



从零实现transformer 4
三角掩码矩阵
之前提到我们的神经网络预测下一个token的时候,只使用了当前token这一个向量的信息。但我们想要在预测下一个token的时候,用到前面所有已知的token的信息。也就是说,当预测第i个token的时候,我们希望f(i) = netowrk([token0, token1,…, token(i-1)])。我们用三角掩码矩阵来做这样一个标记,矩阵由1,0两种元素组成,matrix[i][j] == 1表示预测第 j个的token向量用到了第i行的token的向量。实际使用时,由于使用到了softmax函数,所以三角掩码矩阵不用0而是用-inf,这样计算softmax的时候-inf会被转化为0。
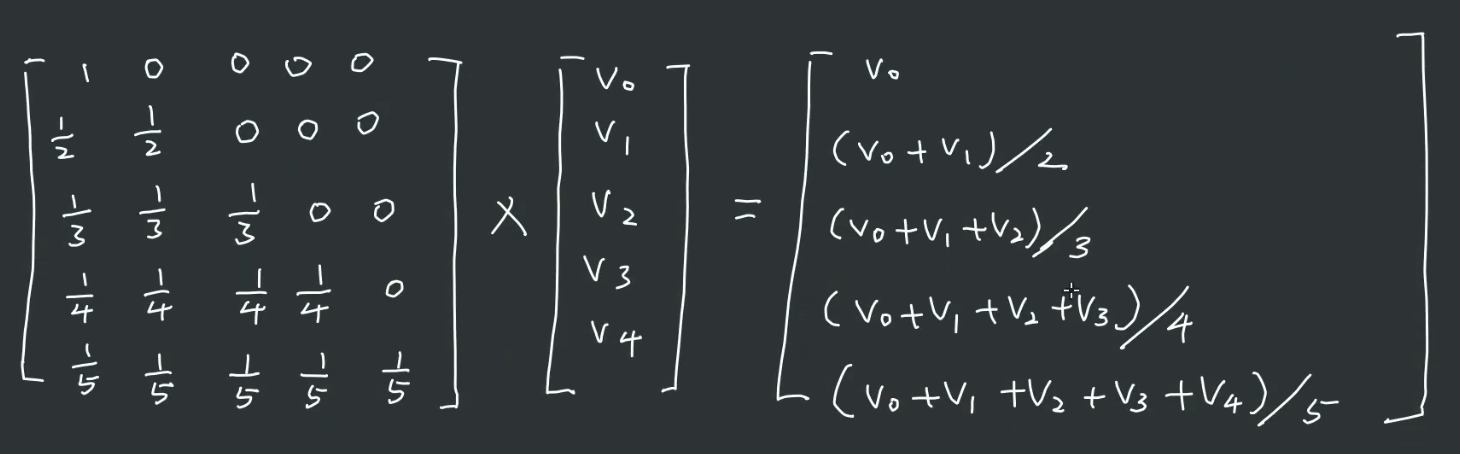
似乎视频里讲的和我想的有差别,但主要的思想是一样的,现在并不是完全的transfomer,key,query都没有出现。三角矩阵的目的便是避免未来信息干扰的情况下,使用到过去的token的信息。
# Head类
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
这样可以方便的构造一个三角矩阵
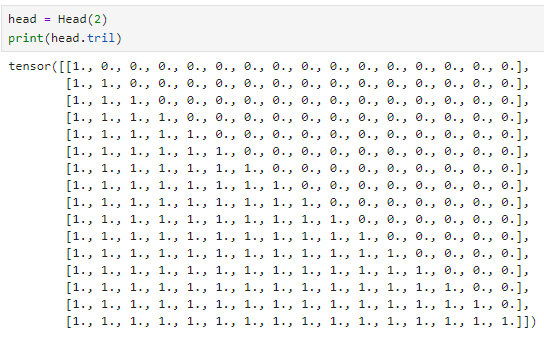
三角矩阵的长宽就是上面设置的一句话的长度(16)
形式上的注意力机制
我们创建一个简易的注意力矩阵,它是平庸的,也就是所有token之间的关联程度都相同
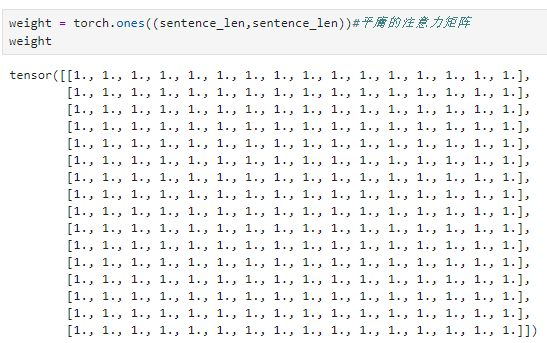
注意力矩阵的大小要和掩码矩阵的大小相同,毕竟掩码矩阵就是用来调整注意力矩阵的,它们之间的矩阵元素有一一对应的关系。
然后我们就可以用掩码矩阵来调节注意力矩阵,比如将注意力矩阵为0的地方调整为9
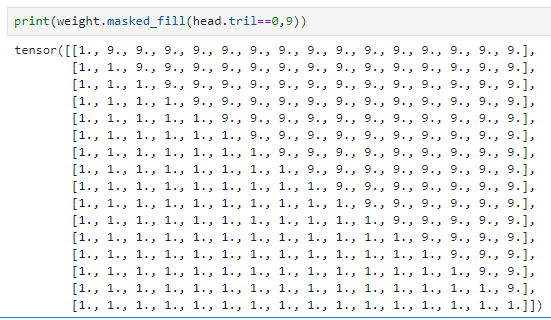
或者-inf
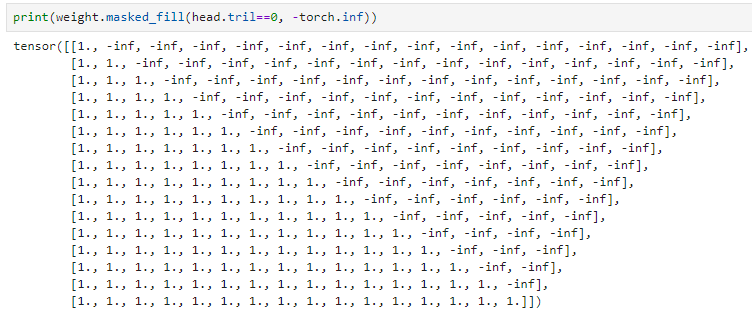
再进行一次softmax,-inf的地方就会都变成0了
把head加进预测模型里再训练一次
# Head类
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
self.dropout = nn.Dropout(0.2)
def forward(self, x):
B,T,C = x.shape
weight = torch.ones(T, T).to(device)#注意力方阵
weight = weight.masked_fill(self.tril==0, float('-inf'))
weight = F.softmax(weight, dim=-1)
weight = self.dropout(weight) #随机将一些值变成0,增加网络的稳定性(网络不会依赖于某几个节点)
v = self.value(x)
out = weight @ v
return out
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(size, embedding_token_dim)
self.pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
self.network1 = nn.Linear(embedding_token_dim, 100)
self.network2 = nn.Linear(100, size)
self.head = Head(embedding_token_dim)
def forward(self, inputs, targets = None):
batch_size, sentence_len = inputs.shape#输入为二维矩阵,此时的token是整数而非多维向量
token_emd = self.token_embedding_table(inputs)
pos_emd = self.pos_embedding_table(torch.arange(sentence_len).to(device))
x = token_emd + pos_emd #(batch_size, sentence_len, embedding_token_dim)
head_out = self.head(x)
logits = torch.relu(self.network1(head_out))
logits = self.network2(logits) #(batch_size, sentence_len, size:(len(uniword)))

看起来模型还是太过简单
那么接下来再往模型中加入注意力机制
注意力机制
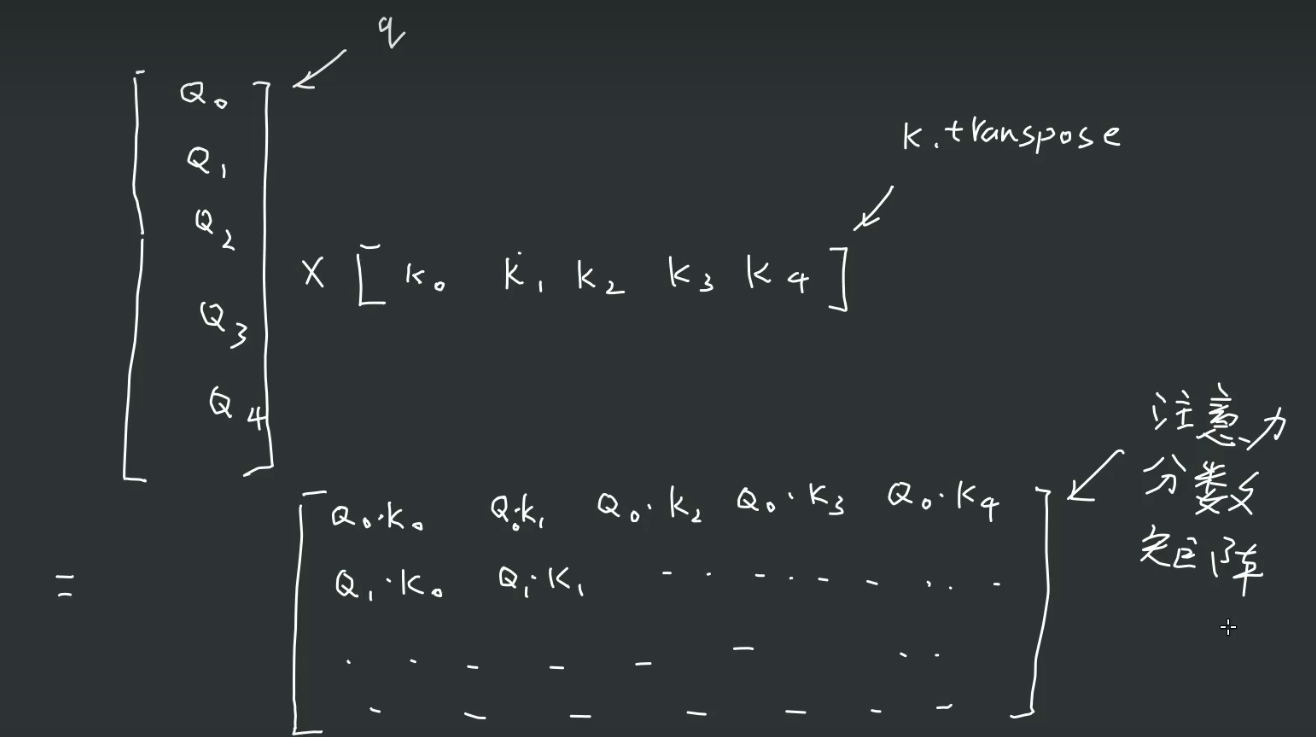
在代码上就是简单的几行
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(embedding_token_dim, head_size, bias=False) # key
self.query = nn.Linear(embedding_token_dim, head_size, bias=False) # query
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
self.dropout = nn.Dropout(0.2)
def forward(self, x):
B,T,C = x.shape
key = self.key(x)
query = self.query(x)
weight = query @ key.transpose(-2,-1) * (key.shape[-1]**(-0.5))#注意力方阵, sentence_len * sentence_len, 并除以sqrt(key.shape[-1]),使方差稳定
在head中加上了key 和query两个线性网络,并且把weight从平凡的全1矩阵改成key和query计算的注意力矩阵。就这个改动。
然后再次训练模型,看看效果
效果初显端倪

效果有点立竿见影啊,比之前生成的内容像人话多了。
凤姐儿,贾母,宝玉,宝钗这种高度关联的词语很明显已经被学习到了,出现频率很高。
只是现在的模型还太简单
到现在为止的代码为
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import textwrap
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.manual_seed(1037)
random.seed(1037)
file_name = "hongloumeng_long.txt"#读取红楼梦全文
with open(file_name, 'r', encoding = 'utf-8') as f:
text = f.read()
text_list = list(set(text))
encodee_dict = {char:i for i,char in enumerate(text_list)}
decoder_dict = {i:char for i,char in enumerate(text_list)}
encoder = lambda string : [encodee_dict[char] for char in string]
decoder = lambda idx : ''.join([decoder_dict[i] for i in idx])
uniword = list(set(text))
size = len(uniword)
embedding_token_dim = 128
sentence_len = 64
batch_size = 32
wrap_width = 40
max_new_tokens = 500
split = 0.8
split_len = int(split*len(text))
train_data = torch.tensor(encoder(text[:split_len]))
val_data = torch.tensor(encoder(text[split_len:]))
def get_batch(split='train'):
if split=='train':
data = train_data
else:
data = val_data
idx = torch.randint(0,len(data)-sentence_len-1, (batch_size,))
x = torch.stack([(data[i:i+sentence_len]) for i in idx])
y = torch.stack([(data[i+1:i+1+sentence_len]) for i in idx])
x,y = x.to(device), y.to(device)
return x,y
# Head类
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(embedding_token_dim, head_size, bias=False) # key
self.query = nn.Linear(embedding_token_dim, head_size, bias=False) # query
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
self.dropout = nn.Dropout(0.2)
def forward(self, x):
B,T,C = x.shape
key = self.key(x)
query = self.query(x)
weight = query @ key.transpose(-2,-1) * (key.shape[-1]**(-0.5))#注意力方阵, sentence_len * sentence_len, 并除以sqrt(key.shape[-1]),使方差稳定
weight = weight.masked_fill(self.tril==0, float('-inf'))
weight = F.softmax(weight, dim=-1)
weight = self.dropout(weight) #随机将一些值变成0,增加网络的稳定性(网络不会依赖于某几个节点)
v = self.value(x)
out = weight @ v
return out
#傻瓜模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(size, embedding_token_dim)
self.pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
self.network1 = nn.Linear(embedding_token_dim, 100)
self.network2 = nn.Linear(100, size)
self.head = Head(embedding_token_dim)
def forward(self, inputs, targets = None):
batch_size, sentence_len = inputs.shape#输入为二维矩阵,此时的token是整数而非多维向量
token_emd = self.token_embedding_table(inputs)
pos_emd = self.pos_embedding_table(torch.arange(sentence_len, device=device), device=device)
x = token_emd + pos_emd #(batch_size, sentence_len, embedding_token_dim)
head_out = self.head(x)
logits = torch.relu(self.network1(head_out))
logits = self.network2(logits) #(batch_size, sentence_len, size:(len(uniword)))
if targets is None:
loss = None
else:
B,T,C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
# random_tensor = torch.rand(batch_size, sentence_len, size)
# logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
# loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
def generate(self, token_seq, new_sentence_len):
for _ in range(new_sentence_len):
token_inputs = token_seq[:, -sentence_len:]
logits, loss = self.forward(token_inputs)
logits = logits[:,-1,:]
prob = F.softmax(logits, dim=-1)
new_token = torch.multinomial(prob, 1).to(device)
token_seq = torch.cat([token_seq, new_token], dim=1)
token_output = token_seq[:,-new_sentence_len:]
return token_output
def estimate_loss(model):
out = {}
estimate_time = 20
model.eval()
for state in ['train','val']:
losses = torch.zeros(estimate_time)
for i in range(estimate_time):
X,Y = get_batch(state)
logits, loss = model(X,Y)
losses[i] = loss
out[state] = losses.mean()
model.train()
return out
#试运行生成句子
learning_rate = 0.003
max_iters = 1000
eval_iter = 50
print(f"训练内容:{file_name}")
model = SimpleModel()
model = model.to(device)
print(sum((p.numel() for p in model.parameters()))/1e6, "M parameters")
# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
#训练循环
progress_bar = tqdm(range(max_iters))
for i in progress_bar:
if i%eval_iter == 0 or i==max_iters-1:
losses = estimate_loss(model)
print(losses)
print(f"train_loss{losses['train']:.4f}, val_loss{losses['val']:.4f}")
xb,yb = get_batch('train')
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
progress_bar.set_description(f"{loss.item()}")
print("训练结束,生成新的内容")
start_idx = random.randint(0, len(val_data)-sentence_len-max_new_tokens)
#上文内容
context = torch.zeros((1,sentence_len), dtype=torch.long, device = device)
context[0,:] = val_data[start_idx:start_idx+sentence_len]
context_str = decoder(context[0].tolist())
wrapped_context_str = textwrap.fill(context_str, width = wrap_width)
#下文内容
next_context = torch.zeros((1,max_new_tokens), dtype=torch.long, device = device)
next_context[0,:] = val_data[start_idx+sentence_len:start_idx+sentence_len+max_new_tokens]
next_context_str = decoder(next_context[0].tolist())
next_wrapped_context_str = textwrap.fill(next_context_str, width = wrap_width)
#生成下文
generated_token = model.generate(context, max_new_tokens)
generated_str = decoder(generated_token[0].tolist())
generated_wrapped_context_str = textwrap.fill(generated_str, width = wrap_width)
print("上文内容:")
print(wrapped_context_str)
print("下文内容:")
print(next_wrapped_context_str)
print("生成内容:")
print(generated_wrapped_context_str)
使用colab上的免费gpu运行
colab上有免费的gpu用,于是可以把代码里的超参数调大,把网络变复杂,看训练后效果有没有提升。除了下面的代码,还要把红楼梦的txt文件一并上传,要注意编码问题,我在vscode上转成了utf-8编码后再上传才能运行成功。
colab用起来还是蛮简单的colab
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import textwrap
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.cuda.empty_cache()
torch.manual_seed(1037)
random.seed(1037)
file_name = "hongloumeng_long.txt"#读取红楼梦全文
with open(file_name, 'r', encoding = 'utf-8') as f:
text = f.read()
text_list = list(set(text))
encodee_dict = {char:i for i,char in enumerate(text_list)}
decoder_dict = {i:char for i,char in enumerate(text_list)}
encoder = lambda string : [encodee_dict[char] for char in string]
decoder = lambda idx : ''.join([decoder_dict[i] for i in idx])
uniword = list(set(text))
size = len(uniword)
embedding_token_dim = 512 # 尽量是2的次方数
sentence_len = 512
batch_size = 32
wrap_width = 40
max_new_tokens = 256
split = 0.8
split_len = int(split*len(text))
train_data = torch.tensor(encoder(text[:split_len]))
val_data = torch.tensor(encoder(text[split_len:]))
def get_batch(split='train'):
if split=='train':
data = train_data
else:
data = val_data
idx = torch.randint(0,len(data)-sentence_len-1, (batch_size,))
x = torch.stack([(data[i:i+sentence_len]) for i in idx])
y = torch.stack([(data[i+1:i+1+sentence_len]) for i in idx])
x,y = x.to(device), y.to(device)
return x,y
# Head类
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(embedding_token_dim, head_size, bias=False) # key
self.query = nn.Linear(embedding_token_dim, head_size, bias=False) # query
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
self.dropout = nn.Dropout(0.2)
def forward(self, x):
B,T,C = x.shape
key = self.key(x)
query = self.query(x)
weight = query @ key.transpose(-2,-1) * (key.shape[-1]**(-0.5))#注意力方阵, sentence_len * sentence_len, 并除以sqrt(key.shape[-1]),使方差稳定
weight = weight.masked_fill(self.tril==0, float('-inf'))
weight = F.softmax(weight, dim=-1)
weight = self.dropout(weight) #随机将一些值变成0,增加网络的稳定性(网络不会依赖于某几个节点)
v = self.value(x)
out = weight @ v
return out
#傻瓜模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(size, embedding_token_dim)
self.pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
self.network1 = nn.Linear(embedding_token_dim, 100)
self.network2 = nn.Linear(100, size)
self.head = Head(embedding_token_dim)
def forward(self, inputs, targets = None):
batch_size, sentence_len = inputs.shape#输入为二维矩阵,此时的token是整数而非多维向量
token_emd = self.token_embedding_table(inputs)
pos_emd = self.pos_embedding_table(torch.arange(sentence_len,device=device).to(device))
x = token_emd + pos_emd #(batch_size, sentence_len, embedding_token_dim)
head_out = self.head(x)
logits = torch.relu(self.network1(head_out))
logits = self.network2(logits) #(batch_size, sentence_len, size:(len(uniword)))
if targets is None:
loss = None
else:
B,T,C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
# random_tensor = torch.rand(batch_size, sentence_len, size)
# logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
# loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
def generate(self, token_seq, new_sentence_len):
for _ in range(new_sentence_len):
token_inputs = token_seq[:, -sentence_len:]
logits, loss = self.forward(token_inputs)
logits = logits[:,-1,:]
prob = F.softmax(logits, dim=-1)
new_token = torch.multinomial(prob, 1).to(device)
token_seq = torch.cat([token_seq, new_token], dim=1)
token_output = token_seq[:,-new_sentence_len:]
return token_output
def estimate_loss(model):
out = {}
estimate_time = 20
model.eval()
for state in ['train','val']:
losses = torch.zeros(estimate_time)
for i in range(estimate_time):
X,Y = get_batch(state)
logits, loss = model(X,Y)
losses[i] = loss
out[state] = losses.mean()
model.train()
return out
#试运行生成句子
learning_rate = 0.003
max_iters = 1000
eval_iter = 100
print(f"训练内容:{file_name}")
model = SimpleModel()
model = model.to(device)
print(sum((p.numel() for p in model.parameters()))/1e6, "M parameters")
# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
#训练循环
progress_bar = tqdm(range(max_iters))
for i in progress_bar:
# if i%eval_iter == 0 or i==max_iters-1:
# losses = estimate_loss(model)
# print(losses)
# print(f"train_loss{losses['train']:.4f}, val_loss{losses['val']:.4f}")
xb,yb = get_batch('train')
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
progress_bar.set_description(f"{loss.item()}")
print("训练结束,生成新的内容")
start_idx = random.randint(0, len(val_data)-sentence_len-max_new_tokens)
#上文内容
context = torch.zeros((1,sentence_len), dtype=torch.long, device = device)
context[0,:] = val_data[start_idx:start_idx+sentence_len]
context_str = decoder(context[0].tolist())
wrapped_context_str = textwrap.fill(context_str, width = wrap_width)
#下文内容
next_context = torch.zeros((1,max_new_tokens), dtype=torch.long, device = device)
next_context[0,:] = val_data[start_idx+sentence_len:start_idx+sentence_len+max_new_tokens]
next_context_str = decoder(next_context[0].tolist())
next_wrapped_context_str = textwrap.fill(next_context_str, width = wrap_width)
#生成下文
generated_token = model.generate(context, max_new_tokens)
generated_str = decoder(generated_token[0].tolist())
generated_wrapped_context_str = textwrap.fill(generated_str, width = wrap_width)
print("上文内容:")
print(wrapped_context_str)
print("下文内容:")
print(next_wrapped_context_str)
print("生成内容:")
print(generated_wrapped_context_str)

网络超参数变大后,此时模型的参数大概为3,8M,比起真正的大模型还是很少。不过此时,已经有点像人话了,虽然细看还不是人类的文字。
多头注意力机制
前面说的注意力机制,是输入一句话,得到带有这句话token与token之间的权重信息的一组转换后的向量,可以理解为注意力机制给输入的这句话加权了。这样我们预测某个token的下一个token时,用到的就是这句话(这个token之前的token)给这个token加权后的结果来进行预测的,这个token就包含了这句话的语义信息。这样就不是单纯的用一个token预测一个token了。
把这样一个注意力机制看做一个打工人A,那么就是我给打工人A一句话,他思考之后交给了我注意力加权后的一句话。
多头注意力机制就是说我同时招了几十个这样的打工人,A,B,C,D。。。,我把同一句话交给他们每个人进行处理,他们每个人独立的给我一份加权后的话,然后我把这几十句不同加权后的话处理成一句话,再往后就是相同的处理方式预测了。
这样做的好处是,几十个人在训练过程中会养成几十种不同的性格,他们加权的方式就会各有优势。比如A对人名很敏感,B对标点符号很敏感,C对量词介词的用法很敏感之类等等。
当然,用了几个多头注意力机制,在注意力机制上的参数就要翻几倍
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(embedding_token_dim, head_size, bias=False) # key
self.query = nn.Linear(embedding_token_dim, head_size, bias=False) # query
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
self.dropout = nn.Dropout(0.2)
def forward(self, x):
B,T,C = x.shape
key = self.key(x)
query = self.query(x)
weight = query @ key.transpose(-2,-1) * (key.shape[-1]**(-0.5))#注意力方阵, sentence_len * sentence_len, 并除以sqrt(key.shape[-1]),使方差稳定
weight = weight.masked_fill(self.tril==0, float('-inf'))
weight = F.softmax(weight, dim=-1)
weight = self.dropout(weight) #随机将一些值变成0,增加网络的稳定性(网络不会依赖于某几个节点)
v = self.value(x)
out = weight @ v
return out
class MultiheadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(num_heads*head_size, embedding_token_dim)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
多头注意力机制中的单头注意力模块是独立的还是不独立的?
这就是一个多头注意力模块。这里我有个地方困惑了蛮久。看代码中,多头注意力机制是把每个单头注意力模块的结果cat到一起,然后再经过一个大linear层得到输出embedding。而我看3Brown1Blue的视频里说,每个单头注意力机制是分开独立的预测出自己的embedding,然后所有单头注意力预测出来的embedding相加起来得到总的embedding。
不过想明白后发现这两种情况是等价的。
如果说单头注意力模块最后输出embedding使用了x * y的线性层,一共是x*y个参数,那么假如有n个模块,所有的参数加起来便是(x*y)*n个。
那么现在把单头注意力模块的中间结果cat起来,就成了一个x * n的向量,那么线性层的参数就变成了(x*n) * y。是一样的。都是n个x*y,而且(x*n) * y这个线性层中,本来就是1*y重复x*n次并相加的结果,变换一下,自然也是(x*y)重复n次并相加,也就是n个单头注意力的结果相加。
把多头注意力加在代码中,然后把线性参数也调大一点,再在colab上训练看看。colab真的有点好用,谷歌很大气啊。

仍然没有到人类写的文章的水平,不过字与字之间的衔接已经有一些了。毕竟相比于gpt3的175b个参数,我们的参数只有13.7m
colab上的代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import textwrap
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.cuda.empty_cache()
torch.manual_seed(1037)
random.seed(1037)
file_name = "hongloumeng_long.txt"#读取红楼梦全文
with open(file_name, 'r', encoding = 'utf-8') as f:
text = f.read()
text_list = list(set(text))
encodee_dict = {char:i for i,char in enumerate(text_list)}
decoder_dict = {i:char for i,char in enumerate(text_list)}
encoder = lambda string : [encodee_dict[char] for char in string]
decoder = lambda idx : ''.join([decoder_dict[i] for i in idx])
uniword = list(set(text))
size = len(uniword)
embedding_token_dim = 512 # 尽量是2的次方数
num_heads = 8
head_size = embedding_token_dim // num_heads
sentence_len = 512
batch_size = 32
wrap_width = 40
max_new_tokens = 256
split = 0.8
split_len = int(split*len(text))
train_data = torch.tensor(encoder(text[:split_len]))
val_data = torch.tensor(encoder(text[split_len:]))
def get_batch(split='train'):
if split=='train':
data = train_data
else:
data = val_data
idx = torch.randint(0,len(data)-sentence_len-1, (batch_size,))
x = torch.stack([(data[i:i+sentence_len]) for i in idx])
y = torch.stack([(data[i+1:i+1+sentence_len]) for i in idx])
x,y = x.to(device), y.to(device)
return x,y
# Head类
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(embedding_token_dim, head_size, bias=False) # key
self.query = nn.Linear(embedding_token_dim, head_size, bias=False) # query
self.value = nn.Linear(embedding_token_dim, head_size, bias=False) # 线性变换层
self.register_buffer("tril", torch.tril(torch.ones(sentence_len,sentence_len )))#不可变的常量
self.dropout = nn.Dropout(0.2)
def forward(self, x):
B,T,C = x.shape
key = self.key(x)
query = self.query(x)
weight = query @ key.transpose(-2,-1) * (key.shape[-1]**(-0.5))#注意力方阵, sentence_len * sentence_len, 并除以sqrt(key.shape[-1]),使方差稳定
weight = weight.masked_fill(self.tril==0, float('-inf'))
weight = F.softmax(weight, dim=-1)
weight = self.dropout(weight) #随机将一些值变成0,增加网络的稳定性(网络不会依赖于某几个节点)
v = self.value(x)
out = weight @ v
return out
class MultiheadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(num_heads*head_size, embedding_token_dim)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
#傻瓜模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(size, embedding_token_dim)
self.pos_embedding_table = nn.Embedding(sentence_len, embedding_token_dim)
self.network1 = nn.Linear(embedding_token_dim, embedding_token_dim*4)
self.network2 = nn.Linear(embedding_token_dim*4, size)
self.multihead = MultiheadAttention(num_heads, head_size)
def forward(self, inputs, targets = None):
batch_size, sentence_len = inputs.shape#输入为二维矩阵,此时的token是整数而非多维向量
token_emd = self.token_embedding_table(inputs)
pos_emd = self.pos_embedding_table(torch.arange(sentence_len,device=device).to(device))
x = token_emd + pos_emd #(batch_size, sentence_len, embedding_token_dim)
head_out = self.multihead(x)
logits = torch.relu(self.network1(head_out))
logits = self.network2(logits) #(batch_size, sentence_len, size:(len(uniword)))
if targets is None:
loss = None
else:
B,T,C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
# random_tensor = torch.rand(batch_size, sentence_len, size)
# logits = random_tensor/random_tensor.sum(dim = -1, keepdim = True)
# loss = None #傻瓜模型,只是为了跑起来,不训练
return logits, loss
def generate(self, token_seq, new_sentence_len):
for _ in range(new_sentence_len):
token_inputs = token_seq[:, -sentence_len:]
logits, loss = self.forward(token_inputs)
logits = logits[:,-1,:]
prob = F.softmax(logits, dim=-1)
new_token = torch.multinomial(prob, 1).to(device)
token_seq = torch.cat([token_seq, new_token], dim=1)
token_output = token_seq[:,-new_sentence_len:]
return token_output
def estimate_loss(model):
out = {}
estimate_time = 20
model.eval()
for state in ['train','val']:
losses = torch.zeros(estimate_time)
for i in range(estimate_time):
X,Y = get_batch(state)
logits, loss = model(X,Y)
losses[i] = loss
out[state] = losses.mean()
model.train()
return out
#试运行生成句子
learning_rate = 0.0003
max_iters = 1000
eval_iter = 100
print(f"训练内容:{file_name}")
model = SimpleModel()
# model = nn.DataParallel(model, device_ids=[0, 1, 2])
model = model.to(device)
print(sum((p.numel() for p in model.parameters()))/1e6, "M parameters")
# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
#训练循环
progress_bar = tqdm(range(max_iters))
for i in progress_bar:
# if i%eval_iter == 0 or i==max_iters-1:
# losses = estimate_loss(model)
# print(losses)
# print(f"train_loss{losses['train']:.4f}, val_loss{losses['val']:.4f}")
xb,yb = get_batch('train')
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
progress_bar.set_description(f"{loss.item()}")
print("训练结束,生成新的内容")
start_idx = random.randint(0, len(val_data)-sentence_len-max_new_tokens)
#上文内容
context = torch.zeros((1,sentence_len), dtype=torch.long, device = device)
context[0,:] = val_data[start_idx:start_idx+sentence_len]
context_str = decoder(context[0].tolist())
wrapped_context_str = textwrap.fill(context_str, width = wrap_width)
#下文内容
next_context = torch.zeros((1,max_new_tokens), dtype=torch.long, device = device)
next_context[0,:] = val_data[start_idx+sentence_len:start_idx+sentence_len+max_new_tokens]
next_context_str = decoder(next_context[0].tolist())
next_wrapped_context_str = textwrap.fill(next_context_str, width = wrap_width)
#生成下文
generated_token = model.generate(context, max_new_tokens)
generated_str = decoder(generated_token[0].tolist())
generated_wrapped_context_str = textwrap.fill(generated_str, width = wrap_width)
print("上文内容:")
print(wrapped_context_str)
print("下文内容:")
print(next_wrapped_context_str)
print("生成内容:")
print(generated_wrapped_context_str)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









