






从零实现transformer 3
用傻瓜模型形式上生成下文
torch.manual_seed(1037)
file_name = "hongloumeng_long.txt"#读取红楼梦全文
with open(file_name, 'r', encoding = 'utf-8') as f:
text = f.read()
encodee_dict = {char:i for i,char in enumerate(list(set(text)))}
decoder_dict = {i:char for i,char in enumerate(list(set(text)))}
encoder = lambda string : [encodee_dict[char] for char in string]
decoder = lambda idx : ''.join([decoder_dict[i] for i in idx])
#试运行生成句子
model = SimpleModel()
model = model.to(device)
split = 0.8
split_len = int(split*len(text))
train_data = text[:split_len]
val_data = text[split_len:]
#生成句子的起点
sentence_len = 20
max_new_tokens = 200
start_idx = random.randint(0, len(val_data)-sentence_len-max_new_tokens)
#上文内容
context = torch.zeros((1,sentence_len), dtype=torch.int32, device = device)
context[0,:] = torch.tensor(encoder(val_data[start_idx:start_idx+sentence_len]))
context_str = decoder(context[0].tolist())
wrapped_context_str = textwrap.fill(context_str, width = wrap_width)
#下文内容
next_context = torch.zeros((1,max_new_tokens), dtype=torch.int32, device = device)
next_context[0,:] = torch.tensor(encoder(val_data[start_idx+sentence_len:start_idx+sentence_len+max_new_tokens]))
next_context_str = decoder(next_context[0].tolist())
next_wrapped_context_str = textwrap.fill(next_context_str, width = wrap_width)
#生成下文
generated_token = model.generate(context, max_new_tokens)
generated_str = decoder(generated_token[0].tolist())
generated_wrapped_context_str = textwrap.fill(generated_str, width = wrap_width)
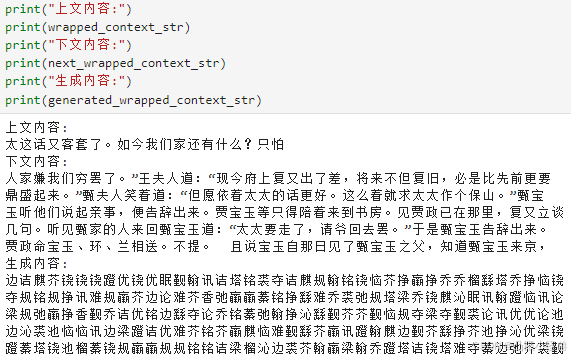
上文内容和下文内容都是原文真实的内容,所以很有逻辑连贯。而生成内容是傻瓜模型随机生成的内容,所以不连贯,现在只是在看形式上是否正确。既然形式上正确,接下来就是优化训练了。可以看到生成内容中相比于真实的下文内容,有很多生僻不常见的字,这是因为本来文章的文字分布就是少数种类的常见字占更多的文字数量,而少数数量的生僻字占了很多文字种类。但在token字典里常见字和生僻字都只占据一个token索引,在随机生成的情况下,生僻字相比原文会有更高的概率生成。
改造傻瓜模型成可训练的模型
加入embedding
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(size, embedding_token_dim)
self.pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
self.network = nn.Linear(embedding_token_dim, size)
def forward(self, inputs, targets = None):
batch_size, sentence_len = inputs.shape#输入为二维矩阵,此时的token是整数而非多维向量
token_emd = self.token_embedding_table(inputs)
pos_emd = self.pos_embedding_table(torch.arange(sentence_len).to(device))
x = token_emd + pos_emd #(batch_size, sentence_len, embedding_token_dim)
logits = self.network(x) #(batch_size, sentence_len, size:(len(uniword)))
if targets is None:
loss = None
else:
B,T,C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
random_tensor = torch.rand(batch_size, sentence_len, size)
logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
def generate(self, token_seq, new_sentence_len):
for _ in range(new_sentence_len):
token_inputs = token_seq[:, -sentence_len:]
logits, loss = self.forward(token_inputs)
logits = logits[:,-1,:]
prob = F.softmax(logits, dim=-1)
new_token = torch.multinomial(prob, 1).to(device)
token_seq = torch.cat([token_seq, new_token], dim=1)
token_output = token_seq[:,-new_sentence_len:]
return token_output
使用cuda的话,要注意这些地方需要加上to(device)
model = model.to(device)
inputs = inputs.to(device)
targets = targets.to(device)
还有其他的一些中间生成向量,如
torch.arange(sentence_len).to(device)
new_token = torch.multinomial(prob, 1).to(device)
在什么地方加上用于训练的神经网络
对输入进行embedding后,x = emb(inputs)
此时x是一个三维张量,维度分别为batch_size * sentence_len * embedding_token_dim
此时我们给模型加入神经网络,是分隔地的给每一个embedding_token_dim加上神经网络,也就是说假如x的维度分别是a * b * c ,那么加入的神经网络的输入节点的数量就是c,这对应着每一个token的embedding向量维度。也就是说,在神经网络预测"你"这个token的下一个token的时候,我们完全只根据"你"这个token的embedding向量去做预测,假如“你”的下一个token被预测为“们”,那么embedding之后的神经网络就做了这样的事情f(“你”) = “们”,当然还有类似的f(“们”)=“在”,f(“在”)=“干”,f(“干”)=“什”,f(“什”)=“么”,f(“么”)=“?”,f(“?”)=“/end”,那么模型就生成了这样的一句话“你们在干什么?”。这并不意味着模型预测"?"的时候,前面的token们“你们在干什”没有发挥作用,这是在添加神经网络之前的注意力机制所做的事情。注意力机制让每一个token能够与其它token相互交流获得信息(生成输出时则只能与前面的token交流,不能看到未来信息),而在预测下一个token时则只根据最新的token进行预测。
尝试运行简单训练模型
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import textwrap
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.manual_seed(1037)
random.seed(1037)
file_name = "hongloumeng_long.txt"#读取红楼梦全文
with open(file_name, 'r', encoding = 'utf-8') as f:
text = f.read()
text_list = list(set(text))
encodee_dict = {char:i for i,char in enumerate(text_list)}
decoder_dict = {i:char for i,char in enumerate(text_list)}
encoder = lambda string : [encodee_dict[char] for char in string]
decoder = lambda idx : ''.join([decoder_dict[i] for i in idx])
uniword = list(set(text))
size = len(uniword)
embedding_token_dim = 16
sentence_len = 16
wrap_width = 40
max_new_tokens = 500
split = 0.8
split_len = int(split*len(text))
train_data = torch.tensor(encoder(text[:split_len]))
val_data = torch.tensor(encoder(text[split_len:]))
batch_size = 16
def get_batch(split='train'):
if split=='train':
data = train_data
else:
data = val_data
idx = torch.randint(0,len(data)-sentence_len-1, (batch_size,))
x = torch.stack([(data[i:i+sentence_len]) for i in idx])
y = torch.stack([(data[i+1:i+1+sentence_len]) for i in idx])
x,y = x.to(device), y.to(device)
return x,y
#傻瓜模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(size, embedding_token_dim)
self.pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
self.network1 = nn.Linear(embedding_token_dim, 100)
self.network2 = nn.Linear(100, size)
def forward(self, inputs, targets = None):
batch_size, sentence_len = inputs.shape#输入为二维矩阵,此时的token是整数而非多维向量
token_emd = self.token_embedding_table(inputs)
pos_emd = self.pos_embedding_table(torch.arange(sentence_len).to(device))
x = token_emd + pos_emd #(batch_size, sentence_len, embedding_token_dim)
x = torch.relu(self.network1(x))
logits = self.network2(x) #(batch_size, sentence_len, size:(len(uniword)))
if targets is None:
loss = None
else:
B,T,C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
# random_tensor = torch.rand(batch_size, sentence_len, size)
# logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
# loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
def generate(self, token_seq, new_sentence_len):
for _ in range(new_sentence_len):
token_inputs = token_seq[:, -sentence_len:]
logits, loss = self.forward(token_inputs)
logits = logits[:,-1,:]
prob = F.softmax(logits, dim=-1)
new_token = torch.multinomial(prob, 1).to(device)
token_seq = torch.cat([token_seq, new_token], dim=1)
token_output = token_seq[:,-new_sentence_len:]
return token_output
#试运行生成句子
learning_rate = 0.003
max_iters = 2000
print(f"训练内容:{file_name}")
model = SimpleModel()
model = model.to(device)
print(sum((p.numel() for p in model.parameters()))/1e6, "M parameters")
# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
#训练循环
progress_bar = tqdm(range(max_iters))
for i in progress_bar:
xb,yb = get_batch('train')
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
progress_bar.set_description(f"{loss.item()}")
print("训练结束,生成新的内容")
#生成句子的起点
sentence_len = 16
wrap_width = 40
max_new_tokens = 500
start_idx = random.randint(0, len(val_data)-sentence_len-max_new_tokens)
#上文内容
context = torch.zeros((1,sentence_len), dtype=torch.long, device = device)
context[0,:] = val_data[start_idx:start_idx+sentence_len]
context_str = decoder(context[0].tolist())
wrapped_context_str = textwrap.fill(context_str, width = wrap_width)
#下文内容
next_context = torch.zeros((1,max_new_tokens), dtype=torch.long, device = device)
next_context[0,:] = val_data[start_idx+sentence_len:start_idx+sentence_len+max_new_tokens]
next_context_str = decoder(next_context[0].tolist())
next_wrapped_context_str = textwrap.fill(next_context_str, width = wrap_width)
#生成下文
generated_token = model.generate(context, max_new_tokens)
generated_str = decoder(generated_token[0].tolist())
generated_wrapped_context_str = textwrap.fill(generated_str, width = wrap_width)
print("上文内容:")
print(wrapped_context_str)
print("下文内容:")
print(next_wrapped_context_str)
print("生成内容:")
print(generated_wrapped_context_str)
经过500次epoch,模型预测的loss从随机预测的8.5降低到了5.0左右。

可以看出,模型的预测已经有点像正常文章的结构了,都是比较常见的字,很少生僻字,标点也很多。相比之下,模型几乎不经过训练时随机预测的结果是这样子的
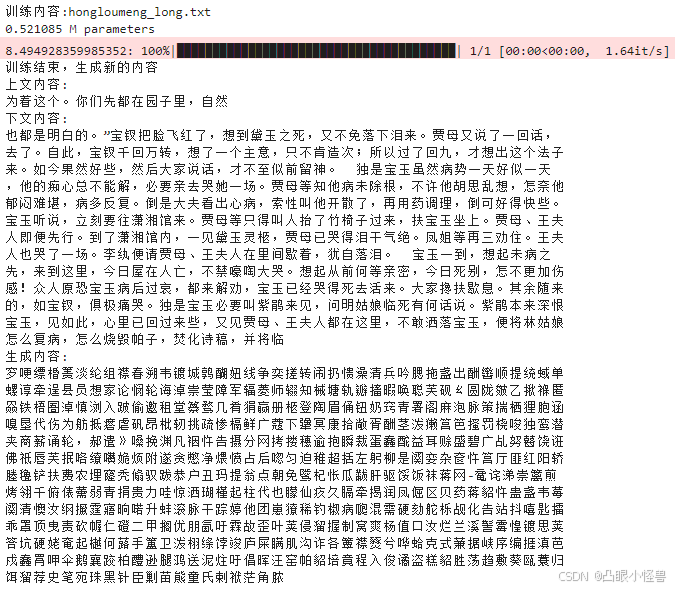
差别会很明显。这表明,至少模型学会了选择常见的字去预测。甚至能预测出一些小词语,比如"宝钗",“丫头”,“宝玉”,“这样”。至少可以说有了预测的雏形。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









