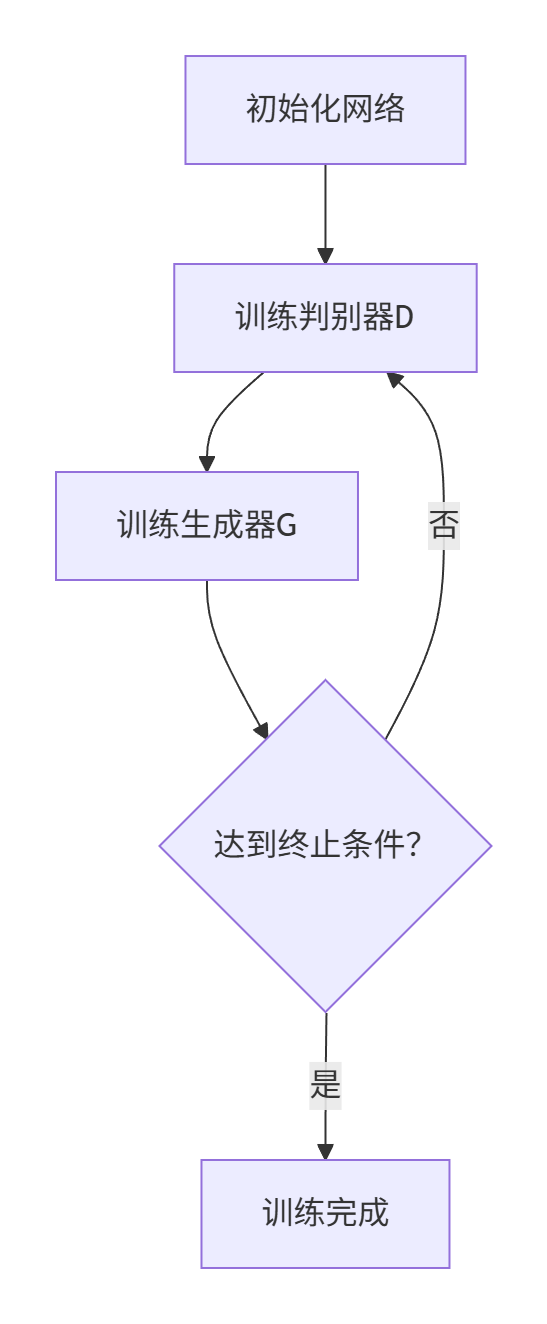
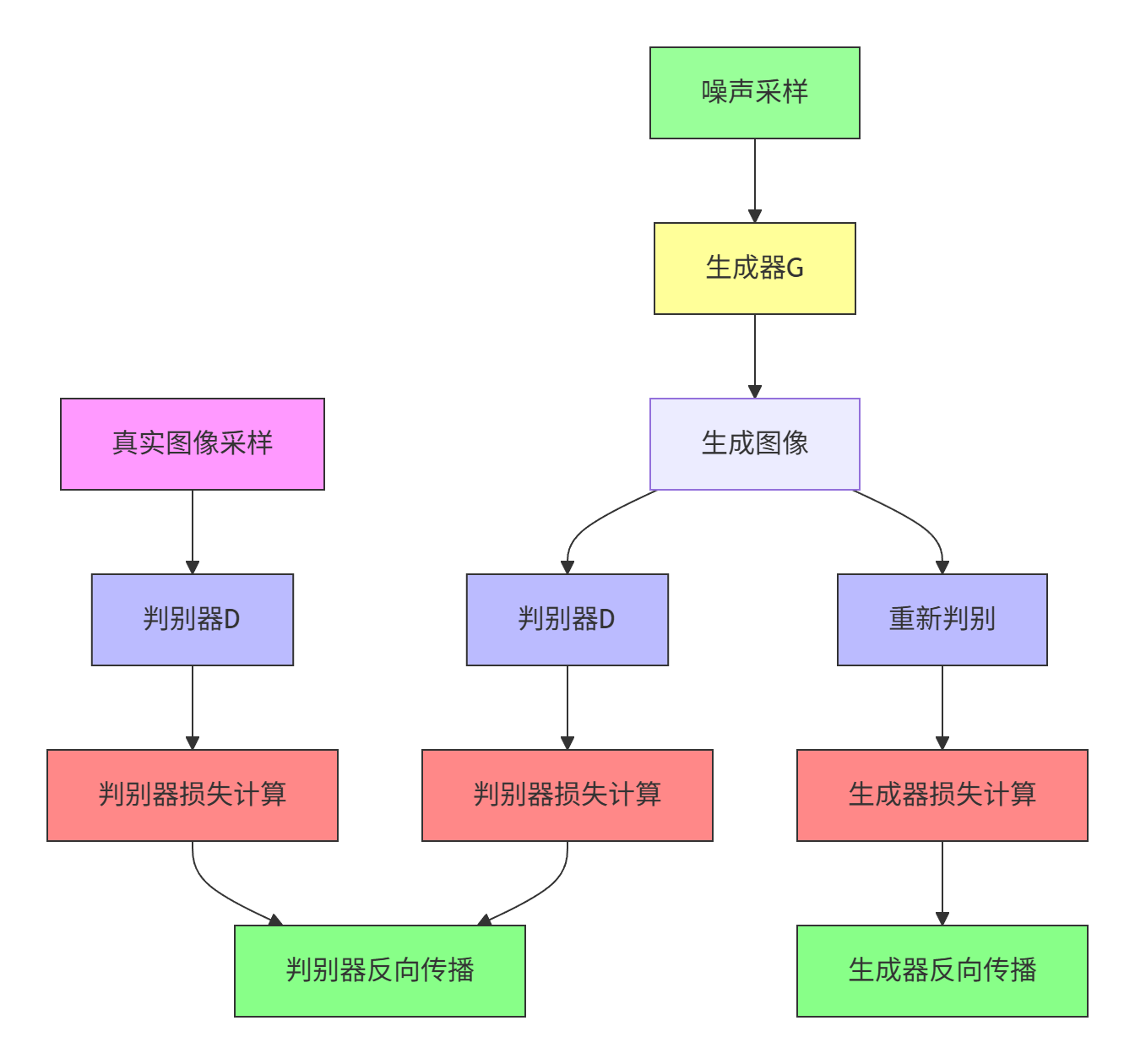
3.详细训练过程
GAN的训练是一个精妙的交替优化过程。在一个训练迭代(epoch)中,我们会分别训练判别器和生成器。并且在训练一方时,另一方的参数是冻结的。
第一步:训练判别器 D
目标: 最大化D判别真假的能力。
【1】取一批真实数据 (例如,m 张真实的猫的图片),将它们输入判别器D。因为它们是真实的,我们希望D的输出尽可能接近 1。计算这批数据的损失(例如,与标签1的交叉熵损失)。
【2】让生成器G 从随机噪声生成一批假数据(m 张假猫图片)。
【3】将这批假数据 输入判别器D。因为它们是假的,我们希望D的输出尽可能接近 0。计算这批数据的损失(例如,与标签0的交叉熵损失)。
【4】将上述两个损失相加,得到判别器的总损失。
【5】根据这个总损失,使用反向传播算法来更新只属于判别器D的权重。在此过程中,生成器G的权重保持不变。
第二步:训练生成器G
目标: 生成能通过判别器D检验的图片。
【1】让生成器G 再次从随机噪声生成一批新的假数据(m 张假猫图片)。
【2】将这批假数据输入判别器D(此时D的权重是冻结的,我们只用它来提供“反馈”)。
【3】生成器G的目标是让判别器D相信这些假图片是真的。也就是说,G希望D对这些假图片的输出尽可能接近 1。
【4】计算生成器G的损失:即判别器D的输出与目标值 1 之间的差距。
【5】这个损失信号会通过判别器D反向传播(但不会更新D的权重),最终传递回生成器G,并用于更新只属于生成器G的权重。
4.数学原理详解:Minimax Game (最小最大博弈)
理想很丰满,但GAN的训练是出了名的困难和不稳定。
所以我们先从数学原理讲起吧
原始GAN论文将这个过程描述为一个二人零和的最小最大博弈。其目标函数如下:
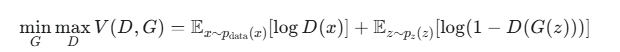
公式很复杂,但是让我们来一步步拆解:
我们把这个公式分成两个主要部分来看,分别对应判别器(D)在两种不同输入(真/假)下的表现。
第一部分:处理真实数据
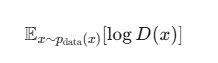
![]() :这表示“对于所有从真实数据分布(pdata)中抽取的样本 x ,求其数学期望”。通俗地说,就是拿一批真实的图片来计算平均结果。
:这表示“对于所有从真实数据分布(pdata)中抽取的样本 x ,求其数学期望”。通俗地说,就是拿一批真实的图片来计算平均结果。
D(x):判别器D看到真实图片 x 后,给出的一个概率值,表示它认为这张图片是“真实”的可能性有多大。
logD(x):对这个概率值取对数。
判别器(D)的目标:对于真实图片 x,D 的目标是让 D(x) 尽可能地接近 1。当 D(x) 趋近于 1 时,logD(x) 趋近于 log(1)=0,这是该项能取到的最大值。
第二部分:处理虚假数据
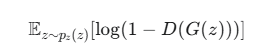
![]() :这表示“对于所有从一个随机噪声分布(pz)中抽取的向量 z,求其数学期望”。通俗地说,就是生成一批假的图片来计算平均结果。
:这表示“对于所有从一个随机噪声分布(pz)中抽取的向量 z,求其数学期望”。通俗地说,就是生成一批假的图片来计算平均结果。
G(z):生成器G接收一个随机噪声 z 后,生成的“假图片”。
D(G(z)):判别器D看到这张假图片 G(z) 后,给出的一个概率值,表示它认为这张假图片是“真实”的可能性。
1−D(G(z)):这代表判别器认为这张假图片是“虚假”的概率。
log(1−D(G(z))):对这个“虚假”的概率值取对数。
判别器(D)的目标:对于假图片 G(z),D 的目标是让 D(G(z)) 尽可能地接近 0(即正确识别出它是假的)。当 D(G(z)) 趋近于 0 时,1−D(G(z)) 就会趋近于 1,那么 log(1−D(G(z))) 就会趋近于 log(1)=0,这也是该项能取到的最大值。
整合理解:min 与 max 的对抗
现在我们把两个角色放进整个公式里:
![]()
max D(最大化判别器的收益): 判别器 D 的目标是让整个表达式 V(D,G) 的值最大化。如上所述,它会通过努力让 D(x)→1 和 D(G(z))→0 来实现这一目标。这完美地对应了判别器的任务:精准地分辨真实与虚假。
min G(最小化生成器的收益): 生成器 G 的目标与 D 完全相反,它要让整个表达式 V(D,G) 的值最小化。
1.G 无法影响第一项,因为那只和真实数据有关。
2.G 只能通过改变自己生成的图片 G(z) 来影响第二项。为了让整个表达式变小,G 必须让第二项 log(1−D(G(z))) 的值变得非常小(一个绝对值很大的负数)。
如何实现:G 会努力让 D(G(z)) 趋近于 1。因为如果 D(G(z))→1,那么 1−D(G(z))→0,而 log(0) 的值会趋近于负无穷大。
让 D(G(z))→1 的含义正是:生成器 G 成功地骗过了判别器 D,让 D 认为它的图案是“真”的。
既然已经知道了GAN损失函数的数学原理,这次我们来讲解一下,为什么GAN的训练如此困难且不稳定,以及现在的解决办法
我们之前提到原始GAN训练非常不稳定,经常不收敛,而且容易模式坍塌。深层原因在于它所使用的损失函数。从数学上讲,原始GAN的损失函数是在衡量真实数据分布和生成数据分布之间的 JS散度 (Jensen-Shannon divergence)。
JS散度有一个致命缺陷:当两个分布几乎没有重叠时(这在训练初期非常常见),相当于就是我们的噪声图像和真实图像,完全没有一点类似时。
JS散度会变成一个常数,其梯度会变为0。梯度为0,意味着生成器接收不到任何有效的反馈信号,不知道该如何优化自己,这就是“梯度消失”。这导致训练无法继续,或者生成器随便找个方向“蒙混过关”(模式坍塌)。
革命性解决方案:Wasserstein GAN(WGAN)
2017年Arjovsky提出的WGAN从根本上解决了JS散度问题:
WGAN提出用 Wasserstein-1距离 (也称作推土机距离, Earth-Mover's Distance) 来替代JS散度。
形象理解:想象有两个沙堆(两个数据分布),推土机距离就是把一堆沙子变成另一堆沙子的形状所需最小的“运输成本”(成本 = 沙子量 × 运输距离)。
优点:与JS散度不同,即使两个分布完全没有重叠,Wasserstein距离依然能提供一个平滑、有意义的距离度量,从而能够持续为生成器提供有效的梯度。
WGAN在实践中的改动
为了实现Wasserstein距离,WGAN对网络做了几个关键改动:
1.判别器变“评论家”(Critic):判别器最后一层去掉Sigmoid激活函数。它不再输出一个0到1的“概率”,而是输出一个可以任意取值的分数。这个分数越高,代表数据越“真实”。因此,它不再是简单的真假判别器,而是一个衡量真实程度的“评论家”。
2.新的损失函数:损失函数变得非常简单。
评论家(D)的损失:![]() 希望假数据的分数低,真数据的分数高,所以要最小化这个值
希望假数据的分数低,真数据的分数高,所以要最小化这个值
生成器(G)的损失:![]() (希望自己生成的假数据的分数越高越好)
(希望自己生成的假数据的分数越高越好)
3.权重裁剪 (Weight Clipping):为了满足Wasserstein距离的数学约束(1-Lipschitz约束),WGAN论文提出一个简单粗暴的方法:在每次更新评论家D的权重后,强制将权重裁剪到一个很小的范围内(例如[-0.01, 0.01])。
WGAN的意义:它极大地提升了GAN的训练稳定性,并从理论上缓解了模式坍塌。最棒的是,评论家的损失值与生成图像的质量有了强相关性,我们可以通过监控损失来判断训练进程,这是原始GAN做不到的。
cGAN (Conditional GAN): 实现“可控”生成
原始GAN是“随机”的,你无法控制它具体生成什么。cGAN解决了这个问题。
非常简单直接:给生成器和判别器都额外增加一个“条件”信息,用y来表示。
生成器 (G):输入不再只是随机噪声z,而是{z, y}。它学习的目标是生成符合条件y的图像。
判别器 (D):输入也不再只是图像x,而是{x, y}。它的任务是判断图像x是否真实,并且是否与条件y相匹配。
例如,如果我们用手写数字数据集MNIST训练cGAN,y可以是数字的标签(0, 1, 2, ...)。训练完成后,我们可以给G输入{某个噪声, 标签7},它就会专门生成数字“7”的图像。
cGAN是所有“可控”生成任务的基石。
第二章:pytorch实例逐行讲解实现
目标: 训练一个GAN来生成以假乱真的手写数字“8”。
我们的模块:
生成器 (G):一个神经网络,他什么都不会,输入是一串随机数(比如100个随机数),输出是一张 28x28 像素的灰度图。
判别器 (D):另一个神经网络,他能接收一张 28x28 的图像,并输出一个0到1之间的分数,代表“这张图有多真”。
真实数据:我们有一大堆真实的手写数字“8”的图片(来自MNIST数据集)。
序言:准备工作
以下代码是训练前的准备工作:
1.导入必要的库
2.设置用GPU训练
3.生成一个目录保存我们的生成图像
4.设置训练参数
这些比较简单,所以我就不展开讲解了,后面的代码我会详细讲解。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os
# 1. 设置超参数和设备
# ==================================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"正在使用的设备: {device}")
# 创建一个目录来保存生成的图像
if not os.path.exists("gan_images"):
os.makedirs("gan_images")
latent_dim = 100 # 随机噪声向量的维度 (z)
image_size = 28 * 28 # 图像大小 (784)
batch_size = 128
num_epochs = 50
lr = 0.0002
然后我们进行数据下载与预处理:
# 2. 准备数据 (MNIST数据集)
# ==================================
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图片转换为Tensor, 并归一化到[0, 1]
transforms.Normalize((0.5,), (0.5,)) # 将数据从[0, 1]归一化到[-1, 1]
])
# 下载并加载训练数据
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
data_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
第一章:先定义判别器D与生成器G
判别器:
# "鉴定师" - 判别器 (Discriminator)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(image_size, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1) # 输出一个分数(logit),而不是概率
# 注意:这里最后没有Sigmoid激活函数
)
def forward(self, img):
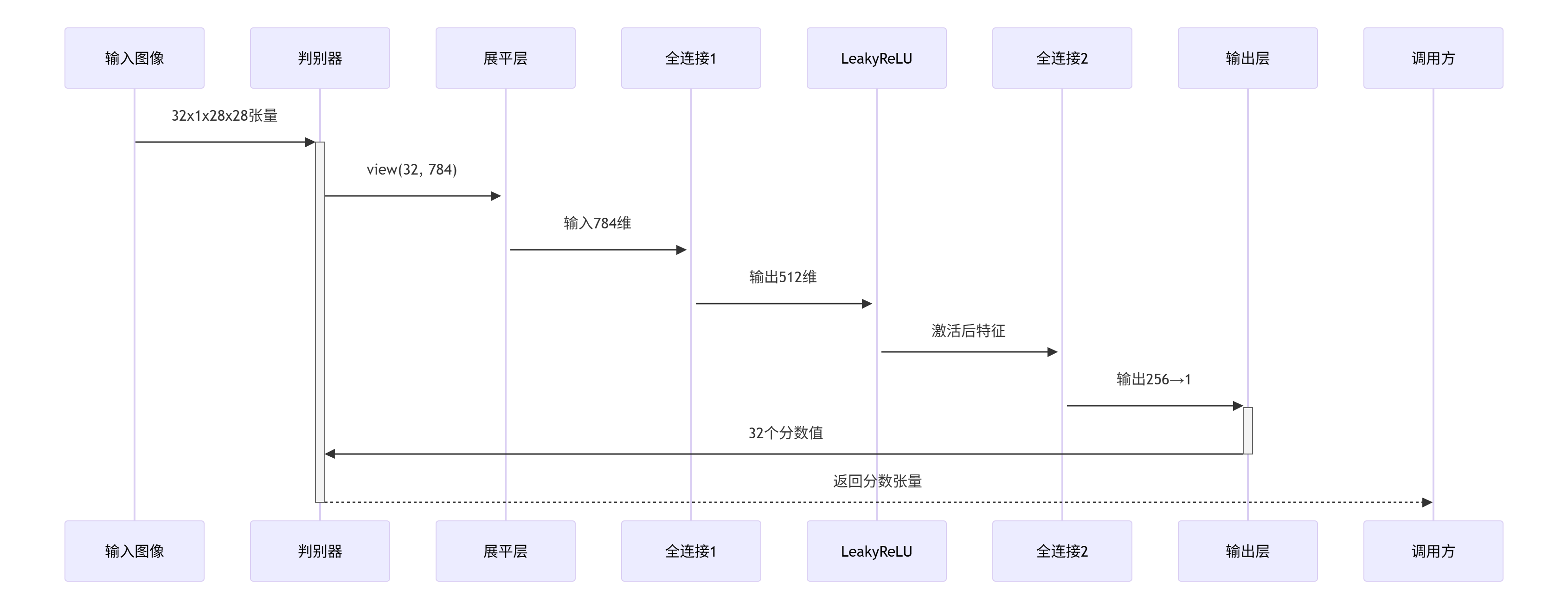
# 将图像扁平化成一维向量
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
1. 类定义与继承
nn.Module:所有PyTorch模型的基类,提供参数管理功能
super().__init__():正确初始化父类,必须调用
2.展平操作解析
img_flat = img.view(img.size(0), -1)
输入假设:img形如(batch_size, channels, height, width)
# 假设输入为32张MNIST图像
original_shape = (32, 1, 28, 28) # 批次,通道,高,宽
view_shape = (32, 1 * 28 * 28) = (32, 784) # 保持批次维度
完整工作流程:
生成器:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.LeakyReLU(0.2), # LeakyReLU是一个常用的激活函数,防止梯度消失
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, image_size),
nn.Tanh() # Tanh激活函数将输出压缩到[-1, 1], 匹配我们归一化的数据
)
def forward(self, z):
img = self.model(z)
# 将一维向量变形成图像的形状
img = img.view(img.size(0), 1, 28, 28)
return img
1. 核心功能
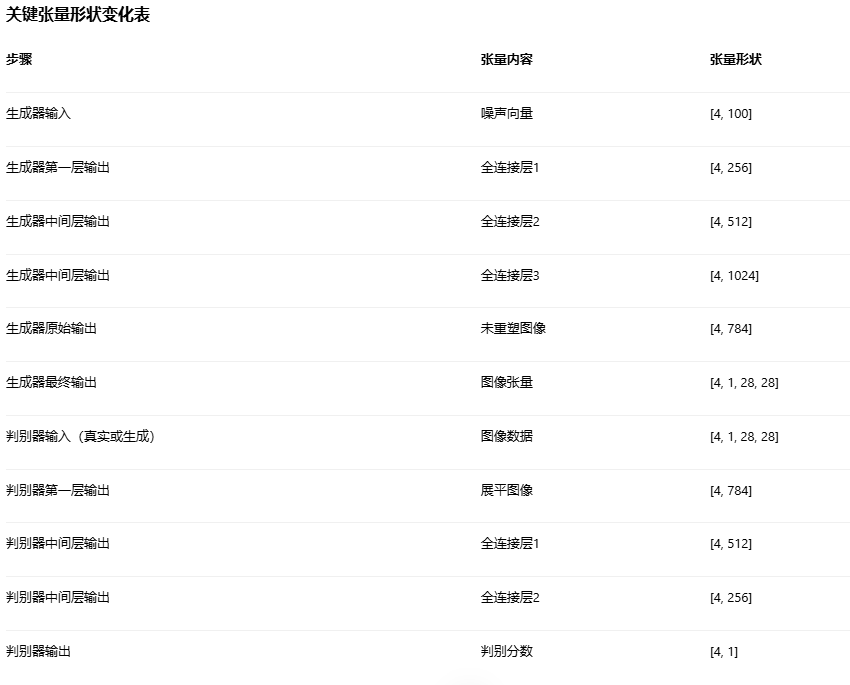
将低维随机噪声(latent_dim维)逐步转换为图像数据(28x28像素)
这种维度扩展是在增加数据的自由度,使生成器能够学习更复杂的特征表示
生成过程的几何解释:

张量变化流程:
第二章:开始训练
初始化
#初始化模型、损失函数和优化器
# ==================================
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 损失函数: BCEWithLogitsLoss 包含了Sigmoid和BCELoss, 数值上更稳定
criterion = nn.BCEWithLogitsLoss()
# 优化器: Adam是一种高效的优化算法
g_optimizer = optim.Adam(generator.parameters(), lr=lr)
d_optimizer = optim.Adam(discriminator.parameters(), lr=lr)
# 创建一个固定的噪声向量,用于在训练过程中可视化生成器的进步
fixed_noise = torch.randn(64, latent_dim).to(device)
generator = Generator().to(device)
1.
discriminator = Discriminator().to(device)
作用: 创建一个生成器 (Generator) 神经网络实例,并将其移动到指定的计算设备 (GPU或CPU)。生成器是GAN的核心组件之一,其职责是将随机噪声转化(生成)为逼真的假数据(如图片)。
创建一个判别器 (Discriminator) 神经网络实例,并将其移动到指定的计算设备。判别器是GAN的另一个核心组件,其职责是区分数据是真实的(来自训练集)还是生成的(来自生成器)。
2.
criterion = nn.BCEWithLogitsLoss()
作用: 定义一个特定的损失函数来计算判别器预测值(logits)与真实标签(real=1, fake=0)之间的差异。这个损失将指导生成器和判别器的参数更新。
BCEWithLogitsLoss = Sigmoid + BCELoss: 该损失函数将二元交叉熵损失 (BCELoss) 和一个内置的 Sigmoid激活层 组合。这意味着它直接在模型的原始输出(logits) 上工作,无需在模型最后显式添加 Sigmoid()。
3.
g_optimizer = optim.Adam(generator.parameters(), lr=lr)
作用: 创建一个使用 Adam 算法的优化器,用于更新生成器的参数以最小化其损失 (loss_g),使其能生成更逼真的假数据来“欺骗”判别器。
使用方式:
1.调用 optim.Adam()创建Adam优化器。
2.传入生成器的可学习参数:generator.parameters(),指定学习率 lr。
4.
fixed_noise = torch.randn(64, latent_dim).to(device)
作用: 生成一个固定的随机噪声张量(大小为 [64, latent_dim])并移动到目标设备。用于可视化训练进度。
数据格式处理
total_step = len(data_loader)
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(data_loader):
real_images = real_images.to(device)
# 创建真实标签和虚假标签
real_labels = torch.ones(real_images.size(0), 0.9).to(device)
fake_labels = torch.zeros(real_images.size(0), 0.1).to(device)
1.
total_step = len(data_loader)
作用:计算当前数据集一个epoch包含的总训练步数(批次数)
2.
for i, (real_images, _) in enumerate(data_loader):
作用:按批次迭代数据集,每次处理一小部分样本
语法:
enumerate同时获取索引i和批次数据
(real_images, _):元组解包,忽略标签(GAN不需要类别标签)
data_loader自动处理洗牌(shuffle)和分批(batching)
3.
# 创建真实标签和虚假标签
real_labels = torch.ones(real_images.size(0), 1).to(device)
fake_labels = torch.zeros(real_images.size(0), 1).to(device)
作用:生成与当前批次大小匹配的真/假标签矩阵
原因:
为判别器提供监督信号:真实图像应标记为1(真)生成图像应标记为0(假)
BCELoss要求标签与输出形状一致
语法:
real_images.size(0)获取当前批次样本数
torch.ones/zeros创建全1/全0矩阵
形状为(batch_size, 1)匹配判别器输出
.to(device)确保标签与数据在同一设备
[[1.],
[1.],
[1.],
... (总共128行)
[1.]]
开始训练
├─ 计算总步数(用于进度显示)
├─ 外层循环:遍历所有epoch
│ ├─ 内层循环:遍历所有批次
│ │ ├─ 获取真实图像批次 → 移到设备
│ │ ├─ 创建全1标签(真)→ 移到设备
│ │ └─ 创建全0标签(假)→ 移到设备
│ └─ (后续将在此处理判别器和生成器训练)
└─ 完成所有epoch后结束
训练判别器
# 1. 计算真实图像的损失
d_outputs_real = discriminator(real_images)
d_loss_real = criterion(d_outputs_real, real_labels)
# 2. 计算虚假图像的损失
z = torch.randn(real_images.size(0), latent_dim).to(device)
fake_images = generator(z)
# 使用.detach()来切断梯度流,因为我们只想更新判别器
d_outputs_fake = discriminator(fake_images.detach())
d_loss_fake = criterion(d_outputs_fake, fake_labels)
# 3. 判别器的总损失并更新
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad() # 梯度清零
d_loss.backward() # 反向传播
d_optimizer.step() # 更新权重
1.
d_outputs_real = discriminator(real_images)
d_loss_real = criterion(d_outputs_real, real_labels)
作用:
将真实图像输入判别器获得预测值(logits)
计算判别器对真实图像的判断损失
输出形式:每个样本一个输出值(batch_size × 1)
2.
# 2. 计算虚假图像的损失
z = torch.randn(real_images.size(0), latent_dim).to(device)
fake_images = generator(z)
作用:
生成随机噪声向量作为生成器输入
生成器产生与真实图像同批次的假图像
3.
# 使用.detach()来切断梯度流
d_outputs_fake = discriminator(fake_images.detach())
d_loss_fake = criterion(d_outputs_fake, fake_labels)
作用:
计算判别器对假图像的判断损失
通过.detach()隔离计算图,防止梯度影响生成器
原因:
梯度隔离必要性:此时只更新判别器,需阻止生成器从此次判别中获益
训练不平衡问题:判别器通常易学,先单独优化可避免压倒性优势
预期标签是fake_labels=0(假图像应判为0)
 训练生成器:
训练生成器:
# 生成一批新的假图像
z = torch.randn(real_images.size(0), latent_dim).to(device)
fake_images = generator(z)
# 计算生成器的损失
# 我们希望生成器生成的图像能够被判别器认为是"真实"的(标签为1)
g_outputs = discriminator(fake_images)
g_loss = criterion(g_outputs, real_labels) # 注意这里用的是real_labels
# 更新生成器
g_optimizer.zero_grad() # 梯度清零
g_loss.backward() # 反向传播
g_optimizer.step() # 更新权重

输出结果:
if (i+1) % 200 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], '
f'D Loss: {d_loss.item():.4f}, G Loss: {g_loss.item():.4f}')
# 每个epoch结束后,保存一张由固定噪声生成的图像,以观察效果
with torch.no_grad():
# 生成图像并取消归一化(从[-1, 1] -> [0, 1])
sample_images = generator(fixed_noise).cpu() * 0.5 + 0.5
torchvision.utils.save_image(sample_images, f'gan_images/epoch_{epoch+1}.png')
print("训练完成!")
1.
# 每个epoch结束后,保存一张由固定噪声生成的图像,以观察效果
with torch.no_grad():
# 生成图像并取消归一化(从[-1, 1] -> [0, 1])
sample_images = generator(fixed_noise).cpu() * 0.5 + 0.5
torchvision.utils.save_image(sample_images, f'gan_images/epoch_{epoch+1}.png')
with torch.no_grad()::禁用梯度计算,节省内存加速推理
.cpu():将GPU张量移至CPU内存(torchvision.save_image要求)
*0.5 + 0.5:将[-1,1]范围映射到[0,1]范围的线性变换
torchvision.utils.save_image():自动拼接并保存图像
反向归一化的数学原理:
原始输入:通常被归一化到[-1,1]
生成器输出:tanh激活 → [-1,1]
图像保存要求:像素值需在[0,1]
代码就到这结束了,不过由于GAN的训练包含太多未知与困难,大家肯定在代码跑完后效果依旧不理想,接下来我会出一章关于优化GAN的文章,帮助大家从0开始生成自己想要的图

















 3609
3609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









