




引子
过去两周,几条系统层面的更新把“编译正在重塑大模型”的趋势按下了快进键:PyTorch 2.8 PyTorch 官方上线了原生的高性能量化 LLM 推理,直接把 x86/Intel 平台上的低比特推理做成“开箱即用”的能力;这意味着在不换硬件的前提下,许多企业现有 CPU 集群也能吃到成本红利。

PyTorch 2.8
同期 TensorRT-LLM 的 0.21.0 版继续快节奏迭代,针对主流 LLM 的图优化、KV-Cache、MoE、量化与新驱动栈做了整包升级,标注“Last updated: Aug 19, 2025”,释放出明确信号:编译栈正在与新硬件/新算子保持周更级联动NVIDIA。

TensorRT-LLM
另一方面,vLLM 一边发布 v0.10.1(700+ 次提交、200+ 贡献者),一边公开 1.0 的工作计划与里程碑,围绕可插拔调度、KV 管理与多后端接口进行“架构级”打磨,指向更通用的推理编译平台GitHub。甚至连硬件厂商也开始把“编译-优先”的思想打包成产品化工具:Intel LLM-Scaler 1.0 与随后发布的 Beta 更新(LLM-Scaler 1.0 As Part Of Project Battlematrix,如下图),主打多 GPU 扩展与 PCIe P2P、容器化一键部署,把“把模型编译到最会跑的形态”变成工程默认路径Phoronix。

LLM-Scaler 1.0 As Part Of Project Battlematrix
把这些新闻放在一起看,会发现它们折叠成同一条主线:一端是让编译器“学会懂模型”,通过图编译、内核融合(甚至 Megakernel)、动态形状与低比特量化,把 LLM 推理/训练的每一毫秒都抠出来;另一端则是让模型“学会做编译”,用大模型去提出优化决策、自动写 CUDA/Triton 内核,甚至在真实硬件回路里做强化学习式的性能闭环。
为什么现在会呈现这两种趋势呢?
概况而言,大语言模型(Large Language Model, LLM)近年来取得了突破性的进展。然而,LLM的训练和推理对计算资源需求极高,在模型规模不断扩大的背景下,如何通过编译技术更高效地利用硬件、降低延迟和成本,成为学术界和工业界共同关注的问题。一方面,研究者尝试利用LLM强大的知识和推理能力来改进传统编译器的优化过程(“LLM-for-Compiler”),通过LLM辅助搜索庞大的优化空间、自动生成高效代码,以及将强化学习等方法融入编译优化,实现以数据驱动方式超越人类手工规则的编译优化效果。另一方面,为训练和推理服务设计高效的编译系统(“Compiler-for-LLM”)也成为关键课题,包括针对动态计算图的编译、统一的中间表示(如Relax IR、StableHLO等)、跨算子融合生成大型内核(如单一MegaKernel)、模型量化加速、混合专家(MoE)模型的优化、针对新型硬件的部署适配,以及Flash系列高效算子内核的应用等等。本文分析2025年以来LLM与编译技术结合的最新研究进展,涵盖上述两个主要方向的核心思想和代表性成果,并对不同方法进行分析对比,最后展望未来的发展趋势。
LLM赋能编译优化(LLM-for-Compiler)
LLM作为拥有海量代码语料和强大推理能力的模型,被寄予厚望用于提升编译器的智能化水平。传统编译器的优化,例如编译优化选项搜索、循环展开和向量化等,往往依赖人为设计的启发式规则或代价模型,难以充分探索庞大的优化空间。而LLM有望通过数据驱动的方式,自动探索和发现高效优化策略。本节按研究范式将LLM用于编译优化的进展分为三类:(1)LLM引导的优化搜索与决策,利用LLM的上下文推理能力辅助探索复杂的编译优化空间;(2)LLM结合强化学习优化编译,通过训练或微调让LLM自行学会提升代码性能;(3)LLM自动生成高效代码,直接让LLM产出高性能的目标代码或优化补丁,包括针对GPU等特殊硬件的代码生成,以及面向编译优化任务专门训练的基础模型。
LLM引导的优化搜索与序贯决策
由于深度学习模型的计算图包含大量算子和可能的变换,编译器面临指数级庞大的优化空间。例如,针对一个神经网络层,编译器需要决定诸如算子融合、循环拆分/合并、存储布局和并行化等众多变换组合。传统方法(如启发式算法或演化搜索)虽然可以找到有效配置,但往往采样效率低下,需要尝试大量冗余或无效方案。为此,Tang等人提出利用LLM的上下文推理能力指导编译优化搜索,开发了“Reasoning Compiler”编译框架(如下图所示,arxiv)。
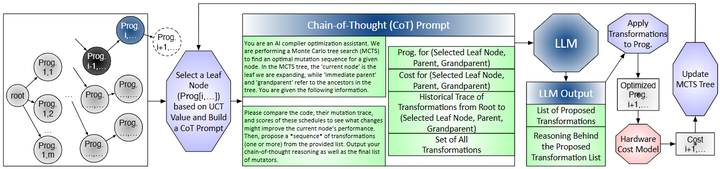
Optimization workflow in REASONING COMPILER
该方法将编译优化视为决策过程,在每一步由LLM根据当前程序状态和过往优化历史提出候选优化变换(如融合特定算子、调整内存布局等),LLM的建议具有硬件相关性和上下文相关性。然后通过蒙特卡洛树搜索(MCTS)评价并选择这些变换,平衡探索新方案和利用已有高性能方案之间的关系(如下图)。
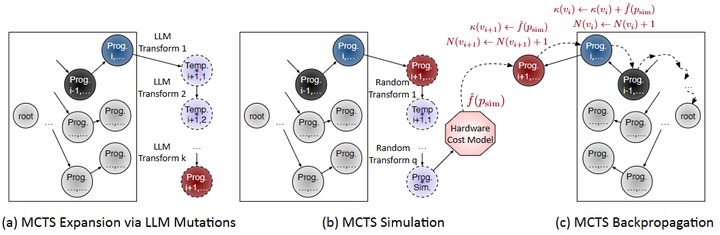
Structured tree search
实验结果显示,该LLM引导的编译器在样本效率上显著优于传统黑盒自动调优:在只尝试36个程序样本的情况下取得了对未优化代码最高2.5×的加速,比进化算法等方法减少了一个数量级的采样。这一研究证明,不经额外训练的LLM通过提供链式思考的上下文建议,结合MCTS等搜索策略,即可显著提升神经网络编译优化的效率和效果。
除了将LLM与决策树搜索结合,另一些工作探索将LLM融入编译器的变换调度和搜索框架。Hong等人提出的“Autocomp”系统以LLM为核心引擎来优化张量加速器(如TPU等)的代码arxiv。Autocomp将每个优化pass分解为“规划”与“生成”两个阶段,以两段式提示引导LLM工作(如下图):首先LLM根据提供的“优化菜单”选择下一步优化策略(如Loop Tiling、算子融合等),然后生成应用该策略后的代码版本。
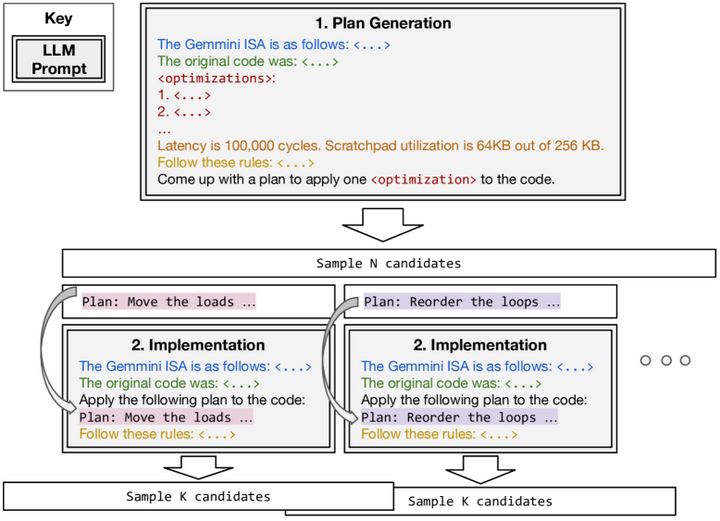
Autocomp’s two-phase optimization
整个过程迭代进行,在每轮生成后将真实硬件的性能反馈(运行时间等)返回给LLM,用于指导后续步骤,从而形成一个闭环的优化搜索(如下图)。这种方法无需额外训练LLM,而是依赖LLM对常见优化模式的先验知识和上下文推理来探索优化空间。
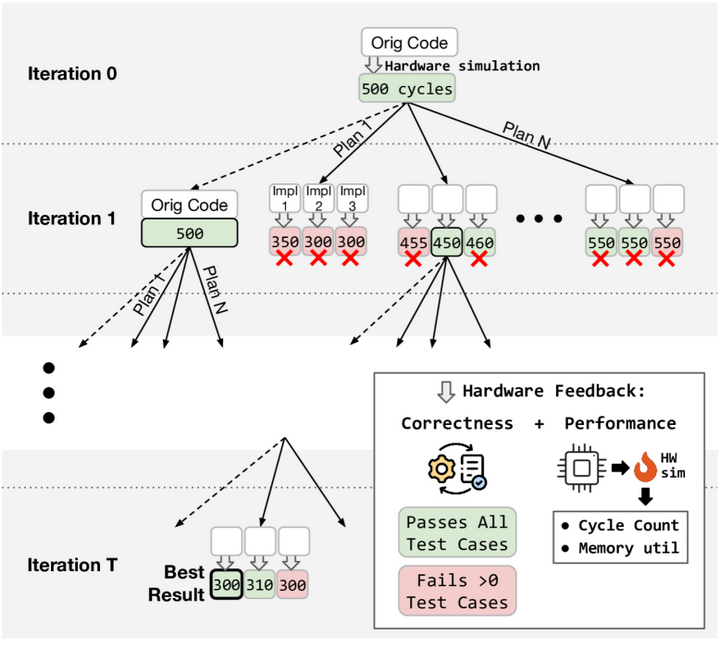
Autocomp’s beam search(Iteration)
Autocomp在两个定制加速器上的评估显示:经该框架优化后,矩阵乘法(GEMM)代码比厂商库实现快5.6倍,卷积代码快2.7倍,均超越专家手写的优化代码。类似地,Acharya等人提出的“AutoPatch”框架通过Retrieval-Augmented Generation(检索增强生成)提升LLM优化代码的能力ar5iv。AutoPatch首先从历史代码库中检索结构类似的“未优化-已优化”代码对及其控制流图差异,将这些作为提示供LLM参考。
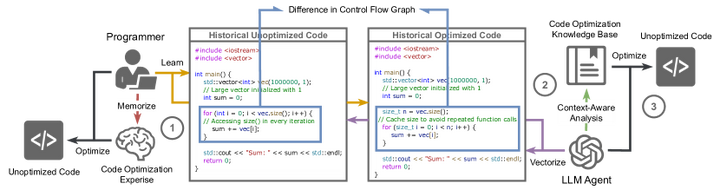
AutoPatch Workflow
LLM据此生成优化补丁代码并输出改进后的版本。该方法在IBM CodeNet数据集上使生成代码的运行效率平均提升7.3%,优于直接让GPT-4输出的结果。这一结果说明,引入历史优化案例和程序结构分析,能帮助LLM更深入地理解性能瓶颈并生成更高效的代码。
总的来看,以LLM为指导的编译优化探索呈现出“LLM提案 + 搜索验证”的范式:LLM利用其对代码和优化模式的语义理解给出启发性的优化建议,然后由搜索算法或实际硬件反馈加以筛选和验证。这种范式提升了优化空间探索的智能性和高效性,在编译优化决策中引入了“经验驱动”的成分,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2407
2407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









