






目录
跟着这个视频学的hugging face
安装环境
我用的conda,首先先创建一个环境
conda create -n namexxx python=3.10
然后安装对应的库
pip install torch2.5.1 torchvision0.20.1 torchaudio==2.5.1 --index-url
https://download.pytorch.org/whl/cu124
还有hugging face库
pip install transformers datasets tokenizers
读取模型
然后这样读取一个模型
from transformers import GPT2LMHeadModel, BertTokenizer
import torch
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = r"C:\Users\11430\Desktop\学习\study\model"
tokenizer = BertTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
model = GPT2LMHeadModel.from_pretrained(model_name, cache_dir=cache_dir)
cache_dir 要写希望模型保存的位置的文件夹,要写绝对路径而不是相对路径,这样会把模型下载到本地。windows下的斜杠是反的,可以在路径字符串前面加上r
下载后的模型是这样子(点进snapshort里面)
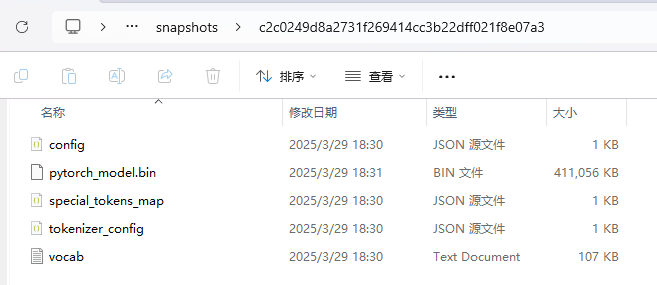
使用模型
然后就可以使用模型了
from transformers import pipeline
generator = pipeline(task='text-generation',model=model, tokenizer = tokenizer, device='cuda')
generator(text_inputs="今天天气真好啊",max_length = 50, num_return_sequences=1)

整体使用还是蛮简单的。不过下载模型的时候,需要用到vpn
我是在自己的电脑上下载了模型,然后把模型搬运到不能用vpn的服务器上用,那么要在参数中添加本地模式local_files_only=True
from transformers import GPT2LMHeadModel, BertTokenizer
import torch
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = "/home/zijian/zijian_cv/transformer/model"
tokenizer = BertTokenizer.from_pretrained(model_name, cache_dir=cache_dir, local_files_only=True)
model = GPT2LMHeadModel.from_pretrained(model_name, cache_dir=cache_dir,local_files_only=True)
下好模型后也可以不需要vpn运行了
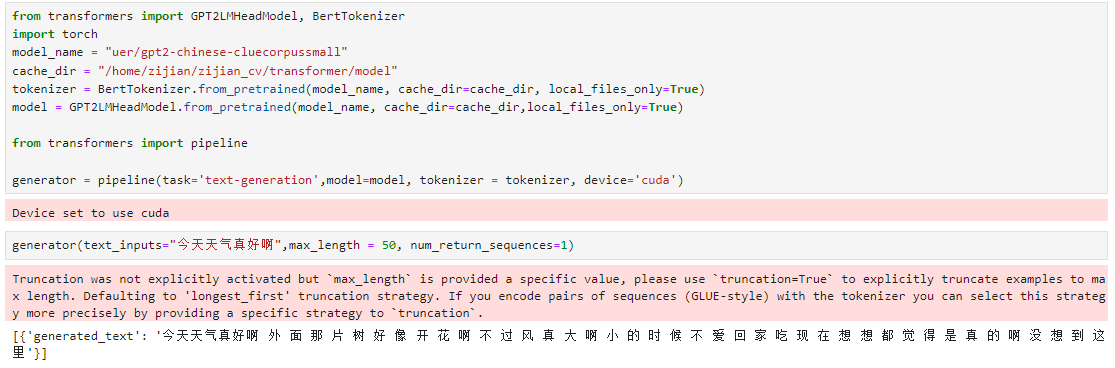
使用预训练模型续写红楼梦
text = "为着这个。你们先都在园子里,自然也都是明白的。”宝钗把脸飞红了,想到黛玉之死,又不免落下泪来。贾母又说了一回话,去了。自此,宝钗千回万转,想了一个主意,只不肯造次;所以过了回九,才想出这个法子来。如今果然好些,然后大家说话,才不至似前留神。独是宝玉虽然"
generator(text_inputs=text,max_new_tokens = 200, num_return_sequences=1)

有一些随机性的参数可以调,影响还是蛮大的
temperature=0.8,top_k=50, top_p = 0.9

下载数据集
from datasets import load_dataset,load_from_disk
data_dir = r"C:\Users\11430\Desktop\学习\study\data\datasets"
dataset = load_dataset(path='lansinuote/ChnSentiCorp', cache_dir=data_dir)
print(dataset)
lansinuote/ChnSentiCorp这些数据集仍然是从hugging face网页上搜索找到的,和下载模型时的方法一样
不过这里需要注意一点,如果想要从本地读取数据集,那么就要把dataset保存在本地
使用save_to_disk来保存为hugging face的数据集格式才能使用
dataset.save_to_disk( r"C:\Users\11430\Desktop\学习\study\data/datasets/lansinuote2")
dataset = load_from_disk(r"C:\Users\11430\Desktop\学习\study\data/datasets/lansinuote2")
准备自己的红楼梦数据集
但我们并不需要它提供的数据集,而是要用我们自己的数据集。现在我们有一个红楼梦全文的txt文本,问了一下deepseek老师,它告诉我这样可以获取dataset数据集
import torch
torch.manual_seed(1037)
from datasets import Dataset, DatasetDict
import pandas as pd
# 读取原始文件
with open("hongloumeng_long.txt", "r", encoding="utf-8") as f:
lines = [{"text": line.strip()} for line in f if line.strip()]
# 转换为 Dataset 对象
full_dataset = Dataset.from_pandas(pd.DataFrame(lines))
# 先拆分成训练集(80%)和临时集(20%)
train_test_split = full_dataset.train_test_split(test_size=0.2, shuffle=True)
# 再从临时集中拆分成验证集(50%)和测试集(50%)
val_test_split = train_test_split["test"].train_test_split(test_size=0.5, shuffle=True)
# 合并最终数据集
final_dataset = DatasetDict({
"train": train_test_split["train"],
"validation": val_test_split["train"],
"test": val_test_split["test"]}
)
print(final_dataset)
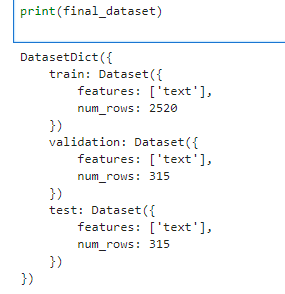
把数据集里的数据进行tokenizer
然后把dataset里的数据进行tokenizer
# 检查并修复特殊token
if tokenizer.eos_token is None:
tokenizer.eos_token = "</s>" # 常见的中文模型eos_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 用eos_token作为pad_token
model.resize_token_embeddings(len(tokenizer))
def tokenize_function(examples):
return tokenizer(
examples["text"], # 输入文本(假设 `examples` 是一个字典,包含 `"text"` 字段)
truncation=True, # 超长截断(超过 `max_length` 时截断)
max_length=512, # 最大 token 长度(BERT 等模型通常限制为 512)
padding="max_length" # 填充至 `max_length`(短于 512 的补 `<pad>`)
)
tokenized_datasets = final_dataset.map(
tokenize_function,
batched=True, # 批量处理提升速度
remove_columns=["text"] # 移除原始文本列(已编码为数字)
)
其实就是把数据中的文本map了一个tokenizer函数

然后生成DataCollatorForLanguageModeling
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 因果语言模型(非掩码语言模型)
)
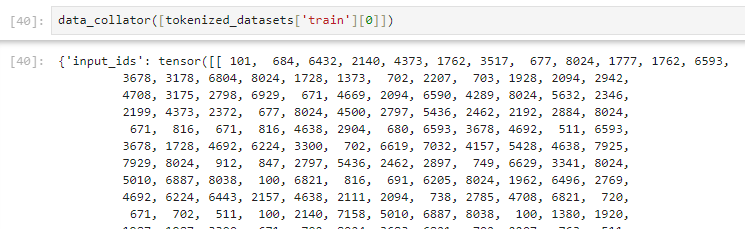
DataCollatorForLanguageModeling生成的label未偏移是什么情况
我遇到了一个麻烦
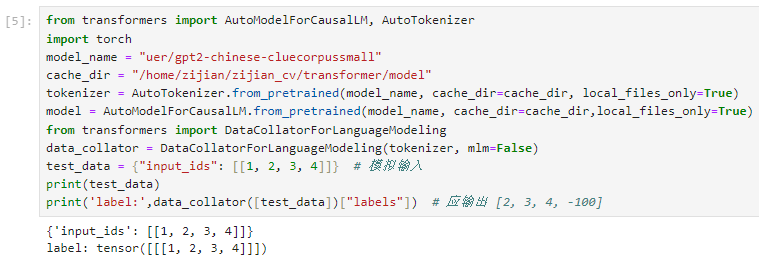
当我的输入时1,2,3,4的时候,我预期输出的label时2,3,4,-100,也就是每个输入的token对应的label时下一个token。但是这里label没有偏移,只是把input_ids复制了过来,这是为什么?
我去读一下源码
先从torch_call查找问题
def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]:
...
if self.mlm:
batch["input_ids"], batch["labels"] = self.torch_mask_tokens(
batch["input_ids"], special_tokens_mask=special_tokens_mask
)
else:
labels = batch["input_ids"].clone()
if self.tokenizer.pad_token_id is not None:
labels[labels == self.tokenizer.pad_token_id] = -100
batch["labels"] = labels
...
当mlm为False的时候,执行
labels = batch["input_ids"].clone() # 先复制input_ids,没有问题
if self.tokenizer.pad_token_id is not None:
labels[labels == self.tokenizer.pad_token_id] = -100# 把pad_token_id填充到-100
batch["labels"] = labels
整个过程没有体现labels被偏移的迹象,难道不是在这里实现的?但是为什么呢,我没有修改源代码啊?我去官网看看代码是不是真的有问题

github上DataCollatorForLanguageModeling的源码也是这样,看起来不是这里的问题
不对,我加了assert False但是没有报错,程序并没有运行这个函数?(最终发现好像是vscode中我修改错了环境,修改的另一个环境中的代码)
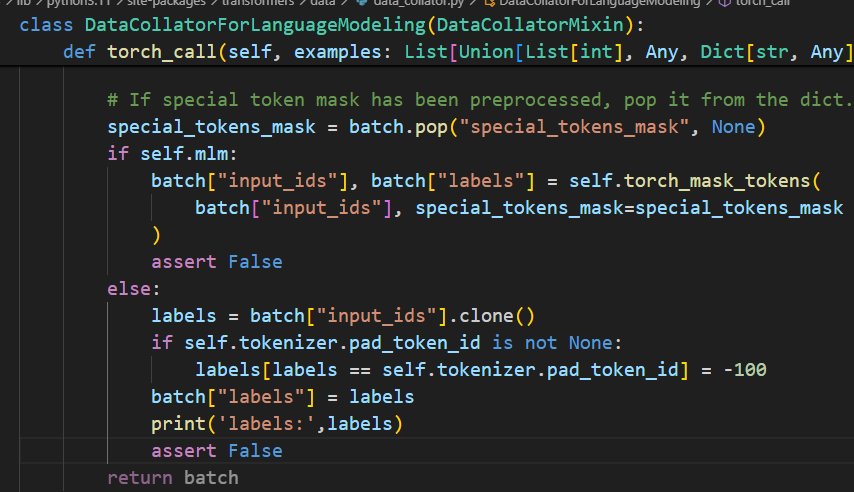
最后终于搞懂了,原来label左移一位的操作是在模型内容完成的,但是deepseek老师的嘴巴好严啊,排查了好久才说出来

我找到的代码为
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(lm_logits.device)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
可以看到在模型内部做了shift操作
mlm参数的意思

再使用DataCollatorForLanguageModeling得到data_collator .它的作用是
1:将样本中的token序列长度填充到最长的token序列长度(虽然前一步的tokenizer已经做过这个事情了?)。
tokenizer和DataCollatorForLanguageModeling的关系
deepseek老师:


设置模型训练的参数
training_args = TrainingArguments(
output_dir="./results", # 模型和训练结果的保存目录
num_train_epochs=3, # 训练的总轮次(整个数据集遍历3次)
per_device_train_batch_size=4, # 每个GPU/CPU的训练批次大小
per_device_eval_batch_size=4, # 每个GPU/CPU的评估批次大小
eval_strategy="epoch", # 评估策略:每个epoch结束后评估
save_strategy="epoch", # 模型保存策略:每个epoch结束后保存
logging_dir="./logs", # 训练日志的保存目录
learning_rate=5e-5, # 初始学习率(常用范围1e-5到5e-5)
fp16=True, # 启用混合精度训练(需要支持FP16的GPU)
)

开始训练模型
RuntimeError: chunk expects at least a 1-dimensional tensor
一训练就遇到了一个bug,找了好久才搞清楚问题出现在哪里。
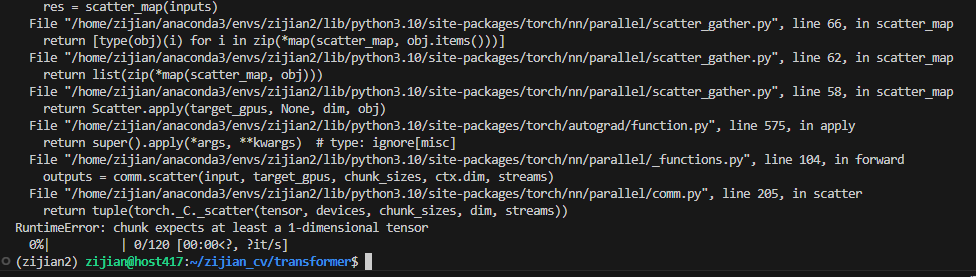
出现了这个报错。这个报错的意思是,在多个GPU并行运行时,程序会尝试将数据分发出去,但是如果此时接受到的数据是一个0维的标量,那么程序就会报错。这个零维的标量是从哪里来的呢?答案就是模型输出的loss。
所以解决办法有两个,一是将模型的loss给unsqueeze(0),升维。我不想改变模型的源代码,所以也可以对Trainer进行操作,写一个Trainer的子类,并重写compute_loss这个函数,将loss升维。然后定义trainer的时候不用父类Trainer而是子类SafeTrainer就可以了。
class SafeTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
outputs = model(**inputs)
loss = outputs.loss
if loss.dim() == 0: # 标量检查
loss = loss.unsqueeze(0) # 转为 [1]
return (loss, outputs) if return_outputs else loss
trainer = SafeTrainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
)
第二个解决办法就是让禁用多GPU就可以了。在代码中加上两行
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 强制单卡
即可让环境中只有一个GPU能被看到。
修完了bug终于可以训练模型了
初次训练代码
import torch
torch.manual_seed(1037)
from transformers import pipeline
from datasets import Dataset, DatasetDict
import pandas as pd
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 读取原始文件
with open("hongloumeng_long.txt", "r", encoding="utf-8") as f:
lines = [{"text": line.strip()} for line in f if line.strip()]
# 转换为 Dataset 对象
full_dataset = Dataset.from_pandas(pd.DataFrame(lines[:600]))
# 先拆分成训练集(80%)和临时集(20%)
train_test_split = full_dataset.train_test_split(test_size=0.2, shuffle=True)
# 再从临时集中拆分成验证集(50%)和测试集(50%)
val_test_split = train_test_split["test"].train_test_split(test_size=0.5, shuffle=True)
# 合并最终数据集
final_dataset = DatasetDict({
"train": train_test_split["train"],
"validation": val_test_split["train"],
"test": val_test_split["test"]}
)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = "/home/zijian/zijian_cv/transformer/model"
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir,local_files_only=True)
# 检查并修复特殊token
if tokenizer.eos_token is None:
tokenizer.eos_token = "</s>" # 常见的中文模型eos_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 用eos_token作为pad_token
model.resize_token_embeddings(len(tokenizer))
from transformers import pipeline
generator = pipeline(task='text-generation',model=model, tokenizer = tokenizer, device='cuda')
def tokenize_function(examples):
return tokenizer(
examples["text"], # 输入文本(假设 `examples` 是一个字典,包含 `"text"` 字段)
truncation=True, # 超长截断(超过 `max_length` 时截断)
max_length=512, # 最大 token 长度(BERT 等模型通常限制为 512)
padding="max_length" # 填充至 `max_length`(短于 512 的补 `<pad>`)
)
tokenized_datasets = final_dataset.map(
tokenize_function,
batched=True, # 批量处理提升速度
remove_columns=["text"] # 移除原始文本列(已编码为数字)
)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 因果语言模型(非掩码语言模型)
)
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="/home/zijian/zijian_cv/transformer/trained_models/gpt2-finetuned", # 模型和训练结果的保存目录
num_train_epochs=30, # 训练的总轮次(整个数据集遍历3次)
per_device_train_batch_size=4, # 每个GPU/CPU的训练批次大小
per_device_eval_batch_size=4, # 每个GPU/CPU的评估批次大小
eval_strategy="epoch", # 评估策略:每个epoch结束后评估
save_strategy="epoch", # 模型保存策略:每个epoch结束后保存
logging_dir="./logs", # 训练日志的保存目录
learning_rate=5e-5, # 初始学习率(常用范围1e-5到5e-5)
fp16=True, # 启用混合精度训练(需要支持FP16的GPU)
)
for param in model.parameters():
param.requires_grad = False
for param in model.lm_head.parameters():
param.requires_grad = True
from transformers import Trainer
class SafeTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
outputs = model(**inputs)
loss = outputs.loss
if loss.dim() == 0: # 标量检查
loss = loss.unsqueeze(0) # 转为 [1]
return (loss, outputs) if return_outputs else loss
trainer = SafeTrainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
)
sample = next(iter(trainer.get_train_dataloader()))
# # 先用单个batch测试
# sample_batch = data_collator([tokenized_datasets["train"][i] for i in range(2)]).to(device)
# outputs = model(**sample_batch)
# print(outputs) # 确认能正常前向传播
# loss = outputs.loss
# print('loss:',loss)
text = "说话时,宝玉已是三杯过去。李嬷嬷又上来拦阻。宝玉正在心甜意洽之时,和宝、黛姊妹说说笑笑的,那肯不吃。宝玉只得屈意央告:"
generator = pipeline(task='text-generation',model=model, tokenizer = tokenizer, device='cuda')
print(generator(text_inputs=text,max_new_tokens = 60, num_return_sequences=1))
trainer.train() # 启动训练
text = "今天天气真好啊"
generator_new = pipeline(task='text-generation',model=model, tokenizer = tokenizer, device='cuda')
print(generator_new(text_inputs=text,max_new_tokens = 60, num_return_sequences=1))
训练后的输出为:
似乎没有特别的学到红楼梦的语言,可能是我只把最后一层lm_head作为可训练层,可能需要训练更多参数才能让模型变化变大一些。那我试试把所有的参数都进行训练
尝试把全部参数都进行训练
把这几行注释掉,然后再运行。也就是默认模型的参数全部都参与训练
# for param in model.parameters():
# param.requires_grad = False
# for param in model.lm_head.parameters():
# param.requires_grad = True
这里我弄错了一个东西,generator只是会调用模型。也就是说模型训练后,generator的生成结果也会改变,所以我上面的代码不能区分模型训练前后generator的变化。
模型训练前后对比
text = "正值林黛玉在旁,因问宝玉:“在哪里的?”宝玉便说:“在宝姐姐家的。”黛玉冷笑道:“我说呢,"
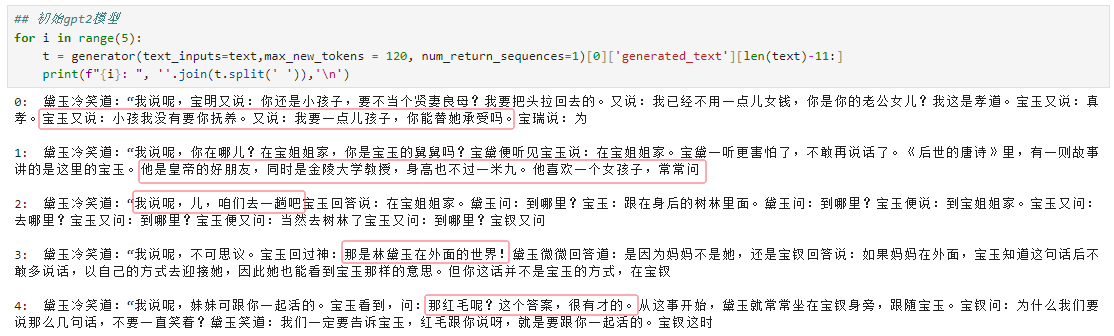
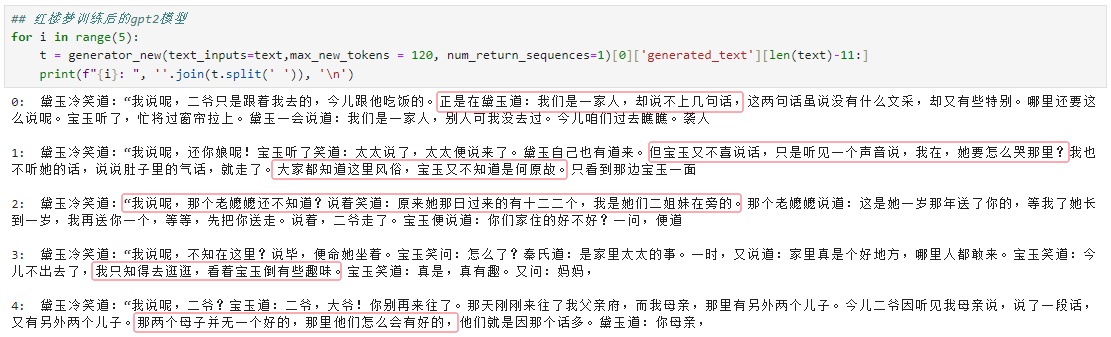
上面是训练前的模型,下面训练后的模型。可以看出来,虽然模型的能力有限,但确实训练后的模型更像红楼梦的说话方式了
改用deepseek r1 1.5B模型来进行训练
小模型的效果不好,改成大一点的模型再看看
未经训练的deepseek r1生成的文字(之后的部分)
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model.eval()
prompt = """请直接续写以下内容,不要添加任何分析或思考过程。只需输出续写部分,不要包含"回答:""我认为:"等前缀。直接写出你的回答
原文开头:
正值林黛玉在旁,因问宝玉:“在哪里的?”宝玉便说:“在宝姐姐家的。”黛玉冷笑道:“我说呢,
续写:<think>\n"""
streamer = TextStreamer(tokenizer, skip_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
model.config.use_cache = False
outputs = model.generate(
**inputs,
max_new_tokens=500,
temperature=0.6,
top_p=0.9,
do_sample=True,
streamer=streamer,
repetition_penalty=1.2,
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
貌似deepseekr1把姐姐这个token弄成olute了,目前还不清楚是什么原因。然后模型经过思考之后,并不能衔接到前文的**”黛玉冷笑道:“我说呢,“**这句话,应该也是模型的参数太小的原因,模型还不够强大,因为只是最小的1.5B模型。最后,之后的生成内容,也并不是红楼梦的语言风格,像别的小说的风格。

然后经过训练之后的deepseek r1模型是这样的,可以看出来结果更像红楼梦的语言了。不过这里的推理过程其实是无效的,因为我没有"推理"这部分的训练数据,所以用掩码将推理过程的loss给覆盖掉了,这也许让模型的输出变得比较天马行空。不过从生成的内容来看,还是比较符合红楼梦的文字风格的。

训练deepseekr1时,要注意输入的类型要按照deepseekr1的模板写,也就是训练文本分为三段,大概是这样
输入+思考过程+ 输出



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









