






前言
本文基于 huggingface 源码,对 RLHF 的实现过程做一个比较通俗的讲解。
我将尽量避免使用过多的强化学习专业术语,重点在于解析如何实现一个 PPO 算法。
01
RLHF 基础知识
RLHF 的核心就是 4 个模型之间的交互过程:
Actor model: 传统的语言模型,最后一层网络是 nn.Linear(hidden_size, vocab_size)。
Reference model(不参与训练): Actor_model的一个复制。
Reward model(不参与训练):
将传统语言模型的最后一层网络,由 nn.Linear(hidden_size, vocab_size) 替换成 nn.Linear(hidden_size, 1),也就是说该模型输出的是当前 token 的得分,而不是对下一个 token 的预测。
输入是 prompt + answer, 输出是 answer 中每个 token 对应的值,answer 中最后一个 token 对应的值即为这条语料的 reward。
Critic model: Reward_model 的一个复制。

deepspeed 的 PPO 示例图
02
强化学习基础知识

很多 NLP 出身的同学,经常会因为强化学习的基础概念模糊,导致长期对 RLHF 一知半解。
这里我用几个例子来做帮助大家更好的认知:
-
大模型生成完整 answer 的过程,视为 PPO 的一次完整的交互,reward_model 的打分便是这次交互的 reward;
-
大模型每生成一个 token,视为 PPO 中的一步;
-
假设一个汉字等价为一个 token。
prompt:中国的首都是哪里? answer:首都是南京
-
Reward = Reward_model(‘首都是南京’),如果我们有一个较好的 reward_model,这里大概率会输出一个负数,例如-10;
-
Q(2, ‘是’) = Q(‘首都’,‘是’) ,意思是在’首都’这个 state 下,下一步action选择’是’这个 token,所能获得的 reward,显然这会是一个较大的值;
-
V(4) = V(‘首都是南’),意思是在’首都是南’这个 state 下,能获得的 reward,显然这会是一个较小的值。
上面的例子也告诉我们,语言模型的 reward,只有看到结束才能确定。有时候一个 token 预测错误,整个句子的 reward 都不会很大。

03
RLHF 完整流程
有了 RLHF 和 RL 的基础知识后,我们来介绍每个模型的作用:
-
Reward_model 负责给 LLM 生成的句子打分
-
Actor_model 就是我们要优化的 LLM
-
Critic_model 负责计算 Actor_model 的状态动作值矩阵,也就是上面提到的 Q 函数(Reward 模型只负责给最后一个 token 打分,给之前 token 打分的重任靠 Critic_model 完成)
-
Reference_model 是一个标杆,为的是让我们的 Actor_model 在训练时不要偏离原始模型太远,保证其不会失去原本的说话能力
(1)RLHF 的第一个环节:让模型生成答案,并对其打分:
-
给定 batch_size 条 prompt
-
调用 actor_model 生成 answer,并进行 token 化,得到一个 B * L 的矩阵;
-
reward_model 对 answer 进行打分,得到一个 B * 1 的矩阵;
-
critic_model 对每个 token 进行打分,得到一个 B * L 的矩阵;
-
actor_model 和 reference_model 对生成的句子进行一遍正向传播,保存output.logits,得到两个 B * L * V 的矩阵
-
利用 gather_log_probs() 函数,只保存目标 token 的 logit 值,得到两个 B * L 的矩阵
{
'prompts': prompts,
'input_ids': seq,
"attention_mask": attention_mask
'logprobs': gather_log_probs(logits[:, :-1, :], seq[:, 1:]), # batch_size * (seq_len - 1)
'ref_logprobs': gather_log_probs(logits_ref[:, :-1, :], seq[:,1:]), # batch_size * (seq_len - 1)
'value': values, # batch_size * seq_len
'rewards': reward_score, # torch.Size([batch_size])
}
def gather_log_probs(logits, labels):
log_probs = F.log_softmax(logits, dim=-1)
log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
return log_probs_labels.squeeze(-1)
(2)RLHF 的第二个环节:修正 reward
前面提到,我们不能让 actor_model 偏离 reference_model 太远,因此我们要给 rewards 矩阵添加一个惩罚项,compute_rewards() 函数的返回是:每个 token 修正后的 rewards:
-
最后一个 token 的计算方法是 Reward_score + KL_penalty
-
前面的所有的 token 的计算方法是 0 + KL_penalty (除了最后一个 token,前置 token 的 reward 初始值都是 0,但是要加上惩罚项)

prompts = inputs['prompts']
log_probs = inputs['logprobs']
ref_log_probs = inputs['ref_logprobs']
reward_score = inputs['rewards']
values = inputs['value']
attention_mask = inputs['attention_mask']
seq = inputs['input_ids']
start = prompts.size()[-1] - 1
action_mask = attention_mask[:, 1:]
old_values = values
old_rewards = self.compute_rewards(prompts, log_probs, ref_log_probs, reward_score, action_mask)
ends = start + action_mask[:, start:].sum(1) + 1
# 计算reward
def compute_rewards(self, prompts, log_probs, ref_log_probs, reward_score, action_mask):
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
start = prompts.shape[1] - 1
ends = start + action_mask[:, start:].sum(1) + 1
reward_clip = torch.clamp(reward_score, -self.clip_reward_value, self.clip_reward_value)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j]
return rewards
(3)RLHF 的第三个环节:计算优势函数和 Q 函数
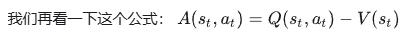
优势函数(Advantage Function)在强化学习中是一个非常关键的概念,通常用于评估在特定状态下采取某个动作比遵循当前策略(Policy)更好或更差的程度。
优势函数的主要用途是优化策略,帮助模型明确地了解哪些动作(哪个 Token)在当前状态(已生成的 token)下是有利的。
get_advantages_and_returns() 函数根据第二个环节修正后的 rewards 和 values 计算优势函数,有两个返回值:
-
advantages 矩阵
-
returns 矩阵,等价于 advantages + values,也就是 Q 函数
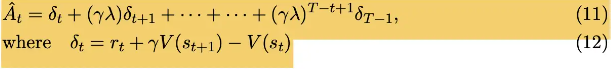
PPO 论文中 Advantage 函数的计算公式
batch = {'input_ids': seq, "attention_mask": attention_mask}
advantages, returns = self.get_advantages_and_returns(old_values, old_rewards, start)
## 优势函数的返回
def get_advantages_and_returns(self, values, rewards, start):
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values[:, start:]
return advantages.detach(), returns
(4)RLHF 的第四个环节:更新 Actor 模型
利用最新的 actor 模型,重新估算一遍语言模型目标 token 的 logits,然后利用 advantages 矩阵进行 loss 计算:
-
输入是新的 actor 模型的语言模型 logits,旧的 actor 模型的语言模型 logits,advantages 矩阵
-
在 clip_loss,和原始 loss 之间,选择一个最小的 loss 进行返回

注意我上文的一句话,“利用最新的 actor 模型”,这里涉及到一个重要的概念:重要性采样!
简单来说,我们的 Actor_model 只要训了一条语料,就会变成一个新的模型,那也就是说:我们在第一个环节所构造的语料都无法使用了,因为现在的 actor_model 已经无法生成出之前的 answer。
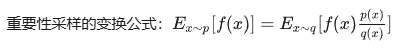
因此,我们是在用另外一个模型的模拟轨迹,来优化我们当前的模型。利用上述公式,我们可以完整这样的近似转化操作,这就是重要性采样的简单理解。
这里不懂也无所谓,就当是引入了一个新的系数来修正 reward 即可。log_ratio = (logprobs - old_logprobs) * mask 这一行代码对应着重要性采样的修正实现。
batch = {'input_ids': seq, "attention_mask": attention_mask}
actor_prob = self.actor_model(**batch, use_cache=False).logits
actor_log_prob = gather_log_probs(actor_prob[:, :-1, :], seq[:, 1:])
actor_loss = self.actor_loss_fn(actor_log_prob[:, start:], log_probs[:, start:], advantages, action_mask[:, start:])
self.actor_model.backward(actor_loss)
self.actor_model.step()
## loss的计算
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
## policy gradient loss
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange, 1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / mask.sum()
return pg_loss
(5)RLHF 的第五个环节:更新 Critic 模型
同理,利用最新的 critic 模型,重新估算一遍 Q 矩阵,然后利用 returns 矩阵(其实就是真实的 Q 矩阵)进行 loss 计算:
-
输入是新的 critic 模型计算的 Q 矩阵,旧的 critic 模型计算的 Q 矩阵,returns 矩阵
-
在 clip_loss,和原始 loss 之间,选择一个最小的 loss 进行返回
value = self.critic_model.forward_value(**batch, return_value_only=True, use_cache=False)[:, :-1]
critic_loss = self.critic_loss_fn(value[:, start:], old_values[:,start:], returns, action_mask[:, start:])
self.critic_model.backward(critic_loss)
self.critic_model.step()
## loss的计算
def critic_loss_fn(self, values, old_values, returns, mask):
values_clipped = torch.clamp(values, old_values - self.cliprange_value, old_values + self.cliprange_value)
if self.compute_fp32_loss:
values = values.float()
values_clipped = values_clipped.float()
vf_loss1 = (values - returns)**2
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(torch.max(vf_loss1, vf_loss2) * mask) / mask.sum()
return vf_loss
04
其他细节
如下:
-
PPO 算法中充斥着大量的 clip 操作,几乎是从头 clip 到尾
-
Reward 模型的打分也要进行 clip 操作:reward_clip = torch.clamp(reward_score, -self.clip_reward_value, self.clip_reward_value)
-
Reward 模型的训练时通过偏好数据对完成的,这里不做赘述,感兴趣的话后面再讲
-
huggingface 的代码很好,但很长;deepspeed 的代码很丑,但很短。建议大家选择喜欢的阅读
-
想透彻了的同学,还是应该看一下 PPO 论文和 A2C 论文
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









