






1.为什么有huffman算法
因为我们在传输数据的时候,直接传输的字节要求较高,于是就发明了huffman算法将传输的数据进行压缩。通过这个算法可以减少传输时需要的数据量,值得注意的是这个算法是一个无损压缩的算法。
2.什么是huffman算法
我们知道计算机在传输数据时通常会将相应的数据转化位只有01的二进制,如果我们用相应的ascll的值来传输,我们消耗的传输空间一定会很大并且传输效率十分低下,而使用相应的huffman算法会极大的减小相应的传输数据。该算法是通过统计大量文件中的相应的字符出现的频率,将字符转化为相应的不会出现前缀字符来表示字符。这样可以极大的提高传输效率。
3.huffman算法原理
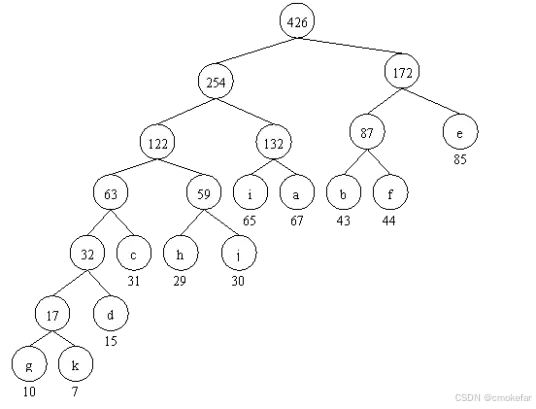
我们在得到大量的文本后我们会已经字符出现的频率建立相应的二叉树(huffman树)。在建立这颗树的时候我们先将所以字符出现的频率从低到高进行排序,然后选出两个频率最小的节点合成一个新的节点,并将新的节点重新放入序列中进行排序,然后不断重复相应的步骤直到该队列中只有一个节点为止,并将该节点理解为根节点。 到此huffman的树的建立就完成了。
在数建立完成之后我们会还要将相应的字符进行赋值,赋给它们相应的01序列。在一个树建立之后我们要开始对树进行遍历,如果往左子树遍历我们就给01序列赋0,如果往右子树遍历我们就给01序列赋1,一直重复相应的过程直到我们赋值到相应的子节点。
4.huffman算法相应的代码实现
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define maxlong 256
typedef struct hlnode
{
char symbol;
char* code;
struct hlnode* next;
}hlnode;
typedef struct hltable
{
struct hlnode* first;
struct hlnode* last;
}hltable;//建立第一个和最后一个在遍历是方便
typedef struct htnode
{
char symbol;
struct htnode* left, * right;
}htnode;
#define type htnode*
typedef struct pqnode
{
type val;
int probablity;
struct pqnode* next;
}pqnode;
typedef struct pQenen
{
unsigned int size;
pqnode* first;
}pQenen;
typedef struct htree
{
htnode* root;
}htree;
void inithuffmantree(pQenen** huffmantree)
{
(*huffmantree) = (pQenen*)malloc(sizeof(pQenen));
(*huffmantree)->size = 0;
(*huffmantree)->first = NULL;
return;
}
void addpQenen(pQenen** huffmantree, htnode* val, int probablity)
{
if ((*huffmantree)->size == maxlong)
{
printf("该队列长度已满\n");
return;
}
//创建相应的列表元素,对列表进行填充
pqnode* aux = (pqnode*)malloc(sizeof(pqnode));
aux->probablity = probablity;
aux->val = val;
if( (*huffmantree)->size == 0 || (*huffmantree)->first == NULL)
{
aux->next = (*huffmantree)->first;
(*huffmantree)->first = aux;
(*huffmantree)->size++;
}
else
{
//接下来对将插入元素的probablity进行讨论,先与第一个进行比较,如果小于第一个就放在第一个的位置上,如果大于使用迭代来解决
if (probablity <= (*huffmantree)->first->probablity)
{
aux->next = (*huffmantree)->first;
(*huffmantree)->first = aux;
(*huffmantree)->size++;
return;
}
else
{
pqnode* iterator = (*huffmantree)->first;//迭代器,用于进行迭代
//开始进行
while (iterator->next != NULL)
{
if (probablity <= iterator->next->probablity)
{
aux->next = iterator->next;
iterator->next = aux;
(*huffmantree)->size++;
return;
}
iterator = iterator->next;
}
if (iterator->next == NULL)
{
aux->next = iterator->next;
iterator->next = aux;
(*huffmantree)->size++;
return;
}
}
}
}
htnode* gethtnode(pQenen** pqenen)
{
//该函数的作用位将队列中的第一个元素对应的节点取出
type returnval = (htnode*)malloc(sizeof(htnode));
if ((*pqenen)->size > 0)
{
returnval = (*pqenen)->first->val;
(*pqenen)->first = (*pqenen)->first->next;
(*pqenen)->size--;
}
else
{
printf("该队列已为空\n");
}
return returnval;
}
htree* creathuffmantree(char* string)
{
int* probablity = (int*)malloc(sizeof(int) * 256);//乘以256的原因是因为ASCLL码有256位,即所有字符的可能
for (int i = 0; i < 256; i++)
{
probablity[i] = 0;
}
for (int i = 0; string[i] != '\0';i++)
{
probablity[(unsigned int)string[i]]++;
}
pQenen* huffmantree;//该结构体的作用可以看为一个列表的头指针
inithuffmantree(&huffmantree);//为什么要传二级指针,以为在函数中我们要开辟相应的内存空间,如果不用二级指针我们需要有返回值
//将队列进行填充
for (int i = 0; i < 256; i++)
{
if (probablity[i] != 0)
{
//对相应的节点进行初始化
htnode* aux = (htnode*)malloc(sizeof(htnode));
aux->left = NULL;
aux->right = NULL;
aux->symbol = (char)i;
addpQenen(&huffmantree, aux, probablity[i]);//此处先创立节点,在填充队列可以简化过程,若直接创立元素会变麻烦
}
}
free(probablity);//该数组已经没用
//接下来要开始形成相应的huffman树
while ((huffmantree)->size > 1)//因为当huffman树的队列中只有一个元素时huffman树构造完成
{
int probablity = huffmantree->first->probablity;
probablity = probablity + huffmantree->first->next->probablity;
htnode* left = gethtnode(&huffmantree);
htnode* right = gethtnode(&huffmantree);
htnode* newnode = (htnode*)malloc(sizeof(htnode));//该节点是两个小节点合成的
newnode->left = left;
newnode->right = right;
addpQenen(&huffmantree, newnode, probablity);//与上文相互照应
}
htree* tree = (htree*)malloc(sizeof(htree));//创立树的根节点
tree->root = gethtnode(&huffmantree);//得到最后一个节点,这个就是根节点
return tree;
}
void traversetree(htnode* treenode, char code[256], int k, hltable** table)
{
if (treenode->left == NULL && treenode->right == NULL)
{
code[k] = '\0';
//创立相应的列表元素并进行赋值
hlnode* aux = (hlnode*)malloc(sizeof(hlnode));
aux->symbol = treenode->symbol;
aux->code = (char*)malloc(sizeof(char) * (strlen(code) + 1));
strcpy(aux->code, code);
//aux->code = NULL;
//将列表元素放入列表
if ((*table)->first == NULL)
{
(*table)->first = aux;
(*table)->last = aux;
}
else
{
(*table)->last->next = aux;
(*table)->last = aux;
}
}
//运用递归来遍历左右子树
if (treenode->left != NULL)
{
code[k] = '0';
traversetree(treenode->left, code, k + 1, table);
}
if (treenode->right != NULL)
{
code[k] = '1';
traversetree(treenode->right, code, k + 1, table);
}
}
hltable* buildtable(htree* tree)
{
hltable* table = (hltable*)malloc(sizeof(hltable));
table->first = NULL;
table->last = NULL;
char code[256];
int k = 0;
traversetree(tree->root, code, k,&table);
return table;
}
void findtable(hlnode* codetable, char word)
{
if (codetable->symbol == word)
{
printf("%s ", codetable->code);
return;
}
else
{
findtable(codetable->next, word);
}
}
void encode(hltable* codetable, char* string)
{
for (int i = 0; string[i] != '\0'; i++)
{
findtable(codetable->first, string[i]);
}
}
void decode(htree* code, char* string)
{
htnode* code1 = code->root;
for (int i = 0; string[i] != '\0'; i++)
{
if (string[i] == '0')
{
code1 = code1->left;
}
else if (string[i] == '1')
{
code1 = code1->right;
}
if (code1->left == NULL && code1->right == NULL)
{
printf("%c", code1->symbol);
code1 = code->root;
}
}
}
int main()
{
htree* code = creathuffmantree("hello world ckf");//根据字符串创立相应的huffmantree
hltable* codetable = buildtable(code);//得到相应的队列
encode(codetable, "ckf");//将字符串解码为相应的01排序
decode(code,"110110101011");//将01排序转化为相应字符串
return 0;
}
现在我将对代码进行相应的讲解。
我们先看main函数我们可以看到4个函数,从第一个到第四个相应的功能分别是创立相应的huffman树、得到相应的字符对应的01序列的表格、将字符串转化为相应的01序列和将01序列转换为相应的字符串。
(1)到处我们先看创立huffman树的函数。
在这个环节我们需要的有几个结构体。htnode对应的是huffman树中的节点,pqnode是形成树之前的列表中的元素即对字符进行排队的队列,pqenen是该队列相应的头节点,htree是huffman树的根节点。
在开始的时候我们将会创建一个probablity的数组其中有256个元素位置,因为ascll码表中只有256个字符。然后我们将对应的字符串中出现的字符在probablity中++,来达到提升相应优先度的结果,然后我们就可以开始创立相应的队列来进行储存,所以我们有inithuffman这个函数。然后我们就将创立好的队列进行填充,我们用节点对其进行填充,这样可以直接在填充时将队列元素直接对应到相应的树节点。所以1我们创立相应的节点并传进addqenen的函数中,在这个队列中我们先创立相应的队列元素,然后通过传入的probablity和val对其进行相应的初始化。然后我们开始向huffmantree的列表中加入对应的元素,而在加入时我们向通过probablity的大小来进行直接的插入。所以我们可能会通过迭代的方法来进行实现。我们创建iterator这个迭代器来实现,我们会先将iterator指向第一个的probablity然后让待插入的元素一个个进行对比来判断相应的加入位置,等到找到相应的插入位置后我们将其进行相应的链表操作就可以了。
我们当然会有getnode的函数来得到相应的节点来达到两个节点合一的效果。我们继续进行creat的函数,我们可以会发现我们用左右节点的变量来不断提出相应的节点并进行合成。一直合成到最后我们直接取出最后一个节点作为根节点。导致我们的Huffmantree创立完成。
(2)然后我们来看建立相应的表格的函数
在这个函数中我们主要有的两个结构体为hlnode这个就是存放字符和01序列的相应的队列节点,而hltree这个就是队列的一个头节点(类似真正用处是将寻找的操作进行简化)。
然后我们会进入到buildtable这个函数中,在这个函数中我们会先将hltable这个变量进行初始化,然后我们会开始遍历huffman树来得到相应01序列。在traversetree这个函数中我们会将判断是不是找到了相应的字节点,如果没有我们会用递归的方式来找到相应的字节点。如果我们找到相应的子节点后我们将使用节点的01序列直接赋给队列节点。到此我们就可以完成相应的table创建。
这就是对两个主要函数的讲解,剩下的两个函数就是用简单的递归和迭代完成的。这就是我对huffman树的总结。
谢谢阅读


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









