



一、引言
YOLO(You Only Look Once)系列算法在目标检测领域取得了显著的成果。作为YOLO家族的最新成员,YOLOv8继承了前几代的优点,并在性能上有了进一步的提升。本文将详细介绍如何使用和训练YOLOv8进行目标检测。
二、YOLOv8简介
2.1 YOLOv8的特点
- 高效性:YOLOv8在保持高准确率的同时,具有更快的推理速度。
- 轻量化:模型参数量和计算量相对较小,适合部署在资源有限的设备上。
- 泛化能力强:能够处理多种类型的数据集和目标检测任务。
2.2 YOLOv8的结构
简要介绍YOLOv8的网络结构,如骨干网络、特征金字塔、检测头等。
三、YOLOv8的安装与配置
3.1 环境准备
使用conda创建一个名叫yolo的虚拟环境,并激活,安装ultralytics包
conda create -n yolov8 python=3.8conda activate yolov8pip install ultralytics如果需要调用GPU,可以自行去PyTorch官网下载适用于自己GPU型号的PyTorch。
3.2 使用官方预训练模型调用本地摄像头实时检测(cpu)
https://github.com/ultralytics/ultralytics
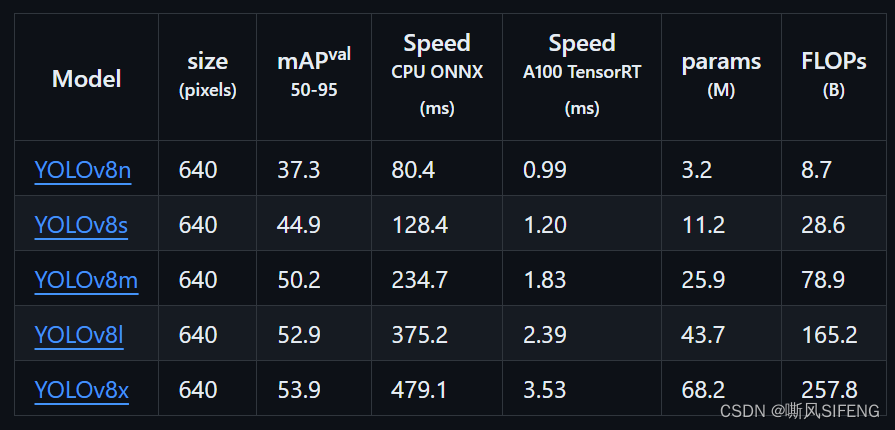
从官方仓库下载yolov8n的预训练文件,也可以根据需求下载其他更大模型。
创建一个名为test.py的文件,并将yolov8n.pt文件放在同一个目录下。文件内容如下:
import cv2
from ultralytics import YOLO
# 加载 YOLOv8 模型
model = YOLO("yolov8n.pt")
# 获取摄像头内容,参数 0 表示使用默认的摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():
success, frame = cap.read() # 读取摄像头的一帧图像
if success:
model.predict(source=frame, show=True) # 对当前帧进行目标检测并显示结果
# 通过按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头资源
cv2.destroyAllWindows() # 关闭OpenCV窗口运行上述脚本即可调用本地摄像头进行实时目标检测。通过按下键盘上的q键可以退出检测循环并释放资源。
3.3 使用官方预训练模型调用本地摄像头实时检测(GPU)
import cv2
import torch
from ultralytics import YOLO
from cv2 import getTickCount, getTickFrequency
# 检查 CUDA 是否可用
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 加载 YOLOv8 模型并移动到 GPU
model = YOLO("yolov8n.pt").to(device) # 你的模型文件地址
# 获取摄像头内容,参数 0 表示使用默认的摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():
loop_start = getTickCount()
success, frame = cap.read() # 读取摄像头的一帧图像
if success:
# 调整图像大小并转换为 RGB
resized_frame = cv2.resize(frame, (640, 640))
resized_frame = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
# 转换为 tensor 并添加批次维度,归一化到0-1之间
frame_tensor = torch.from_numpy(resized_frame).permute(2, 0, 1).unsqueeze(0).float() / 255.0
frame_tensor = frame_tensor.to(device)
# 对当前帧进行目标检测并显示结果
results = model.predict(source=frame_tensor)
# 将结果移回 CPU 进行处理
annotated_frame = results[0].plot()
# 将结果转换回 BGR 格式以用于 OpenCV 显示
annotated_frame = cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR)
loop_time = getTickCount() - loop_start
total_time = loop_time / (getTickFrequency())
FPS = int(1 / total_time)
# 在图像左上角添加FPS文本
fps_text = f"FPS: {FPS:.2f}"
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
font_thickness = 2
text_color = (0, 0, 255) # 红色
text_position = (10, 30) # 左上角位置
cv2.putText(annotated_frame, fps_text, text_position, font, font_scale, text_color, font_thickness)
cv2.imshow('img', annotated_frame)
# 通过按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头资源
cv2.destroyAllWindows() # 关闭OpenCV窗口
四、训练自己的数据集
选择合适的带有 YOLO 格式标注的数据集。data 文件夹下至少包含 train 和 valid 文件夹,以及训练所需要的 yaml 文件。


训练和验证文件夹里面是相对应的图像和标签文件夹。以下为 yaml 文件配置案例,需要根据你的训练目录和标签自行修改:
train: ../train
val: ../valid
nc: 21
names: ['ambulance', 'army vehicle', 'auto rickshaw', 'bicycle', 'bus', 'car', 'garbagevan', 'human hauler', 'minibus', 'minivan', 'motorbike', 'pickup', 'policecar', 'rickshaw', 'scooter', 'suv', 'taxi', 'three wheelers -CNG-', 'truck', 'van', 'wheelbarrow']下面是 yolotrain.py 启动训练的代码:
from ultralytics import YOLO #导入Yolo模块
model = YOLO("yolov8n.pt")
if __name__ == '__main__':
model.train(data="yaml文件地址.yaml", epochs=300)
model.val()训练完成后,模型和训练日志将保存在 runs 文件夹中,其中的 best.pt 是你用自己的数据集训练出来的模型文件。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









