










 CUDA编程模型中,计算任务由网格、线程块和线程三级结构组织。网格包含线程块,线程块又包含线程,这种层次结构允许大规模并行计算。线程索引计算涉及不同维度的组合,为程序员提供了灵活的编程方式。最大线程数量可达一亿,远超CPU。线程间可通过同步和共享内存进行通信,实现高效并行处理。
CUDA编程模型中,计算任务由网格、线程块和线程三级结构组织。网格包含线程块,线程块又包含线程,这种层次结构允许大规模并行计算。线程索引计算涉及不同维度的组合,为程序员提供了灵活的编程方式。最大线程数量可达一亿,远超CPU。线程间可通过同步和共享内存进行通信,实现高效并行处理。
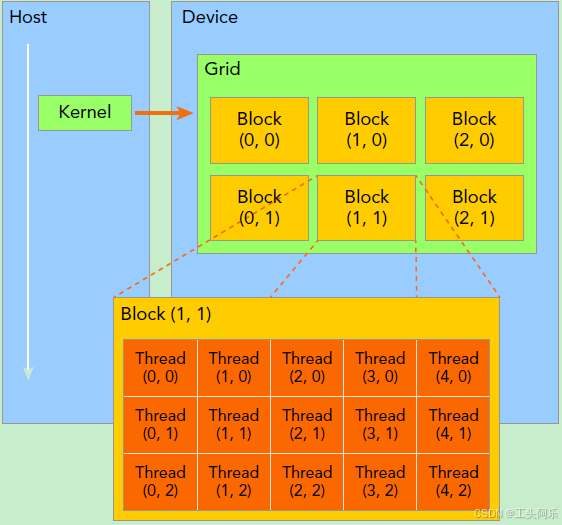
网格(Grid)、线程块(Block)和线程(Thread)的组织关系
CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread)组成,相当于把GPU上的计算单元分为若干(2~3)个网格,每个网格内包含若干(65535)个线程块,每个线程块包含若干(512)个线程,三者的关系如下图:
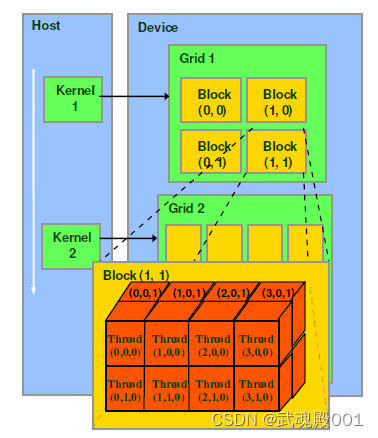
Thread,block,grid是CUDA编程上的概念,为了方便程序员软件设计,组织线程。
thread:一个CUDA的并行程序会被以许多个threads来执行。
block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
grid:多个blocks则会再构成grid。
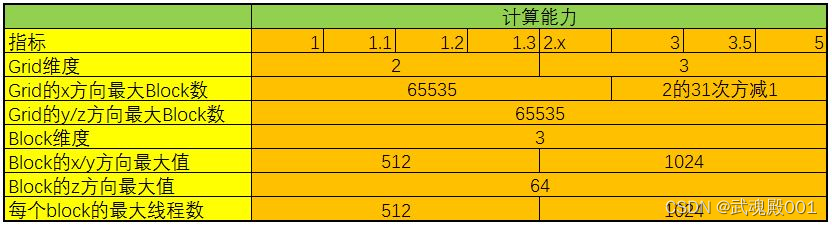
网格(Grid)、线程块(Block)和线程(Thread)的最大数量
CUDA中可以创建的网格数量跟GPU的计算能力有关,可创建的Grid、Block和Thread的最大数量参看以下表格:
在单一维度上,程序的执行可以由多达365535512=100661760(一亿)个线程并行执行,这对在CPU上创建并行线程来说是不可想象的。
线程索引的计算公式
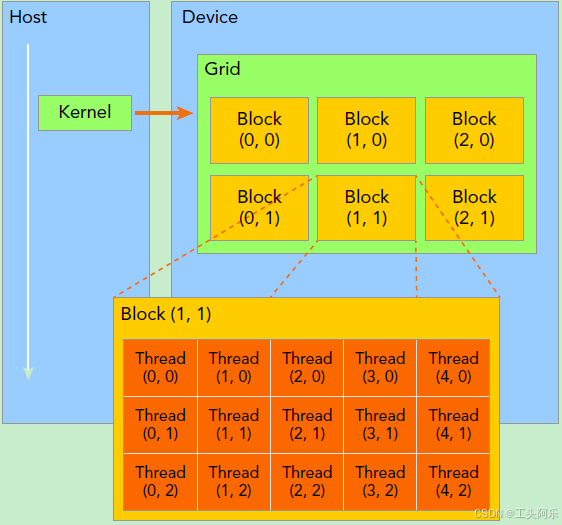
一个Grid可以包含多个Blocks,Blocks的组织方式可以是一维的,二维或者三维的。block包含多个Threads,这些Threads的组织方式也可以是一维,二维或者三维的。
CUDA中每一个线程都有一个唯一的标识ID—ThreadIdx,这个ID随着Grid和Block的划分方式的不同而变化,这里给出Grid和Block不同划分方式下线程索引ID的计算公式。
1、 grid划分成1维,block划分为1维
int threadId = blockIdx.x *blockDim.x + threadIdx.x;
2、 grid划分成1维,block划分为2维
int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x;
3、 grid划分成1维,block划分为3维
int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z
+ threadIdx.z * blockDim.y * blockDim.x
+ threadIdx.y * blockDim.x + threadIdx.x;
4、 grid划分成2维,block划分为1维
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int threadId = blockId * blockDim.x + threadIdx.x;
5、 grid划分成2维,block划分为2维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
6、 grid划分成2维,block划分为3维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
7、 grid划分成3维,block划分为1维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * blockDim.x + threadIdx.x;
8、 grid划分成3维,block划分为2维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
9、 grid划分成3维,block划分为3维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
例子
以二维的例子,辅助理解
一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明block在grid中的位置,而threaIdx指明线程所在block中的位置。
dim3 即一个(x,y,z)
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void checkIndex(void)
{
printf("x index: %d, threadIdx:(%d,%d,%d) blockIdx:(%d,%d,%d) blockDim:(%d,%d,%d) gridDim(%d,%d,%d)\n",
threadIdx.x + threadIdx.y*blockDim.x + blockIdx.x*blockDim.x*blockDim.y + blockIdx.y*blockDim.x*blockDim.y*gridDim.x,
threadIdx.x,threadIdx.y,threadIdx.z,
blockIdx.x,blockIdx.y,blockIdx.z,
blockDim.x,blockDim.y,blockDim.z,
gridDim.x,gridDim.y,gridDim.z);
printf("------------.\n");
}
int main(int argc,char **argv)
{
dim3 block(2,2);
dim3 grid(2,2);
printf("grid.x %d grid.y %d grid.z %d\n",grid.x,grid.y,grid.z);
printf("block.x %d block.y %d block.z %d\n",block.x,block.y,block.z);
checkIndex<<<grid,block>>>();
cudaDeviceReset();
return 0;
}
结果
nvcc -o
(220) lewele:~/code/cuda/Hello$ ./hello_grid_block_thread.o
grid.x 2 grid.y 2 grid.z 1
block.x 2 block.y 2 block.z 1
x index: 8, threadIdx:(0,0,0) blockIdx:(0,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 9, threadIdx:(1,0,0) blockIdx:(0,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 10, threadIdx:(0,1,0) blockIdx:(0,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 11, threadIdx:(1,1,0) blockIdx:(0,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 4, threadIdx:(0,0,0) blockIdx:(1,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 5, threadIdx:(1,0,0) blockIdx:(1,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 6, threadIdx:(0,1,0) blockIdx:(1,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 7, threadIdx:(1,1,0) blockIdx:(1,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 0, threadIdx:(0,0,0) blockIdx:(0,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 1, threadIdx:(1,0,0) blockIdx:(0,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 2, threadIdx:(0,1,0) blockIdx:(0,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 3, threadIdx:(1,1,0) blockIdx:(0,0,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 12, threadIdx:(0,0,0) blockIdx:(1,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 13, threadIdx:(1,0,0) blockIdx:(1,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 14, threadIdx:(0,1,0) blockIdx:(1,1,0) blockDim:(2,2,1) gridDim(2,2,1)
x index: 15, threadIdx:(1,1,0) blockIdx:(1,1,0) blockDim:(2,2,1) gridDim(2,2,1)
从上面例子可以看出,一共16个线程:分为了2 * 2=4个block,每个block中2 * 2=4个线程,
blockDim:(2,2,1)是固定的,也就是说(blockDim.x, blockDim.y, blockDim.z)是init后保持不变的;
gridDim(2,2,1)是固定的,也就是说(gridDim.x, gridDim.y, gridDim.z)是init后保持不变的。
进而有如下定义:
blockIdx.x:表示当前线程所在的块(block)在网格(grid)中的X维索引。块是并行计算中的一个独立执行单元,网格是块的集合。blockIdx.x用于确定当前线程所在的块的位置。
blockDim.x:表示每个块中X维的线程数量。块中的线程是并行执行的,blockDim.x用于确定每个块中的线程数,从而在程序中进行线程同步和数据划分。
threadIdx.x:表示当前线程在其所属块中的X维索引。每个块中的线程通过threadIdx.x来确定自己在块内的位置。
线程id如何索引
1 一维
按照一维的思路简单理解一下:
具体用下图做个说明,blockIdx.x索引从线程块0~N-1,threadIdx.x从线程0到线程N-1,blockDim.x就是block在一维上的维度(图中是4)
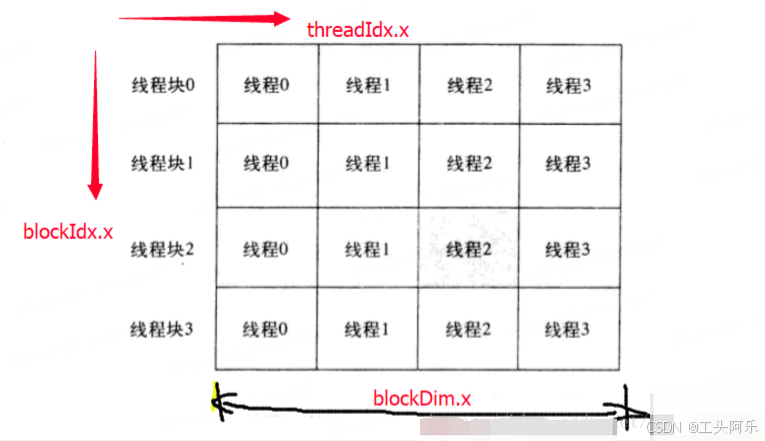
int tid = threadIdx.x + blockIdx.x*blockDim.x;
2 二维线程块索引
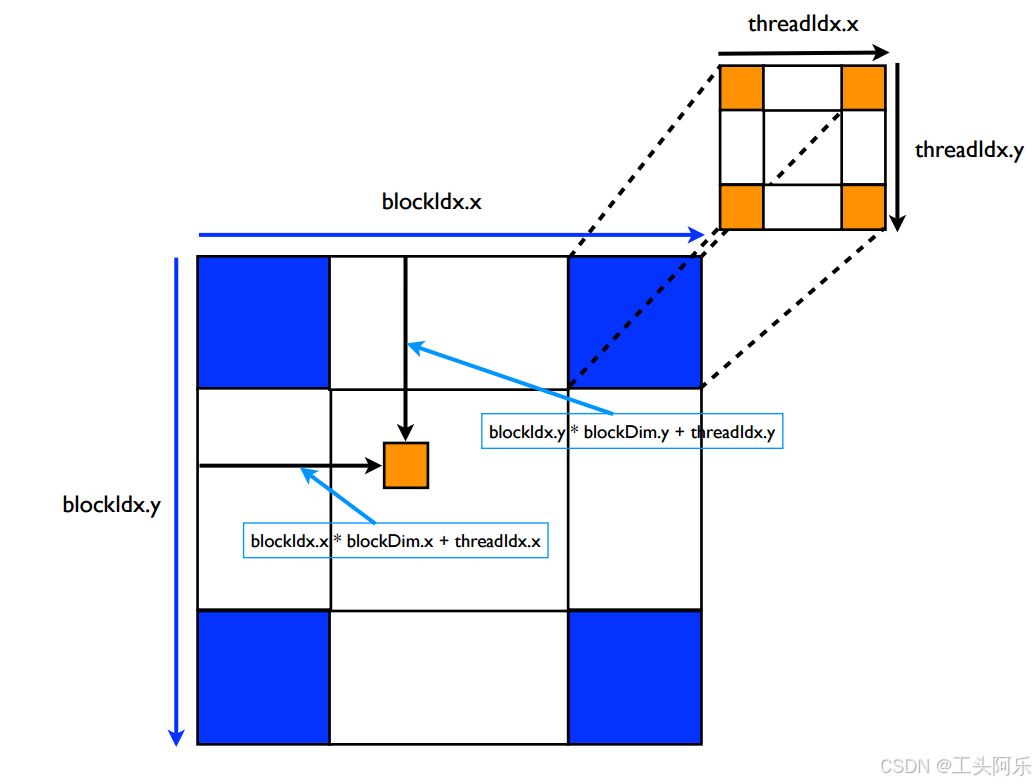
根据上图,取block中某一个线程的索引,按照如下步骤:
借由《GPU高性能编程CUDA实战中文版》中一个图,分析二维情况 ,首先明确二维索引情况意义,为了每一个线程对应一个像素的运算,我们必须要知道这样一个映射函数:f(像素坐标,某一线程),这有点类似数据结构二维索引的感觉,像素坐标很简单(x, y);线程如下索引,这个x,y对应图像的x, y。
注意:这里先要摒弃(c/c++/…)二维数组中查找一个元素,转成一维的思想。还是要以坐标的方式考虑。
求x方向
int x = blockIdx.x * blockDim.x(x方向上block个数) + threadIdx.x
求y方向
int y = blockIdx.y * blockDim.y(y方向上block个数) + threadIdx.y
这样,就获得了每个线程的二维坐标。如果需要转成一维索引,这里才和(c/c++/…)二维数组中查找一个元素的思想一样(x是行方向,y是列方向)
int offset = x + y * blockDim.x;
通过这个图来辅助理解一下:
3 示例代码
假设你有一个二维的线程块,并且你想在一个二维数组上进行某种操作,比如计算梯度。下面是一个简单的示例代码:
二维结构:

__global__ void computeGradient(float* grad, float* input, int width, int height) {
// 计算二维线程块中的线程ID,二维坐标
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
// 检查边界
if (x < width && y < height) {
int tid = y * width + x; // 一维线性索引
// 假设我们在这里计算梯度
grad[tid] = /* 某种计算 */;
}
}
// 在主机端设置网格和块的尺寸
dim3 block(16, 16); // 16x16 的线程块
dim3 grid((width + block.x - 1) / block.x, (height + block.y - 1) / block.y);
// 调用内核函数
computeGradient<<<grid, block>>>(d_grad, d_input, width, height);
在这个示例中:
blockDim.x 和 blockDim.y 分别是线程块在x轴和y轴上的大小。
blockIdx.x 和 blockIdx.y 分别是线程块在网格中的位置。
threadIdx.x 和 threadIdx.y 分别是线程在线程块中的位置。
tid 是一维的线性索引,用于访问二维数组中的元素。
通过这种方式,你可以有效地利用CUDA和cuDNN进行高效的并行计算。


















 2867
2867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









