






VIT(Vision TrousFarmar)
Attention(注意力机制)
开始起源于图像识别,后来在TrousFarmar领域不断发扬
原理:通过不断加权求和对全局进行感知
RNN模型
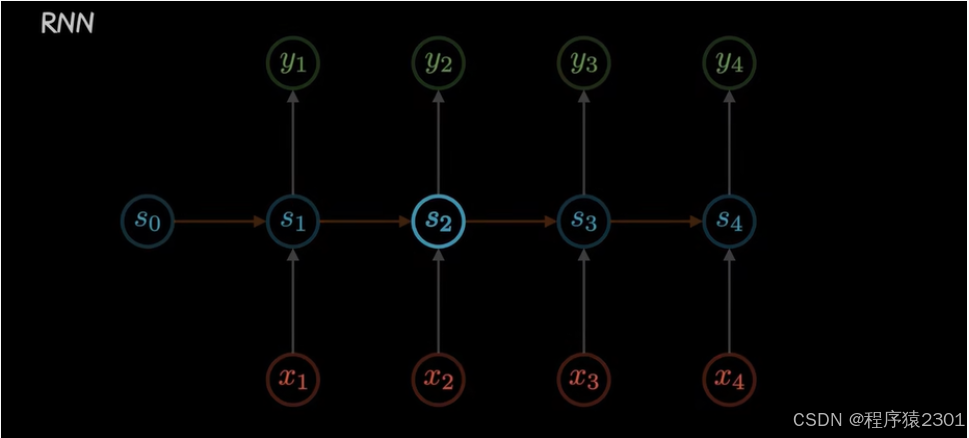
每一时刻的状态如S2不仅仅包含当前时刻的输入x含包含前一时刻的状态如S1
Encoder-Decoder模型
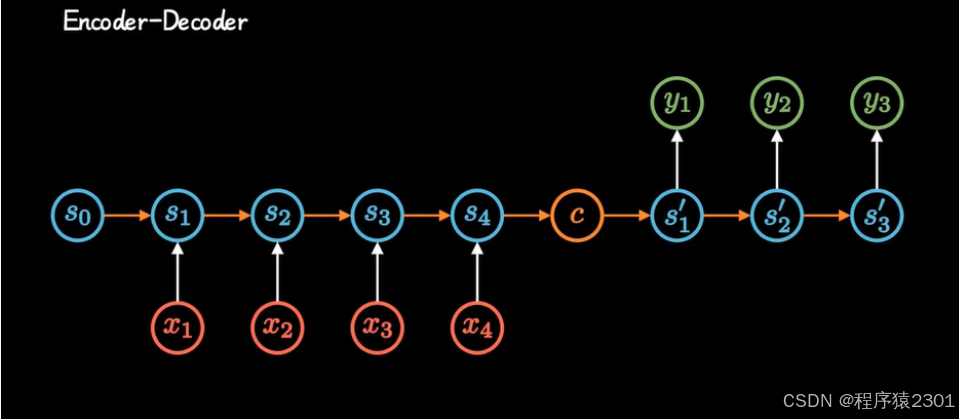
在RNN的基础之上建立,由两个RNN层结合而成,先对每一个输入x进行编码,集合成编码c,在进行解码,输出为y,但这种无论输入x为多少都编码成一个统一长度的编码c的方式会导致精度下降。
Attention机制
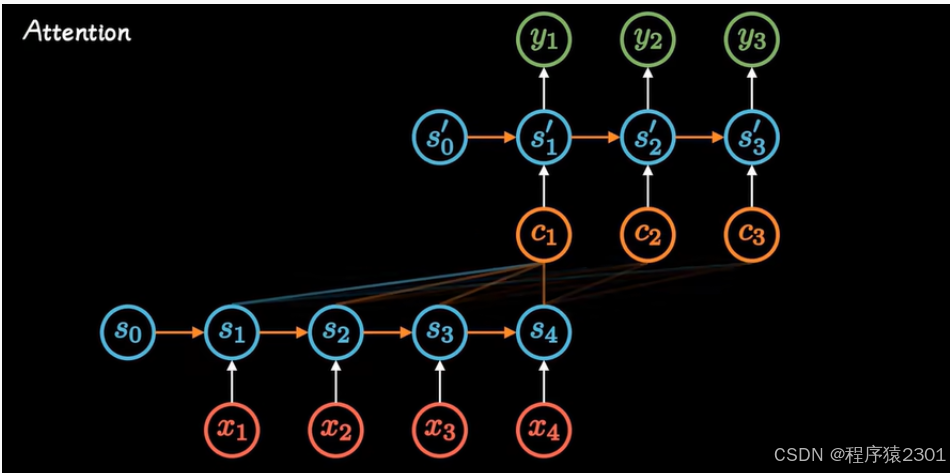
在Encoder-Decoder模型基础上改进而成,在Encoder阶段计算每个输入与其他输入的关联,通过每个时间有着不同的编码c来解决精度下降,比如只有状态s1时只有编码c1,有着状态s1,s2时有编码c1,编码c2,等等,通过Attention我们打破了只能利用Encoder形成单一向量的限制,让每一时刻,模型都能动态地看到全局信息,将注意力集中到对当前输出最重要的信息上
Self-Attention机制
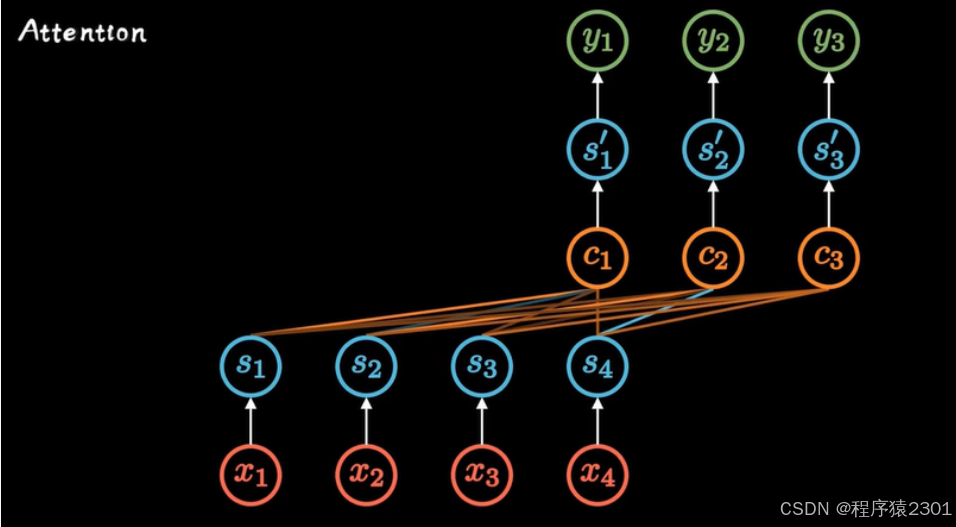
在Attention机制上改进而成,删掉了RNN模型中表示顺序的箭头,在Encoder阶段计算每个输入与其他输入的关联,而输出不仅仅受限与当前的输出还有以前的输出。
Attention的3大优点:参数更少,速度更快,效果更好
Transformer模型
模型架构
谷歌2017年提出的网络,在机器翻译效果巨好
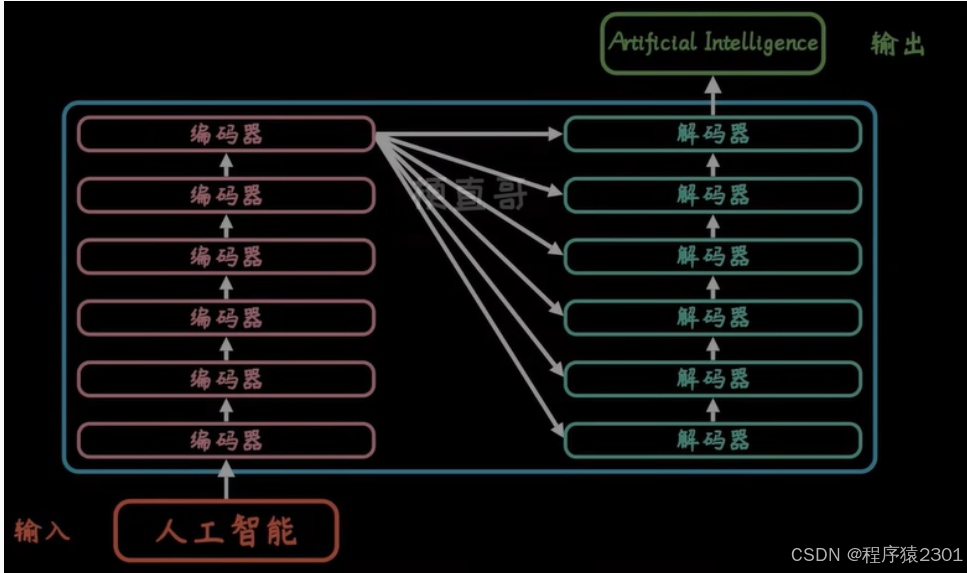
在每一个编码器,解码器中
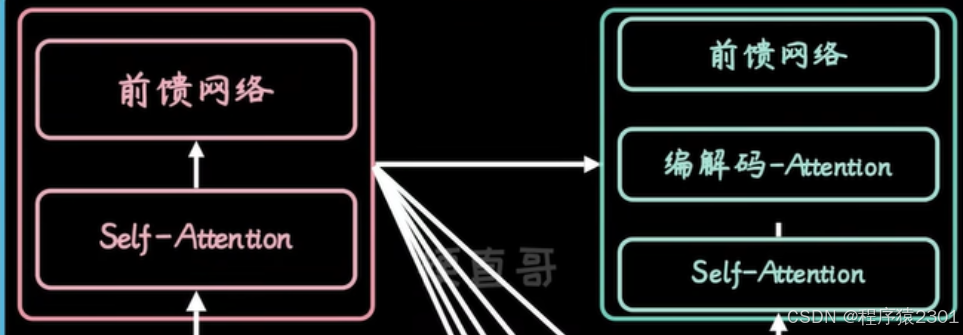
前馈网络:对信息进行一次编码
Self-Attention:对信息的编辑表,通过权重表明每个字眼的关系,嵌入上下文信息
解码器Attention:兼顾全局,在进行解码时不仅仅要考虑当前输出,还要根据全局输出对当前输出进行改变
Self-Attention如何计算的
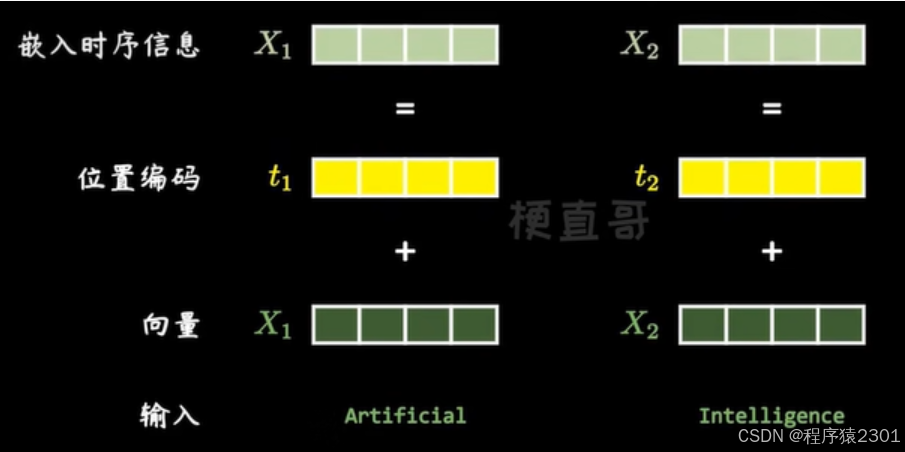
1.输入先加上位置信息
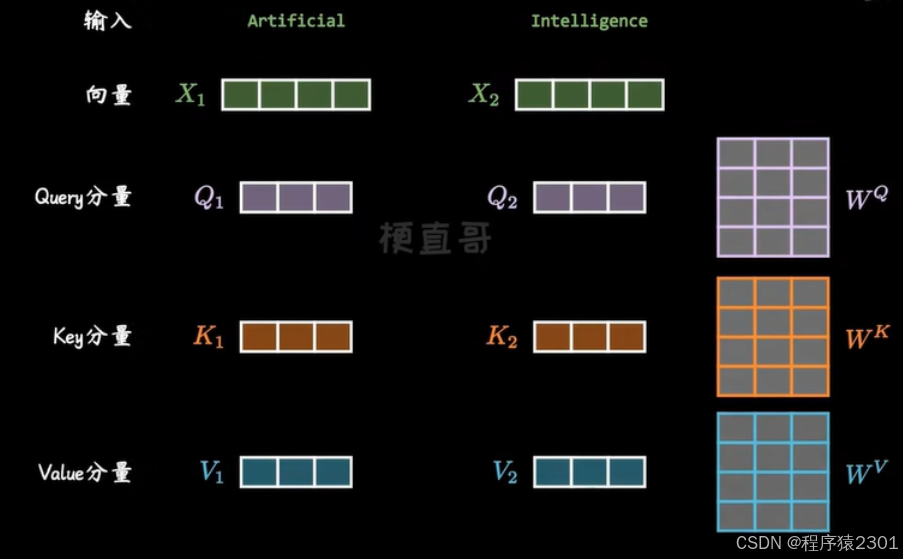
2.乘以已经训练好的Q,K,V向量
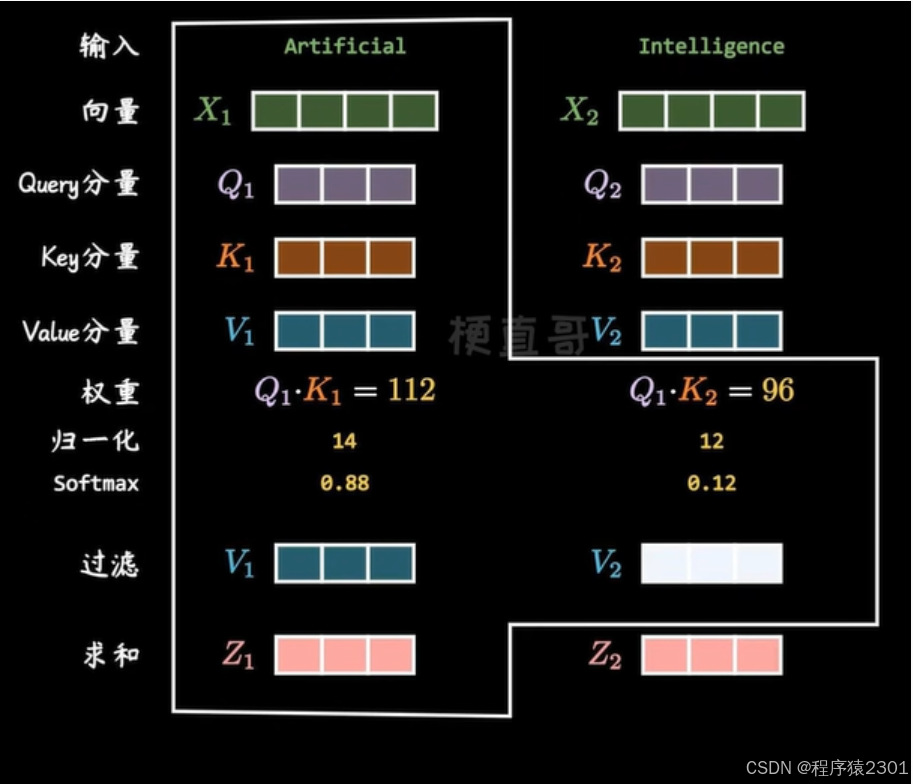
3.再用每个单词的Q向量,和所有单词的 K 向量相乘,得到的权重就是 attention,通过归一化,用 softmax 函数过滤掉不相干的单词,乘以 V 向量后加全求和,就得到了输出向量 Z
BERT模型(Bidirectional EncoderRepresentation from Transfomers)
原型:Encoder
在Transformer模型中,Encoder实现对语言语法和上下文的理解,Decoder实现了一种语言到另一种语言的映射,将Encoder和Decoder分开就分别成为了BERT模型和GPT模型, BERT模型就是双向连接的多个Encoder。
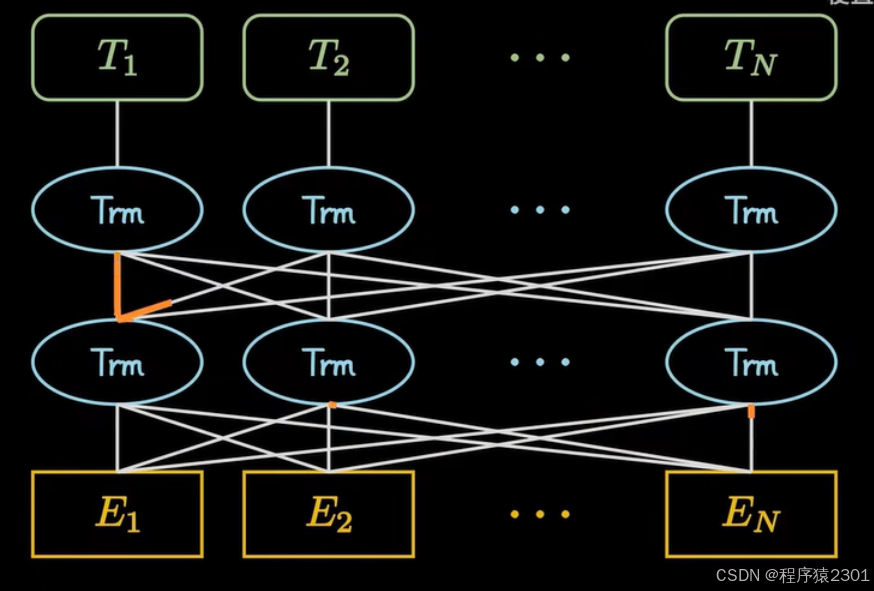
预训练:
语法和上下文的基础理解
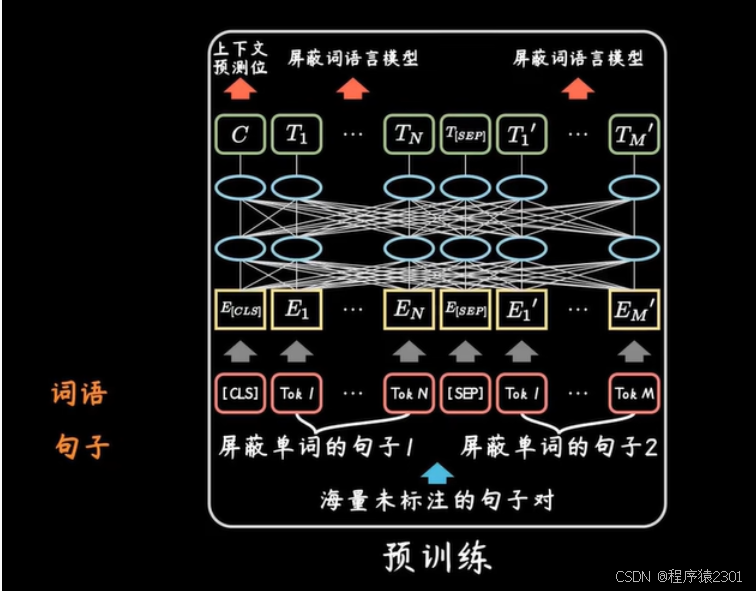
在进行训练时会在完整的句子之上屏蔽一些单词,将句子切割成一些高频率的词根或者词缀,之后预测出频闭后的单词,或者输入的一句话是否是上下文。
精调:
根据具体任务进行加训
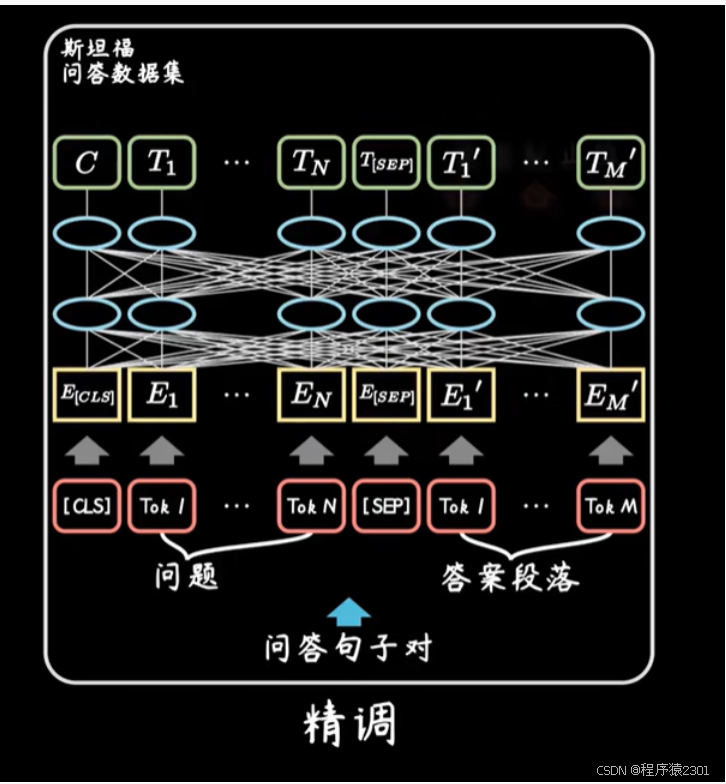
比如在进行问答的预测时,将出入与输出改成问题与答案,与预测后输出的问题。
而Encoder分为三类,作用如下:
Token Embedding:词向量
Segment Embedding:区别两种句子
Position Embedding:位置编码
VIT模型
当BERT模型转战视觉领域就是VIT模型了。
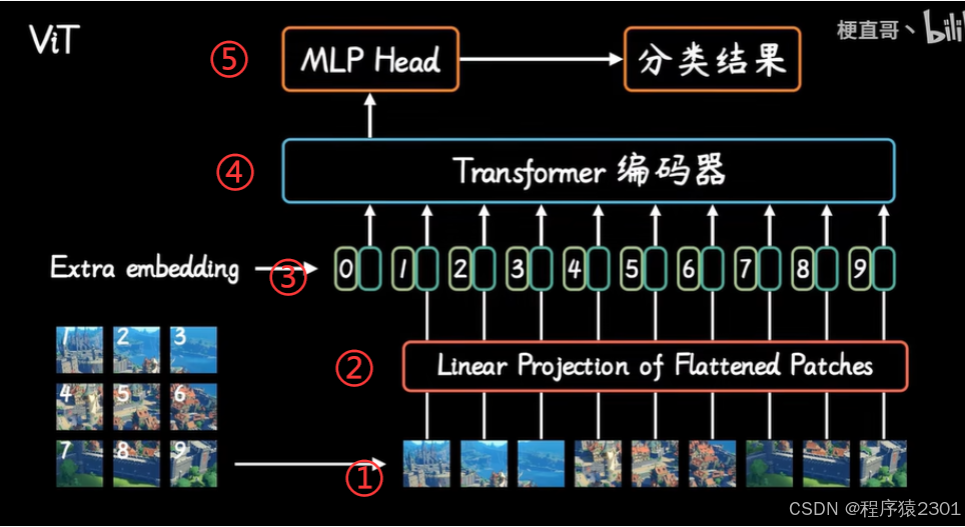
1.patch embedding,把原始二维图像分成小块,成为pach,相当于BERT中输入的句子。
2.经过全连接层将图片压缩成向量。
3.position embedding,就是加入tokens的位置信息,还在开头加上了class token方便做分类。
4.将所有的输入放入Transformer网络。
5.MLP Head就是一个全连接层,把输入时添加的分类向量拿出来。
1,【Attention 注意力机制】激情告白transformer、Bert、GNN的精髓
(https://www.bilibili.com/video/BV1xS4y1k7tn/?spm_id_from=333.788&vd_source=10d66866b4ef8f705e15bf630c035a15)
2,【Transformer模型】曼妙动画轻松学,形象比喻贼好记(https://www.bilibili.com/video/BV1MY41137AK/?spm_id_from=333.788&vd_source=10d66866b4ef8f705e15bf630c035a15)
3,【BERT模型】暴力的美学,协作的力量(https://www.bilibili.com/video/BV1NS4y1e7gz/?spm_id_from=333.788&vd_source=10d66866b4ef8f705e15bf630c035a15)
4,【ViT模型】Transformer向视觉领域开疆拓土……(https://www.bilibili.com/video/BV13B4y1x7jQ/?spm_id_from=333.788&vd_source=10d66866b4ef8f705e15bf630c035a15)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









