




今天我们的主题是计算机视觉领域一个非常重要的自监督学习模型:Masked Autoencoder (MAE),中文通常翻译为 掩码自编码器。它由来自 Facebook AI Research (FAIR) 的何恺明等大神提出,其设计思想,在当时乃至现在都对整个领域产生了深远的影响。
1. 核心思想:根据已有图像补出缺少图像
想象一下,我给你一幅画,但随机抠掉了其中 75% 的小方块,只留下 25% 的零散碎片。然后,我要求你根据这些零散的碎片,把整幅画恢复原状。就像现在比较火的AI扩图,我们如何让AI去理解图片,扩大图片?
这个任务非常困难,要完成它,你不能只关注单个碎片的颜色和纹理,而必须理解这幅画的整体结构、物体关系、光影变化和风格。比如,你看到一小块蓝天和一小块白云,就能推断出它们周围可能也是天空;你看到一只猫的耳朵,就能大致推断出头部的轮廓和眼睛的位置
MAE 的核心思想就是让计算机来做这个高难度的扩图任务。
通过强迫模型根据极少量的、随机的可见部分(Visible Patches)来重建大量的、被遮盖的部分(Masked Patches),模型被迫去学习图像的深层语义信息和高级结构知识,而不仅仅是表面的纹理。这种“从部分推断整体”的能力,就是一种非常强大的表征学习(Representation Learning)。
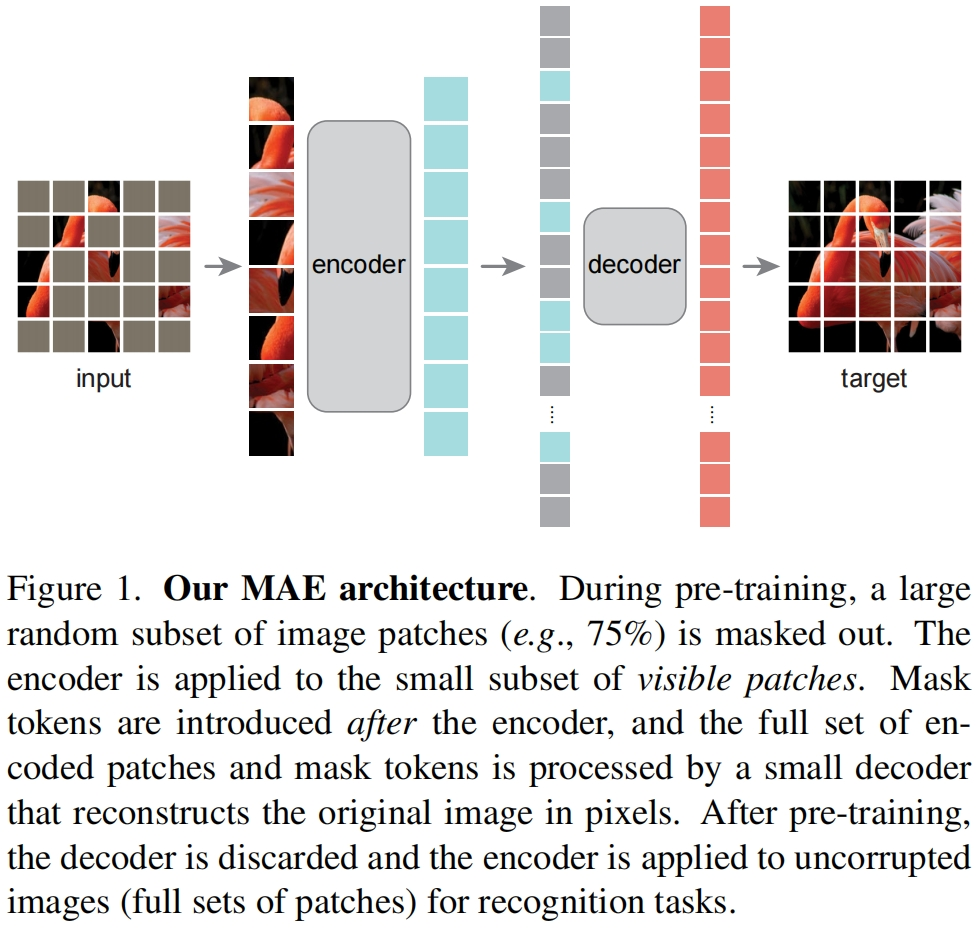
2. 架构详解:巧妙的非对称设计
MAE 的成功很大程度上归功于其独特的 非对称(Asymmetric)Encoder-Decoder 架构。这与传统的自编码器有很大不同。
我们来拆解一下它的结构:
a. 图像分块与随机掩码 (Patching & Masking)
1.分块 (Patching): 首先,和 Vision Transformer (ViT) 一样,输入图像被分割成一系列不重叠的小图像块(Patches),例如 16x16 像素的方块。每个 Patch 被展平成一个向量。
2.掩码 (Masking): 接下来,进行非常激进的随机掩码。高达 75% 的图像块被遮盖,只有 25% 的图像块被保留下来送入编码器。这是 MAE 的关键之一。
b. 编码器 (Encoder)
输入: 编码器的输入仅仅是那 25% 的可见图像块。这是“非对称”设计的核心!
结构: 编码器通常是一个标准的 Vision Transformer (ViT)。
任务: 负责处理这些零散的、无序的可见块,并将它们编码成包含丰富语义信息的特征向量(Latent Representation)。
位置编码 (Positional Embeddings): 因为输入的块是无序的,我们需要告诉模型每个块来自原图的哪个位置。因此,每个可见块在输入编码器前,都会加上其对应的“位置编码”。
由于编码器只处理了 25% 的数据,其计算量和内存消耗相比于处理整张图的模型大大降低(大约减少了 3-4 倍)。这使得 MAE 的预训练过程非常高效。
c. 解码器 (Decoder)
输入: 解码器的输入包含两部分:
1.经过编码器处理后的可见块的特征向量。
2.一系列特殊的 掩码标记” (Mask Tokens),它们作为占位符,代表那些被遮盖掉的图像块。
同样,所有这些输入(可见块特征 + 掩码标记)都会被赋予它们在原始图像中的位置编码,
这样解码器就知道该在哪个位置重建图像。
结构: 解码器通常也是一个 Transformer 结构,但远比编码器要轻量级(更浅、更窄)。这是“非对称”的又一体现。
任务: 解码器的任务相对简单,它利用可见块的深层语义信息,来推断并重建出所有被遮盖块的原始像素值。
d. 重建目标与损失函数 (Reconstruction Target & Loss)
目标: 解码器输出被遮盖块的预测像素值。
损失函数: 计算模型预测的像素值与原始图像中被遮盖块的真实像素值之间的差异。通常使用均方误差 (Mean Squared Error, MSE)。
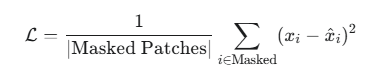
其中 x_i 是真实像素值,hat-x_i 是预测像素值。
3. 工作流程:预训练与微调
MAE 的应用遵循一个经典的两阶段范式:
阶段一:自监督预训练 (Self-Supervised Pre-training)
数据: 使用海量的、无标签的图像数据(例如 ImageNet 的全部图片,但不需要它们的类别标签)。
过程:
1.对一张图片进行分块和高比例掩码。
2.将可见块送入 Encoder。
3.将 Encoder 的输出和 Mask Tokens 送入 Decoder。
4.Decoder 重建被掩码的像素。
5.计算损失,并通过反向传播更新 Encoder 和 Decoder 的权重。
产物: 经过在亿万张无标签图片上的训练后,我们得到了一个强大的 Encoder。这个 Encoder 已经学会了如何从零散的视觉信息中理解图像的通用结构和语义。
丢弃解码器: 在预训练结束后,我们不再需要这个轻量级的 Decoder,它的使命已经完成。
阶段二:下游任务微调 (Fine-tuning)
准备: 获取预训练好的 Encoder。
改造: 在 Encoder 的末端接上一个针对特定任务的分类头(通常是一个简单的全连接层)。
数据: 使用规模小得多的、有标签的数据集(例如 ImageNet-1k 的分类标签)。
过程:
将完整的、未被掩码的图像输入到 Encoder 中。
将 Encoder 输出的特征喂给分类头,进行预测。
计算分类损失,并用较低的学习率微调整个模型(主要是 Encoder 和新加的分类头)的权重。
由于 Encoder 在预训练阶段已经学到了非常通用的视觉特征,所以在微调阶段,它能以很少的标注数据和训练时间,快速适应新的任务,并达到非常高的性能。
4.实例演示:深入理解
假设我们有以下设定:
输入图片: 一张 224x224 像素的彩色猫咪图片 (尺寸: 224 x 224 x 3)。
Patch 尺寸: 16x16 像素。
Encoder/Decoder 维度:
Encoder 隐藏维度 D_enc = 768
Decoder 隐藏维度 D_dec = 512
掩码比例: 75%
第 1 步: 分块、展平与掩码 (Patching, Flattening & Masking)
1.分块 (Patching):
我们将 224x224 的图片分割成 16x16 的小块。
总共的 Patch 数量 = (224 / 16) x (224 / 16) = 14 x 14 = 196 个 Patch。
2.展平 (Flattening):
每个 16x16x3 的 Patch 被展平成一个向量。
向量维度 = 16 * 16 * 3 = 768。
现在我们得到了一个序列,包含 196 个向量,每个向量的维度是 768。可以表示为 (196, 768) 的张量。
3.随机掩码 (Random Masking):
我们设定了 75% 的掩码比例。
被遮盖 (Masked) 的 Patch 数量 = 196 * 75% = 147 个。
可见 (Visible) 的 Patch 数量 = 196 * 25% = 49 个。
模型会随机生成一个包含 0 到 195 的索引列表,然后随机打乱,取出前 49 个作为可见 Patch 的索引,剩下的 147 个作为被遮盖 Patch 的索引。
数据状态:
可见数据: 49 个 (1, 768) 的向量。
被遮盖数据: 147 个 (1, 768) 的向量 (这部分数据暂时被“丢弃”,只记住它们的位置)。
第 2 步: 编码器 (Encoder) - 理解语义
这是非对称设计的体现。
1.输入准备:
我们将 49 个可见的 Patch 向量 作为输入。
为这 49 个向量分别加上它们原始的位置编码 (Positional Embeddings)。例如,如果第 3、15、28... 号 Patch 是可见的,我们就取出第 3、15、28... 号的位置编码向量,与对应的 Patch 向量相加。位置编码的维度也是 768。
2.数据流动:
输入Encoder的张量维度: (49, 768)。
这个张量流经一个标准的、较深(例如 12 层)的 Transformer Encoder。
在 Encoder 内部,通过多头自注意力机制 (Multi-Head Self-Attention),这 49 个零散的 Patch 互相交互,模型试图从这些碎片中理解图像的整体内容(“哦,这几个色块看起来像猫的眼睛,那另一个可能是鼻子”)。
输出Encoder的张量维度: (49, 768)。这个输出是 49 个可见 Patch 的深度语义表征 (Latent Representation)。
结构与数据流总结:
[Input: 49x768] -> [ViT Encoder (12层, 768维)] -> [Output: 49x768]
第 3 步: 解码器 (Decoder) - 准备重建
1.输入准备:
可见块表征: 从 Encoder 得到的 (49, 768) 的语义表征。
掩码标记 (Mask Tokens): 我们创建 147 个 可学习的共享向量,称为“掩码标记”。它的维度与 Decoder 维度一致,为 (1, 512)。
注意:如果 Encoder 和 Decoder 维度不同 (768 vs 512),通常会有一个线性层将 Encoder 的输出从 768 维降到 512 维。
2.组合完整序列:
a.我们将 49 个可见块的表征和 147 个掩码标记,按照它们在原始图像中的位置,重新排列成一个完整的序列。
b.如果原始序列是 [P1, P2, P3, P4, ...],而 P2 和 P4 被遮盖了,那么输入到 Decoder 的序列就是 [Enc(P1), MaskToken, Enc(P3), MaskToken, ...]。
c.为完整序列添加位置编码: 再次为这 196 个 元素(49个编码过的+147个掩码标记)全部加上它们对应的原始位置编码(维度为 512)。
3.数据流动:
输入Decoder的张量维度: (196, 512)。
这个完整的序列流经一个轻量级的 Transformer Decoder(例如,只有 4 层,512 维)。
Decoder 中的自注意力机制让可见块的信息“扩散”到旁边的掩码标记中,从而预测被遮盖区域的内容。
输出Decoder的张量维度: (196, 512)。
结构与数据流总结:
[Input: 196x512] -> [Lightweight Decoder (4层, 512维)] -> [Output: 196x512]
第 4 步: 重建与计算损失 (Reconstruction & Loss)
像素预测头 (Prediction Head):
1.像素预测头 (Prediction Head):
在 Decoder 之后,接一个简单的全连接层(线性层)。
这个线性层负责将 Decoder 输出的 (196, 512) 的张量,重新映射回像素空间。
输出维度: (196, 768) (因为每个 Patch 的原始像素向量维度是 768)。
2.计算损失 (Loss Calculation):
关键点: 我们只关心被遮盖的部分是否重建得好。
模型从预测出的 (196, 768) 结果中,只取出那 147 个被遮盖位置的预测向量。
同时,我们拿出原始图片中对应的 147 个真实 Patch 向量。
计算这两组 147 个向量之间的均方误差 (MSE)。这个误差就是我们的损失值,用于通过反向传播更新整个模型(Encoder、Decoder、Prediction Head)的参数。
微调阶段 (Fine-tuning)
预训练完成后,我们进行下游任务微调,比如图像分类。
1.丢弃 Decoder: 我们扔掉轻量级的 Decoder 和预测头。它们只是预训练的“脚手架”。
2.保留 Encoder: 我们保留训练好的、强大的 ViT Encoder。
输入完整图片:
1.将整张猫咪图片 (224x224) 输入,不再进行任何掩码。
2.图片同样被分为 196 个 Patch,展平后全部送入 Encoder。
3.输入Encoder的张量维度: (196, 768)。
添加分类头:
在 Encoder 的输出端,通常会取所有 Patch 表征的平均值或只取 [CLS] 标记的表征,得到一个代表整张图的向量 (1, 768)。
将这个向量喂给一个新加的、随机初始化的分类头(一个简单的全连接层,输出维度为类别数,比如 ImageNet 的 1000 类)。
训练:
使用带标签的数据(如 "猫"),计算分类损失。用较小的学习率,微调 Encoder 和新分类头的参数。
题外话:
transformer 的encoder做了什么?明明图片向量的维度没有改变,为什么可以学习到更深层的信息?
从输入到输出,每个图片向量(Patch Embedding)的维度 D (例如 768) 没有改变。
学习到更深层的信息,其奥秘不在于“改变维度”,而在于“丰富每个维度所蕴含的信息”。
我们可以把每个 768 维的向量想象成一个信息极其丰富的“个人档案袋”。一开始,这个档案袋里只装着最原始的信息——这个 Patch 的像素颜色和位置。经过 Encoder 的处理,这个档案袋的内容被不断地更新和丰富,最后它不仅包含自己的原始信息,还包含了它与图像中所有其他部分的关系。
一个 Encoder Layer 的完整流程是:
输入向量 -> 多头自注意力 (建立全局关联) -> 前馈网络 (独立深度加工) -> 输出向量
而一个完整的 Encoder 是由很多层这样的结构堆叠而成的(比如 12 层)。
第 1 层: Patch 们可能只学会了最基本的关系,比如“这几个相邻的 Patch 颜色相近,可以组成一条边”。
中间层: 模型开始组合这些边,形成更复杂的纹理和部件,比如“这些边和纹理组合起来,像一只眼睛”。
高层: 模型组合这些部件,形成对物体的整体认知,比如“这只眼睛、耳朵和鼻子共同构成了一张猫脸,它在图片的左侧”。
所以维度没有改变,但向量内部的“信息熵”或“语义密度”大大增加了。
输入时,向量[0:10] 可能只代表了 Patch 左上角的蓝色像素。
输出时,向量[0:10] 可能已经代表了“作为天空一部分的蓝色,并且它与下方的白色云朵 Patch 有着强烈的关联”。
一个 Patch 展平后是 (1, 768),每个维度是一个像素的一个颜色通道值。它会先被映射成 (1, 512) 的特征向量 (Embedding),这是起点。
经过 Transformer 后,它变成了一个全新的向量 z_i。z_i 是所有其他向量的内容 v_j 的加权平均,而权重是注意力分数 α_ij。这个过程是融合。
对于Transformer不懂得可以看看我之前的文章,有非常详细的讲解。

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









