 LLM训练并行策略演进与优化
LLM训练并行策略演进与优化







引言
目前,硬件端的超级并行在不断抬高上限:英伟达在 GTC 2025 公布新一代 Blackwell Ultra / Rubin 路线,强调更强的多 GPU 并行互联和更大的显存/带宽,就是为了让上万卡协同训练成为常态;主流媒体把它解读为“为下一代超大模型和更省电的训练做铺路”AP 。这意味着:如果不拥抱更聪明的并行策略,算力再强也会被“沟通成本”吃掉。

Nvidia CEO Jensen Huang speaks at the company's GPU Technology Conference
与此同时,模型侧的“多维并行”正在走向工业标准。Meta 的 Llama 3 工程论文把“4D 并行(FSDP × 张量并行 × 流水线并行 × 上下文并行,如下图)”公开成体系:他们在1.6 万块 GPU上,把模型切分、层内并行、流水线调度和长上下文切片协同推进,来换取“能训得动、还要训得快”的平衡 (AIsystem) 。对普通大众而言,关键信息是——如今的大模型,已不是“把参数丢给一堆显卡”这么简单,而是把时间线与数据路由都并行化。
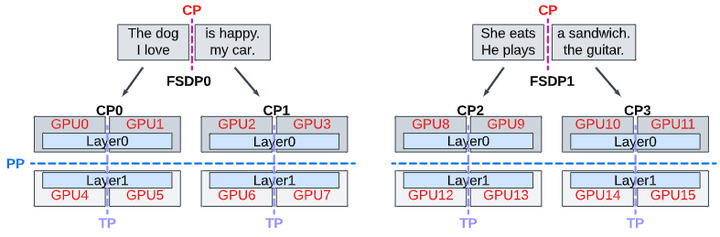
A two-layer LLM is sharded across 16 GPUs using 4D parallelism
更现实的难题是:流水线(Pipeline)里的“空转时间”(气泡,bubble)非常多。特别是在大规模流水线并行里,GPU 的空等时间常年 15%–30%,极端能超 60% (如下图例子,MLsys)。这告诉我们,优化并行≠只改模型,更是把时间切干净的工程学。
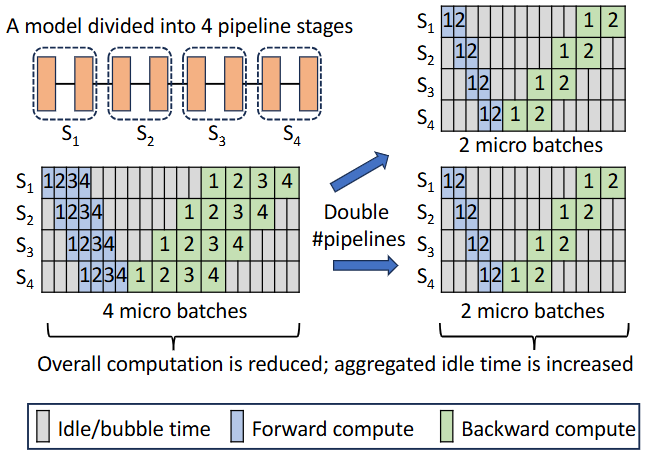
PP combined with DP
再往外看,训练规模已经超出单个机房。USENIX ATC 的 CrossPipe (USENIX)显示:跨机房训练会被高时延/低带宽“卡脖子”(如下图),必须把pipeline scheduler和数据并行通信放在同一个优化框架里,才能把“等网络”的时间压下去。这让“跨地域的协同并行”成为下一步的硬题,也解释了为什么数据中心与运营商,都在讨论面向 AI 并行的网络/光互联改造。
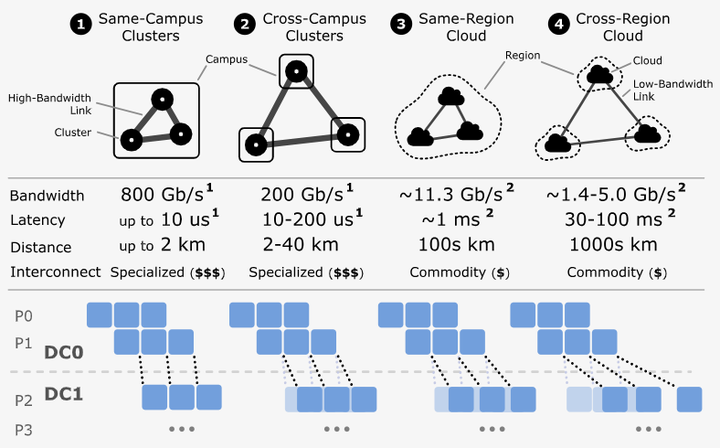
Cross-DC infrastructure setup types and their impact on the PP communication at DC boundaries
最后是模型结构的演进:生产级的 MoE(专家混合)系统报告,把“全到全(All-to-All)通信”做成体系化优化后,才能在上千 GPU 上把有效算力(MFU)拉上来 (arxiv) ;这类工作一方面让“大模型变大”,另一方面也逼着并行策略从“能跑”走向“会跑”。行业文章也在提醒:并行策略和网络架构是一体的,没有高质量的互联与调度,所谓“大模型训练”就像堵车时开跑车 ( drivenets ) 。
因为这些变化决定了AI 发展的速度与成本:并行做不好,训练就更慢、更贵;并行做对了,模型能更快上线、更省电、更普惠。你在新闻里看到的“更聪明的 AI”“更长的上下文”“开放模型能赶上闭源”等,背后都离不开这场关于并行与优化的“系统工程革命”。为此,本文将梳理一下关于LLM模型训练的并行策略与优化,侧重于最新的研究和实践成果,按照数据,模型和流水线三个维度去分析(内容上有交叉和重叠【各维度解决问题的思路却不同】,因为对一个系统而言,三者多是需要同时考虑及优化。)
并行策略的演进与优化
大规模模型训练最核心的挑战在于如何将计算和模型参数有效地划分到多机多卡上。经典并行策略包括数据并行、模型(参数)并行和流水线并行三大类,以及它们的组合(有时称为混合并行或三维/四维并行【如下图,arxiv】)。近年来,这些并行化方案不断演进,既追求更高的硬件资源利用率,也为适应日益增长的模型规模和序列长度进行了优化(如下图)。
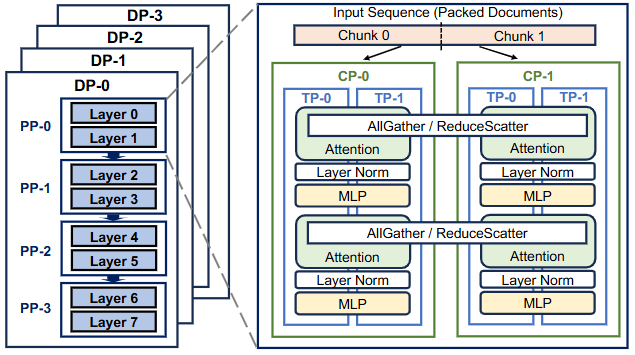
4D parallelism for LLM training
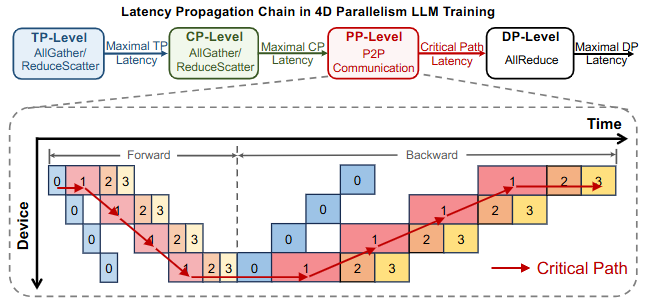
The process of latency propagation in 4D parallelism LLM training
数据并行与优化
大规模语言模型(LLM)训练与推理的工程目标显著不同:训练强调吞吐(tokens/s、step/s),推理强调并发与延迟。这一差异直接投射到并行策略与系统设计:训练侧通过数据并行扩容样本处理能力,并辅以模型/张量并行、流水线并行、专家并行等组合;推理侧则围绕KV 缓存、长上下文与并发连接做内存与通信优化。
数据并行的“老三件”:同步聚合、桶化重叠、弹性与鲁棒
经典 DDP(Distributed Data Parallel)在每个 worker 持有一份完整参数,前后向各自计算梯度后做AllReduce 平均。为隐藏通信,框架将梯度按“桶(bucket)”打包并在反向图回溯过程中边计算边聚合;但现实集群存在慢节点/拥塞导致尾部延迟,形成“长尾阻塞”(如下图,USENIX)。
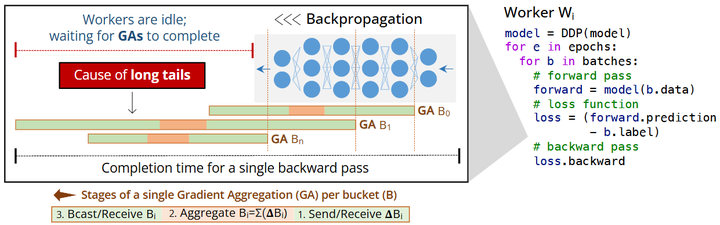
A backpropagation pass in distributed data-parallel (DDP) training
NSDI’25 的 OptiReduce (USENIX,如下图)从集体通信(collective communication)侧切入:用Transpose AllReduce(TAR)、有界不可靠传输(UBT)与Hadamard 变换把“允许少量梯度丢失/近似”纳入系统设计目标,显著降低回合数与最慢路径占比,从而压缩 AllReduce 的 99 分位时延并提升 TTA(Time-to-Accuracy)。
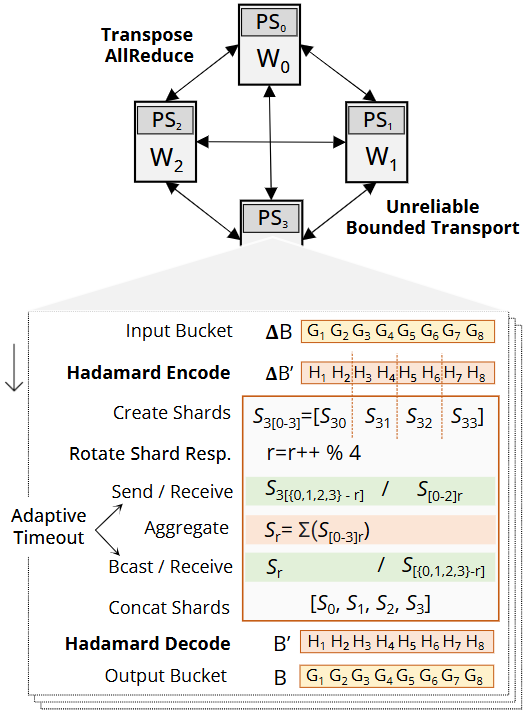
OptiReduce design
从 ZeRO/FSDP 到“更聪明”的通信:重叠、稀疏与感知
为降低数据并行的内存和通信开销,研究者提出了一系列优化技术。例如,微软提出的ZeRO(如下图,arxiv)系列方法通过显存优化将优化器状态、梯度和模型参数在进程间按块拆分,减少每个GPU需持有的数据副本。
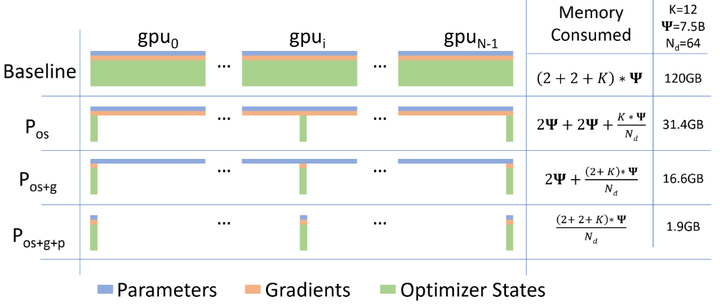
ZeRO
PyTorch社区发展出Fully Sharded Data Parallel (如下图,pytorch, arxiv),在训练过程中按层对模型参数进行分片和重组,实现近乎线性可扩展的内存优化。
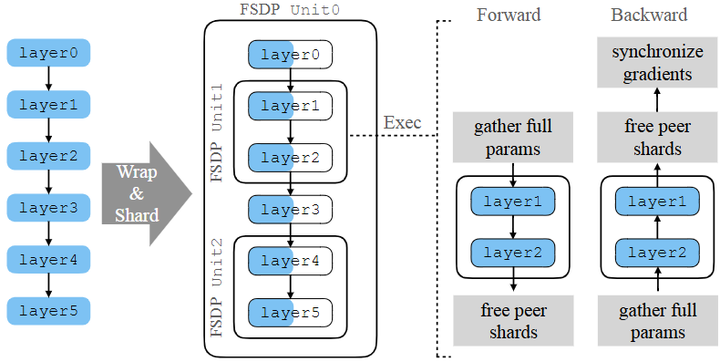
Fully Sharded Data Parallel
这些技术本质上都是分布式张量存储与计算的思想,将数据并行策略推进到“零冗余”的极致,但同步界面从一次 AllReduce 变为层粒度的ReduceScatter/AllGather,通信更频繁、更难隐藏。2025 年出现两条清晰路线:
-
更强的通信–计算重叠:FlashOverlap(如下图,ar5iv):识别 GEMM 的tile→wave完成序规律,基于信号触发与重排实现tile/wave级的通信启动,不改变 GEMM 主逻辑,也不要求定制通信核,因而通信无关、干扰最小,在多 GPU(尤其消费级 PCIe)下可达 1.65× 加速。

FlashOverlap
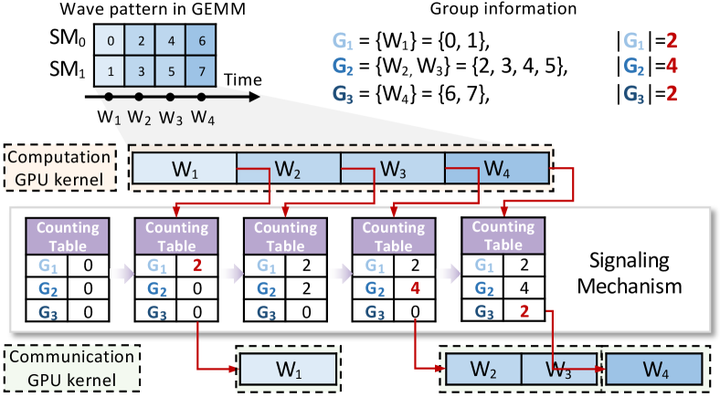
Signaling mechanism in FlashOverlap
GPU 上的重叠(如下图,arXiv)表征研究给出更系统的性能模型与可重叠性边界,为“是否值得再细粒度拆分/融合”提供定量依据(如对 GEMM+AllReduce/GEMM+RS 的分析,如下图说明计算-通信重叠会带来显著的计算减速,特别是在 FSDP 和小 batch 下,而流水线并行受影响较小)。

overlapping computation and communication
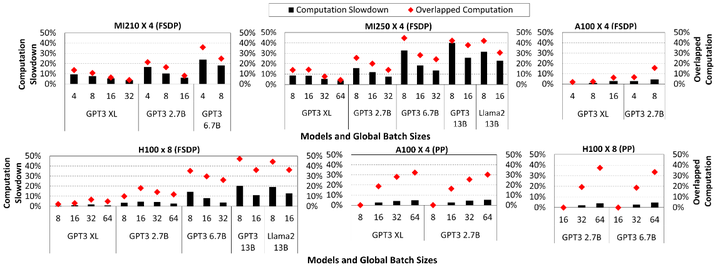
Computation slowdowns across GPUs for various models
-
梯度压缩/稀疏化与变体: TAGC(Transformer-Aware Gradient Compression,arXiv):把同态无损压缩(LHC)迁移到 FSDP 的分片场景,并结合层选择与动态稀疏化(伪码如下);在低带宽时对 FSDP 有最高 ~15% 加速。

TAGC Algorithm
同时, SparseLoCo(arxiv)、SEPARATE(openreview)、GWT(arxiv) 等:分别从分组 Top-k、分离式压缩-聚合、离散小波等角度降低梯度通信量,对预训练/微调均有实证收益与可控精度损失。为了理解方便,本文进行对比:
| 方法(年份 / 场合) |
作用范围 |
核心技术路径 |
接入位置 |
作者报告的性质 / 收益 |
开源代码 / 适配框架 |
|---|---|---|---|---|---|
| DiLoCo (ICML’22) |
通用分布式 SGD |
延迟通信—每 H 步同步 AllReduce + 外动量 |
DDP / FSDP |
通信量减少 10–20×,但存在精度风险 |
有 PyTorch 插件,兼容 FSDP |
| DeMo (ICLR’23) |
分布式优化 |
延迟动量保留一阶/二阶信息 |
DDP / FSDP |
相较 LocalSGD,收敛更稳;通信 ~5–10% |
PyTorch Hook,可改造 Megatron-LM |
| SparseLoCo (arXiv’25) |
LLM 预训练 |
TOP-k 稀疏 + 误差反馈 + 2-bit 量化 |
DDP / FSDP |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









