






大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。而检索增强生成(RAG, Retrieval-Augmented Generation)则巧妙地整合从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
什么是大语言模型(LLM)
大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。我们一般说的LLM 通常指包含数百亿(或更多)参数的语言模型,它们在海量的文本数据上进行训练,从而获得对语言深层次的理解。
与之对应的还有VLM(Visual Language Model),也称为视觉语言模型,是一种结合了视觉信息处理和语言理解的人工智能模型。这种模型不仅能够处理文本数据,还能理解和生成与图像相关的描述,实现图像和文本之间的语义关联。VLM通常用于任务如图像标注、视觉问答(Visual Question Answering, VQA)和多模态翻译等。通过整合视觉和语言信息,VLM能够提供更为丰富和准确的语言生成和理解能力。
为了探索性能的极限,许多研究人员开始训练越来越庞大的语言模型,例如拥有 1750 亿参数的 GPT-3 和 5400 亿参数的 PaLM 。尽管这些大型语言模型与小型语言模型(例如 3.3 亿参数的 BERT 和 15 亿参数的 GPT-2)使用相似的架构和预训练任务,但它们展现出截然不同的能力,尤其在解决复杂任务时表现出了惊人的潜力,这被称为“涌现能力”。以 GPT-3 和 GPT-2 为例,GPT-3 可以通过学习上下文来解决少样本任务,而 GPT-2 在这方面表现较差。因此,科研界给这些庞大的语言模型起了个名字,称之为“大语言模型(LLM)”。LLM 的一个杰出应用就是 ChatGPT ,它是 GPT 系列 LLM 用于与人类对话式应用的大胆尝试,展现出了非常流畅和自然的表现。
LLM 的能力与特点
区分大语言模型(LLM)与以前的预训练语言模型(PLM)最显著的特征之一是它们的涌现能力 。涌现能力是一种令人惊讶的能力,它在小型模型中不明显,但在大型模型中特别突出。类似物理学中的相变现象,涌现能力就像是模型性能随着规模增大而迅速提升,超过了随机水平,也就是我们常说的量变引起质变。
涌现能力可以与某些复杂任务有关,但我们更关注的是其通用能力。接下来,我们简要介绍三个 LLM 典型的涌现能力:
-
**上下文学习:**上下文学习能力是由 GPT-3 首次引入的。这种能力允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
-
**指令遵循:**通过使用自然语言描述的多任务数据进行微调,也就是所谓的 指令微调。LLM 被证明在使用指令形式化描述的未见过的任务上表现良好。这意味着 LLM 能够根据任务指令执行任务,而无需事先见过具体示例,展示了其强大的泛化能力。
-
**逐步推理:**小型语言模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然而,LLM 通过采用 思维链(CoT, Chain of Thought) 推理策略,利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。据推测,这种能力可能是通过对代码的训练获得的。
这些涌现能力让 LLM 在处理各种任务时表现出色,使它们成为了解决复杂问题和应用于多领域的强大工具。
LLM 的特点
大语言模型具有多种显著特点,这些特点使它们在自然语言处理和其他领域中引起了广泛的兴趣和研究。以下是大语言模型的一些主要特点:
-
**巨大的规模:**LLM 通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
-
**预训练和微调:**LLM 采用了预训练和微调的学习方法。首先在大规模文本数据上进行预训练(无标签数据),学习通用的语言表示和知识。然后通过微调(有标签数据)适应特定任务,从而在各种 NLP 任务中表现出色。
-
上下文感知: LLM 在处理文本时具有强大的上下文感知能力,能够理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。
-
多语言支持: LLM 可以用于多种语言,不仅限于英语。它们的多语言能力使得跨文化和跨语言的应用变得更加容易。
-
多模态支持: 一些 LLM 已经扩展到支持多模态数据,包括文本、图像和声音。使得它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
-
伦理和风险问题: 尽管 LLM 具有出色的能力,但它们也引发了伦理和风险问题,包括生成有害内容、隐私问题、认知偏差等。因此,研究和应用 LLM 需要谨慎。
-
高计算资源需求: LLM 参数规模庞大,需要大量的计算资源进行训练和推理。通常需要使用高性能的 GPU 或 TPU 集群来实现。
检索增强生成 RAG 简介
大型语言模型(LLM)相较于传统的语言模型具有更强大的能力,然而在某些情况下,它们仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,研究人员提出了一种新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
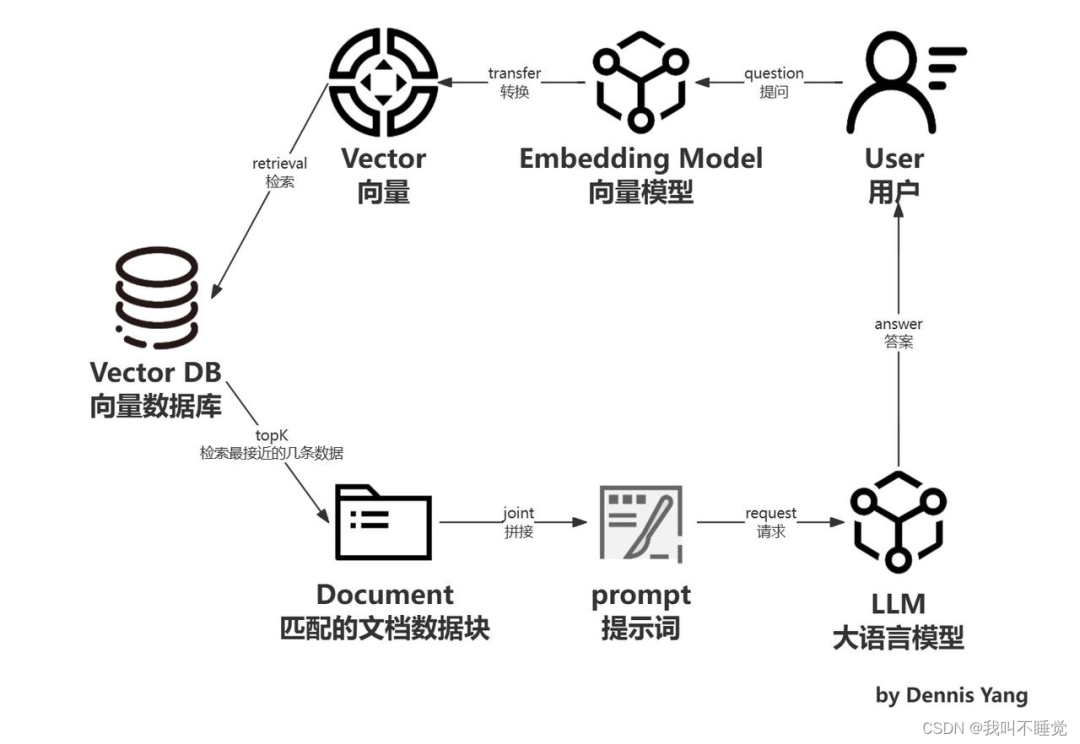
RAG 是一个完整的系统,其工作流程可以简单地分为数据处理、检索、增强和生成四个阶段:
1. 数据处理阶段
-
对原始数据进行清洗和处理。
-
将处理后的数据转化为检索模型可以使用的格式。
-
将处理后的数据存储在对应的数据库中。
2. 检索阶段
将用户的问题输入到检索系统中,从数据库中检索相关信息。
3. 增强阶段
对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。
4. 生成阶段
将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
RAG VS Finetune
微调: 通过在特定数据集上进一步训练大语言模型,来提升模型在特定任务上的表现。
|
特征 |
RAG |
微调 |
|
输入与反馈 |
自动筛选和综合知识库,无需重新训练。信息呈现方式灵活,适合满足实际的数据需求。 |
通常需要重新训练或者使用特定的数据集来训练模型。模型的灵活性和适应性较差。 |
|
外部知识引入 |
通过长周期的部署演进,持续迭代会为模型导入他们的专业/非专有化数据库。 |
将外部知识学习到 LLM 内部。 |
|
数据处理 |
对数据的处理和操作要求低。 |
依赖于构建高质量的数据集,有限的数据集可能会导致信息泛化性差。 |
|
模型可定制 |
借助于信息检索和融合的智能知识,但可能无法完全定制模型行为或与行业相关。 |
可以根据特定区域或者情境定制 LLM 行为,与行业相关性更强。 |
|
可解释性 |
可以透明引入体外数据来源,有较好的可解释性和可追溯性。 |
黑盒子,可解释性相对较低。 |
|
计算资源消耗 |
需要密切的资源投资支持大规模知识库的建立和维护。 |
依赖高昂的训练资源来维护和训练模型,对计算资源的要求较高。 |
|
推理速度 |
增加了检索步骤的耗时。 |
单纯 LLM 在完成的速度。 |
|
应用场景 |
适用于检索到的真实信息包括政治、医疗等产业领域的模型。 |
模型学习特定领域的数据能力较为灵活,但面对未见过的场景时仍可能出现不准确。 |
|
信息更新频率 |
体系和使用外部数据源可自动化定期和不间断的更新。 |
川流数据中的敏感信息管理严格性较低,以防泄露。 |

















 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









