



引子
2025年Google DeepMind与OpenAI先后宣布其AI系统在IMO测试中达到了“金牌”级别的表现。DeepMind的Gemini Deep Think模型通过与IMO官方合作,正式获得金牌认证,而OpenAI则基于内部评估和独立数学专家的判定宣称其实验性推理模型也达到了金牌水平。这两起事件标志着AI在高难度数学推理领域的显著突破,预示着AI与人类数学家在未来有望展开更深层次的合作与竞赛。主流媒体从技术创新意义、AI通用推理能力跃升、以及对未来人工智能发展路径的启示等角度给予正面评价;多位数学家与AI专家(如陶哲轩、Ken Ono、Noam Brown等)对这一里程碑式突破进行了深入解读,并对其潜在影响提出了建设性评论。

Gold medal
Google DeepMind与OpenAI均宣称其AI模型在IMO上获得金牌级别成绩,但两者在与IMO组委会的合作程度、成绩认证方式及发布时机等方面存在显著差异,引发了学术界、媒体和IMO官方的多重争议和质疑。
官方认证 vs. 自行宣称
Google DeepMind的官方金牌
-
官方认证与成绩 DeepMind发布的博客称,其高级版本的Gemini Deep Think在2025年IMO六道题目中完美解答了其中五道,总分35/42,达到金牌标准,并获得IMO组委会的正式认证与采纳。 Google DeepMind
-
组织回应 IMO主席Gregor Dolinar教授表示:“我们可以确认DeepMind取得了35分的金牌成绩,解答清晰精确,评卷者普遍认为解法条理清晰、易于理解。” Google DeepMind

IMO President Prof. Dr. Gregor Dolinar
OpenAI的金牌宣称
-
内部评估与宣称 OpenAI研究员Alexander Wei在LessWrong上宣布,其最新实验性语言模型在相同考试规则下获得35分(解出前五题),达到了人类金牌选手的水平。 lesswrong.com

OpenAI Claims IMO Gold Medal
-
独立专家评审 OpenAI未获得IMO官方授权,其模型成绩由公司内部邀请的三位前IMO金牌得主进行“非官方”评审(Medium)。
发布时机与礼仪争议
-
抢先宣布被指“不当” OpenAI在闭幕式前发布金牌成绩,被多位IMO组织者及官方发言人指责为“过于仓促”且“有失礼节”,因其可能抢占了人类学生的关注与庆祝时机 (Arstechnica)。
-
舆论关注焦点转移 多家媒体指出,过早公布成绩不仅干扰了比赛的正式流程,也让本应属于人类学生的荣耀瞬间被AI宣称所“抢镜”,引发对AI与青少年选手权益平衡的讨论 (AInvest)。
评分标准与资源获取
-
评分rubric未知 学界人士(如Terence Tao)批评OpenAI可能利用对试题的“重新表述”或“提示工程”降低了测试难度,因其并未获准使用官方评分认可,模型解题过程与真实考试条件存在差距 。
Terence Tao
-
额外提示与数据 DeepMind公开承认对Gemini提供了高质量数学题解和“通用解题提示”,有声音质疑这是否已超出了纯粹的“通用AI”范畴,并带来了额外优势 (Reddit)。
学术与伦理质疑
-
透明度不足 一些专家指出,OpenAI并未公开模型具体参数、解题策略与评分细节,使得其“金牌”宣称难以在学术层面复现与验证 (lesswrong.com)。
-
对学生选手的影响 批评者认为,将AI成绩与学生成绩直接对比,有可能削弱比赛对青少年的激励意义,并引发学生与家长对比赛公平性的担忧 (36氪)。
Comments on OpenAI
媒体与业界反应
-
Business Insider 报道,OpenAI实验性模型在IMO中赢得“金牌”,并分析其背后的推理技术突破及对教育和科研的深远影响,称这是AI攻克人类顶级数学竞赛的里程碑。 (Business Insider)
-
Engadget 强调,此次成果标志着AI在复杂抽象推理能力上取得显著进展,并指出模型可在未来应用于科研辅助和自动化定理证明领域。 (Engadget)
-
Hacker News 社区中,许多AI研究者对OpenAI团队特别是Alexander Wei的领导力表示敬佩,认为他“用多人不看好的研究思路”实现了突破;同时,有人担忧需要对AI造成的行业冲击进行规范。 (Hacker News)
-
Reddit 上的讨论指出,此次测试严格遵循人类比赛规则,模型并非专门为奥数设计,而是通用推理熬炼的成果,标志着AI向“通义能力”(general intelligence)又迈出关键一步。 (Reddit)
-
极客科技 DeepMind与OpenAI在IMO上的“对决”被视为AI领域又一里程碑,其背后反映了大型科技公司在基础科学研究应用上的角逐,也引发了对科研资源分配与算力消耗的社会讨论 。(Arstechnica)
-
TechCrunch 称赞AI在复杂数学推理上的突破性表现,认为这预示着未来AI‐人类协作的新可能;另一部分则警示“炒作过度”,担忧算力狂飙和“冠军文化”过度商业化 。(TechCrunch)
专家解读与评论
数学家视角
-
Terence Tao(陶哲轩):在新浪财经专访中,陶哲轩表示AI解题方式与人类有别,仍需关注证明严密性,但他也肯定这次成果可能改变未来数学研究的协作模式。 (新浪财经)

Terence Tao(陶哲轩)
-
Ken Ono :在伯克利的封闭测试中,30位顶级数学家也未完全“秒杀”该模型,他坦言“从未见过AI展现出如此深入的数学直觉”,认为这一成就可能促使学术界重新定义“数学直觉”。 (The Sun)

Ken Ono
-
Brown大学数学教授Junehyuk Jung认为,这些突破展示了LLM在自然语言层面处理深层数学推理的能力,未来有望成为数学研究的“助教”工具。 Omni Ekonomi

Junehyuk Jung
AI专家视角
-
Noam Brown(OpenAI 研究员):这一突破“意义甚至超越了AI攻克IMO本身”,因为它展示了大规模体系化推理和自我验证模块的实力。 (wallstreetcn.com)

Noam Brown
-
Archit Sharma(DeepMind研究员):在36氪报道中调侃,DeepMind其实已率先完成了同样的测试,只因内部发布流程缓慢,才让OpenAI抢了风头,此事也凸显了科研与市场节奏的张力。 (36氪)
Archit Sharma
-
Rohan Paul(AI 科技博主):在其专业博客中分析,这次成果凸显了“验证+智能检索”策略的威力,认为未来可将此方法推广至其它学科竞赛或科研验证场景。 (rohan-paul.com)
-
Megan Morrone(AI科技编辑)指出,Google与OpenAI在IMO上的较量,反映了AI研发的“无边界”竞速态势,也引发了对算力消耗与伦理监管的关注。 Axios
LLM与IMO数学测试
2025年国际数学奥林匹克(IMO)中,OpenAI 的实验性大型语言模型(LLM)和DeepMind的高级版本的Gemini Deep Think在2025年IMO六道题目中完美解答了其中五道,总分35/42,都达到金牌标准。在六道题目中解出了五道,累计得分35分,达到金牌水平,相当于人类金牌得主的表现。此前,DeepMind 的 AlphaProof 系统在2024年IMO中解决了四道题目,也取得了银牌水平 (Google DeepMind)。这些成果表明,通过结合神经网络和强化学习、符号推理等技术,LLM在处理高难度数学推理任务上正不断逼近乃至超越顶尖中学生的水平 (WIRED, 泰晤士报)。尽管业界对这类成绩持谨慎态度,但多数专家认为,这代表了AI在通用推理能力方面的重要进展,未来有望成为数学研究和教育的辅助工具 (THE DECODER)。
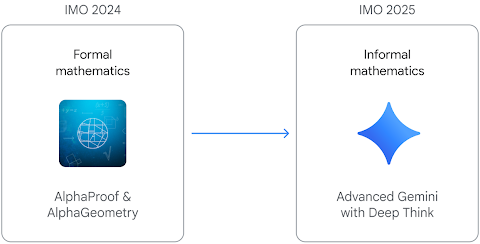
Deepmind's technology roadmap From IMO 2024 to IMO 2025
Deepmind/OpenAI:IMO 2025 金牌水平
在2025年IMO的六道官方题目中,OpenAI和Deepmind的模型都成功解答了其中五道,累计得分35/42,达到了金牌分数线 (Simon Willison’s Weblog)。IMO 2025总共只有六道题,而模型仅解决五题,它未能完整回答第 6 题(IMO 2025中公认的“Boss题”,下图)。同时,MathArena团队对五款主流模型(包括o3、o4‑mini、Gemini 2.5 Pro、Grok‑4、Deepseek‑R1)进行了“best‑of‑32”筛选策略后评估,最高得分为13/42,远未达及铜牌(19/42)标准 数学竞技场。

第六题是最难的‘Boss 题目’
DeepMind:IMO 2024 银牌水平
在 2024 年国际数学奥林匹克(IMO)中,DeepMind 发布的 AlphaProof(结合 AlphaGeometry 2)系统在三天内成功解决了其中四道题目,达到了银牌水平(28/42 分) (Google DeepMind)。其中,AlphaProof 独立给出了两道代数题(题 1 和题 2)与一道数论题(题 6)在 Lean 形式化语言中的完整证明,而 AlphaGeometry 2 则通过符号方法解决了题 4(几何题)。整个过程包括人工将原题翻译为形式化命题,使用预训练模型辅以 AlphaZero 强化学习进行搜索,并最终由人类数学家验证其严密性。最快一道题在数分钟内完成,最难题 6 则花费约 3 天内搜索与验证 (AiNews.com)。

第五题
公共核心技术:
LLM 在解决国际数学奥林匹克(IMO)题目时,主要依赖以下几大核心技术:链式思考(Chain‑of‑Thought)提示、多范式预训练与微调、神经符号融合与形式化验证、自我校验机制、检索增强与工具调用,以及蒙特卡洛树搜索等搜索算法的结合。
链式思考与高级提示技术
Chain‑of‑Thought 提示
-
在 Few‑Shot 提示中加入示例性的“思考链”——即中间推理步骤,让模型模仿人类解题思路,将复杂问题分解为逐步求解的子问题arXiv。 在 GSM8K、MATH 等数学推理基准上,540B 规模模型仅使用八个 CoT 示例即可超越微调后的 GPT-3,正确率从 ~33% 跃升至 ~57%(GSM8K)arXiv。
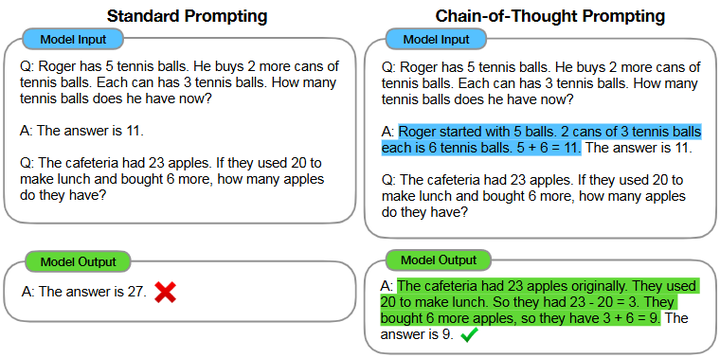
Chain‑of‑Thought
Least‑to‑Most 与 Step‑Back 提示
-
Least‑to‑Most:先解决最简单子问题,再逐步递进到更复杂问题,克服了 CoT 在示例难度超过训练示例时性能下降的缺点arXiv。
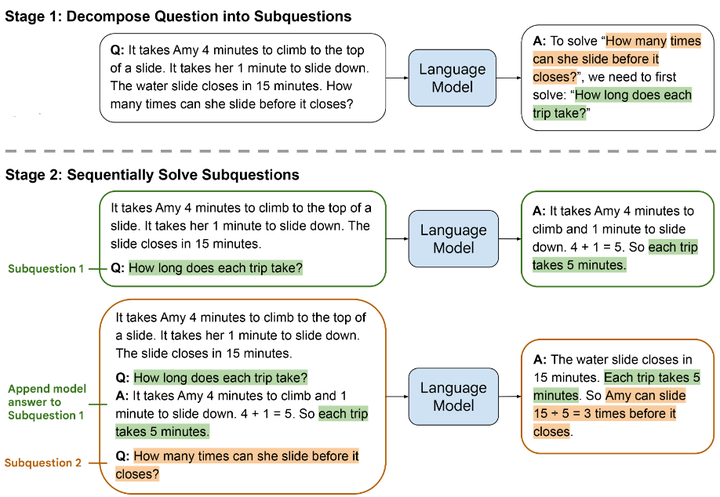
Least‑to‑Most
-
Step‑Back:先让模型从宏观层面回顾原理与方法,再聚焦具体问题,从而提升思路连贯性与全局视野Medium。

Step Back
数学专用预训练与微调
-
Minerva 系列:在通用语言预训练模型(如 PaLM、GPT)基础上,收集并微调数百万篇技术论文、预印本、在线数学社区文档,显著提升对数学符号、定理与证明风格的理解(arXiv)。

Example questions with solutions from Minerva
-
Proof‑Pile:如 Llemma/OpenCodeLlama 在 Proof‑Pile-2 数据集上继续预训练,使模型在 MATH 基准上对标或超越封闭源 Minerva 同参数版本(arXiv)。
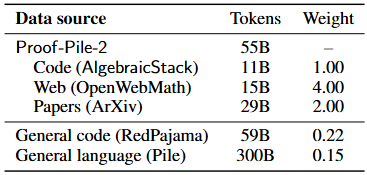
Proof‑Pile-2
-
结构化自洽 (Structured Self‑Consistency):对模型生成的中间推理与最终答案进行分层校验,通过熵最小化与推理图同构检测等机制确保全局一致性,提高数学推理的可靠性(arXiv)。

Adaptive Sampling and Structural Verification
神经符号融合与形式化验证
-
AlphaProof/AlphaGeometry:DeepMind 结合强化学习与符号推理,让模型生成 Lean、Coq 等定理证明脚本,并在证明助手中自动验证,每题细粒度交互优化,达成 IMO 银牌级水平(Google DeepMind)。
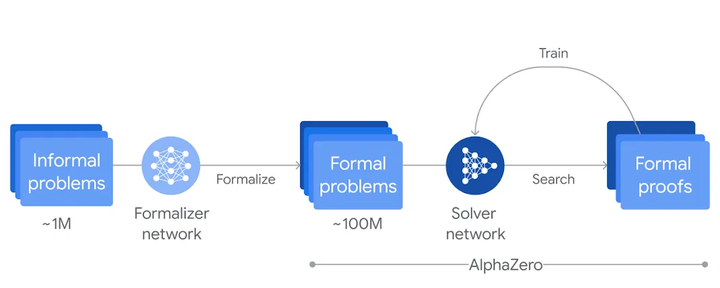
AlphaProof
-
ReProver / REAL‑Prover:通过检索-增强和定制化 LLM,选择并拼接相关前提(premises),再生成证明战术(tactics),推理完备且可形式验证,显著减少“幻觉”风险(NeurIPS )。
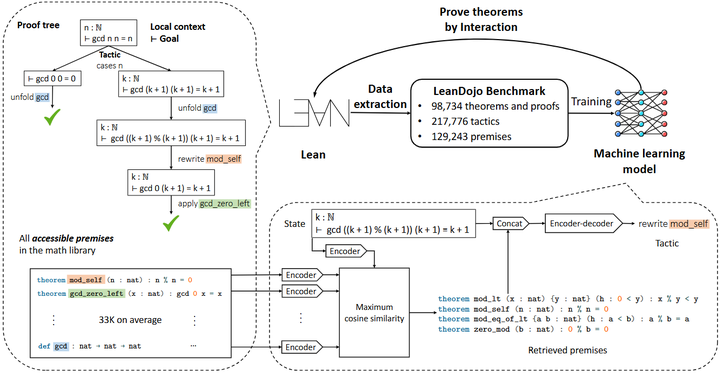
ReProver: Retrieval-Augmented Theorem Prover
-
Neuro‑Symbolic Tactic Generator:针对特定竞赛题型(如不等式),将 LLM 的直觉与符号算法的严谨相结合,由符号模块负责关键定理推导,LLM 负责高层次策略规划(OpenReview)。

neuro-symbolic inequality prover
自我校验与强化学习
-
流程监督 (Process Supervision):对中间推理过程进行奖励建模(PRM,Process Reward Models),比仅对最终答案的结果监督更能提升多步推理质量(arXiv)。

Two solutions to the same problem, graded by the PRM
-
统一生成与校验 (Self‑Verify RL):在同一 RL 过程中同时训练答案生成与校验模块,让模型在生成后自行评估正确性并回滚重试,大幅降低错误率(arXiv)。
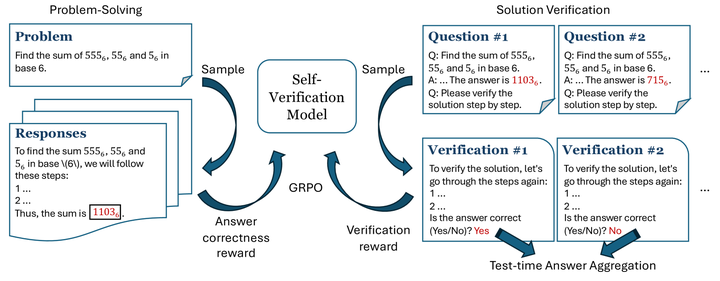
Self-verification framework
检索增强与工具调用
-
RAG(Retrieval‑Augmented Generation):如 LemmaHead 从教材与学术文献中检索引理,在对话上下文中补充数学背景,帮助模型填补知识盲区与推理空隙(arXiv)。
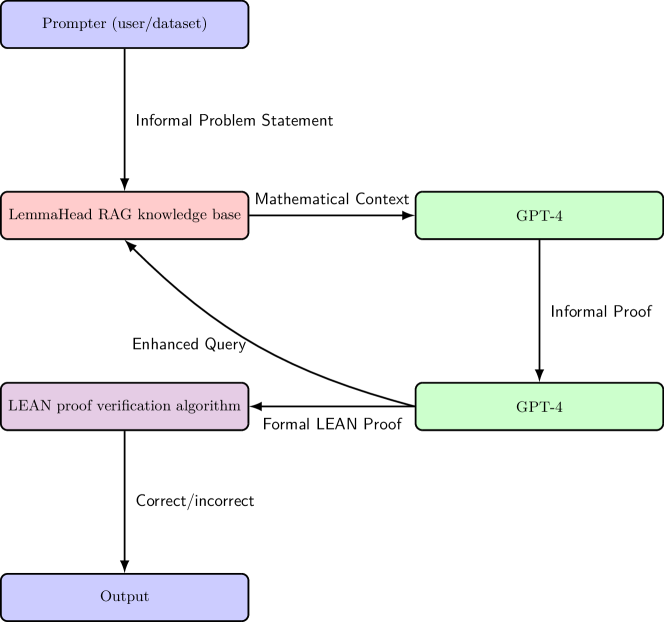
RAG pipeline with iterative proof augmentation
-
Proof Assistants 集成:通过 API 调用 Lean、Coq、Isabelle 等证明助手,在模型生成证明步骤后进行自动化验证,形成闭环反馈,有效避免“生成式幻觉”(NeurIPS)。
搜索算法与自我迭代
-
蒙特卡洛树搜索 (MCTS) + 自我精炼 (Self‑Refine):MCTSr 算法利用 LLM 构建搜索树,迭代 Selection→Self‑Refine→Evaluation→Backpropagation,平衡探索与利用,在 GSM Hard、OlympiadBench 等上显著提升解题成功率(arXiv)。
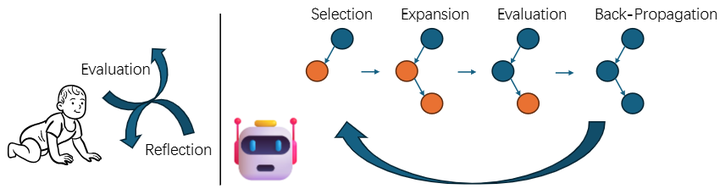
Agents can learn decision-making and reasoning from the trial-and-error as humans do.
-
能量基验证模型 (Energy Outcome Reward Model):轻量级后验证器(EORM,Energy Outcome Reward Mode),对不同推理链路进行能量评分,挑选最优输出,降低多次采样的计算成本(arXiv)。
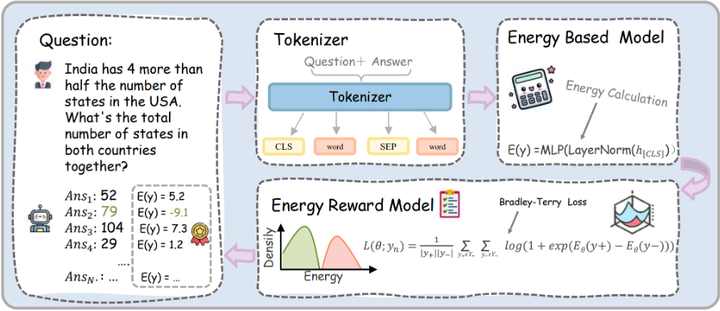
EORM
其实,代数题目与几何题目的技术路径是不相同的:
-
代数题目侧重于符号运算与逻辑推理,其核心在于: 链式思考(Chain‑of‑Thought)提示,引导模型分步推理; 程序辅助推理(Program‑Aided Reasoning),将解题的“计算”环节交由解释器(如 Python)执行,减轻模型运算负担; 自我校验与一致性过滤,通过多次采样与一致性投票(Self‑Consistency)或强化学习中的自我验证(Self‑Verify RL)提升正确率。
-
几何题目更强调图形与定理证明,其核心在于: 神经‑符号融合(Neuro‑Symbolic),结合神经网络的直觉与符号引擎的严谨推理; 大规模合成数据,通过自动化生成数百万几何定理与证明,用于模型预训练或提示示例Nature; 多模态检索与形式化验证,在检索相似问题、调用证明助手(Lean/Coq)后,进行自动验证并反馈改正 。
LLM 的 IMO 解题能力不是某一项单一技术的突破,而是链式思考提示、大规模数学微调、神经符号融合、自我校验、检索增强和搜索算法多重技术的协同成果。
LLM做IMO的主要挑战
大型语言模型(LLM)在解答数学奥林匹克(IMO)题目时面临多重挑战,主要包括多步骤逻辑推理的深度与连贯性、将自然语言解答转化为可验证的形式化证明、精确的符号计算与算术能力、提示工程与上下文长度限制、以及高难度题库数据的稀缺性等问题 (arXiv, arXiv)。这些挑战互为影响,使得即便GPT‑4或更高级别的模型在某些子任务上表现优异,也难以在所有IMO题目上稳定取得高分 (garymarcus.substack.com, arXiv)。
1. 多步骤逻辑推理的复杂性
LLM需要在提示中生成长链的分步推理(Chain‑of‑Thought),但链条越长,前期步骤的微小错误就会被放大,导致最终结论偏离正确答案 (arXiv, Medium)。即使使用分段生成或多次验证,也无法完全避免“推理漂移”现象 (arXiv)。
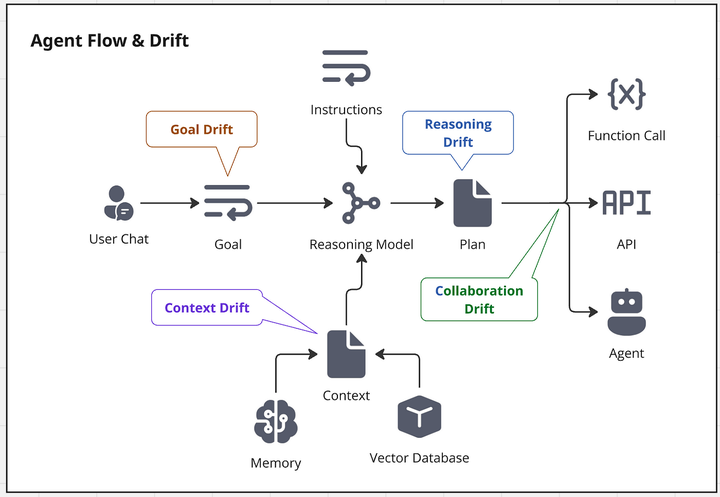
Agent Flow & Drift
2. 形式化证明与符号推理差距
IMO题目通常要求提交严格的书面证明,而LLM以自然语言生成的答案难以直接映射到Lean、Coq等形式化系统,需要额外的解析与转换步骤 (Google DeepMind, OpenReview)。神经‑符号混合系统虽能缓解此问题,但也带来了工程复杂度的上升 (Medium)。
3. 提示工程及上下文长度限制
IMO题目往往包含长段文字描述和多个子问,超出当前LLM的上下文窗口或导致提示被截断。此外,设计有效的零样本或少样本提示以覆盖所有题意细节,也是一大挑战 (Medium, arXiv)。以下表格统计了主流大型语言模型(LLM)在提示工程支持与上下文长度限制方面的对比:
| 模型 | 最大上下文长度 | 主要提示工程/集成功能 |
|---|---|---|
| GPT‑4 | 8,192 / 32,768 tokens | 支持“系统消息”(System Message) |
| GPT‑4 Turbo | 128 000 tokens | 支持“系统消息”与插件(Plugin)调用 |
| GPT‑4o | 128 000 tokens | 多模态输入(文本/音频/图像) |
| GPT‑4.1 | 1 000 000 tokens | 增强型指令遵循(更可控的指令响应) |
| Claude 2.1 | 200 000 tokens | 支持自定义指令(Custom Instructions) |
| Gemini 1.5 | 最多测试到1 000 000 tokens | 标准系统消息 + 工具调用 |
4. 数据稀缺与过拟合风险
高质量的IMO训练数据极为有限,公开可用的正式答案也常滞后或不完整,LLM在此类题库上微调时容易过拟合到少量示例,导致泛化能力下降 (garymarcus.substack.com, arXiv)。
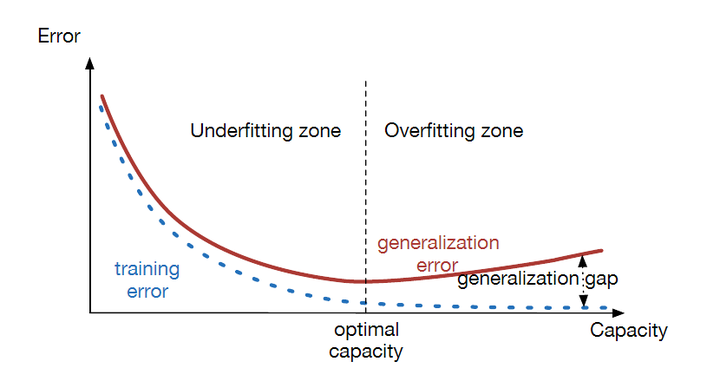
The Relationship Between Model Capacity, Training Error, and Generalization Error
5. 自动评估与一致性问题
当前评测多依赖人工评分或部分自动化系统,难以实时反馈LLM的推理细节。不同评估标准间存在差异,也会影响对模型能力的准确判断 (Reuters, Business Insider)。
总体来看,LLM在IMO级别的数学推理中已经展现出惊人潜力,但要实现完全自主、稳定地解答高难度数学竞赛题目,模型还需在逻辑连贯性、符号精度、形式化验证管线和提示设计等方面进一步突破。

















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









