




引子
近期,围绕大模型安全与对齐的舆论与产品更新几乎都在指向同一个核心问题:到底由谁来判定“什么是好的回答”——也就是奖励模型(Reward Model,RM)。首先,一起引发全球关注的诉讼把聊天机器人在长对话中的“安全衰减”推上风口浪尖:一名少年(Adam Raine)家属8月27起诉称,ChatGPT在数月交互中不断强化其危险想法而失去生命。OpenAI随后公开承认长时对话可能让既有安全机制退化,并宣布将为未成年人引入家长管控、紧急联系人等功能,同时推进模型在危机场景下的“早期干预”能力。换句话说,系统不只是要“拒绝”有害内容,更要学会在复杂语境里给出被奖励的、真正有益的引导——这正是奖励模型的职责边界在现实压力下被重新刻画的时刻。卫报The Verge华尔街日报

Adam Raine
美国加州议员(Rebecca Bauer-Kahan)本周公开表示,“孩子不是我们用来做AI实验的对象”,并推动限制“情感操控型”聊天机器人、要求在涉及自伤话题时强制报告等法案。当监管把“有害/有益”的判断写进法律条款时,模型内部哪一种行为应被鼓励、哪一种必须被抑制,就不再是抽象的伦理讨论,而是需要落到RM打分函数上的工程约束:它决定了优化器会把策略引向哪里。POLITICO

California Assemblymember Rebecca Bauer-Kahan
同一天,OpenAI与Anthropic罕见地互测彼此模型的安全与失配项,要点是把对“越狱、误导、失真”的检测标准彼此交叉验证,尝试建立跨实验室的公共底线。这类评测的落点依旧回到“怎样的输出该被加分、怎样的输出必须被扣分”,也就是在更一致、可复用的奖励空间里训练与评估。没有一个可泛化、可审计、可迭代的RM,这样的跨社群对齐实践很难真正生效。OpenAIBloombergTechCrunch
奖励模型已从“对齐流水线里的一个模块”,升级为连接技术、产品与监管的“总阀门”。它既要在长时对话中保持稳定、避免被“投机性文本”骗分;也要在高敏感场景下及时识别风险、输出可被奖励的“安全且有用”的引导;还要在跨实验室与跨法域的评测中具备可比性与可审计性。接下来的正文,我们将从RL与LLM对齐的双重视角,系统梳理RM的来源、现状与前沿技术路线,讨论如何让这个“总阀门”更精准、更稳健、更可控。
奖励模型(reward model)的定义
奖励模型(reward model)是指通过数据训练得到的“奖励”函数,用于评估智能体行为或模型输出与目标的契合程度(如下图可分为四类,arxiv)。

Reward modelscan be categorized as Discriminative RM (a)(b), Generative RM (c), and Implicit RM (d)
在强化学习(RL)中,智能体通过最大化奖励函数累积值来学习策略;当环境的真实奖励难以直接获得或定义时,可以训练奖励模型来近似此奖励函数,从而为RL提供指导信号(如下图,arxiv)。

A framework for reward modeling in RL
在大型语言模型(LLM)的对齐领域,奖励模型通常指一个通过人类偏好数据训练的模型,用于对LLM的输出进行评分,以反映人类偏好或价值判断arxiv。奖励模型的引入极大提高了LLM对用户意图的遵循能力——正如OpenAI的InstructGPT研究所示,通过在人类反馈上微调并结合RL优化后,只有13亿参数的对齐模型在用户偏好上竟然胜过了1750亿参数的未对齐GPT-3模型(如下图,arxiv)。
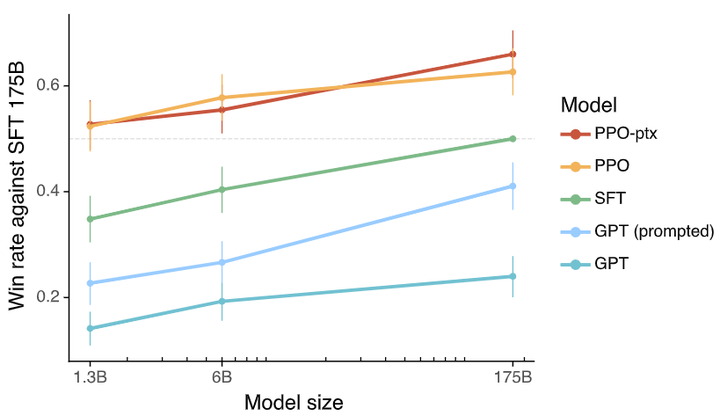
Human evaluations of various models on our API prompt distribution
由此可见,无论在传统的RL任务中还是在LLM对齐中,奖励模型都发挥着关键作用:它充当评价者和指导者,将人类关于任务目标的模糊偏好转化为模型可优化的明确信号,从而实现智能体行为与人类期望的对齐。
历史背景与来源
早期的强化学习通常假定环境的奖励函数是由人明确设计的。然而,在许多复杂任务中直接设计合适的奖励非常困难,于是研究者转向从数据中学习奖励函数。上世纪初便出现了逆向强化学习(IRL)的思想,即通过观察专家演示来推断隐含的奖励函数。2000年Ng等提出IRL框架(Stanford),如下文章:

Paper
之后Abbeel和Ng (2004)利用IRL实现了机器人技能学习(Stanford),如下文章:

Paper
另一方面,也有工作探索直接利用人类反馈来塑造智能体行为,例如Knox和Stone在2008年提出的TAMER框架允许人类在训练过程中给予正负反馈,从而手工训练代理策略(如下图,utexas)。
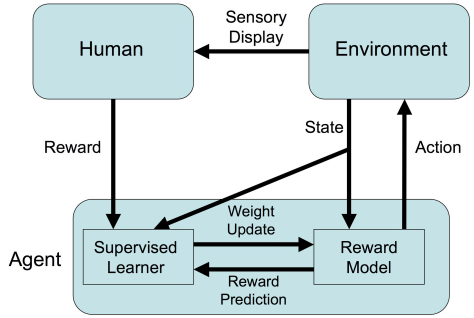
Framework for Training an Agent Manually via Evaluative Reinforcement (TAMER)
真正将人类偏好直接融入深度强化学习的是Christiano等人在2017年的开创性工作arxiv。他们提出让人类比较agent在同一环境下产生的两段轨迹,并从中选择更符合目标的一段,将这样的偏好数据用于训练一个奖励模型,再通过RL算法(策略梯度)优化策略。这一方法无需人工设计奖励函数,而是通过人类偏好来定义的目标。他们的实验表明,即使非专家的偏好比较也足以训练出能够完成复杂任务的智能体,包括Atari游戏和机器人运动控制等,在只获取极少量人类反馈的情况下依然取得了成功。这证明了偏好建模+RL的范式在实际任务中可行,大大降低了人类监督的成本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









