







如果你想吃第5个馒头,总要先吃了前4个才可以。
学习也一样,需要循序渐进。
很多同学觉得Transformer模型难学,看不懂;
这是因为Transformer是一个非常复杂的模型。
其中包括了很多的基础知识;
这些基础知识都需要同学们提前掌握;
然后才能开始学习Transformer模型中的特有内容。
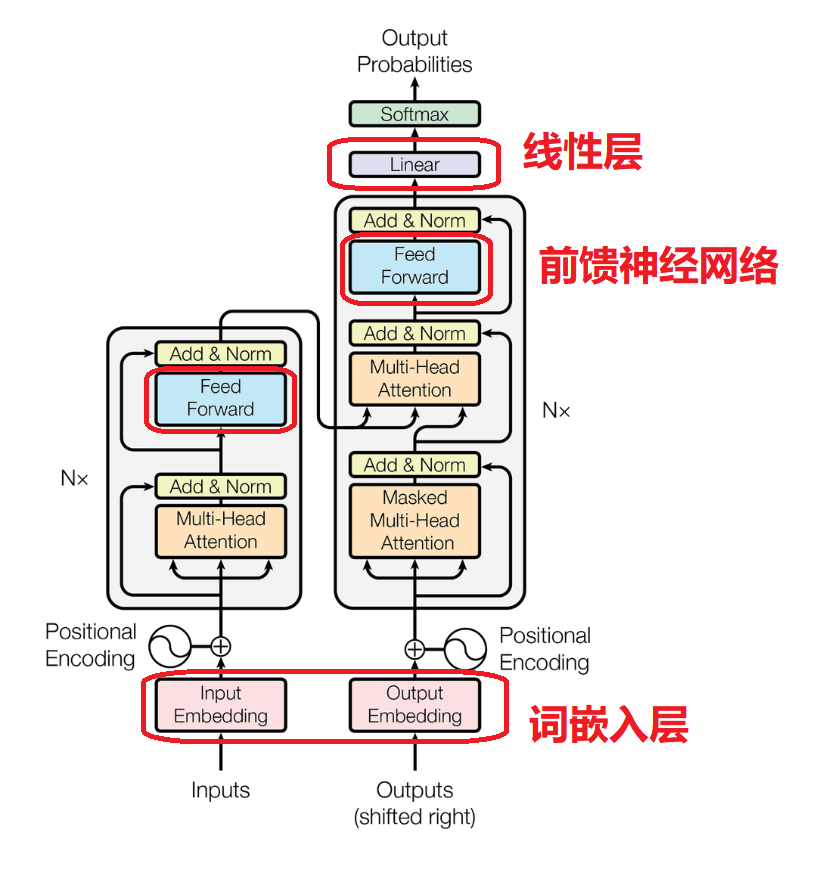
例如,图中的红框圈出了:
线性层(Linear);
词嵌入(Embedding);
前馈神经网络(Feed-Forward);
…等等。
这些部分,都是学习Transformer模型的前提依赖。
就比如我们完全没办法跳过线性层,直接去学习多头注意力机制;
这是因为多头注意力机制,就是由多个线性层构成的。
对于初学者来说,Transformer模型的第一个组件:
词嵌入(Embedding)层,第一个学习难点。
看不明白Embedding层,就很容易就被劝退了。
今天,我就试着从头,从零讲解Transformer模型。
其中会详细讲解Transformer模型的第一个组件:
什么是词嵌入,Embedding技术。
这里我先笼统、概述的说一下Embedding技术。
实际上,只要是使用深度学习模型处理NLP问题;
都需要在模型中添加,Embedding层。
例如,在下面的llama3架构中:

其中的2号位置,就是词嵌入层。
Embedding层用于将离散的单词数据,转换为连续且固定长度的向量:

这样使模型才能处理和学习这些数据的语义信息。
例如,我们希望将“Are you OK ?”这句话,作为神经网络模型的输入。
此时神经网络是没办法直接处理这句文本的。
我们需要先将“Are you OK ?”,基于词表vocab,转为整数索引序列的形式。
例如,转为1、2、3、4。
然后再基于Embedding层,将整数索引序列,转换为单词向量的序列。
过程如下图所示:

这里假设每个单词用4维的向量表示。
那么四个词的句子“Are you OK ?”,就会被转换为4*4的词向量矩阵;
每行对应一个单词。
得到输入文本的词向量矩阵后,才可以继续使用神经网络对文本进行特征提取和处理。
下面,我就重点讲解词嵌入技术的三个关键部分:
1.词嵌入的作用
2.嵌入矩阵的计算
3.Embedding层的代码实验
帮助大家理解词嵌入(Embedding)技术的原理和使用方法。
1.词嵌入有什么用
词嵌入是一种将词汇表中的词或短语,映射为固定长度向量的技术。
通过词嵌入,我们可以将高维且稀疏的单词索引,转为低维且连续的向量。
转换后的连续向量,可以表示出单词与单词之间的语义关系。
例如,假设词汇表中有10000个单词:

此时我们希望表示出man、woman、king、queen四个词语
这四个词语的索引是1~10000中的4个整数。
如果用one-hot向量表示这4个词;
那么就需要4个10000维度的one-hot向量。
这种表示方法,不仅维度高,而且非常的稀疏。
在向量中,只有1个维度是1,其他维度都是0。
不仅如此,单词向量和单词向量之间,都是正交的,没有任何语义关系。
我们使用词嵌入技术,可以把上述的4四个高维稀疏的onehot向量,转换为低维连续向量。

转换后的向量,每个维度都是一个浮点数。
图中就表示了,将单词映射到一个7维的空间中;
那么每个词语就都对应了一个7维的浮点数向量。
为了进一步说明词与词之间的关系:
我们还可以使用PCA降维算法,将7维的词嵌入向量降维至2维。
从而将单词向量在平面上绘制出来。
例如,在下图中:

语义相近的词语,词语对应的向量位置也更相近。
例如,cat猫与kitten小猫的含义相近,它们就聚在一起。
horse、dog与cat的语义差异比kitten大,所以它们距离cat,就相对较远。
不仅如此,我们还可以通过词嵌入向量的数学关系,来描述词语之间的语义关联。
例如,从图中可以看出:

向量(“king”)−向量(“man”)≈向量(“queen”)-向量(“woman”)。
总结来说:
词嵌入技术能够有效地将自然语言中的词语,转换为数值向量;
从而表达词语之间的语义关系。
这种技术也为后续更高级的自然语言处理任务,提供了坚实的基础。
2.嵌入矩阵的计算
为了实现词嵌入,我们会通过特定的词嵌入算法;
例如,word2vec、fasttext、Glove等等,训练一个通用的嵌入矩阵。
下图就表示了一个嵌入矩阵:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2759
2759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









