




引言
OpenAI在9月5日宣布将与Broadcom合作进行首款自研AI芯片的量产,预计于2026年开始出货,仅供内部使用。此举不仅是OpenAI第一次亲自参与硬件生产,也标志着大规模AI基础设施正在从“依赖GPU”的时代,迈向“硬件自主可控”的新时代 金融时报。

Broadcom’s chief executive referred to a mystery new customer committing to $10bn in orders
同一天,微软 CEO Satya Nadella在社交平台上透露,公司在模拟光学计算方面取得重大进展,并在《Nature》杂志中发表了相关论文,指出它将为复杂计算任务带来前所未有的效率提升 Times。

Microsoft CEO Satya Nadella
它们构建出一个清晰背景:AI 基础设施不再满足于 GPU 通用方案,而向着更高效率、更大规模、更专业化演进,昭示着一个底层转变: 企业不再满足于“外购 GPU”,而是在打造自身定制加速硬件; 新型芯片技术正在被商业化推进,拥有改变 AI 基础设施格局的潜力; 光子计算、模拟计算等非传统路径正在进入主流视野。
正是在这一行业背景下,本文将深入探讨三条极具颠覆性的技术路线——新一代GPU与ASIC设计、Chiplet 与内存层次架构、新兴硬件技术(光子技术和互联,神经形态,封装)——它们正是支持前述趋势落地的技术基石。一同揭示这些革命性方案如何从实验室走向数据中心和终端设备,塑造 AI 加速器的未来格局。
基本认识
近年来,随着大规模模型(尤其是大型语言模型,LLM)的飞速发展,AI 基础设施面临着巨大的挑战。大规模训练对硬件性能、推理效率和分布式计算提出了前所未有的要求。为了满足这些需求,学术界和工业界在AI加速器硬件方面纷纷展开创新。NVIDIA、AMD、Google等公司持续推出新架构以提升AI性能。例如,NVIDIA 已公布面向2026年的“Rubin”架构(代号Vera Rubin),其第一代GPU配备8片HBM4E,单卡显存高达288GB,并引入NVLink 6代互联、1600Gb/s InfiniBand高速网络和X1600交换芯片等新技术tomshardware(如下图)。
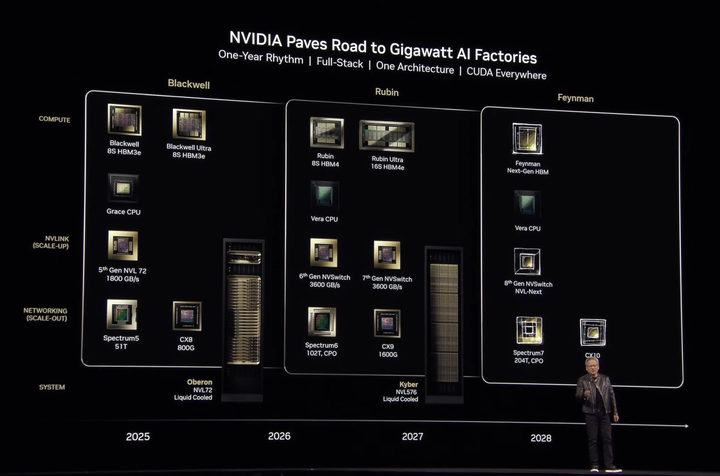
Nvidia’s new AI chip roadmap
类似地,AMD在MI300系列GPU上首次大规模采用chiplet设计,并通过Infinity Fabric实现了跨芯片通信(如下图)。

MI300
Google推出的的下一代TPU——代号“Ironwood”(如下图),专为大规模AI推理和推理优化模型(如LLM和专家模型)设计。
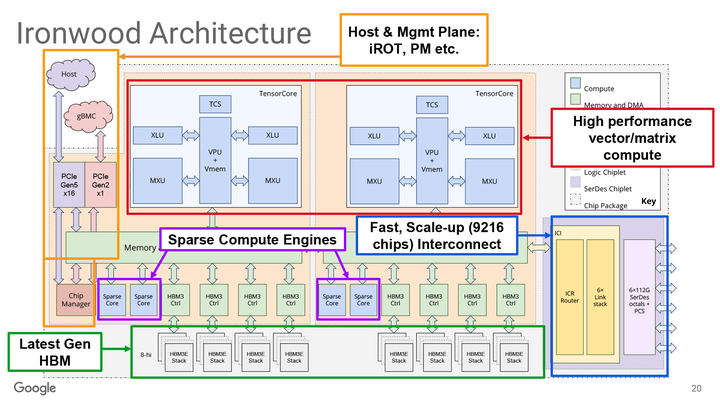
Ironwood
此外,研究者探索新型加速硬件。例如光子芯片已在学术界受到关注。HP Labs提出了一种基于III-V材料的硅光子学集成电路架构(如下图),用于加速神经网络推理 ieeephotonics 。

AI accelerators using photonic integrated circuits on silicon chip
该研究演示了基于光学神经网络(ONN,Optical neural network,wiki)的AI加速平台,通过片上激光器、放大器和调制器等组件实现整体光子芯片集成,具有较传统GPU更高的能效和可扩展性(如下图)。

Optical neural network
类似地,UPMEM团队提出PIM-AI架构(如下图),将处理单元直接集成在DDR5/LPDDR5内存中,无需修改内存控制器即可用作LLM推理。在云端场景下,PIM-AI相比顶级GPU实现在每秒查询成本上降低近7倍;在移动场景下,每token能耗降低10–20倍,查询吞吐增加25–45% arxiv。这些工作表明,内存计算(Processing-In-Memory)和光子计算等新兴硬件技术有望显著提高AI计算的能效和成本效益。
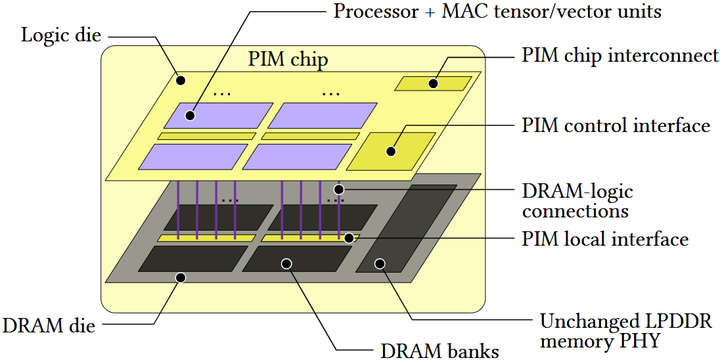
PIM-AI
这些新产品或新思路可能只是冰山一角。各大公司和科研机构正从深入解决 AI 某些技术细节入手,并以此为起点,逐步影响并重塑 AI 基础设施和算力的定义。基于此,本文将对这些新技术与新趋势进行深入分析。
新一代GPU与ASIC设计
设计目标与演进脉络:从“通用张量引擎”到“数据与格式原生化”
近两年的AI加速器升级,集中体现为三条主线: (1)算术密度:以FP8/FP6/FP4及micro-scaling类格式为代表的低比特浮点与标度化数制,要求硬件原生支持缩放元数据与混合精度的流水化处理(不仅是运算核,还包括寄存与访存路径)。例如,ISCA’25提出的Avant-Garde即把“多层级标度格式”作为一等公民(First-class Citizen),在前端将多样数制折叠为单层内部表示,减少格式转换与调度开销,从而把“数制多样性→算术密度提升”落到微架构层面(如下图)。ACM

Emerging scaled numeric formats.
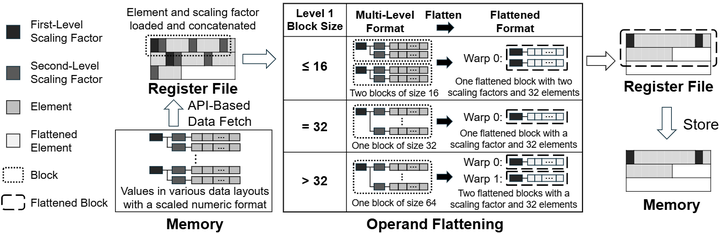
Operand flattening in Avant-Garde
(2)存储-计算协同:KV-cache的容量/带宽成为大模型推理的首要瓶颈,促生“缓存压缩+KV量化+流水分解”的三件套:ISCA’25的Ecco arXiv 用熵感知压缩把KV-cache从访存型负担转化为L2邻近“可并行解码”数据流;
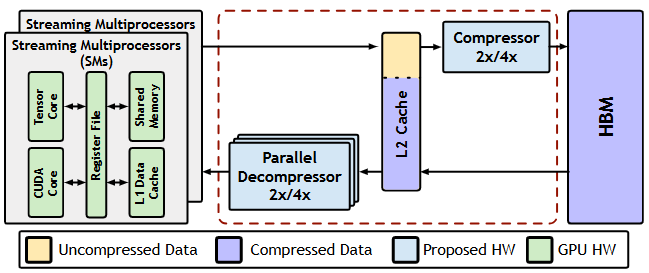
Ecco
同样,Oaken把KV-cache的“离线门限+在线尺度”量化做成软硬协同模块,直接进入专用加速数据通路。Park
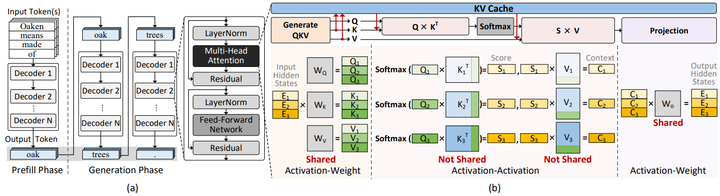
LLM inference
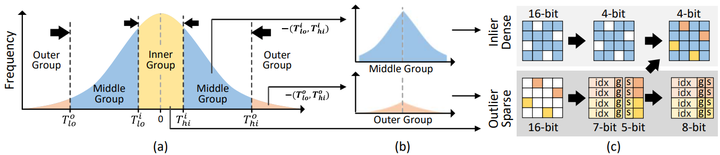
Oaken’s quantization algorithm
(3)系统互连与异构:
-
GPU 与 CPU(如 AMX)、NPU、以及通过 CXL 扩展的内存耦合加强: 这些异构组件的集成不仅改变了同步路径,也推动了跨设备协同的基础设施演进,从而促进 GPU 对 CPU 内存的透明访问,以此改变流水关键路径 (如下图,LIA acm)。
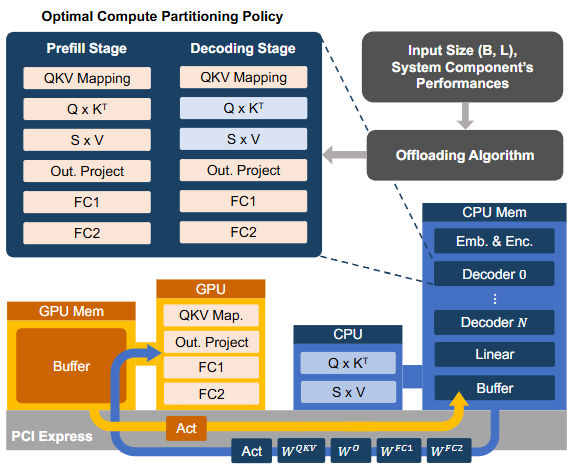
CPU-GPU cooperative computing framework for LLM inference
-
这类耦合结构改变了 prefill 与 decoding 阶段的分化与跨设备并行调度方式: 在新的系统中,可以将 prefill 阶段与 decode 阶段分布到不同设备上,协调资源以提升整体性能。例如, Nexus 设计通过在 GPU 内动态切分资源以应对这两阶段的计算与带宽需求。arXiv
Nexus
-
这也推动了 GPU / ASIC 必须将“跨域搬运、分阶段调度、跨格式核心控制”等调度控制面下沉到硬件层设计中: 包括调度逻辑从上层软件下放到硬件,支持异构计算调度。例如,HybriMoE 就体现了此趋势:它通过 CPU-GPU 协同调度策略,实现实现内存调度与 cache 管理 。arxiv
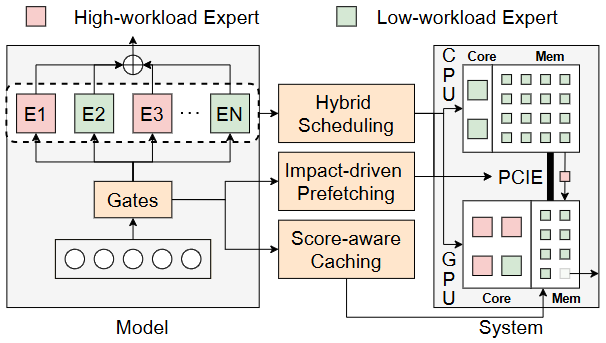
HybriMoE
GPU方向:Blackwell与原生多格式张量核”的微架构深化
-
Blackwell 的结构要点
公开的NVIDIA Blackwell资料与最新微基准研究表明(nvidia):第五代Tensor Core在Hopper的FP8变体基础上(如下图),新增FP6/FP4并扩展混合精度矩阵路径,这意味着数制多样性成为硬件一等公民(FP4/FP6/FP8/INT混合);同时在SM子核、缓存/共享存储与调度细节上做出针对Transformer的“算子-缓存一体化”调优。
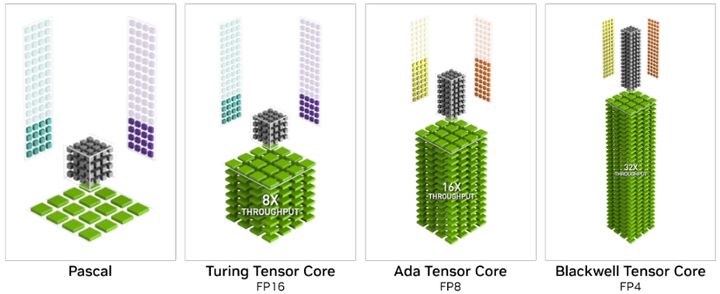
Blackwell 5th Generation Tensor Cores with FP4, double throughput of FP8
-
低比特乘加的新形态:查表型与任意精度张量核
面向mpGEMM(低比特权重×高比特激活,mixed-precision matrix multiplication),传统“先反量化再MAC”代价高(如下图(b))。
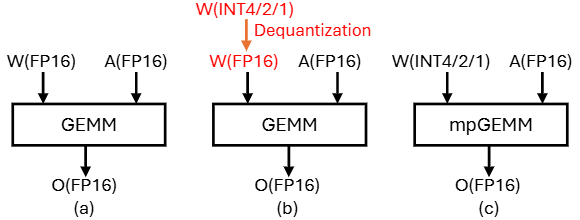
(a) GEMM, (b) Indirect mpGEMM with dequantization, (c) Direct mpGEMM for low-bit LLM inference
2025年更新的LUT (lookup table)Tensor Core把查表作为一等乘法原语,经由表对称化、拉长tiling与比特串行支撑多组合精度;评测显示对BitNet/量化LLaMA的密度与能效数量级提升,并给出指令/编译器栈以支持端到端流水(如下图例子,arxiv)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









