








Harmonizing Visual Text Comprehension and Generation
论文:
https://arxiv.org/abs/2407.16364v1
前排提示,文末有大模型AGI-优快云独家资料包哦!
TextHarmony 是由华东师范大学和字节跳动的研究人员共同开发的一款多模态生成模型,它在视觉文本理解与生成领域展现出卓越的能力。该模型通过创新的Slide-LoRA技术,有效解决了在单一模型中同时生成图像和文本时遇到的性能下降问题。Slide-LoRA通过动态聚合特定于模态和模态无关的低秩适应(LoRA)专家,实现了在保持参数增加极小化的同时,提高了模型对视觉和语言模态的生成一致性。
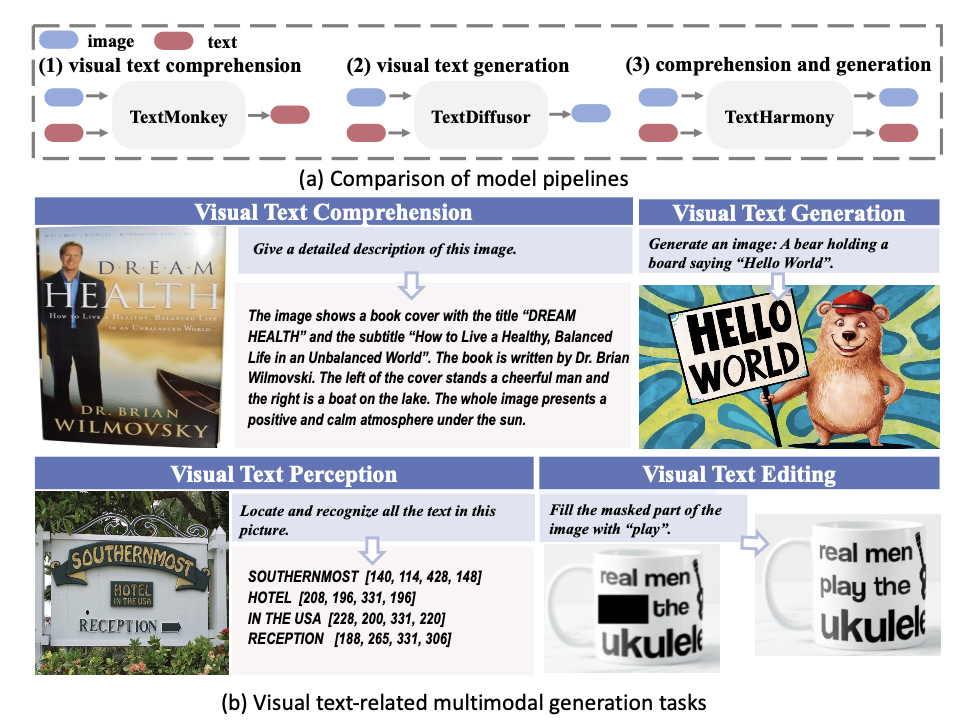
TextHarmony 能够处理多种以文本为中心的多模态任务,包括文本检测、识别、视觉问答(VQA)、关键信息提取(KIE)以及视觉文本的生成、编辑和擦除等。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









