







2.2 注意力机制
想必大家都已经知道注意力机制在各种计算机视觉任务中都是有帮助,如图像分类和图像分割。其中最为经典和被熟知的便是SENet,它通过简单地squeeze每个2维特征图,进而有效地构建通道之间的相互依赖关系。
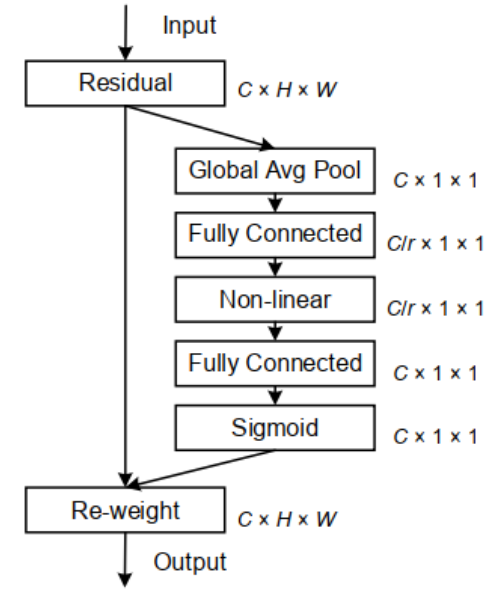
CBAM进一步推进了这一思想,通过大尺度核卷积引入空间信息编码。后来的研究如GENet、GALA、AA、TA,通过采用不同的空间注意力机制或设计高级注意力块,扩展了这一理念。
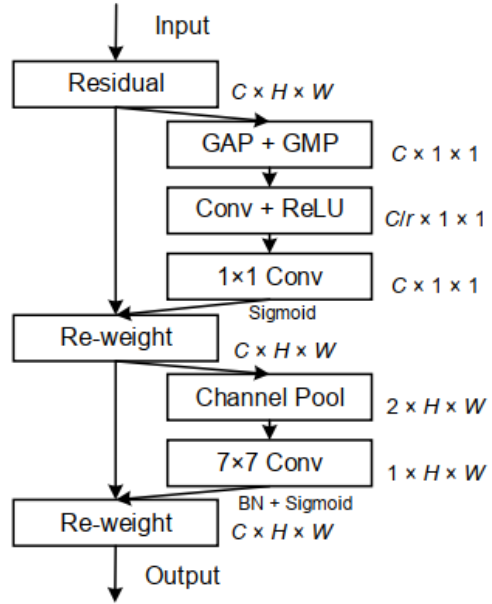
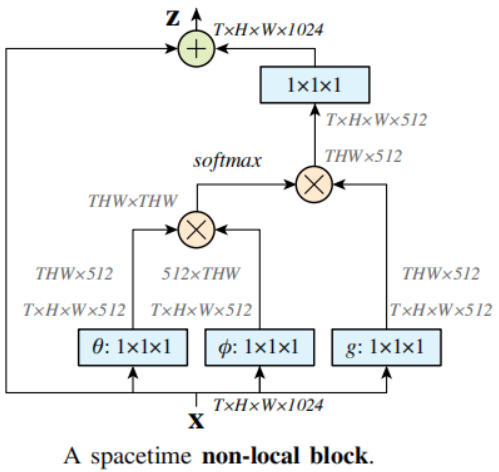
Non-local/self-attention Network则着重于构建spatial或channel注意力。典型的例子包括NLNet、GCNet、A2Net、SCNet、gsopnet和CCNet,它们都利用Non-local机制来捕获不同类型的空间信息。然而,由于self-attention模块内部计算量大,常被用于大型模型中,不适用于Mobile Network。
与Non-local/self-attention的方法不同,CA方法考虑了一种更有效的方法来捕获位置信息和通道关系,以增强Mobile Network的特征表示。通过将二维全局池操作分解为两个一维编码过程,本文方法比其他具有轻量级属性的注意力方法(如SENet、CBAM和TA)运行得更好。
3 Coordinate Attention
一个coordinate attention块可以被看作是一个计算单元,旨在增强Mobile Network中特征的表达能力。它可以将任何中间特征张量作为输入并通过转换输出了与
张量具有相同size同时具有增强表征的
。为了更加清晰的描述CA注意力,这里先对SE block进行讨论。
3.1 Revisit SE Block
在结构上,SE block可分解为Squeeze和Excitation 2步,分别用于全局信息嵌入和通道关系的自适应Re-weight。
Squeeze
在输入
的条件下,第
通道的squeeze步长可表示为:

式中,
是与第
通道相关的输出。
输入
来自一个固定核大小的卷积层,因此可以看作是局部描述符的集合。Sqeeze操作使模型收集全局信息成为可能。
Excitation
Excitation的目的是完全捕获通道之间的依赖,它可以被表述为:

其中
为通道乘法,
为
激活函数,
为变换函数生成的结果,公式如下:

这里,
和
是2个线性变换,可以通过学习来捕捉每个通道的重要性。
为什么SE Block不好?
SE Block虽然近2年来被广泛使用;然而,它只考虑通过建模通道关系来重新衡量每个通道的重要性,而忽略了位置信息,但是位置信息对于生成空间选择性attention maps是很重要的。因此作者引入了一种新的注意块,它不仅仅考虑了通道间的关系还考虑了特征空间的位置信息。
3.2 Coordinate Attention Block
Coordinate Attention通过精确的位置信息对通道关系和长期依赖性进行编码,具体操作分为Coordinate信息嵌入和Coordinate Attention生成2个步骤。

3.2.1 Coordinate信息嵌入
全局池化方法通常用于通道注意编码空间信息的全局编码,但由于它将全局空间信息压缩到通道描述符中,导致难以保存位置信息。为了促使注意力模块能够捕捉具有精确位置信息的远程空间交互,本文按照以下公式分解了全局池化,转化为一对一维特征编码操作:

具体来说,给定输入
,首先使用尺寸为(H,1)或(1,W)的pooling kernel分别沿着水平坐标和垂直坐标对每个通道进行编码。因此,高度为
的第
通道的输出可以表示为:

同样,宽度为
的第
通道的输出可以写成:

上述2种变换分别沿两个空间方向聚合特征,得到一对方向感知的特征图。这与在通道注意力方法中产生单一的特征向量的SE Block非常不同。这2种转换也允许注意力模块捕捉到沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。
3.2.2 Coordinate Attention生成
通过3.2.1所述,本文方法可以通过上述的变换可以很好的获得全局感受野并编码精确的位置信息。为了利用由此产生的表征,作者提出了第2个转换,称为Coordinate Attention生成。这里作者的设计主要参考了以下3个标准:
- 首先,对于Mobile环境中的应用来说,新的转换应该尽可能地简单;
- 其次,它可以充分利用捕获到的位置信息,使感兴趣的区域能够被准确地捕获;
- 最后,它还应该能够有效地捕捉通道间的关系。
通过信息嵌入中的变换后,该部分将上面的变换进行concatenate操作,然后使用
卷积变换函数
对其进行变换操作:

式中
为沿空间维数的concatenate操作,
为非线性激活函数,
为对空间信息在水平方向和垂直方向进行编码的中间特征映射。这里,
是用来控制SE block大小的缩减率。然后沿着空间维数将
分解为2个单独的张量
和
。利用另外2个
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 4011
4011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









