






换了一个更新的视频学习 课程概述 - PyTorch手搓Transformer
准备数据文本
网上下载了红楼梦,最终目标是用transformer模仿红楼梦里的文字方式
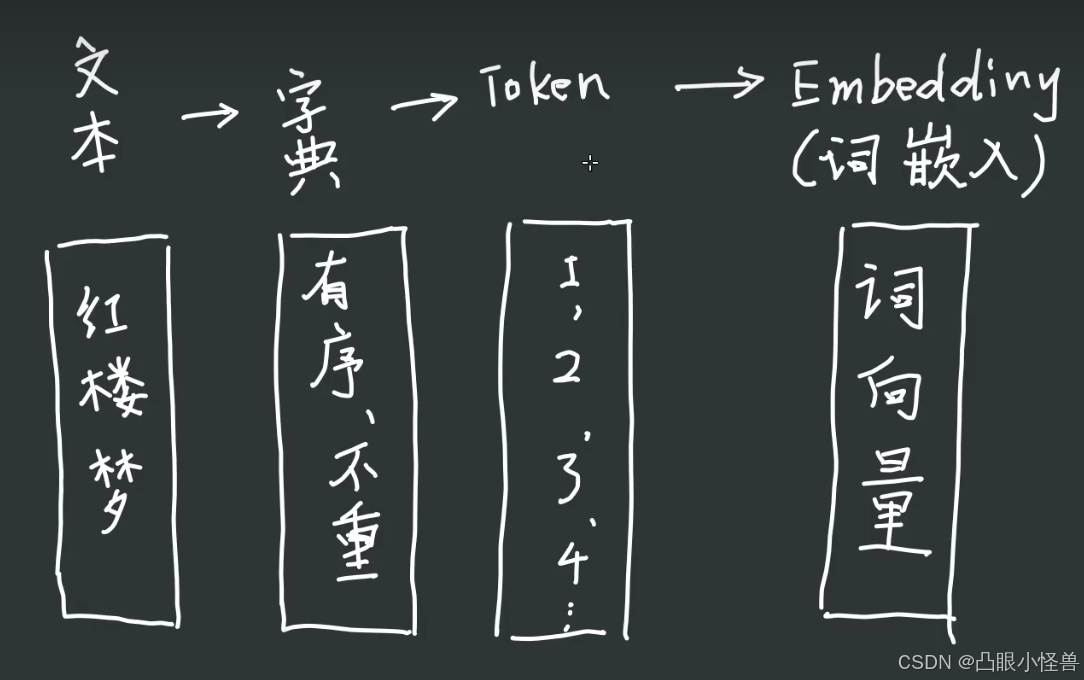
为了方便起见,将红楼梦每一个字作为一个token
[“红”,“楼”,“梦” ]: ["23""276"“12”] …
然后通过embedding,每一个token映射成一个多维向量。
为了简化,假设红楼梦全文是下面两行,这样一共只有几十个不同的字,几十个token:
黛玉再看了一看,冷笑道:“我就知道,别人不挑剩下的,也不给我。”
黛玉笑道:“早知他来,我就不来了。”
首先将红楼梦"全文"读取
import torch
import torch.nn as nn
import torch.functional as F
torch.manual_seed(1037)
file_name = "hongloumeng.txt"
with open(file_name, 'r', encoding = 'utf-8') as f:
text = f.read()
text

构建encoder,decoder
uniword = list(set(text))
encoder_dict = {char : i for i,char in enumerate(list(set(text)))}
decoder_dict = dict(enumerate(list(set(text))))

这里构建一个encoder和decoder,先用set将全部文本中的字符去重,并用list来固定顺序(set是无序的)。这样就可以将每个独一无二的字符(token)与一个独一无二的数字(索引值)一一对应起来。(这里还没有考虑padding,0索引值也被用到了,看看之后有没有用到padding再说)
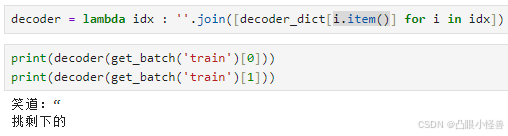
encoder = lambda string : [encodee_dict[char] for char in string]
decoder = lambda idx : ''.join([decoder_dict[i] for i in idx])
print('text:',text[:10])
print('encoder(str):',encoder(text[:10]))
print('decoder(idx):',decoder(encoder(text[:10])))
![text: 黛玉再看了一看,冷笑
encoder(str): [25, 29, 10, 0, 1, 17, 0, 9, 13, 24]
decoder(idx): 黛玉再看了一看,冷笑](https://i-blog.csdnimg.cn/direct/d23da81ca0e54d8d8ba498fecfd20eeb.png)
然后构建encoder,可以将一个字符串映射到其对应的索引列表。而decoder可以将索引列表映射回字符串。
准备train/val data
text为原始文本,我们将text分割成两部分,一部分为train data,一部分为val data
split = 0.8
split_len = int(split*len(text))
train_data = text[:split_len]
val_data = text[split_len:]
print(train_data)
print("****")
print(val_data)
黛玉再看了一看,冷笑道:“我就知道,别人不挑剩下的,也不给我。”
黛玉笑道:“早
****
知他来,我就不来了。”
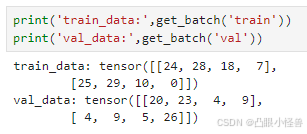
train_data和val_data现在还都只是各自一长串的字符串,但是模型想要的输入不是这样。模型想要的输入格式是batch_size * len_sentens * embedding_token_dim。那我们先从batch_size入手,把train/val data分割成一堆数据,每堆数据有batch_size 句话。
sentence_len = 4
batch_size = 2
def get_batch(split='train'):
if split=='train':
data = torch.tensor(encoder(train_data))
else:
data = torch.tensor(encoder(val_data))
idx = torch.randint(0,len(data)-sentence_len, (batch_size,))
batch_data = torch.stack([(data[i:i+sentence_len]) for i in idx])
return batch_data
首先将原始本文字符串经过encoder编码成数字,然后转化成tensor。根据batch_size的大小,随机从data中选取batch_size个起点,然后从这些起点开始截取相同长度(一句话的长度)的数据,这样就得到了batch_size句话,每句话的长度为sentence_len。此时没批次的训练数据还是二维的向量,这是因为每句话里的每个token还是一个数字,之后我们要把token也embedding成一个多维度的向量,这样训练数据的结构就变成三维了。
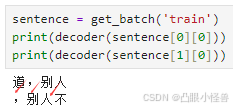
不过这里的数据都变成了tensor,那原来的decoder就用不了了,因为之前创建的decoder的key不是tensor。改一下decoder就好了
但这里还不是完整的train/val data,因为这里只有输入,也就是模型接收到的x,我们还要生成相应的预测值y,才算完整的数据。我们的任务是根据当前看到的最后一个字符,去预测下一个字符,所以如果输入是原文中的[a,b]这一段截取的话,那么预测的输出就是[a+1,b+1],当看到第a个字符时预测原文中第a+1个字符。当然,在输入a预测a+1时,模型会用mask机制遮盖后面的话,不让使用未来信息作弊。
sentence_len = 4
batch_size = 2
device = "cuda" if torch.cuda.is_available() else "cpu"
def get_batch(split='train'):
if split=='train':
data = torch.tensor(encoder(train_data))
else:
data = torch.tensor(encoder(val_data))
idx = torch.randint(0,len(data)-sentence_len-1, (batch_size,))
x = torch.stack([(data[i:i+sentence_len]) for i in idx])
y = torch.stack([(data[i+1:i+1+sentence_len]) for i in idx])
x,y = x.to(device), y.to(device)
return x,y

word embedding
size = len(uniword)
embedding_token_dim = 6
embedding_table = nn.Embedding(size, embedding_token_dim)
print(embedding_table)
word_embedding用nn.Embedding就可以了。两个参数size和embedding_token_dim(不是官方的参数名字),size表示nn.Embedding需要把多少种token映射成向量,如果有x种token(不考虑padding),那token的索引就是0 ~ x-1,那size设置成x,nn.Embedding就可以把0 ~ x-1这x个tensor数字映射成embedding_token_dim维度的向量。

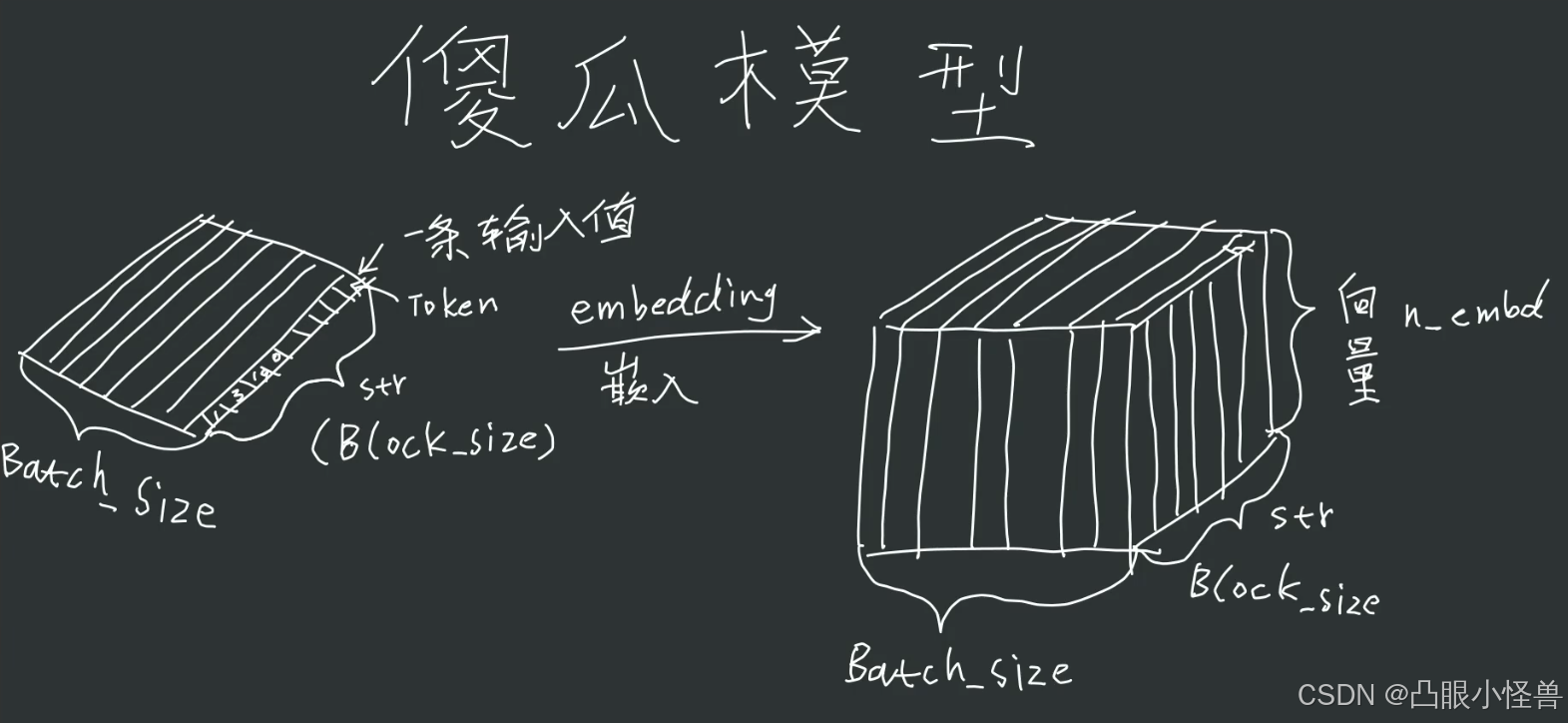
上图sentence[0]表示输入的两句话,每句话里有四个token,并且token用其索引数字表示。embedding将这两句话映射成了两句4x6的tensor. 此时整个输入变成了三维2x4x6的tensor,对应batch_size x sentence_len x token_dim。
刚创建的embedding是随机初始化的,但是这些参数都是可以学习的,在模型训练的过程中,每个token的embedding向量都会逐渐变化,学习到该token特定的语义信息。
position embedding
sentence_len = 4
pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
position embedding的方式和word embedding差不多,区别在于position embedding是将token的位置而非token本身映射成一个embedding_token_dim维度的向量。也就是说position embedding的结果和token内容是无关的。每一句话的position embedding矩阵都完全相同,因为position embedding与token的内容无关。有些position embedding是预先固定的(比如gpt3),但是也可以和word embedding一样随机初始化并在训练过程中逐渐学习。
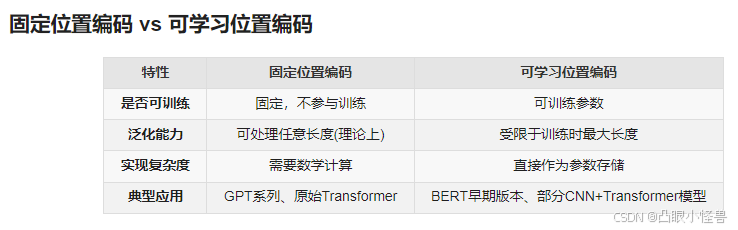
闻了一下deepseek老师固定位置编码和可学习位置编码的区别
傻瓜模型(无注意力机制)
size = len(uniword)
#傻瓜模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__
def forward(self, inputs, targets = None):
batck_size, sentence_len = inputs.shape #输入为二维矩阵,此时的token是整数而非多维向量
random_tensor = torch.rand(batck_size, sentence_len, size)
logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
x,y = get_batch('train')
model = SimpleModel()
model = model.to(device)
out = model(x)
print(out)
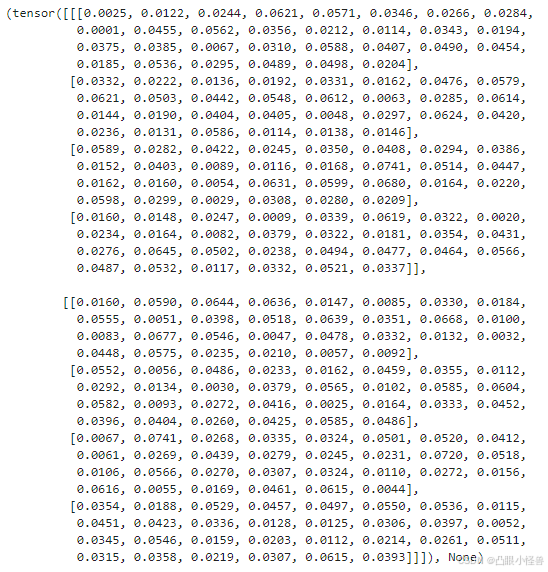
out的结构为batch_size x sentence_len x len(uniword)。len(uniword)则是token的种类数量,因此out中的每一个数字可以看做是某个token被预测为下一个token的概率。由于是傻瓜模型,只是实现了输入输出在形式上的正确形式,但此时模型没有预测能力。
现在再给这个傻瓜模型增加一个生成函数,用于生成预测的文本token
size = len(uniword)
sentence_len = 4
#傻瓜模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
def forward(self, inputs, targets = None):
batck_size, sentence_len = inputs.shape #输入为二维矩阵,此时的token是整数而非多维向量
random_tensor = torch.rand(batck_size, sentence_len, size)
logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
def generate(self, token_seq, new_sentence_len):
for _ in range(new_sentence_len):
token_inputs = token_seq[:, -sentence_len:]
logits, loss = self.forward(token_inputs)
logits = logits[:,-1,:]
prob = F.softmax(logits, dim=-1)
new_token = torch.multinomial(prob, 1).to(device)
token_seq = torch.cat([token_seq, new_token], dim=1)
token_output = token_seq[:,-new_sentence_len:]
return token_output

generate中的参数为3,意味着每一句话都往后预测三个token,现在看来形式上是正确的,虽然现在这个傻瓜模型和“预测”没有任何关系。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









