



前言
之前写过联网对话、聊天历史对话,现在继续写个文件对话。
一、环境准备
- ollama,用于在本地运行、部署和管理大型语言模型(LLMs)。
- deepseek 模型,本文用的 deepseek-r1:14b。
- langchain,大语言模型应用程序的开发框架,主要 python 实现。
具体环境搭建这里不在细说,大家可以看看以前文章,传送门:
手撸一个 deepseek 本地联网版且私有化部署(ollama + deepseek + langchain + searxXNG + flask)
手撸一个 deepseek 聊天历史对话、多轮对话(ollama + deepseek + langchain + flask)
保姆级教程 本地部署 deepseek + ollama + open-webui + cuda + cudnn
二、开发思路
- 文档预处理
- 使用PyPDFLoader加载PDF并合并文本(这里演示 pdf 加载器,其他文件格式的可以看看 langchain 文档)
- 正则清洗(合并空格/调整标点格式)
- 递归文本分割(中文友好分隔符)
- 语义检索
- 使用BGE中文嵌入模型生成向量
- FAISS向量数据库存储
- Top10相似度检索
- 问答生成
- DeepSeek中文模型处理提示
- 流式输出结果
三、代码解读
- 初始化 llm
# 设置Ollama的主机和端口
os.environ["OLLAMA_HOST"] = "127.0.0.1"
os.environ["OLLAMA_PORT"] = "11434"
def get_chat_llm(model="deepseek-r1:14b") -> OllamaLLM:
return OllamaLLM(model=model)
def get_answer_prompt() -> ChatPromptTemplate:
system_prompt = """
【指令】
你是一个AI文档助手,根据文档信息,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据文档信息无法回答该问题”,不允许在答案中添加编造成分,答案请使用中文。
【文档信息】
{context}
"""
return ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}") # 将query改为input以匹配输入键
])
- 文档清洗
# 文档清洗,加强中文标题,去冗余空白
def load_and_preprocess_pdf(pdf_path):
loader = PyPDFLoader(pdf_path)
documents = loader.load()
merged_text = "\n".join([doc.page_content for doc in documents])
cleaned_text = re.sub(r'\s+', ' ', merged_text)
cleaned_text = re.sub(r'【(.*?)】', r'\n【\1】', cleaned_text)
return cleaned_text.strip()
- 文本分块
# 按优先级从高到低的分割符序列,模拟人类阅读时识别文本结构的逻辑顺序。
def create_text_splitter():
return RecursiveCharacterTextSplitter(
separators=["\n\n", "。", "!", "?", "\n", ",", ";", " "],
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
- 语义检索返回TOP10
# 语义检索返回TOP10
def get_retriever(documents: List[Document]):
embeddings = OllamaEmbeddings(model="quentinz/bge-large-zh-v1.5", base_url="http://127.0.0.1:11434")
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store.as_retriever(search_kwargs={"k": 10})
- 主流程,文件放在 uploads 目录下,可以使用 flask 提供接口上传,在对话中指定文件
# 主流程
def start_chat_file(query, model, file_name):
pdf_path = os.path.join("./uploads", file_name)
cleaned_text = load_and_preprocess_pdf(pdf_path)
chunks = create_text_splitter().split_text(cleaned_text)
documents = [Document(page_content=chunk) for chunk in chunks]
llm = get_chat_llm(model)
retriever = get_retriever(documents)
# 构建链
prompt = get_answer_prompt()
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 调用链
stream = retrieval_chain.stream({"input": query})
return stream
四、完整代码
import os
import re
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List
# 设置Ollama的主机和端口
os.environ["OLLAMA_HOST"] = "127.0.0.1"
os.environ["OLLAMA_PORT"] = "11434"
def get_chat_llm(model="deepseek-r1:14b") -> OllamaLLM:
return OllamaLLM(model=model)
def get_answer_prompt() -> ChatPromptTemplate:
system_prompt = """
【指令】
你是一个AI文档助手,根据文档信息,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据文档信息无法回答该问题”,不允许在答案中添加编造成分,答案请使用中文。
【文档信息】
{context}
"""
return ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}") # 将query改为input以匹配输入键
])
# 文档清洗,加强中文标题,去冗余空白
def load_and_preprocess_pdf(pdf_path):
loader = PyPDFLoader(pdf_path)
documents = loader.load()
merged_text = "\n".join([doc.page_content for doc in documents])
cleaned_text = re.sub(r'\s+', ' ', merged_text)
cleaned_text = re.sub(r'【(.*?)】', r'\n【\1】', cleaned_text)
return cleaned_text.strip()
# 按优先级从高到低的分割符序列,模拟人类阅读时识别文本结构的逻辑顺序。
def create_text_splitter():
return RecursiveCharacterTextSplitter(
separators=["\n\n", "。", "!", "?", "\n", ",", ";", " "],
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
# 语义检索返回TOP10
def get_retriever(documents: List[Document]):
embeddings = OllamaEmbeddings(model="quentinz/bge-large-zh-v1.5", base_url="http://127.0.0.1:11434")
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store.as_retriever(search_kwargs={"k": 10})
# 主流程
def start_chat_file(query, model, file_name):
pdf_path = os.path.join("./uploads", file_name)
cleaned_text = load_and_preprocess_pdf(pdf_path)
chunks = create_text_splitter().split_text(cleaned_text)
documents = [Document(page_content=chunk) for chunk in chunks]
llm = get_chat_llm(model)
retriever = get_retriever(documents)
# 构建链
prompt = get_answer_prompt()
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 调用链
stream = retrieval_chain.stream({"input": query})
return stream
if __name__ == "__main__":
stream = start_chat_file("总结下采购管理办法", "deepseek-r1:14b", "6fad621de57646a297bf0354e853f0d2.pdf")
for chunk in stream:
print(chunk)
五、测试效果
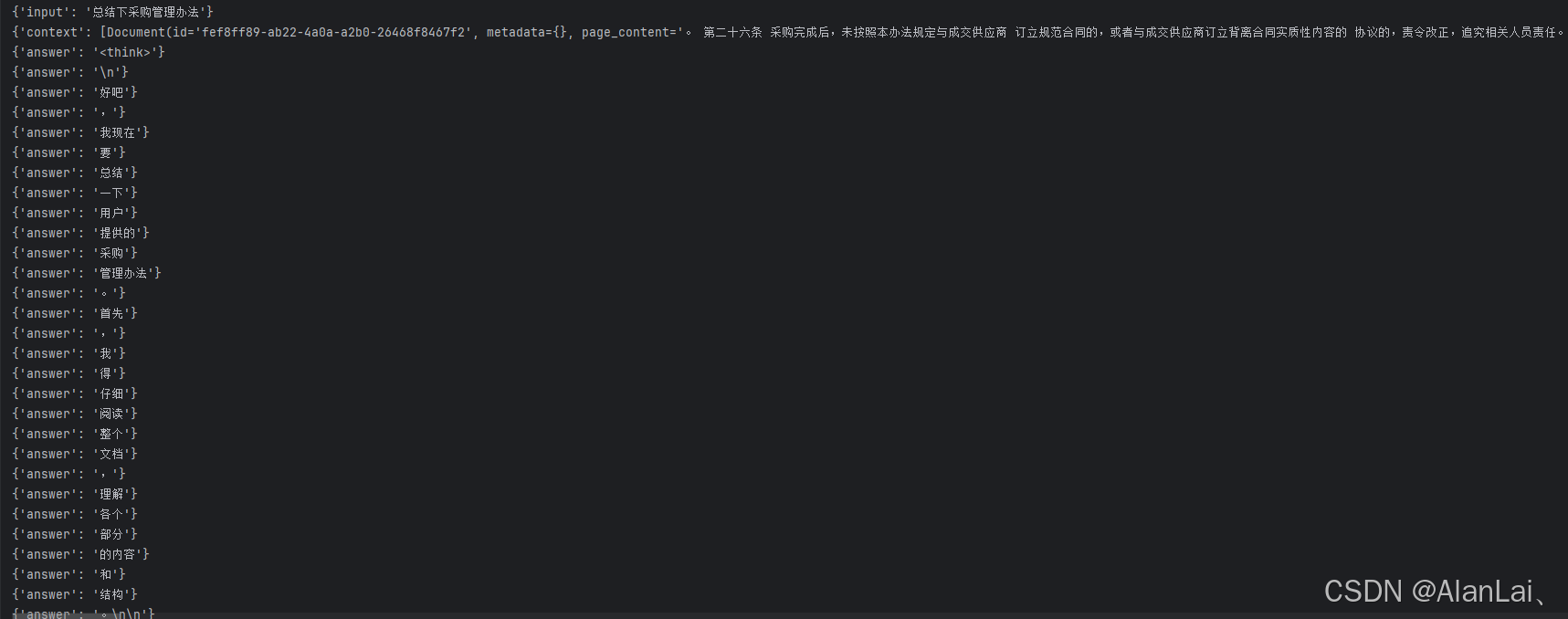
这里用的流式输出,效果还可以,大家可以自行调整参数和优化代码。

















 6983
6983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









