



什么是 Embedding
1.1 一句话解释
Embedding(嵌入)= 把文字转换成数字向量
1.2 形象理解
想象你要给每个人建立档案
传统方式(文字)

Embedding 方式(向量)

这些数字向量包含了所有信息,而且相似的人向量会更接近。
1.3 核心特点
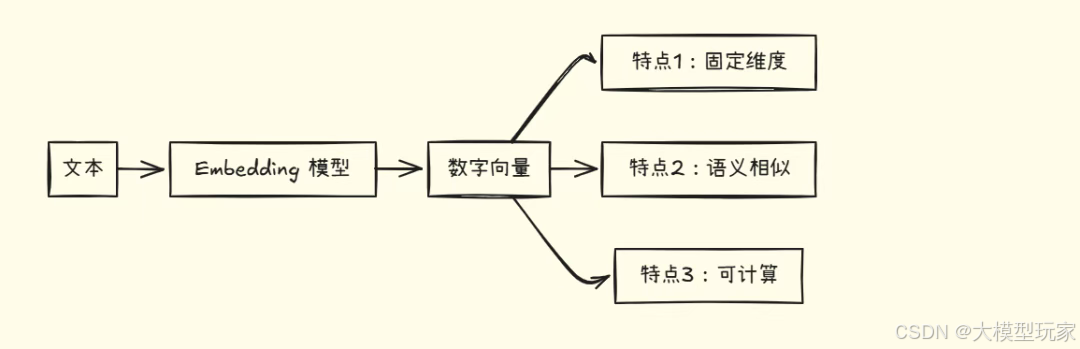
三个核心特点
-
- 固定维度:无论文本长短,都转换为固定长度的向量(如 768 维、1536 维)
-
- 语义相似:意思相近的文本,向量也相近
-
- 可计算:可以用数学方法计算相似度
2. 为什么需要 Embedding
2.1 计算机不懂文字
问题: 计算机如何判断两段文字是否相似?
错误方法:字符串匹配

正确方法:Embedding + 向量相似度

2.2 应用场景


2.3 实际案例对比
场景:在知识库中搜索
用户问题: “如何重置密码?”
知识库中的文档:
-
- “忘记密码怎么办”
-
- “修改登录凭证的方法”
-
- “公司年会时间安排”
传统关键词搜索:
- • 搜索 “重置密码”
- • 结果:无匹配 (因为知识库中没有"重置"这个词)
Embedding 语义搜索:
- • 计算问题的 embedding
- • 与所有文档的 embedding 计算相似度
- • 结果:
- • 文档1:“忘记密码怎么办” - 相似度 0.89
- • 文档2:“修改登录凭证的方法” - 相似度 0.76
- • 文档3:“公司年会时间安排” - 相似度 0.12
3. Embedding 的工作原理
3.1 从词向量到句子向量
早期:Word2Vec(词向量)
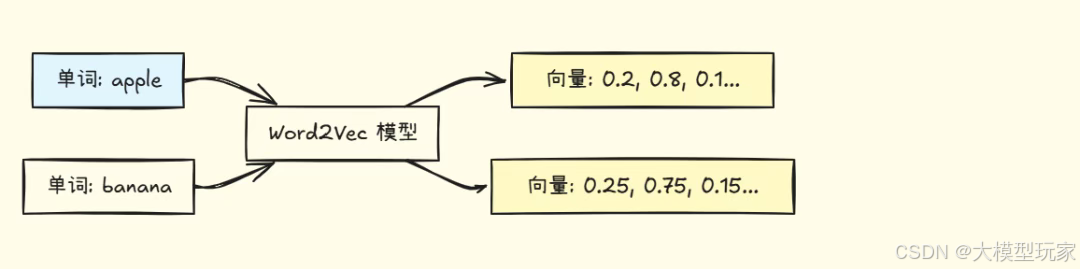
特点:
- • 只能处理单个词
- • 相似的词向量相近(apple 和 orange)
现代:Transformer(句子向量)
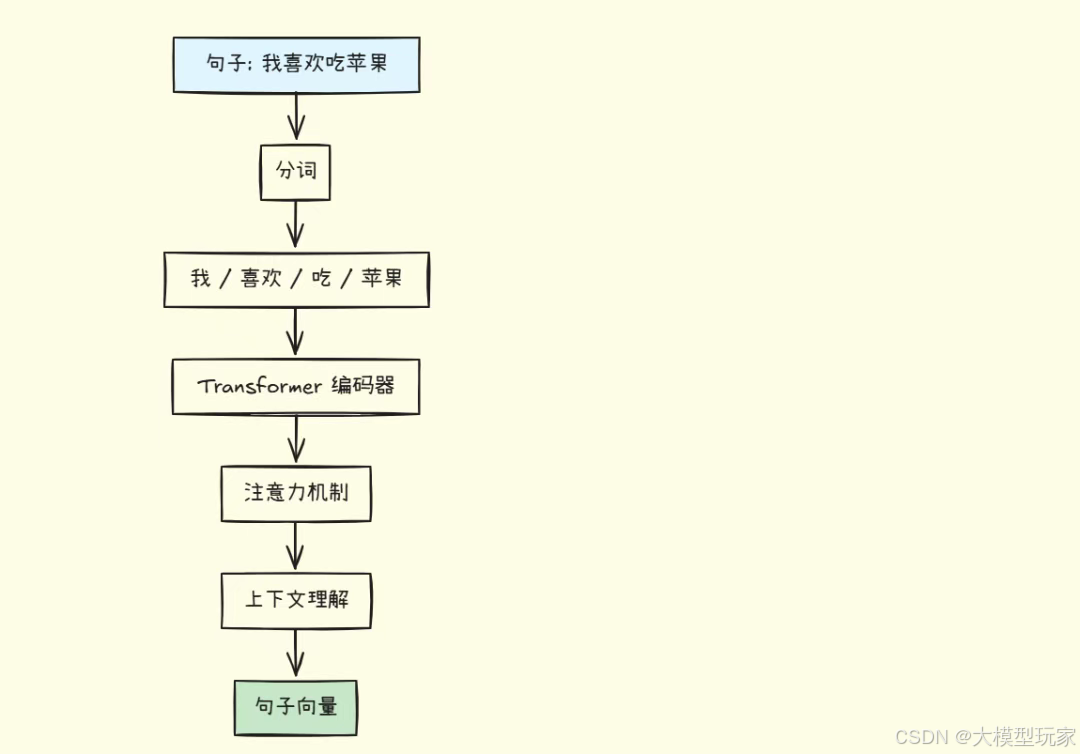
特点:
- • 可以处理整个句子/段落
- • 理解上下文关系
- • 捕捉语义信息
3.2 Embedding 模型的训练
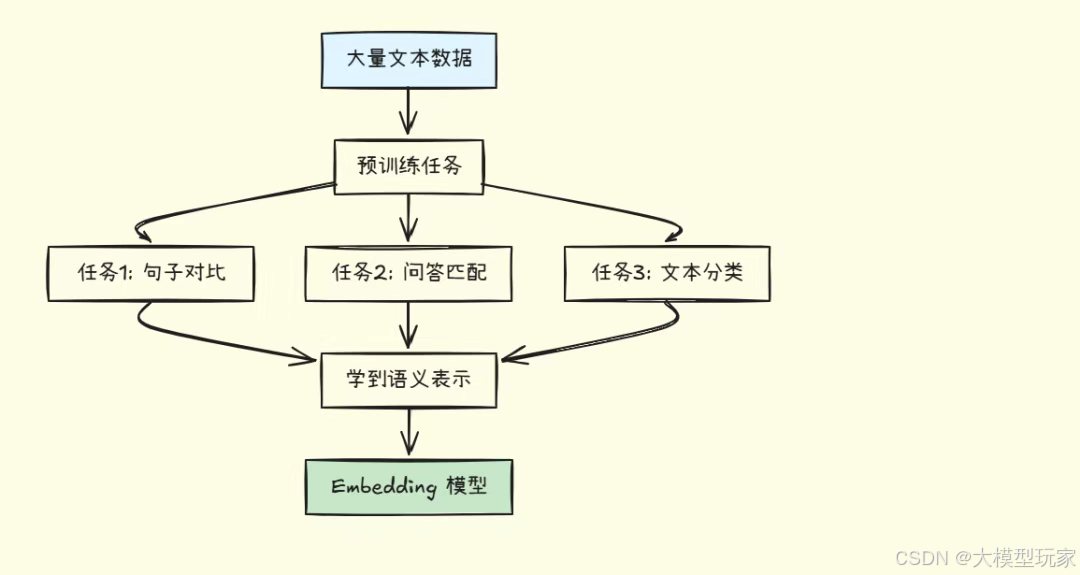
训练方式举例:
-
- 对比学习
- • 正样本对:
"天气真好" <-> "今天天气不错"→ 向量要接近 - • 负样本对:
"天气真好" <-> "我喜欢编程"→ 向量要远离
-
- 问答对训练
- • 问题:
"如何学习 Python?" - • 答案:
"可以从基础语法开始..." - • 目标:问题和答案的 embedding 要接近
3.3 维度的意义
为什么是 768 维或 1536 维?
每一维可以理解为捕捉某种语义特征:

直观比喻:
- • 1 维:只能表示"大小"(一条线)
- • 2 维:能表示"长宽"(一个平面)
- • 3 维:能表示"长宽高"(一个空间)
- • 1536 维:能表示 1536 种不同的语义特征(超空间)
4. 向量相似度计算
4.1 三种常见相似度算法
余弦相似度(最常用)
公式:

图示:
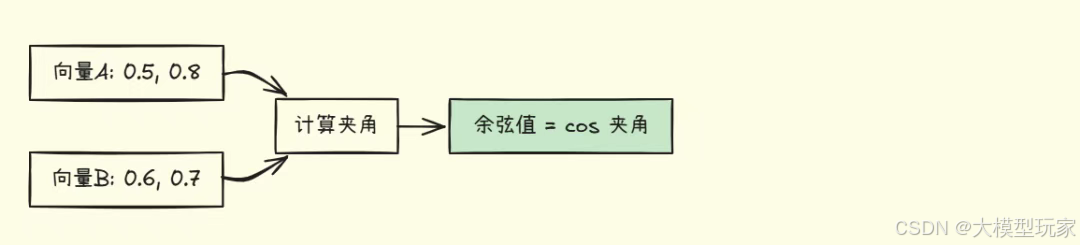
优点:
- • 不受向量长度影响
- • 只关注方向
- • 适合文本相似度
欧氏距离

点积(内积)

对比
余弦相似度:文本语义比较、文档检索排序、内容推荐系统(多数场景用的都是这个)
欧氏距离:空间位置测量、聚类分析、异常检测
点积相似度:快速初步筛选、计算资源有限场景(说白了,就是比较拉)
4.2 实际例子

余弦相似度计算:

image-20251123230640603
4.3 相似度阈值设置

5. 常见的 Embedding 模型
5.1 国际主流模型

5.2 国内主流模型

5.3 开源 vs 闭源
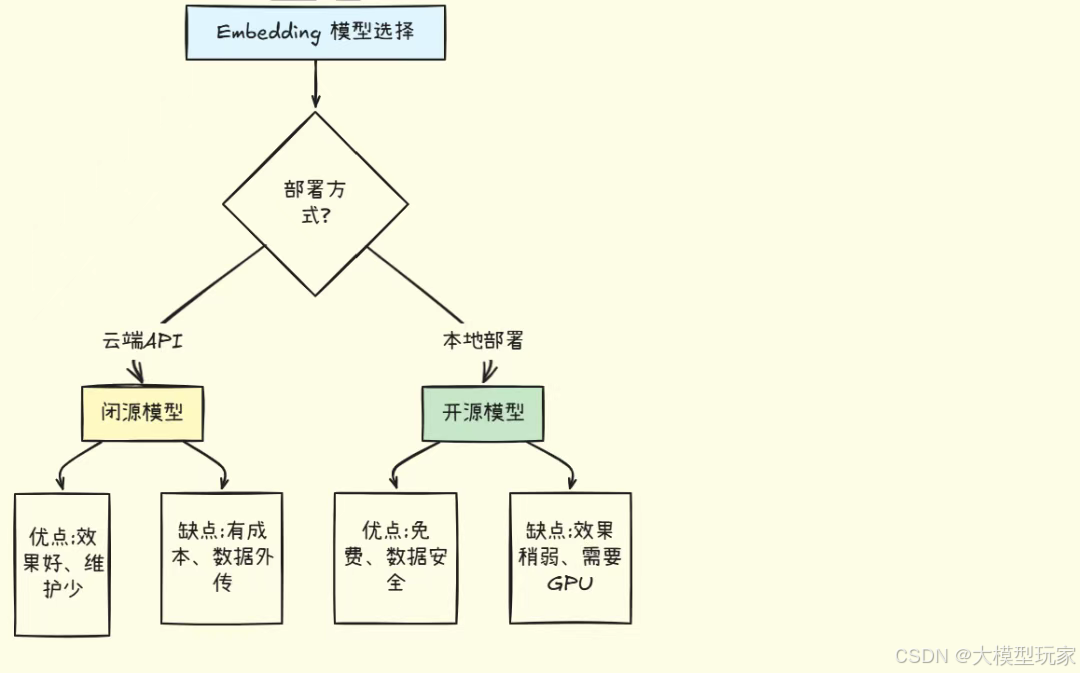
5.4 模型性能对比
中文检索任务 Benchmark:
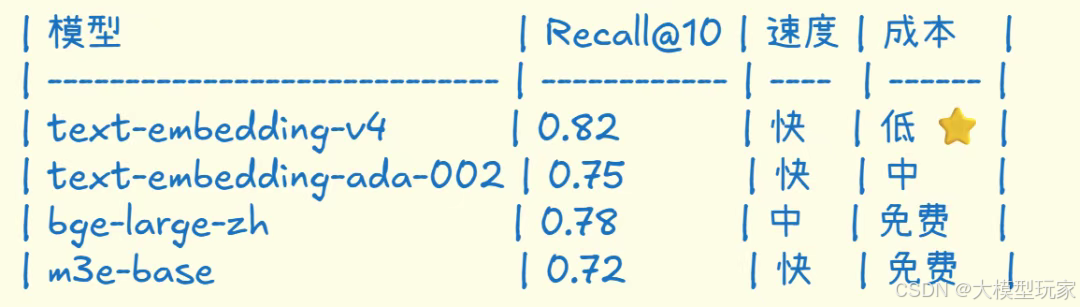
推荐选择:
- • 🥇 中文 RAG:阿里 text-embedding-v4
- • 🥈 预算有限:bge-large-zh(开源)
- • 🥉 英文为主:OpenAI text-embedding-3-small
6. 向量数据库介绍
6.1 为什么需要向量数据库?
问题: 假设你有 100 万个文档的 embedding
暴力搜索:

向量数据库:

6.2 常见向量数据库对比
在这里插入图片描述
6.3 Milvus 架构
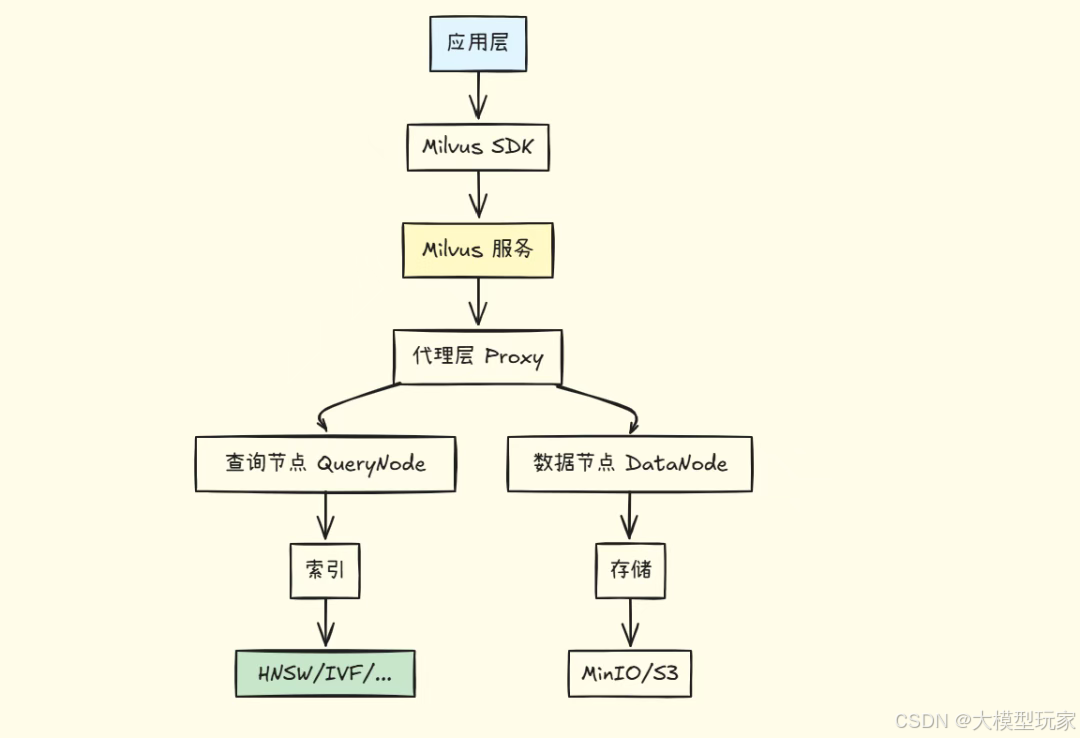
核心概念:
-
- Collection(集合)
- • 类似关系型数据库的"表"
- • 存储同一类型的向量
-
- Field(字段)
- • 向量字段:存储 embedding
- • 标量字段:存储元数据(ID、文本、标签等)
-
- Index(索引)
- • HNSW:高性能,内存占用大
- • IVF_FLAT:平衡性能和内存
- • DiskANN:处理超大规模
-
- Partition(分区)
- • 按业务逻辑分区(如按日期、类别)
- • 提高查询效率
6.4 向量检索流程
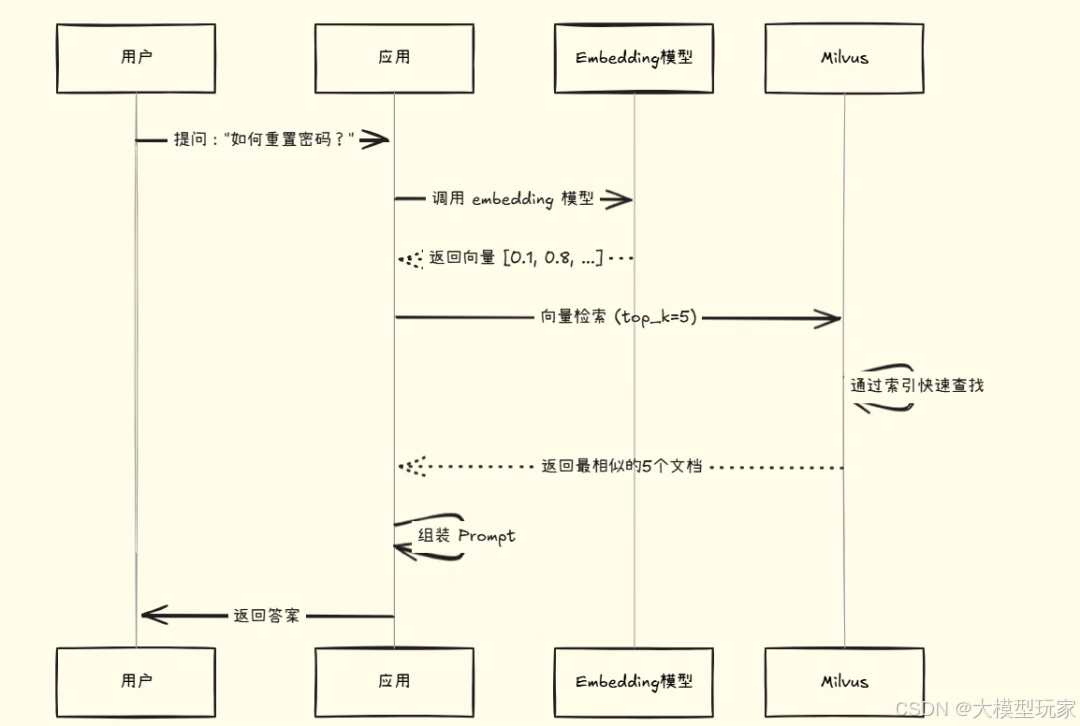
7. 实战:LangChain4j + 阿里 text-embedding-v4 + Milvus
7.1 环境准备
依赖配置(Maven)
<dependencies> <!-- LangChain4j 核心 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>0.35.0</version> </dependency> <!-- LangChain4j DashScope(阿里通义)集成 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-dashscope</artifactId> <version>0.35.0</version> </dependency> <!-- LangChain4j Milvus 支持 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-milvus</artifactId> <version>0.35.0</version> </dependency> <!-- 日志 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.9</version> </dependency></dependencies>
Docker 启动 Milvus
# 下载 docker-compose.ymlwget https://github.com/milvus-io/milvus/releases/download/v2.4.1/milvus-standalone-docker-compose.yml -O docker-compose.yml# 启动 Milvusdocker-compose up -d# 检查状态docker-compose ps# 访问 Milvus# 默认端口:19530# Attu 可视化界面:8000
Milvus 服务说明:
- • Milvus:向量数据库服务(端口 19530)
- • Etcd:元数据存储
- • MinIO:对象存储
- • Attu:Web 管理界面(可选,端口 3000)
7.2 核心代码实现
步骤 1:创建阿里云 Embedding 模型
使用 langchain4j-dashscope 官方集成,无需自己实现 HTTP 调用:
import dev.langchain4j.model.dashscope.QwenEmbeddingModel;import dev.langchain4j.model.embedding.EmbeddingModel;import java.time.Duration;/** * 阿里云 DashScope Embedding 模型工厂 */publicclassEmbeddingModelFactory { /** * 创建 text-embedding-v4 模型 * * @param apiKey 阿里云 API Key * @return Embedding 模型实例 */ publicstatic EmbeddingModel createQwenEmbeddingModel(String apiKey) { return QwenEmbeddingModel.builder() .apiKey(apiKey) .modelName("text-embedding-v4") // 使用 v4 版本 .build(); } /** * 创建 text-embedding-v3 模型(如果需要) */ publicstatic EmbeddingModel createQwenEmbeddingV3(String apiKey) { return QwenEmbeddingModel.builder() .apiKey(apiKey) .modelName("text-embedding-v3") .build(); } /** * 创建带详细日志的模型(用于调试) */ publicstatic EmbeddingModel createQwenEmbeddingWithLogs(String apiKey) { return QwenEmbeddingModel.builder() .apiKey(apiKey) .modelName("text-embedding-v4") .build(); }}
步骤 2:初始化 Milvus 连接
import dev.langchain4j.data.segment.TextSegment;import dev.langchain4j.store.embedding.EmbeddingStore;import dev.langchain4j.store.embedding.milvus.MilvusEmbeddingStore;import io.milvus.param.IndexType;import io.milvus.param.MetricType;/** * Milvus 向量存储配置 */publicclassMilvusConfig { privatestaticfinalStringMILVUS_HOST="localhost"; privatestaticfinalintMILVUS_PORT=19530; privatestaticfinalStringCOLLECTION_NAME="knowledge_base_v2"; // 改用新集合名 privatestaticfinalintDIMENSION=1024; // text-embedding-v4 维度 /** * 创建 Milvus Embedding 存储 * 不指定索引类型,让 LangChain4j 自动选择 */ publicstatic EmbeddingStore<TextSegment> createEmbeddingStore() { return MilvusEmbeddingStore.builder() .host(MILVUS_HOST) // Milvus 主机地址 .port(MILVUS_PORT) // Milvus 端口 .collectionName(COLLECTION_NAME) .dimension(DIMENSION) // 不指定 indexType,使用默认配置 // 不指定 metricType,使用默认配置 .build(); } /** * 创建 IVF_FLAT 索引的存储(适合中等数据集) * 注意:LangChain4j 的 MilvusEmbeddingStore 可能不支持自定义 IVF 参数 * 建议使用 FLAT 或 HNSW */ publicstatic EmbeddingStore<TextSegment> createIVFFlatStore() { return MilvusEmbeddingStore.builder() .host(MILVUS_HOST) .port(MILVUS_PORT) .collectionName(COLLECTION_NAME + "_ivf") .dimension(DIMENSION) .indexType(IndexType.IVF_FLAT) .metricType(MetricType.IP) .build(); } /** * 创建高性能配置的 Milvus 存储(HNSW 索引) * 适合大数据集,性能最好但内存占用大 */ publicstatic EmbeddingStore<TextSegment> createHighPerformanceStore() { return MilvusEmbeddingStore.builder() .host(MILVUS_HOST) .port(MILVUS_PORT) .collectionName(COLLECTION_NAME + "_high_perf") .dimension(DIMENSION) .indexType(IndexType.HNSW) // HNSW:更高性能,更大内存 .metricType(MetricType.COSINE) // 余弦相似度 .build(); } /** * 创建自定义配置的 Milvus 存储 */ publicstatic EmbeddingStore<TextSegment> createCustomStore( String host, int port, String collectionName, int dimension) { return MilvusEmbeddingStore.builder() .host(host) .port(port) .collectionName(collectionName) .dimension(dimension) .indexType(IndexType.FLAT) // 使用 FLAT 避免参数问题 .metricType(MetricType.IP) .build(); }}
步骤 3:文档索引(存储)
import com.example.embedding.config.EmbeddingModelFactory;import com.example.embedding.config.MilvusConfig;import dev.langchain4j.data.document.Document;import dev.langchain4j.data.document.DocumentSplitter;import dev.langchain4j.data.document.splitter.DocumentSplitters;import dev.langchain4j.data.embedding.Embedding;import dev.langchain4j.data.segment.TextSegment;import dev.langchain4j.model.embedding.EmbeddingModel;import dev.langchain4j.store.embedding.EmbeddingStore;import java.util.List;/** * 文档索引服务:将文档切分、向量化并存储到 Milvus */publicclassDocumentIndexer { privatefinal EmbeddingModel embeddingModel; privatefinal EmbeddingStore<TextSegment> embeddingStore; privatefinal DocumentSplitter documentSplitter; publicDocumentIndexer(String apiKey) { // 使用 LangChain4j 官方的 DashScope 集成 this.embeddingModel = EmbeddingModelFactory.createQwenEmbeddingModel(apiKey); this.embeddingStore = MilvusConfig.createEmbeddingStore(); // 文档分割器:每 500 字符一个片段,重叠 50 字符 this.documentSplitter = DocumentSplitters.recursive(500, 50); } /** * 索引单个文档 */ publicvoidindexDocument(String documentText) { System.out.println("开始索引文档..."); // 1. 创建文档 Documentdocument= Document.from(documentText); // 2. 切分文档 List<TextSegment> segments = documentSplitter.split(document); System.out.println("文档切分为 " + segments.size() + " 个片段"); // 3. 生成 embeddings System.out.println("正在生成向量..."); List<Embedding> embeddings = embeddingModel.embedAll(segments).content(); System.out.println("生成了 " + embeddings.size() + " 个向量"); // 4. 存储到 Milvus System.out.println("正在存储到 Milvus..."); embeddingStore.addAll(embeddings, segments); System.out.println("✅ 成功存储到 Milvus"); } /** * 批量索引多个文档 */ publicvoidindexDocuments(List<String> documents) { for (inti=0; i < documents.size(); i++) { System.out.println("\n========================================"); System.out.println("索引文档 " + (i + 1) + "/" + documents.size()); System.out.println("========================================"); indexDocument(documents.get(i)); } } /** * 索引带元数据的文档 */ publicvoidindexDocumentWithMetadata(String text, String category, String source) { Documentdocument= Document.from(text); List<TextSegment> segments = documentSplitter.split(document); // 为每个片段添加元数据 for (TextSegment segment : segments) { segment.metadata().put("category", category); segment.metadata().put("source", source); segment.metadata().put("timestamp", String.valueOf(System.currentTimeMillis())); } List<Embedding> embeddings = embeddingModel.embedAll(segments).content(); embeddingStore.addAll(embeddings, segments); System.out.println("✅ 存储了 " + segments.size() + " 个片段(类别:" + category + ")"); }}
步骤 4:语义检索(查询)
import com.example.embedding.config.EmbeddingModelFactory;import com.example.embedding.config.MilvusConfig;import dev.langchain4j.data.embedding.Embedding;import dev.langchain4j.data.segment.TextSegment;import dev.langchain4j.model.embedding.EmbeddingModel;import dev.langchain4j.store.embedding.EmbeddingMatch;import dev.langchain4j.store.embedding.EmbeddingStore;import java.util.List;/** * 语义检索服务 */publicclassSemanticSearcher { privatefinal EmbeddingModel embeddingModel; privatefinal EmbeddingStore<TextSegment> embeddingStore; publicSemanticSearcher(String apiKey) { // 使用 LangChain4j 官方的 DashScope 集成 this.embeddingModel = EmbeddingModelFactory.createQwenEmbeddingModel(apiKey); this.embeddingStore = MilvusConfig.createEmbeddingStore(); } /** * 语义搜索 * * @param query 查询文本 * @param maxResults 返回最多几个结果 * @param minScore 最小相似度阈值(0-1) * @return 相关文档列表 */ public List<EmbeddingMatch<TextSegment>> search(String query, int maxResults, double minScore) { // 1. 将查询转换为向量 System.out.println("正在生成查询向量..."); EmbeddingqueryEmbedding= embeddingModel.embed(query).content(); // 2. 在 Milvus 中检索 System.out.println("正在检索..."); List<EmbeddingMatch<TextSegment>> matches = embeddingStore.findRelevant( queryEmbedding, maxResults, minScore ); return matches; } /** * 打印搜索结果 */ publicvoidprintSearchResults(String query) { System.out.println("\n=========================================="); System.out.println("查询:" + query); System.out.println("=========================================="); List<EmbeddingMatch<TextSegment>> results = search(query, 5, 0.5); if (results.isEmpty()) { System.out.println("❌ 未找到相关内容"); return; } for (inti=0; i < results.size(); i++) { EmbeddingMatch<TextSegment> match = results.get(i); System.out.printf("\n📄 结果 %d (相似度: %.3f):\n", i + 1, match.score()); System.out.println("----------------------------------------"); System.out.println(match.embedded().text()); System.out.println("----------------------------------------"); } } /** * 搜索并返回最佳匹配 */ public String searchBestMatch(String query) { List<EmbeddingMatch<TextSegment>> results = search(query, 1, 0.5); if (results.isEmpty()) { return"未找到相关内容"; } return results.get(0).embedded().text(); } /** * 按类别搜索(需要先索引时添加了元数据) */ publicvoidsearchByCategory(String query, String category) { List<EmbeddingMatch<TextSegment>> matches = search(query, 10, 0.5); // 过滤指定类别 List<EmbeddingMatch<TextSegment>> filtered = matches.stream() .filter(match -> { StringmetaCategory= match.embedded().metadata("category"); return category.equals(metaCategory); }) .toList(); System.out.println("\n类别「" + category + "」的搜索结果:"); for (inti=0; i < filtered.size(); i++) { EmbeddingMatch<TextSegment> match = filtered.get(i); System.out.printf("\n结果 %d (相似度: %.3f):\n", i + 1, match.score()); System.out.println(match.embedded().text()); } }}
步骤 5:完整示例程序
import com.example.embedding.service.DocumentIndexer;import com.example.embedding.service.SemanticSearcher;import java.util.List;import java.util.Scanner;/** * Embedding Demo 主程序 * 演示:文档索引 + 语义检索 */publicclassEmbeddingDemo { publicstaticvoidmain(String[] args) { // ============ 配置 API Key ============ // 替换为你的阿里云 API Key // 获取地址:https://dashscope.aliyun.com/ StringapiKey= getApiKey(); // ============ 第一步:索引文档 ============ System.out.println("========================================"); System.out.println(" 📚 开始索引知识库文档"); System.out.println("========================================"); DocumentIndexerindexer=newDocumentIndexer(apiKey); // 准备知识库文档 List<String> knowledgeBase = List.of( """ 密码重置流程: 1. 访问登录页面,点击"忘记密码" 2. 输入注册邮箱 3. 查收邮件中的重置链接 4. 设置新密码(至少8位,包含字母和数字) 5. 使用新密码登录 注意:重置链接有效期为24小时。 """, """ 账号安全建议: - 定期更换密码(建议每3个月一次) - 不要使用弱密码(如123456、生日等) - 启用两步验证增强安全性 - 不要在多个网站使用相同密码 - 发现异常登录及时修改密码 """, """ 公司年会安排: 时间:2025年1月20日 18:00-22:00 地点:香格里拉大酒店3楼宴会厅 着装要求:商务正装 节目报名:请在1月10日前提交到人事部 抽奖活动:特等奖iPhone 15 Pro一部 """, """ 请假流程: 1. 提前3天在OA系统提交请假申请 2. 等待直属主管审批 3. 超过3天需要部门总监审批 4. 病假需要提供医院证明 5. 年假需要提前一周申请 特殊情况:紧急事假可电话或微信告知主管。 """, """ 报销流程: 1. 在财务系统提交报销申请 2. 上传发票照片(需清晰可见) 3. 填写报销事由和金额 4. 主管审批后提交财务部 5. 财务审核通过后3-5个工作日到账 报销范围:差旅费、招待费、办公用品等 """, """ 远程办公政策: - 每周可申请1-2天远程办公 - 需提前一天在系统申请 - 保持在线状态,及时响应消息 - 参加线上会议必须开启摄像头 - 工作时间与办公室一致(9:00-18:00) """ ); // 索引所有文档 indexer.indexDocuments(knowledgeBase); System.out.println("\n========================================"); System.out.println(" ✅ 文档索引完成!"); System.out.println("========================================"); // 等待索引生效 System.out.println("\n等待 Milvus 索引生效(2秒)..."); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } // ============ 第二步:语义检索 ============ System.out.println("\n========================================"); System.out.println(" 🔍 开始语义检索测试"); System.out.println("========================================"); SemanticSearchersearcher=newSemanticSearcher(apiKey); // 预设测试查询 List<String> testQueries = List.of( "我忘记密码了怎么办?", "我想请病假,需要什么流程?", "公司年会什么时候举办?", "如何保护账号安全?", "可以在家办公吗?", "报销需要多久到账?" ); for (String query : testQueries) { searcher.printSearchResults(query); System.out.println("\n"); } System.out.println("========================================"); System.out.println(" ✅ 测试完成!"); System.out.println("========================================"); // ============ 第三步:交互式查询 ============ interactiveSearch(searcher); } /** * 交互式查询模式 */ privatestaticvoidinteractiveSearch(SemanticSearcher searcher) { System.out.println("\n========================================"); System.out.println(" 💬 进入交互式查询模式"); System.out.println(" 输入 'exit' 退出"); System.out.println("========================================\n"); Scannerscanner=newScanner(System.in); while (true) { System.out.print("请输入查询内容:"); Stringquery= scanner.nextLine().trim(); if (query.equalsIgnoreCase("exit")) { System.out.println("👋 再见!"); break; } if (query.isEmpty()) { continue; } try { searcher.printSearchResults(query); System.out.println(); } catch (Exception e) { System.err.println("❌ 查询失败:" + e.getMessage()); } } scanner.close(); } /** * 获取 API Key * 优先从环境变量读取,如果没有则使用硬编码的值 */ privatestatic String getApiKey() { // 方式1:从环境变量读取(推荐) StringapiKey= System.getenv("DASHSCOPE_API_KEY"); // 方式2:从系统属性读取 if (apiKey == null || apiKey.isEmpty()) { apiKey = System.getProperty("dashscope.api.key"); } // 方式3:硬编码(不推荐,仅用于测试) if (apiKey == null || apiKey.isEmpty()) { // TODO: 替换为你的 API Key apiKey = "sk-********c4573"; } return apiKey; }}
7.3 运行结果示例
milvus的数据展示
最终输出展示
======================================== 📚 开始索引知识库文档================================================================================索引文档 1/6========================================开始索引文档...文档切分为 1 个片段正在生成向量...生成了 1 个向量正在存储到 Milvus...✅ 成功存储到 Milvus========================================索引文档 2/6========================================开始索引文档...文档切分为 1 个片段正在生成向量...生成了 1 个向量正在存储到 Milvus...✅ 成功存储到 Milvus========================================索引文档 3/6========================================开始索引文档...文档切分为 1 个片段正在生成向量...生成了 1 个向量正在存储到 Milvus...✅ 成功存储到 Milvus========================================索引文档 4/6========================================开始索引文档...文档切分为 1 个片段正在生成向量...生成了 1 个向量正在存储到 Milvus...✅ 成功存储到 Milvus========================================索引文档 5/6========================================开始索引文档...文档切分为 1 个片段正在生成向量...生成了 1 个向量正在存储到 Milvus...✅ 成功存储到 Milvus========================================索引文档 6/6========================================开始索引文档...文档切分为 1 个片段正在生成向量...生成了 1 个向量正在存储到 Milvus...✅ 成功存储到 Milvus======================================== ✅ 文档索引完成!========================================等待 Milvus 索引生效(2秒)...======================================== 🔍 开始语义检索测试==================================================================================查询:我忘记密码了怎么办?==========================================正在生成查询向量...正在检索...📄 结果 1 (相似度: 0.867):----------------------------------------密码重置流程:1. 访问登录页面,点击"忘记密码"2. 输入注册邮箱3. 查收邮件中的重置链接4. 设置新密码(至少8位,包含字母和数字)5. 使用新密码登录注意:重置链接有效期为24小时。----------------------------------------📄 结果 2 (相似度: 0.798):----------------------------------------账号安全建议:- 定期更换密码(建议每3个月一次)- 不要使用弱密码(如123456、生日等)- 启用两步验证增强安全性- 不要在多个网站使用相同密码- 发现异常登录及时修改密码----------------------------------------📄 结果 3 (相似度: 0.687):----------------------------------------请假流程:1. 提前3天在OA系统提交请假申请2. 等待直属主管审批3. 超过3天需要部门总监审批4. 病假需要提供医院证明5. 年假需要提前一周申请特殊情况:紧急事假可电话或微信告知主管。----------------------------------------📄 结果 4 (相似度: 0.672):----------------------------------------报销流程:1. 在财务系统提交报销申请2. 上传发票照片(需清晰可见)3. 填写报销事由和金额4. 主管审批后提交财务部5. 财务审核通过后3-5个工作日到账报销范围:差旅费、招待费、办公用品等----------------------------------------📄 结果 5 (相似度: 0.657):----------------------------------------远程办公政策:- 每周可申请1-2天远程办公- 需提前一天在系统申请- 保持在线状态,及时响应消息- 参加线上会议必须开启摄像头- 工作时间与办公室一致(9:00-18:00)----------------------------------------==========================================查询:我想请病假,需要什么流程?==========================================正在生成查询向量...正在检索...📄 结果 1 (相似度: 0.875):----------------------------------------请假流程:1. 提前3天在OA系统提交请假申请2. 等待直属主管审批3. 超过3天需要部门总监审批4. 病假需要提供医院证明5. 年假需要提前一周申请特殊情况:紧急事假可电话或微信告知主管。----------------------------------------📄 结果 2 (相似度: 0.773):----------------------------------------报销流程:1. 在财务系统提交报销申请2. 上传发票照片(需清晰可见)3. 填写报销事由和金额4. 主管审批后提交财务部5. 财务审核通过后3-5个工作日到账报销范围:差旅费、招待费、办公用品等----------------------------------------📄 结果 3 (相似度: 0.766):----------------------------------------远程办公政策:- 每周可申请1-2天远程办公- 需提前一天在系统申请- 保持在线状态,及时响应消息- 参加线上会议必须开启摄像头- 工作时间与办公室一致(9:00-18:00)----------------------------------------📄 结果 4 (相似度: 0.686):----------------------------------------公司年会安排:时间:2025年1月20日 18:00-22:00地点:香格里拉大酒店3楼宴会厅着装要求:商务正装节目报名:请在1月10日前提交到人事部抽奖活动:特等奖iPhone 15 Pro一部----------------------------------------📄 结果 5 (相似度: 0.673):----------------------------------------密码重置流程:1. 访问登录页面,点击"忘记密码"2. 输入注册邮箱3. 查收邮件中的重置链接4. 设置新密码(至少8位,包含字母和数字)5. 使用新密码登录注意:重置链接有效期为24小时。----------------------------------------
7.4 核心要点回顾
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









