






有一说一,这个安全项目需要对c语言有较高的理解。所以,我想来总结一下来保证我对安全项目的理解正确。
1.对题目的理解。
无论什么题,我认为最重要的就是对题目的理解,如果漏掉什么关键信息那作这个题会变得很难。(我就少看了一个信息,导致我开始做了很多无用功):<
(ps:该题目我以绑定资源的形式发出,在文章头部会显示)
首先,要知道这个题目最重要的是将16机制的数转化为一个字符串。而且,4个key是可以分两部来进行解决的,这会极大的使本题的难度减小。最后,在本题的思路是通过已知的文本内容寻找相应的key值,所以对文本内容的结合十分重要,甚至要通过文本内容来解决问题。
 (找到key1,2时出现的文本)
(找到key1,2时出现的文本)
 (找到key3,4时出现的文本)
(找到key3,4时出现的文本)
2.基本思路
(我认为思路是很重要的所以用蓝色写)
我们既然要吃这个16机制的数中找到特定字符串,所以我们可以通过特定的网站等,先对整个数字进行大概的解码,当然要注意数据是不是大端存储还是小端存储。当然在vs2022中也可以看见。
比如调试功能内存窗口中右边的数据。然后通过输入的key的值来对dummy进行改变,进而来得到想要的字符串。
3.对问题开始进行分析
源代码
#include <stdio.h>
#include <stdlib.h>
int prologue[] = {
0x5920453A, 0x54756F0A, 0x6F6F470A, 0x21643A6F,
0x6E617920, 0x680A6474, 0x6F697661, 0x20646E69,
0x63636363, 0x63636363, 0x72464663, 0x6F6D6F72,
0x63636363, 0x63636363, 0x72464663, 0x6F6D6F72,
0x2C336573, 0x7420346E, 0x20216F74, 0x726F5966,
0x7565636F, 0x20206120, 0x6C616763, 0x74206C6F,
0x20206F74, 0x74786565, 0x65617276, 0x32727463,
0x594E2020, 0x206F776F, 0x79727574, 0x4563200A
};
int data[] = {
0x63636363, 0x63636363, 0x72464663, 0x6F6D6F72,
0x466D203A, 0x65693A72, 0x43646E20, 0x6F54540A,
0x5920453A, 0x54756F0A, 0x6F6F470A, 0x21643A6F,
0x594E2020, 0x206F776F, 0x79727574, 0x4563200A,
0x6F786F68, 0x6E696373, 0x6C206765, 0x796C656B,
0x2C336573, 0x7420346E, 0x20216F74, 0x726F5966,
0x7565636F, 0x20206120, 0x6C616763, 0x74206C6F,
0x20206F74, 0x74786565, 0x65617276, 0x32727463,
0x6E617920, 0x680A6474, 0x6F697661, 0x20646E69,
0x21687467, 0x63002065, 0x6C6C7861, 0x78742078,
0x6578206F, 0x72747878, 0x78636178, 0x00783174
};
int epilogue[] = {
0x594E2020, 0x206F776F, 0x79727574, 0x4563200A,
0x6E617920, 0x680A6474, 0x6F697661, 0x20646E69,
0x7565636F, 0x20206120, 0x6C616763, 0x74206C6F,
0x2C336573, 0x7420346E, 0x20216F74, 0x726F5966,
0x20206F74, 0x74786565, 0x65617276, 0x32727463
};
char message[100];
void usage_and_exit(char* program_name) {
fprintf(stderr, "USAGE: %s key1 key2 key3 key4\n", program_name);
exit(1);
}
void process_keys12(int* key1, int* key2) {
*((int*)(key1 + *key1)) = *key2;
}
void process_keys34(int* key3, int* key4) {
*(((int*)&key3) + *key3) += *key4;
}
char* extract_message1(int start, int stride) {
int i, j, k;
int done = 0;
for (i = 0, j = start + 1; !done; j++) {
for (k = 1; k < stride; k++, j++, i++) {
if (*(((char*)data) + j) == '\0') {
done = 1;
break;
}
message[i] = *(((char*)data) + j);
}
}
message[i] = '\0';
return message;
}
char* extract_message2(int start, int stride) {
int i, j;
for (i = 0, j = start;
*(((char*)data) + j) != '\0';
i++, j += stride)
{
message[i] = *(((char*)data) + j);
}
message[i] = '\0';
return message;
}
int main(int argc, char* argv[])
{
int dummy = 1;
int start, stride;
int key1, key2, key3, key4;
char* msg1, * msg2;
key3 = key4 = 0;
if (argc < 3) {
usage_and_exit(argv[0]);
}
key1 = strtol(argv[1], NULL, 0);
key2 = strtol(argv[2], NULL, 0);
if (argc > 3) key3 = strtol(argv[3], NULL, 0);
if (argc > 4) key4 = strtol(argv[4], NULL, 0);
process_keys12(&key1, &key2);
start = (int)(*(((char*)&dummy)));
stride = (int)(*(((char*)&dummy) + 1));
if (key3 != 0 && key4 != 0) {
process_keys34(&key3, &key4);
}
msg1 = extract_message1(start, stride);
if (*msg1 == '\0') {
process_keys34(&key3, &key4);
msg2 = extract_message2(start, stride);
printf("%s\n", msg2);
}
else {
printf("%s\n", msg1);
}
return 0;
}首先,从我的看代码的习惯是先看主函数,如果看到函数或全局变量在回去看。所以当我们看主函数时, 最先注意到的应该是函数process__key12,而我们在去看这个函数时,可以发先这个函数正好是资源中说的可以去改变dummy值的一个函数,进而改变start和strdie来对message中进行赋值。在我们知道可以大概写法后,我们要先确定start和strdie,在知道想要得到相应字符串需要的两者的值后在找到相应的key1,2.
(1)key1,2
为了找相应的字符串,我们先观察相应的解码。
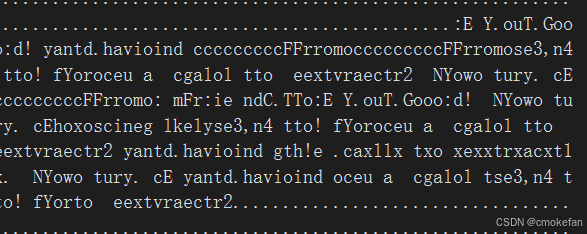
在面对这样的数据时,我们可以通过找相应的开头就可以了。第一个开头时from:friend...我们可以看见第4行出现了开头的字母,我们开始找寻规律。可以发现是每连着两个字母会跳过一个字母。在结合关键函数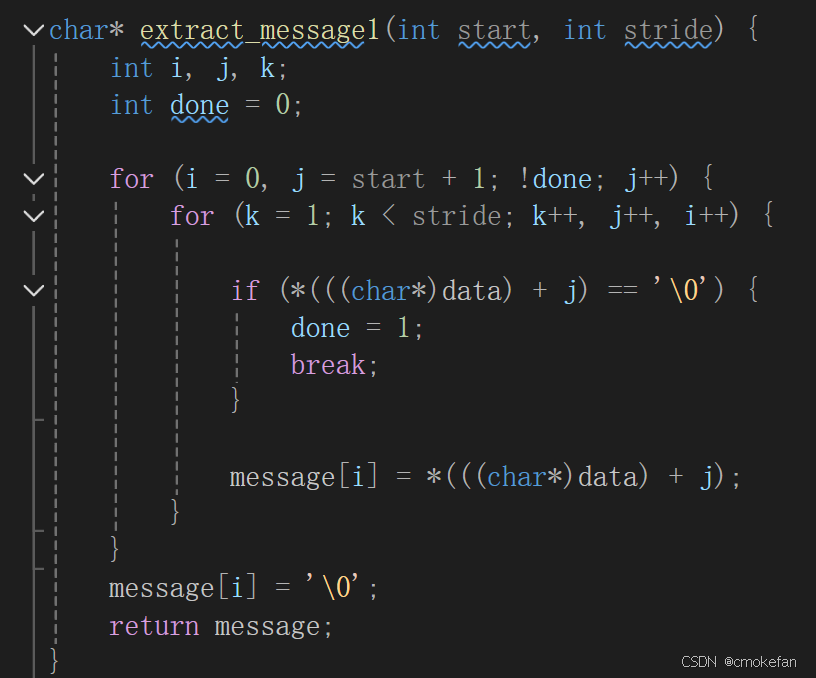
可以看见两循环中j都会相加,在内部的循环结束时,j就会因为两个循环相加两次,这样就会出现刚刚说的跳过一位的情况。而且目标字母会连续两个出现,所以可以推出stride=3。而j要从F出发所以start=9。这样我们在去推出key1,2的值。我们假如要通过内存来改变dummy的值,我们就要用process__key12改变dummy的内存。面对这个函数的具体实现过程简单的说说吧。这个函数通过指针的加减改变了对应内存存储的值,等号前半部分是指定要改变的内存,而key2是给相应地址进行赋值。通过调试可知key1和dummy的内存差36个字节。所以是key1=9可以实现指向特定内存空间的功能,而当key2=777时其16进制为309,这样就可以分别将start和strdie给与刚刚推得的值。
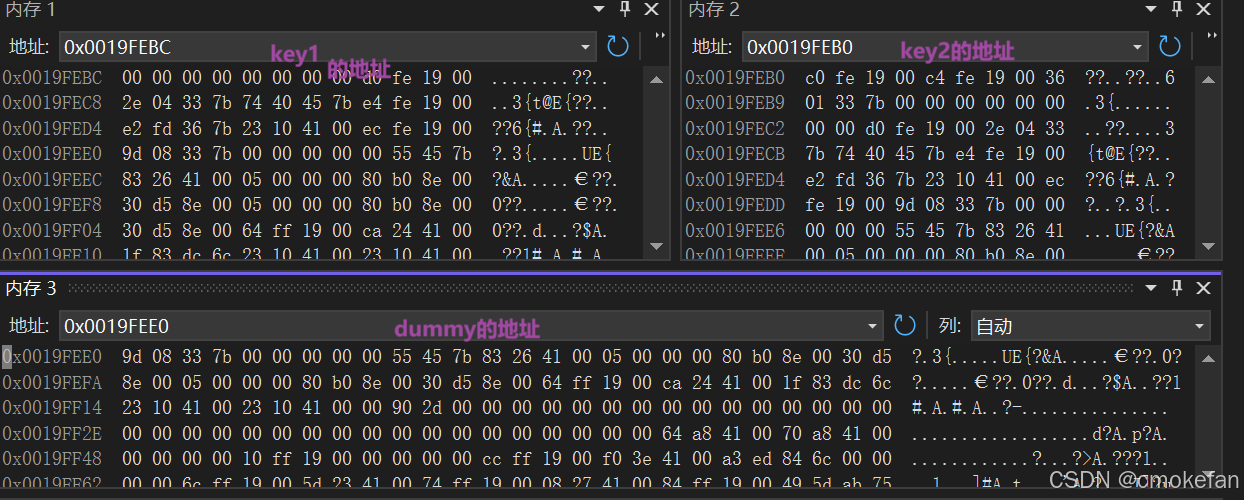
所以key1=9;key2=777;
在寻找key3,4时也是相同的思路,但唯一不同的是3,4的作用是不一样的。他们3的作用是让message[0]=‘\0’.所以在使data中第10个元素等于零(因为‘\0’对应的16进制使零)。一样的思路找到数据相应的地址通过相应的函数对message相应的值进行改变。但是,如果你在寻找内存时会发现两者的差值比较大,但思路不会改变。
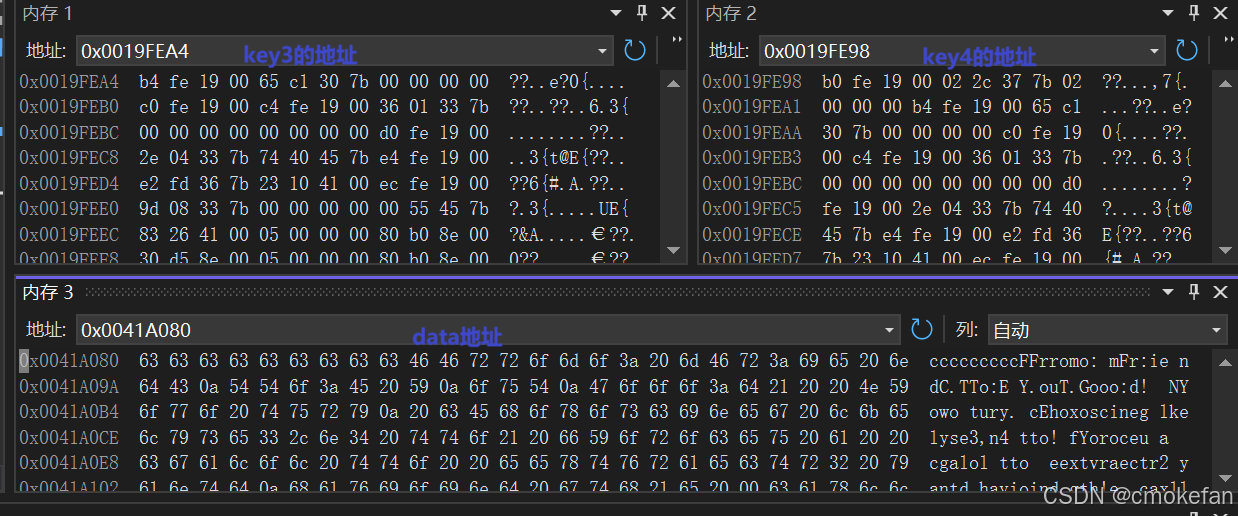
所以key3=649600;key4=-4587520;
总结,我认为这个安全项目是一个非常不错的东西,其对代码理解能力和指针等方面需要较高的理解认识。:)
有一些地方没有进行特定的说明,但都不是难点稍稍思考可以得到相应的答案.

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









