







概念介绍:Anacanda的介绍,YOLOv8的介绍
一、Anaconda概述
Anaconda指的是一个开源的Python发行版本,其包含了Conda、Python等180多个科学包及其依赖项,可以说安装了Anacanda就可以不用安装python了,Anaconda的作用就是整合依赖和分虚拟环境,因为有些代码需要的依赖的版本不同,而Anaconda可以将这些不同的版本隔离开来创建属于自己的独特的虚拟环境。
二、Conda概述
Conda是Anaconda能够创建虚拟环境的关键所在,Conda的作用就是创建虚拟环境。Conda将几乎所有的工具、第三方包都当做package对待,甚至包括python和conda自身!因此,conda打破了包管理与环境管理的约束,能非常方便地安装各种版本python、各种package并方便地切换。
三、YOLO概述(YOLO的前世与今生)
YOLOV1:
在2015年提出,是一种将目标检测任务转换为单一回归问题的创新方法,基于卷积神经网络。
卷积神经网络:拥有三层架构:卷积层,池化层,全连接层
YOLOV2:
也叫yolo9000,对yolo的方法进行优化,可以对9000多个物体进行识别。
YOLOV3:
设置多个输出源
提问:我们在做图像识别时,是小的物体好识别还是大的物体好识别?
答案:大的好识别。
原因:在图像识别时,使用的是卷积神经网络,大的卷积是小的卷积卷出来的,一张大图片是由一快快的图片拼凑成的,一块图片是由一个个像素点拼凑成的,就像这样:
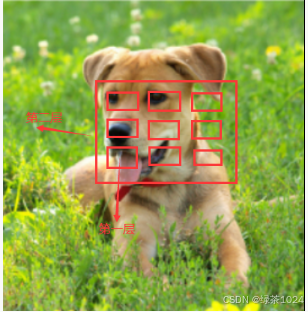
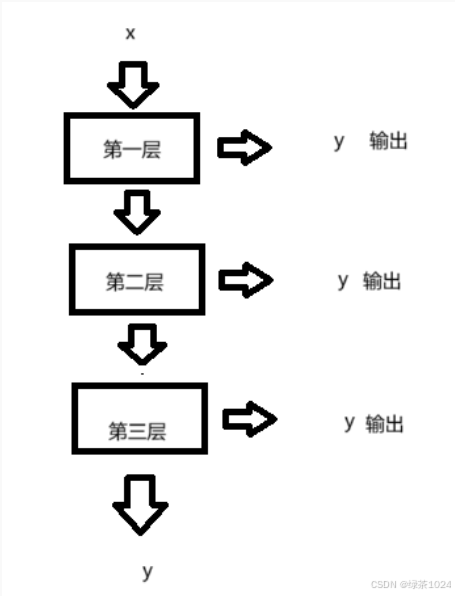
所以大的物体比小的物体好识别的多,那么小的物体就不识别了吗?不是,yolov3创建了多个输出源,什么意思,意思是卷积网络在一层一层的加层之中,在每一层中都加上了一个输出,就像这样:
YOLOV4与YOLOV5:
借用了其他模型的特征汲取技术,如DropBlock,mosaic马赛克数据增强,label_smoothing标签平滑,CBAM轻量级的卷积注意力模块
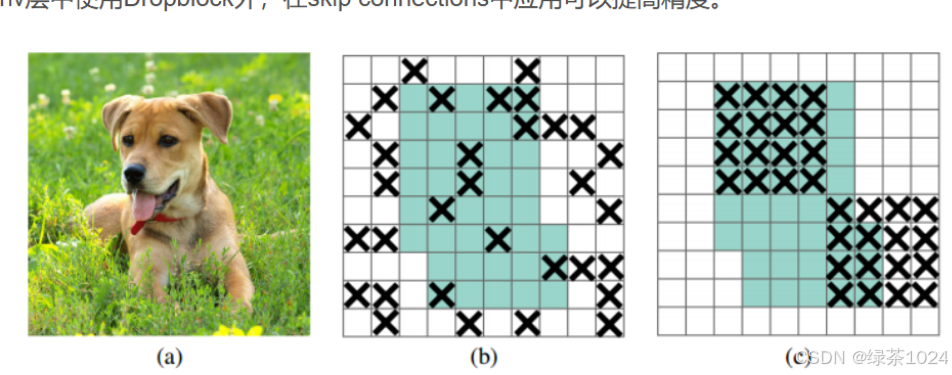
DropBlock:
在图片上加上随机的噪点,遮住一些像素点,或者集中在一起,遮住一些主要特征前来训练。
mosaic马赛克数据增强:
数据增强方法是YOLOV4论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高了batch_size。
label_smoothing标签平滑:
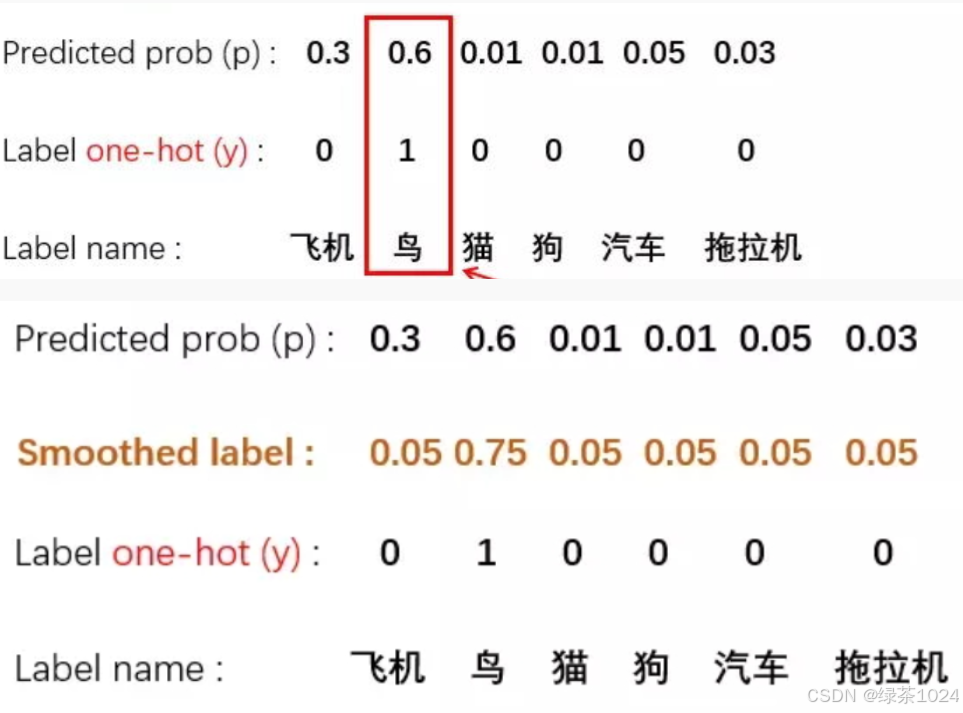
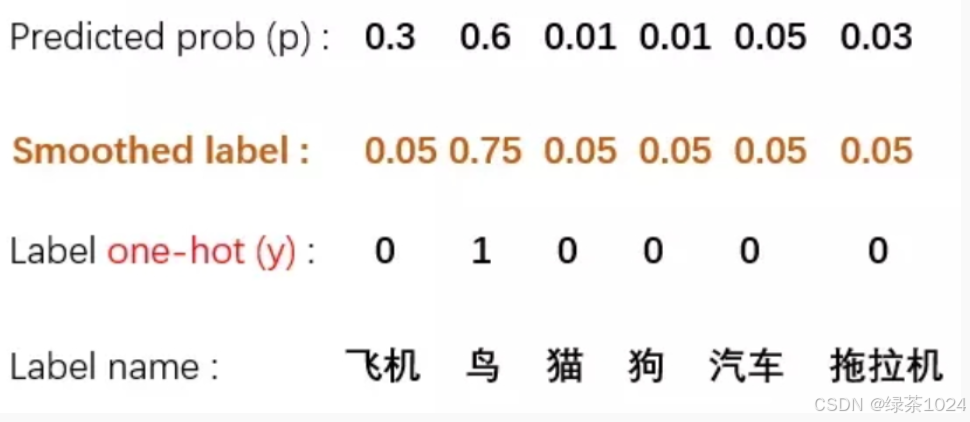
label_smoothing: 标签平滑(label smoothing)。标签平滑是一种正则化技术,用于减少模型对训练数据的过拟合程度。在下图1中模型的比重鸟为1,其他的为0,意思是模型不是鸟的通通都是错误图片,但其实这是不对的,容易产生过拟合,并且对于模型的泛化能力也有影响,正确的做法应该将比重分散开来,如下图2.
CBAM:
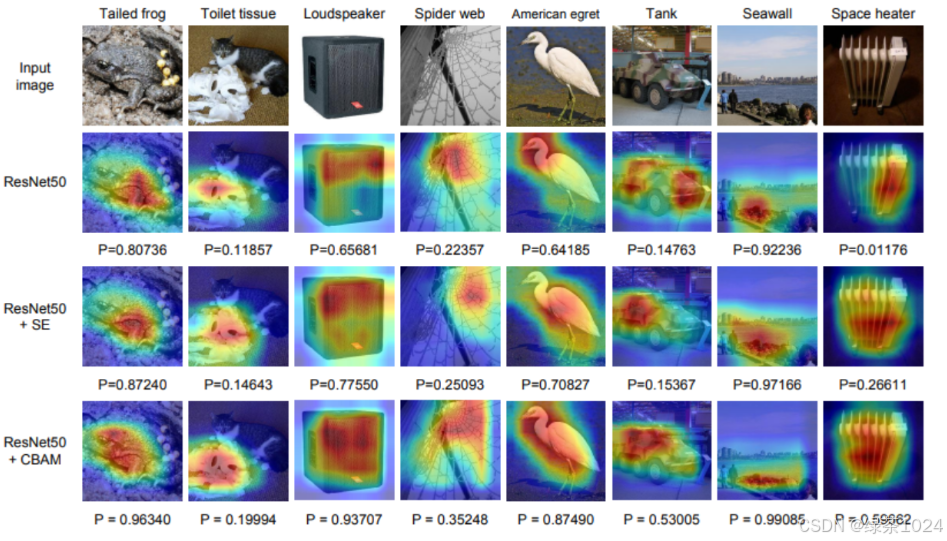
轻量级的卷积注意力模块,简单来说就是注意力机制,不同的图片要提取的特征,注意的模块的不同,如鸟要注意头、翅膀、脚,车要注意轮子、车头、车身等等
YOLOV6与YOLOV7:
推理加速,使用了RepVGG是基于VGG网络实现的,VGG:是一种深度卷积神经网络,使用多个3x3的卷积核堆叠来代替大尺寸的卷积核
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









