






在今年 7 月 4 日举行的 2024 WAIC 科学前沿主论坛上,书生·万象多模态大模型(InternVL 2.0)正式发布,并陆续开源了 1B、2B、4B、8B、26B、40B 以及 76B 共 7 个参数版本的模型。目前 IntenVL2 系列模型在 Hugging Face 平台上的下载量已超 160 万,其中 InternVL2-1B 下载量接近 100 万,可谓是“社区用户最喜爱的模型”!
开源链接:(欢迎 star)
https://github.com/OpenGVLab/InternVL
模型链接:(文末点击阅读原文可直达,欢迎使用)
https://huggingface.co/collections/OpenGVLab/internvl-20-667d3961ab5eb12c7ed1463e
今天就给大家重点介绍下如何使用 XTuner 微调 InternVL2 系列模型,以 微调 InternVL-1B 使之具有给表情包配上内涵梗文的能力 为例。无基础小白或者初入门的新手都适用,赶紧学习起来吧!
微调教程来自社区用户投稿,作者:小鲶鱼。
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。高效支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。
使用 XTuner 微调的总体步骤为:
-
下载 XTuner 源码,安装源码所需依赖
-
下载 InternVL2-1B 模型,下载或者制作 VLM 数据集
-
修改微调训练的参数
-
输入微调命令,开始微调
-
可视化监控
-
模型合并
-
微调后模型的推理测试
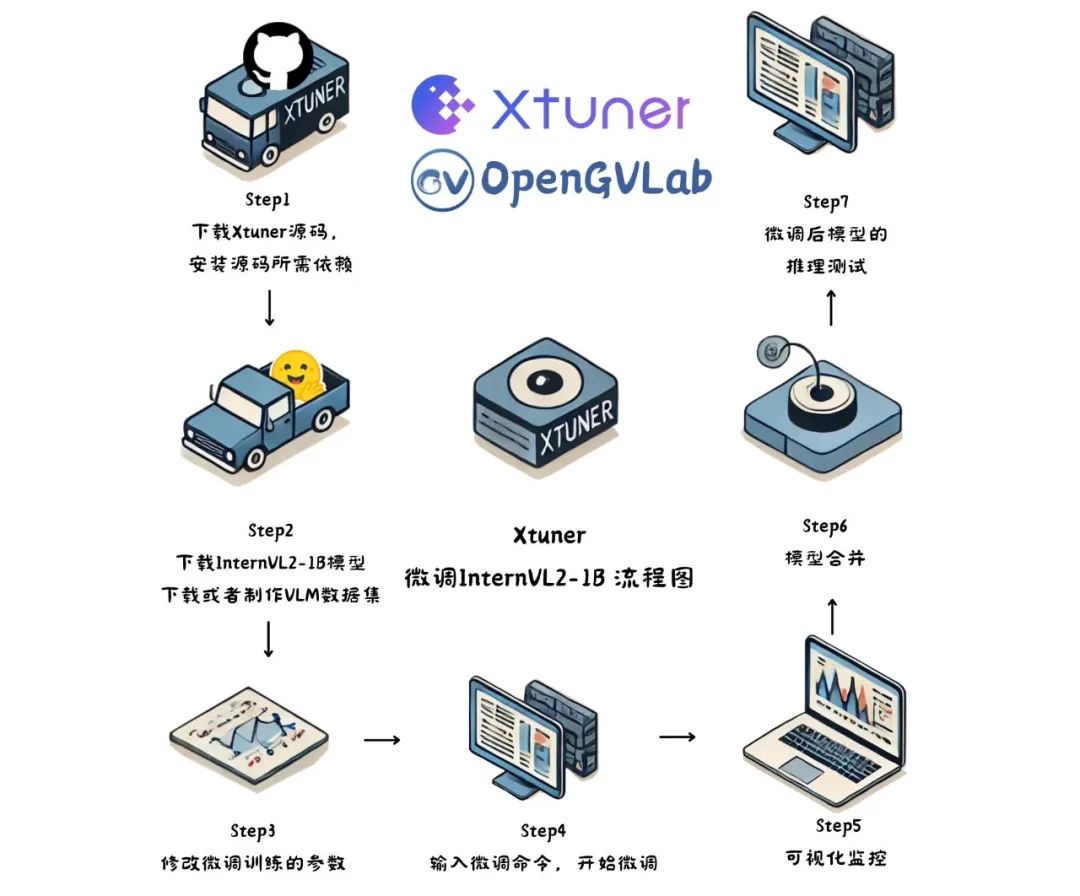
微调流程图
1. 下载 XTuner 源码,安装源码所需依赖
下载源码:
# 创建一个目录,用来存放源代码``mkdir -p /root/code`` ``cd /root/code``git clone -b v0.1.23 https://github.com/InternLM/XTuner
安装所需依赖的时候,为了避免 XTuner 项目的包跟其他项目的包产生冲突,需要新建一个虚拟环境并激活。在虚拟的环境里安装依赖。
比如有的项目需要 Numpy<2.0,但是有的项目需要 Numpy>2.0,那么就冲突了。
创建虚拟环境:
conda create --name xtuner python=3.10 -y`` ``# 激活虚拟环境(注:后续的所有操作都需要在这个虚拟环境中进行)``conda activate xtuner`` ``# 安装torch和torch系列的库,torch是深度学习框架,AI项目大部分都是基于这个框架的``conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y``# 安装其他依赖``apt install libaio-dev -y``pip install transformers==4.39.3 streamlit==1.36.0 lmdeploy==0.5.3
安装 XTuner 所需依赖:
cd /root/code/XTuner``pip install -e '.[deepspeed]'
安装完毕后,测试 XTuner 相关的命令能否生效:
xtuner version # 查看xtuner的版本`` ``xtuner help # 查看xtuner的一系列命令
2. 下载 InternVL2-1B 模型,
下载或者制作 VLM 数据集
下载 InternVL2-1B 模型
cd /root``mkdir -p model`` ``# 安装huggingface-hub库,方便从hf里下载或上传文件``pip install huggingface-hub``# 从hf的OpenGVLab/InternVL2-1B仓库里下载模型到本地的/root/model/InternVL2-1B文件夹``huggingface-cli download OpenGVLab/InternVL2-1B --local-dir /root/model/InternVL2-1B
如果下载失败,则设置环境变量 HF_ENDPOINT,从 hf 的镜像站下载模型:
export HF_ENDPOINT=https://hf-mirror.com``huggingface-cli download OpenGVLab/InternVL2-1B --local-dir /root/model/InternVL2-1B

下载或者制作 VLM 数据集
这一步比较重要,如果用现成的数据集,也需要把格式准备正确了。如果自己去爬取图片,然后自己人工标注,则爬取和标注过程都比较花时间,是注入“智能”的过程。
InternVL2 系列模型所需的数据集格式为:图片文件夹+索引目录 json 文件。
其中 json 文件的格式如下:
[` `{` `"id": "11", # id也可以不设置` `"image": "ex_images/MjxjVcrFf9ReweWibHwWQsM2iaiajJd0GQvFPsMPic79PnZGffSNfdVTQV9Z5J4FW1XciaIibRoosGuIfSPaFBuADCQA.jpg",` `"conversations": [` `{` `"from": "human",` `"value": "<image>\n请你用中文描述一下这张图片"` `},` `{` `"from": "gpt",` `"value": "你嘴里啃的是什么!我问你嘴里啃的是什么!"` `}` `]` `},` `{` `"id": "22",` `"image": "ex_images/007aPnLRgy1hb39z0im50j30ci0el0wm.jpg",` `"conversations": [` `{` `"from": "human",` `"value": "<image>\nDescribe this image in English"` `},` `{` `"from": "gpt",` `"value": "Ok Doge"` `}` `]` `},` `]
如果要自己构建数据集,可以先爬取符合自己要求的图片,然后标注的内容保存为同名的 txt 文件。之后写一个 python 脚本把这些图文数据对给创建一个 json 格式的索引目录。如果是代码小白,可以写好要求,让 GPT 来帮自己完成这个脚本。
好在 Hugging Face 上的 zhongshsh/CLoT-Oogiri-GO 数据集恰好符合 InternVL2-1B 的格式,因此可以直接下载后使用。CLoT-Oogiri-GO 数据集是一个表情包和梗文的配套数据集,有2000多张图。
数据集地址:https://huggingface.co/datasets/zhongshsh/CLoT-Oogiri-GO
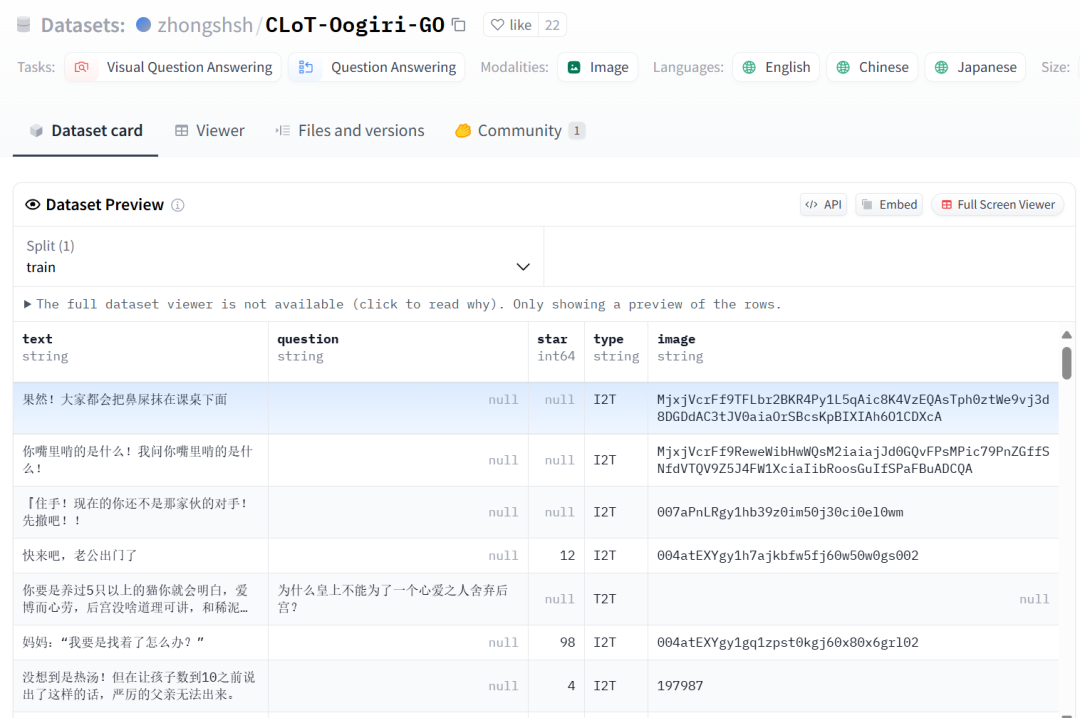
由于里面的数据包含 Text2Text、Image2Text 等多种类型,图片数量一共有 3 万多张,数据量有些大。作为轻量型的 demo,需要对其进行筛选,筛选出 2000 多张图片。筛选后的数据集,我上传到了 modelscope 数据集里:https://www.modelscope.cn/datasets/livehouse/CLoT_cn_2000/files
下载 CLoT_cn_2000 数据集的代码为:
cd /root/code``mkdir datasets`` ``pip install modelscope # modelscope包,用来往modelscope下载上传文件`` ``# 把数据集放在/root/code/datasets里``modelscope download livehouse/CLoT_cn_2000 --repo-type dataset --local_dir /root/code/datasets
下载完成后需要解压:
cd /root/code/datasets``unzip ./CLoT_cn_2000.zip -d ./

笔者测试的时候`unzip ./CLoT_cn_2000.zip -d ./CLoT_cn_2000`多加了个 CLoT_cn_2000,导致嵌套了
测试 InternVL2-1B 的推理效果
下载完数据集了,先从里面找一张图来用 InternVL2-1B 模型推理一下看看效果:
随机选择了 /root/code/datasets/CLoT_cn_2000/ex_images/007aPnLRgy1hb39z0im50j30ci0el0wm.jpg 图片,对它进行 Image-to-Text 的推理。
from lmdeploy import pipeline``from lmdeploy.vl import load_image`` ``pipe = pipeline('/root/model/InternVL2-1B')`` ``image = load_image('/root/code/datasets/CLoT_cn_2000/ex_images/007aPnLRgy1hb39z0im50j30ci0el0wm.jpg')``response = pipe(('请你根据这张图片,讲一个脑洞大开的梗', image))``print(response.text)
上面的代码是使用 InternVL2-1B 模型对目标图片进行 Image2Text 单图推理的代码。
用下面的代码创建一个空的 test.py 文件,然后把上面代码粘贴进去,再执行这个代码即可。
touch /root/code/test.py # 创建空文件
粘贴后,再 Ctrl+S 保存一下 test.py 文件,之后运行这个代码:
python /root/code/test.py
图片和图片推理的结果如下:
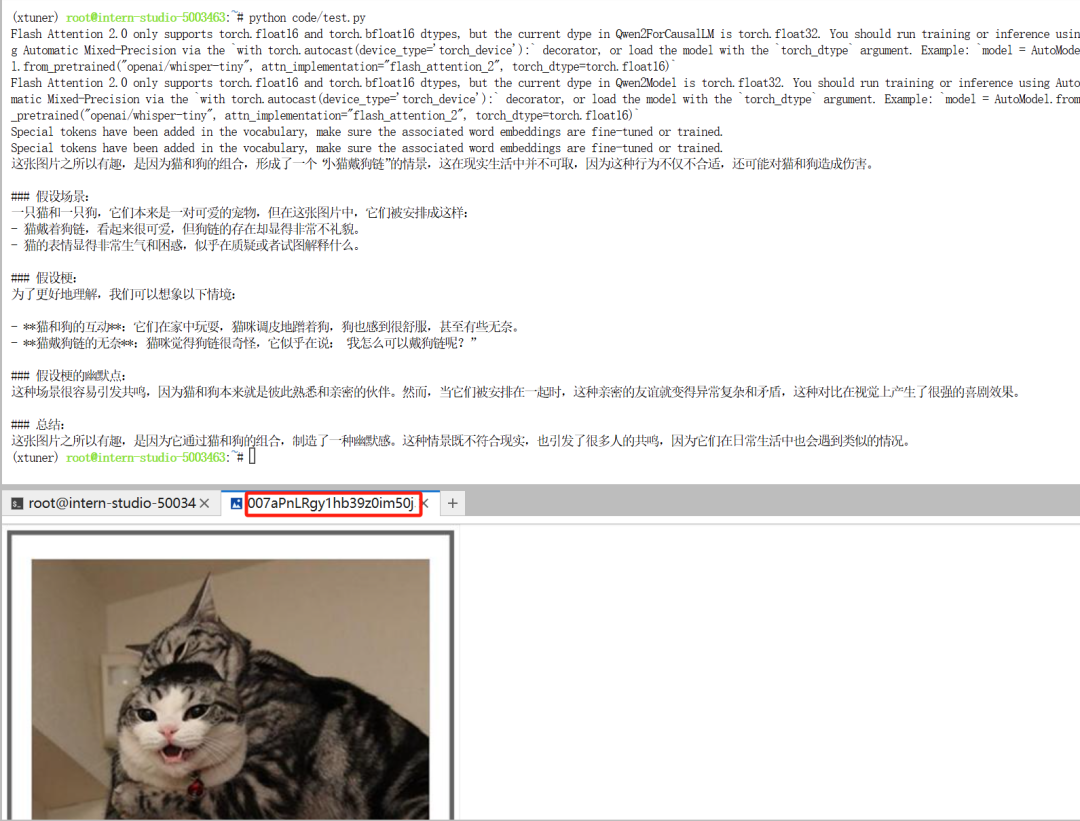
下方是表情包数据集里的测试图,上方是 InternVL2-1B 对该图的推理结果。从文字回答可以看出 InternVL2-1B 目前还没法胜任"表情包配梗"的任务。
正是因为这个特定的“表情包配梗”任务无法被 VLM 实现,所以才要构建表情包数据集,之后用它来微调 VLM 模型。
3. 修改微调训练的参数
/root/code/XTuner/xtuner/configs/internvl/v2 文件夹里,有一个 internvl_v2_internlm2_2b_qlora_finetune.py 文件,这个文件是用 qlora 方法去微调 InternVL2 系列模型的一个脚本。
这里有训练的参数,按要求修改之后,再执行这个脚本,就可以进行微调训练了!
这个训练脚本要修改的参数有:
-
模型路径
-
训练集路径
-
批次大小
-
训练轮数
-
学习率
-
保存间隔
-
可视化
-
甚至调度器 scheduler、优化器 optimizer、返回点 resume
基础部分就只介绍前7个参数。
3.1 修改模型路径与训练集的路径
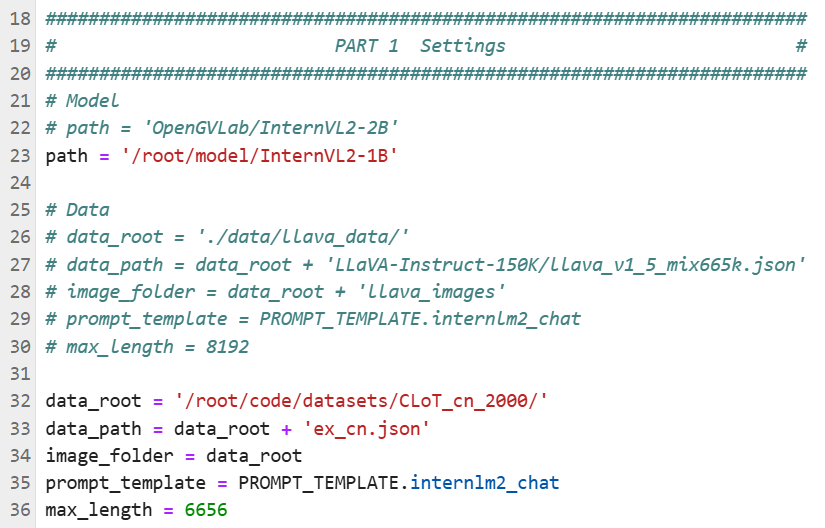
配置文件里的模型路径与训练集路径
这个 internvl_v2_internlm2_2b_qlora_finetune.py 的脚本文件虽然文件名上包含 2b,实际上对于 InternVL2 系列的任意参数量的模型都能用,只需要 path 进行正确赋值即可。
#######################################################################``# PART 1 Settings #``#######################################################################``# Model``# path = 'OpenGVLab/InternVL2-2B'``path = '/root/model/InternVL2-1B'`` ``# Data``# data_root = './data/llava_data/'``# data_path = data_root + 'LLaVA-Instruct-150K/llava_v1_5_mix665k.json'``# image_folder = data_root + 'llava_images'``# prompt_template = PROMPT_TEMPLATE.internlm2_chat``# max_length = 8192``data_root = '/root/code/datasets/CLoT_cn_2000/'``data_path = data_root + 'ex_cn.json'``image_folder = data_root``prompt_template = PROMPT_TEMPLATE.internlm2_chat``max_length = 6656
3.2 修改批次大小、训练轮数、学习率和保存间隔
对应的参数分别是 batch_size 和 accumulative_counts、max_epochs、 lr 以及 save_steps。
# Scheduler & Optimizer``batch_size = 4 # per_device``accumulative_counts = 2``dataloader_num_workers = 4``max_epochs = 4``optim_type = AdamW``# official 1024 -> 4e-5``# lr = 1e-5``lr = 2e-5``betas = (0.9, 0.999)``weight_decay = 0.05``max_norm = 1 # grad clip``warmup_ratio = 0.03`` ``# Save``# save_steps = 1000``save_steps = 100``# save_total_limit = 1 # Maximum checkpoints to keep (-1 means unlimited)``save_total_limit = -1
批次大小
真实的批次大小是 per_device_batch_size = batch_size*accumulative_counts,这里暂时设置batch_size = 4、accumulative_counts = 2。
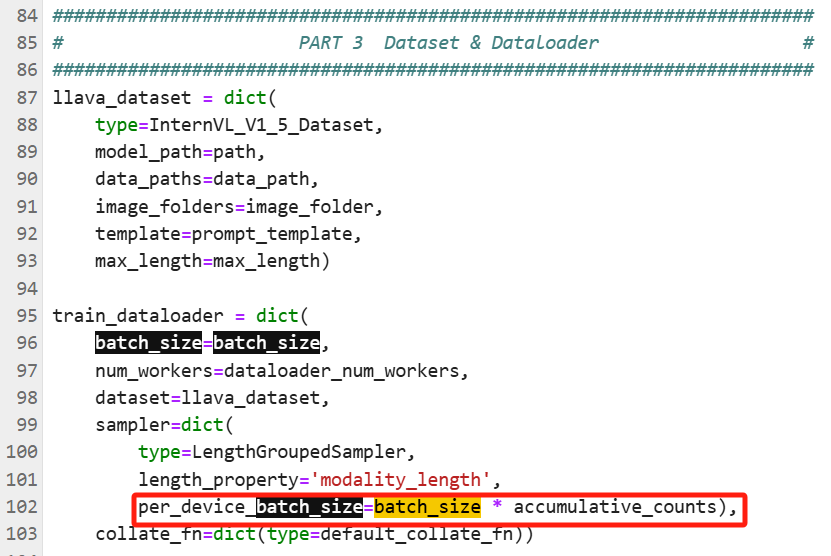
训练脚本文件 /root/code/XTuner/xtuner/configs/internvl/v2 /internvl_v2_internlm2_2b_qlora_finetune.py 里,这两个参数跟批次大小相关的内容为:
# Scheduler & Optimizer``# batch_size = 8 # per_device``batch_size = 4``accumulative_counts = 2
-
训练脚本里 batch_size 默认值是 8,太大了。后面实测,batch_size = 4、 accumulative_counts = 2 的时候已经吃了 40G 显存了。
-
如果是 8G 显存,建议这两个参数都赋值为 1。否则会 CUDA Out of Memory。
训练轮数
max_epochs 这个参数是最大训练轮数,/root/code/XTuner/xtuner/configs/internvl/v2 /internvl_v2_internlm2_2b_qlora_finetune.py 里,这个参数默认值是 1:
# max_epochs = 1``max_epochs = 4
这个只训练 1 轮基本是不足的,因为图片本身就 2000 张,不够多。还是要多训练几轮,确保训练的过程更加充分。训练的过程是拟合的过程,一个训练集来回多训练几遍,确保拟合到位。
训练轮数(max_epochs)越高,拟合程度就越高。
-
训练轮数太低,不拟合(模型回答问题不准确)。
-
训练轮数太高,则会过拟合(模型只能正确回答训练集里的问题;用其他的问题去提问,也只能得到训练集里写好的标注)。
如果图片有上百万张,那么 max_epochs = 1 也没问题。
对于拟合的举例解释:拟合的意思是让模型的预测值更加靠近真实值。
比如用面积x预测房价y的模型,训练集里有很多个(x1,y1),(x2,y2),…,(xk,yk),…,(xn,yn)的坐标点,这些坐标组成散点图,拟合出一条曲线或者直线,拟合的解析式为y=f(x),这就是一次拟合。
那么这个y=f(x)可以看成是模型。对于面积xk,模型预测的值是f(xk),真实值是yk,如果f(xk)离yk很近,那么从这个xk的数据来看,拟合程度就很高。
这时候对于 xk 定义一个 loss_xk = f(xk) - yk,那么对于 x1,x2,…,xk,…,xn,就有loss_x1, loss_x2, …, loss_xk, …, loss_xn,这 n 个 loss。给他们取平均值,得到Loss。如果这个 Loss 最小化,就说明这个拟合最到位。因此拟合的过程又演变为 Loss 下降的过程。
学习率
lr 是 learning rate 的缩写,也就是学习率。在训练脚本 /root/code/XTuner/xtuner/configs/internvl/v2 /internvl_v2_internlm2_2b_qlora_finetune.py 里,这个参数默认值是 lr = 1e-6。这个1e-6的值可以先用着,如果发现跑完一轮训练,Loss 下降得不明显,那么需要给 lr 提高。
Loss 下降从哪里观察:
进行训练的时候命令行的日志里会显示 Loss 值
训练过程的可视化图表也会有 Loss 的变化曲线
我还是习惯用 10^-4 数量级的 lr 作为开局的 lr:
# official 1024 -> 4e-5``# lr = 1e-6``lr = 2e-4
学习率可以理解为训练过程(拟合过程、Loss 下降过程)的拟合速度。学习率越高,拟合得越快(相当于 Loss 下降的越快)。
-
lr 比较大,可以快速拟合,往往几轮训练就拟合到位了。
-
lr 比较小,拟合的速度比较慢,但是拟合比较精细,一些个体数据的特征也能照顾到位。
保存间隔
save_steps,这个参数的意思是保存间隔,每多少步保存一个 lora 模型。训练脚本 /root/code/XTuner/xtuner/configs/internvl/v2 /internvl_v2_internlm2_2b_qlora_finetune.py 里设置的默认值是 1000:
# Save``# save_steps = 1000``save_steps = 100``# save_total_limit = 1 # Maximum checkpoints to keep (-1 means unlimited)``save_total_limit = -1
我这里修改为 save_steps = 100 和 save_total_limit = -1。
-
save_total_limit要从 1 改为 -1。如果这个值为 1,那么 iter_200.pth 生成之后,iter_100.pth 就会删掉,后面依此类推。
-
保存间隔 save_steps 的设置,建议新手设置为 save_steps = 100,然后看训练过程中,保存的“训练结果”的次数是高频还是低频。如果保存的频率太高,那再手动删掉一些即可。
这个保存间隔,需要计算本次训练一共要训练多少步。假如某次训练一共训练 1000 步,这个保存间隔如果是 1000 的话,就不合适了。因为训练过程的中间状态就无法保存,无法达到“间隔”的目的。
-
训练结果,就是训练出来的 lora 模型。这些结果会保存在 /root/code/qlora_output 里,是一系列 iter_100.pth, …, iter_1000.pth,iter_2000.pth 这种的后缀为 pth 的文件。这些训练结果可以称为 lora 模型,它的学名叫做适应层(Adaptation)。这些适应层只有跟大模型合并了,才是完整的模型。
-
如果训练了一个小时,一下子出来了 100 多个 iter_x00.pth 模型,那就跳着删掉一些。如果出来了 10 多个 lora 模型,那 save_steps = 100 就是一个合理的保存间隔。
这里做一个总训练步数的计算示例,感兴趣的可以读一下:
我的训练集里有 2000 个图文对的数据,由于显存的限制,无法 2000 张图和标注同时进入模型进行拟合。拟合,可以用之前用面积 x 预测房价 y 的模型组成散点图拟合曲线的那个例子去理解。
于是要拆开,分批进去。如果批次大小是 8,那么 2000 个图文就拆分成 250 批,每批 8 个图文对。每一批数据进入模型后,都要进行一次拟合(散点图新增8个点,修正一次拟合曲线,就是一次新的拟合)。
这一次拟合就是一次迭代。迭代是 iteration,训练的过程就是一次次拟合(迭代)的过程,所以保存文件有个 iter 的前缀。
当 250 批数据全部进入模型,拟合一遍之后,才算完成了一轮训练。
上面两段介绍了一步迭代和一轮训练的过程。那么假如我现在的训练集里的图文数据是 2000 个,batch_size =4、accumulative_counts = 2、max_epochs = 4。对于一轮训练来说,2000个数据,拆分为 250 批,每批 8 个图文对进入模型进行拟合。每一批都是一次迭代,因此 250 批就是 250 个迭代。所以一轮训练要迭代 250 次。一共 4 轮训练,所以整个训练需要迭代 1000 次。
3.3 修改可视化参数
在脚本里 Ctrl+F 检索 visualizer,可以看到 visualizer = None 的一行代码,把它替换为下面的代码:
# visualizer = None`` ``visualizer = dict(` `type=Visualizer,` `vis_backends=[` `dict(type=WandbVisBackend, init_kwargs=dict(project='internvl2-example'))])
启用 Wandb 可视化,需要开一个终端在 XTuner 的虚拟环境里安装 wandb 库,并登陆 wandb 账号:
conda activate xtuner``pip install wandb``wandb login
在 wandb login 那一步,需要用 wandb 的登陆密钥,需要进入 https://wandb.ai/ 注册一下,注册后进入https://wandb.ai/authorize,复制登陆密钥后,回到命令行里,粘贴并回车即可登陆到 wandb。
之后运行脚本的时候,可视化部分的 wandb 才能正常工作。
这样训练过程的数据就会传输到 wandb 这个网站,开启训练后,命令行会提示查看训练曲线的网址:
wandb 可视化的 project 地址
绘制得到可视化曲线,比如下面这样:
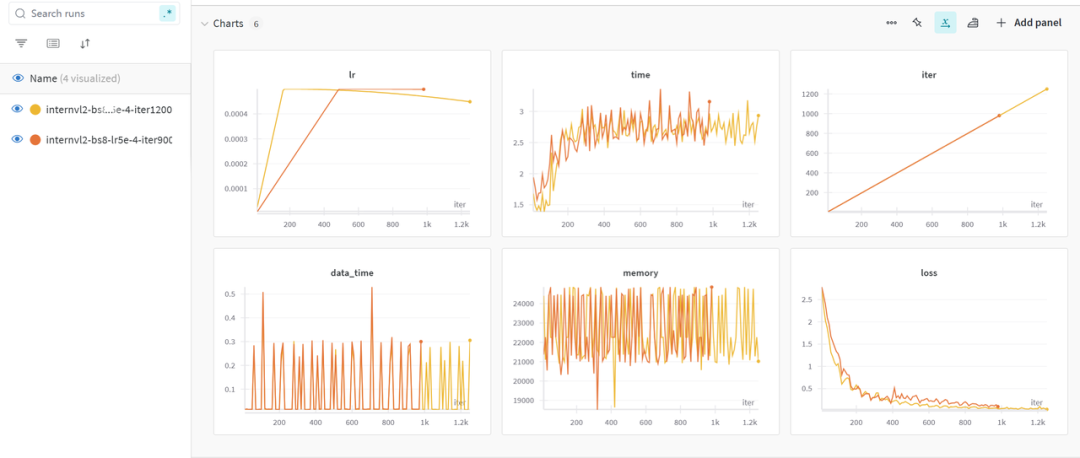
wandb 的可视化效果
有了可视化曲线,可以便捷地观察 lr、loss 曲线,还有训练总步数也能一目了然。如果不需要这个可视化曲线,可以保持 visualizer = None 不变。
4. 输入微调命令,开始微调
使用 xtuner train 命令开始微调:
conda activate xtuner``NPROC_PER_NODE=1 xtuner train /root/code/XTuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_qlora_finetune.py --work-dir /root/code/qlora_output --deepspeed deepspeed_zero1
1B 模型跟 2B 的 Language Part 不一样,直接执行微调命令,会有一个 NotImplementedError 的报错:
after_test:``(VERY_HIGH ) RuntimeInfoHook` `--------------------` `after_run:``(BELOW_NORMAL) LoggerHook` `--------------------` `Traceback (most recent call last):` `File "/root/InternLM/code/XTuner/xtuner/tools/train.py", line 360, in <module>` `main()` `File "/root/InternLM/code/XTuner/xtuner/tools/train.py", line 356, in main` `runner.train()` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/_flexible_runner.py", line 1160, in train` `self._train_loop = self.build_train_loop(` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/_flexible_runner.py", line 958, in build_train_loop` `loop = LOOPS.build(` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/registry.py", line 570, in build` `return self.build_func(cfg, *args, **kwargs, registry=self)` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 121, in build_from_cfg` `obj = obj_cls(**args) # type: ignore` `File "/root/InternLM/code/XTuner/xtuner/engine/runner/loops.py", line 32, in __init__` `dataloader = runner.build_dataloader(` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/runner/_flexible_runner.py", line 824, in build_dataloader` `dataset = DATASETS.build(dataset_cfg)` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/registry.py", line 570, in build` `return self.build_func(cfg, *args, **kwargs, registry=self)` `File "/root/.conda/envs/xtuner/lib/python3.10/site-packages/mmengine/registry/build_functions.py", line 121, in build_from_cfg` `obj = obj_cls(**args) # type: ignore` `File "/root/InternLM/code/XTuner/xtuner/dataset/internvl_dataset.py", line 160, in __init__` `raise NotImplementedError``NotImplementedError
找到 /root/code/XTuner/xtuner/dataset/internvl_dataset.py 的 160 行,其内容为:
`if self.cfg.llm_config.architectures[0] == 'Phi3ForCausalLM':` `self._system = 'You are an AI assistant whose name is Phi-3.'` `self.template[` `'INSTRUCTION'] = '<|user|>\n{input}<|end|><|assistant|>\n'` `elif self.cfg.llm_config.architectures[0] == 'InternLM2ForCausalLM':` `self._system = 'You are an AI assistant whose name ' \` `'is InternLM (书生·浦语).'` `self.template['SYSTEM'] = '<|im_start|>system\n{system}<|im_end|>'` `self.template[` `'INSTRUCTION'] = '<|im_start|>user\n{input}' \` `'<|im_end|><|im_start|>assistant\n'` `else:` `raise NotImplementedError`
由于 InternVL2-1B 的 Language Part 是 Qwen2-0.5B-Instruct,既不是 Phi3,也不是InternLM2,所以要为这个 Qwen2 新增一个判断条件:
+ elif self.cfg.llm_config.architectures[0] == 'Qwen2ForCausalLM':``+ self._system = 'You are an AI assistant whose name is Qwen2.'``+ self.template[``+ 'INSTRUCTION'] = '<|user|>\n{input}<|end|><|assistant|>\n'` `else:` `raise NotImplementedError
备注:
-
InternVL2-2B 的 Language Part 是 internlm2-chat-1_8b
-
InternVL2-4B 的 Language Part 是 Phi-3-mini-128k-instruct
-
InternVL2-8B 的 Language Part 是 internlm2_5-7b-chat
-
InternVL2-26B 的 Language Part 是 internlm2-chat-20b
-
InternVL2-40B 的 Language Part 是 Nous-Hermes-2-Yi-34B
-
InternVL2-Llama3-76B 的 Language Part 是 Hermes-2-Theta-Llama-3-70B
因此微调 2B、4B、8B、26B 模型时,不会遇到这个 NotImplementedError,但是微调 1B、40B 和 76B 的模型时,会遇到这个 NotImplementedError
修改完成后,运行微调的命令:
conda activate xtuner``NPROC_PER_NODE=1 xtuner train /root/code/XTuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_qlora_finetune.py --work-dir /root/code/qlora_output --deepspeed deepspeed_zero1
执行这个运行命令,有时候命令行会沉默几秒,卡住不动。只加载了配置 configs,一直不出现下面这种加载模型的日志:
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:05<00:00, 1.47s/it]
那就耐心等待 5 分钟,或者关掉 wandb 可视化功能(给配置文件里的 visualizer = None 取消注释)。
训练开始后,发现 batch size 是 4 * 2 = 8 的时候,占用 40G 显存。
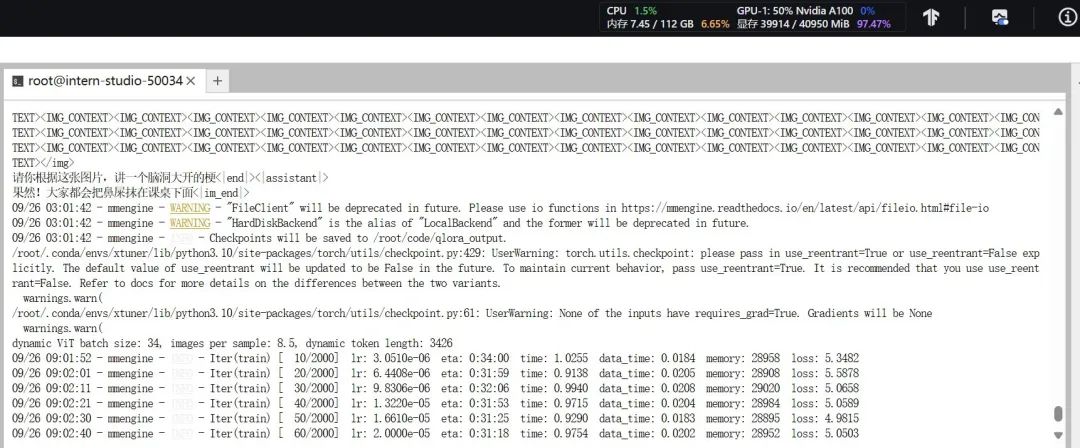
训练开始,显存占用 40G
训练完成后得到的一系列模型如下:
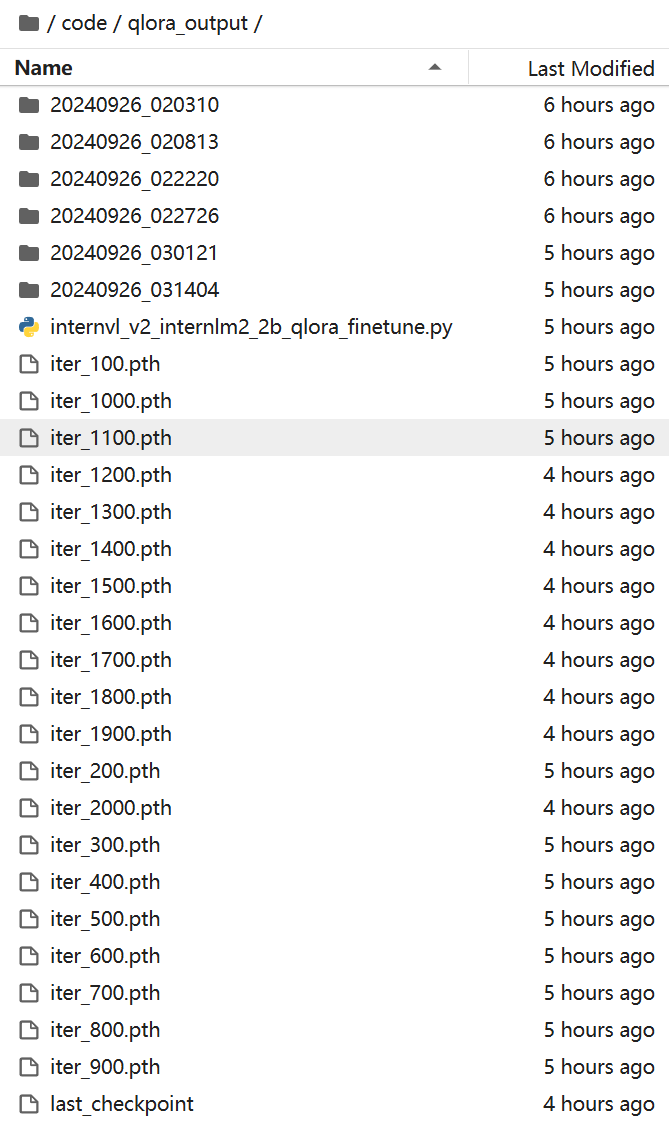
训练中间过程的 20 个 lora (每隔 100 步保存一次 lora)
一共是 2000 步迭代,并不是 之前计算的1000 步迭代。可能是代码里计算总步数的时候,使用的实际 batch size,错误地用了 batch_size 这个变量。而没有用 per_device_batch_size=batch_size * accumulative_counts) 这个变量。
在上一节保存间隔里有一个延伸计算,那里介绍了一个训练所需的迭代步数多少。从那里得到的经验,可以进行下面的计算:
如果 真实的批次大小 错误地用了 batch_size=4 这个变量,那么 2000 张图片跑完一轮,就是 500 步。那么一个 epoch 就是 500 个 iteration。我设置了 max_epochs = 4,因此跑完 4 轮,就需要 2000 个 iteration。
实际上这个 2000 个 iteration 是错误的数据,因为漏掉了 accumulative_counts 这个变量。可能是 XTuner 源代码里漏掉了accumulative_counts ,不过无伤大雅。
5. 可视化监控
打开访问命令行里的那个 wandb 的 project 网址,在训练完成后,会看到训练过程的 2000 个迭代的过程被各种曲线可视化了:
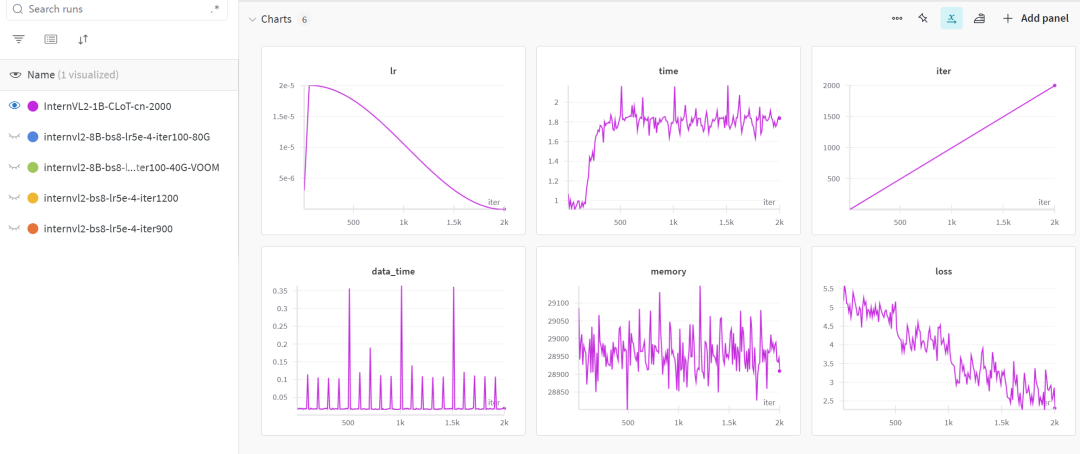
训练过程的可视化
第 1 张图 lr 是用的余弦调度器,因此 lr 从 2e- 5逐渐衰减到 0。
第 6 张图 loss 逐步下降,loss 下降到最后是第 2000 步迭代,那时候保存了 iter_2000.pth。
并非 loss 越低,拟合的效果越好。只需要基本拟合,然后修改 lr 进行进一步的细致训练。由于这里是个简单的 demo,就直接用 iter_2000.pth 进行微调后的推理测试了。
6. 模型合并
使用 /root/code/XTuner/xtuner/configs/internvl/v1_5 里的 convert_to_official.py 脚本进行合并,把 /root/code/qlora_output/iter_2000.pth 这个 lora 跟大模型合并为 /root/model 文件夹里的 InternVL2-1B-iter2000 模型:
conda activate xtuner`` ``# transfer weights``python /root/code/XTuner/xtuner/configs/internvl/v1_5/convert_to_official.py /root/code/XTuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_qlora_finetune.py /root/code/qlora_output/iter_2000.pth /root/model/InternVL2-1B-iter2000/
python ./convert_to_official.py 后面需要加入三个参数,分别是配置文件路径、lora 文件路径和保存路径,缺一不可。因为在 merge 脚本 convert_to_official.py 里需要这三个参数:
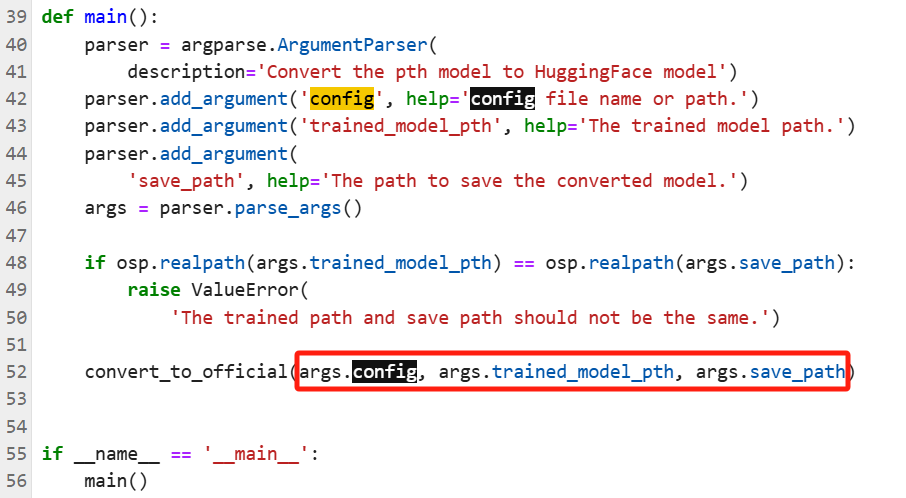
convert_to_official.py 脚本里的三个参数
运行 merge 模型的命令,得到微调后的 InternVL2-1B,命名为 InternVL2-1B-iter2000:
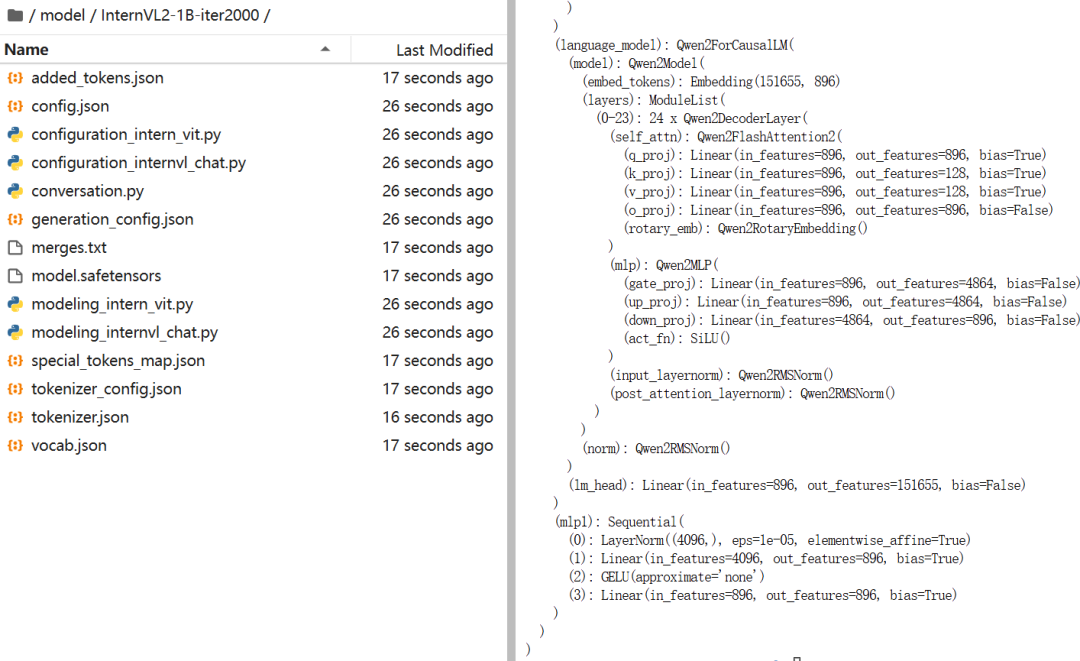
左边是合并后的模型,右边是合并脚本运行时的日志
7. 微调后模型的推理测试
把 Step3 里的 /root/code/test.py 里的模型路径修改一下:
from lmdeploy import pipeline``from lmdeploy.vl import load_image`` ``pipe = pipeline('/root/model/InternVL2-1B-iter2000')`` ``image = load_image('/root/code/datasets/CLoT_cn_2000/ex_images/007aPnLRgy1hb39z0im50j30ci0el0wm.jpg')``response = pipe(('请你根据这张图片,讲一个脑洞大开的梗', image))``print(response.text)
之后 python /root/code/test.py 进行测试:
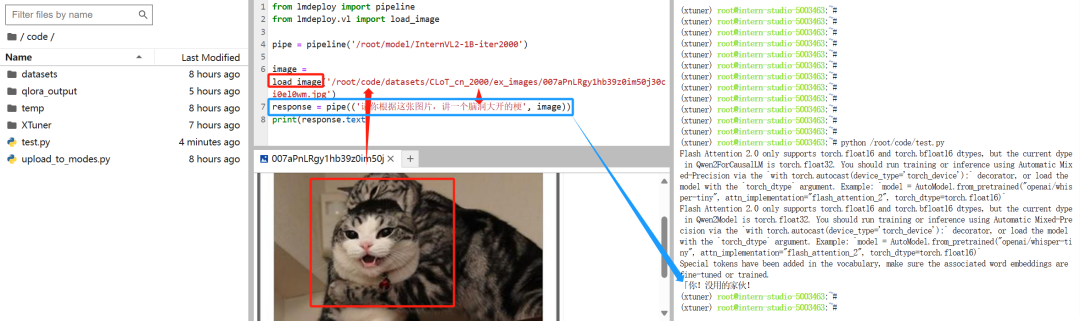
微调后 InternVL2-1B-iter2000 的推理结果
图片推理的输出语气基本到位了,但是准确度还差一些。
训练集里这张图的标注是“『住手!现在的你还不是那家伙的对手!先撤吧!!”
微调后的模型进行这张图的推理,输出结果至少有“住手,先撤吧”的含义,才能说明微调过程达到拟合。现在是不拟合的状态,还需要继续训练,直到拟合。
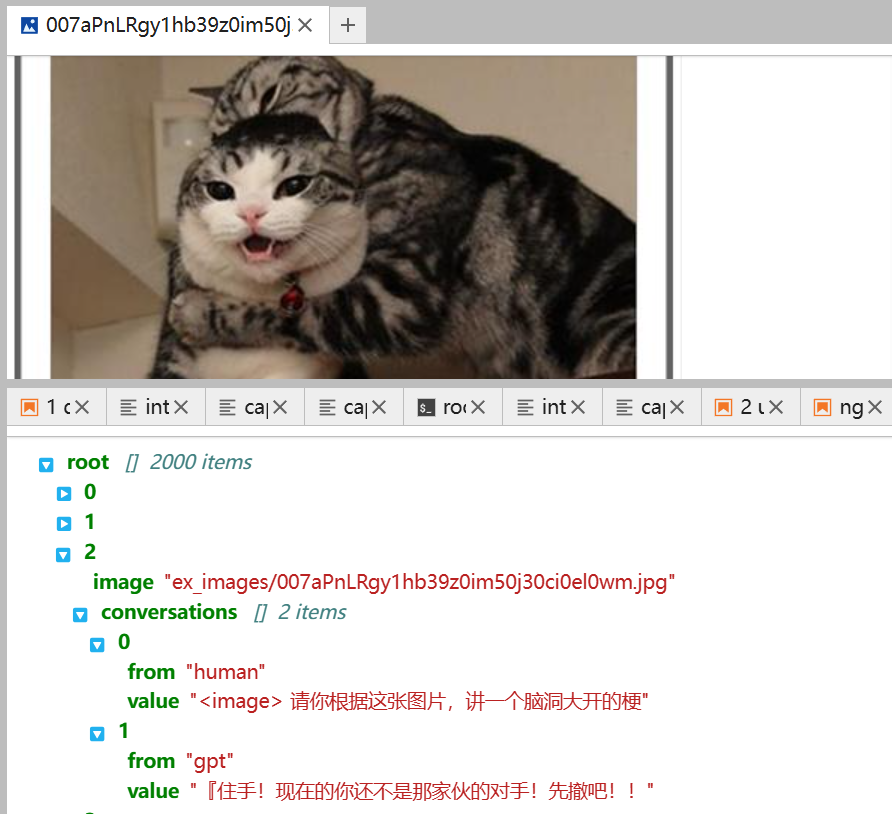
训练集里的图片和标注
为了解决不拟合的问题,需要在 iter2000 这个 2000 步迭代的状态上继续训练,有两种继续训练的方案:
1. 使用 path 参数,用合并后的大模型文件进行继续训练
在配置文件(训练脚本, /root/code/XTuner/xtuner/configs/internvl/v2 /internvl_v2_internlm2_2b_qlora_finetune.py)里,把 path = “/root/model/InternVL2-1B” 修改为 “/root/model/InternVL2-1B-iter2000”:
# Model``# path = 'OpenGVLab/InternVL2-2B'``path = '/root/model/InternVL2-1B-iter2000'
之后其他参数不需要改,跳到 Step4 执行训练命令,在InternVL2-1B-iter2000模型的基础上继续训练,进一步进行拟合。
2. 使用 reumse 和 load_from 参数,用合并前的 lora 文件进行继续训练。配置文件(训练脚本)里还有 reumse 和 load_from 的参数,修改一下它们,即可进行 resume:
# load from which checkpoint``# load_from = None``load_from = "/root/code/qlora_output/iter_2000.pth"`` ``# whether to resume training from the loaded checkpoint``# resume = False``resume = True
用了这两个参数,跳到 Step4 执行训练命令,就可以在 iter2000.pth 基础上继续训练。
结语
经过上面 7 个步骤,就完成 InternVL2-1B 的微调啦,掌握了工具,就可以开动脑筋构建合适的数据集,为 VLM 注入自己的智能。

















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









