




实践方法论
前言
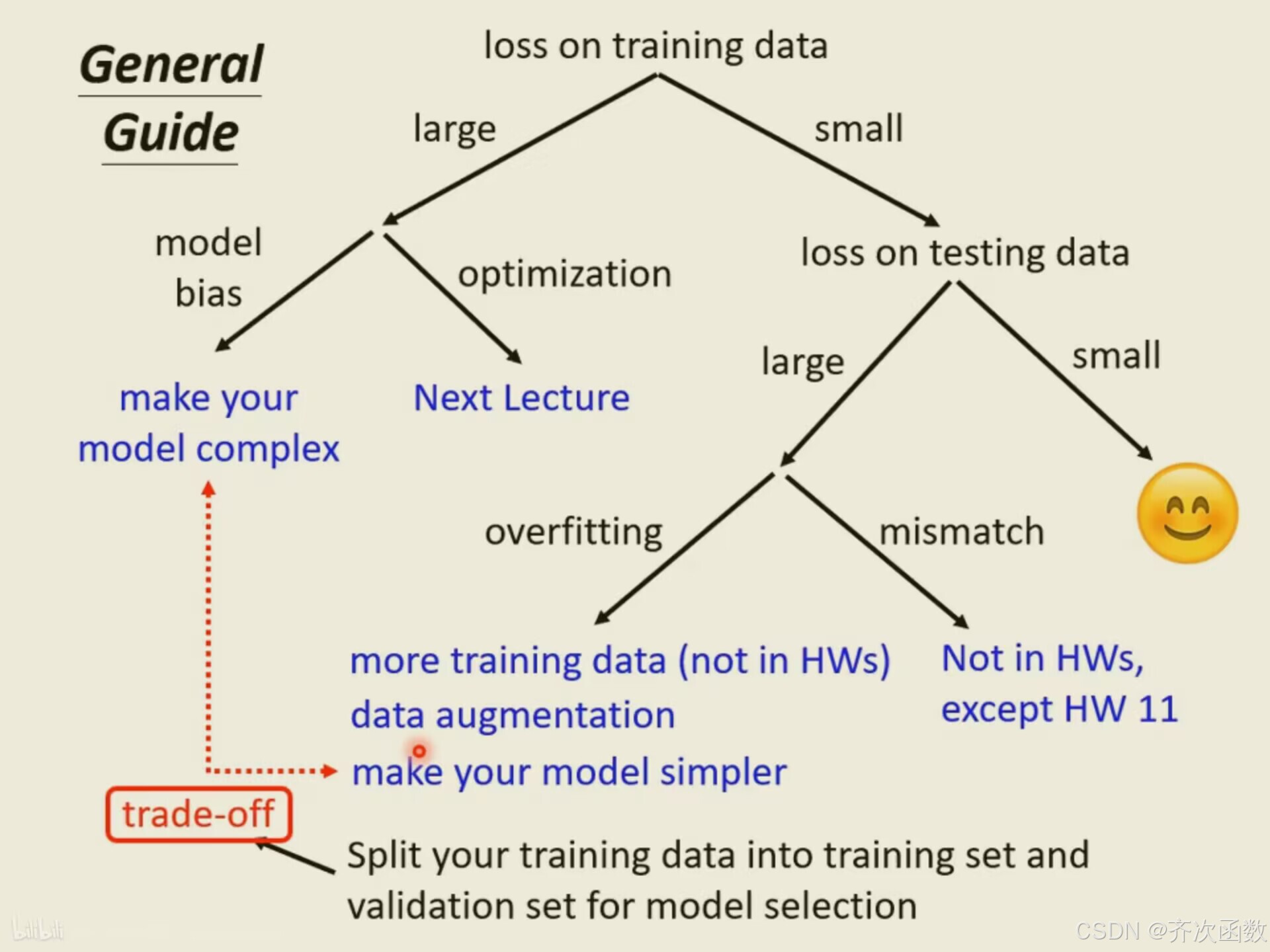
实践方法论可以帮助我们更好的训练模型,假如模型在Kaggle上的测试结果不大好,要先看看训练集上的结果,假如训练集上也没有学好,则需要先分析在训练集上的结果。
2.1模型偏差
也就是模型设置的过于简单,假如训练集本身对应曲线模型,而模型只是直线方程,那就算大海捞针,也找不出误差小的模型,因为我们想找的针根本不在这个海里。
这个时候需要设计一个新模型,给模型更大的灵活性。一种方法是输入更多的特征,比如采用56天的数据做预测。另一种方法则是采用深度学习,多点几层神经网络,增加模型灵活性。
2.2优化问题
深度学习中通常使用梯度下降法,但这难免会出现局部最小值问题,导致损失偏高。但是,如何判断究竟是由于模型偏差还是由于优化问题导致的误差偏大呢?一个方法是测试两个模型,如果20层的模型测试结果优于40层,那么就是40层的模型没优化好。
书中还有一个建议:拿到问题,先建立一个简单的模型,如:线性模型、支持向量机(SVM)。它们比较不会有模型优化的问题,那么可以先看看得到的损失是什么样的,再进行判断。
2.3过拟合
为什么会有过拟合这样的情况呢?举一个极端的例子,这是训练集。假设根据这些训练集,某一个很废的机器学习的方法找出了一个一无是处的函数。这个一无是处的函数,只要输入 x 有出现在训练集里面,就把它对应的 y 当做输出。
举个例子,输入i个特征值,训练出的模型在i个特征值上拟合效果很好,但是由于灵活度过高,在测试集上损失很大。
怎样解决过拟合问题呢,有两个有效的方法:
第一个方向是往往是最有效的方向,即增加训练集。可以根据自己对问题的理解,做数据增强(data augmentation)
另外一个解法是给模型一些限制,让模型不要有过大的灵活性。例如,卷积神经网络(Convolutional Neural Network,CNN)是一个比较有限制的架构。
- 给模型比较少的参数。如果是深度学习的话,就给它比较少的神经元的数量,本来每层一千个神经元,改成一百个神经元之类的,或者让模型共用参数,可以让一些参数有一样的数值。
- 用比较少的特征,本来给 3 天的数据,改成用给两天的数据,其实结果就好了一些。
- 还有别的方法,比如早停(early stopping)、正则化(regularization)和丢弃法(dropoutmethod)。
但也不要给太多限制,否则就不是过拟合,而是模型偏差。
2.4交叉验证
比较合理选择模型的方法是把训练的数据分成两半,一部分称为训练集(training set),一部分是验证集(validation set)。
或者将一份训练集分成K份,取其中一份作为训练集,接下去再逐个连换,就会得到K个模型。再把这K个模型,在K个训练和测试集上面通通跑一次,最后K折交叉验证得出的结果,j模型效果最好。
2.5不匹配
不匹配与过拟合不同,过拟合可以通过增加训练集来避免,但是不匹配用再多数据集都没用。
增加数据也不能让模型做得更好,所以这种问题要怎么解决,匹不匹配要看对数据本身的理解了,我们可能要对训练集跟测试集的产生方式有一些理解,才能判断它是不是遇到了不匹配的情况。
最后附上一张神图:

















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









