







CUDA线程执行原理
- CUDA的线程执行原理是理解GPU并行计算的基础。以下是CUDA线程执行的核心概念和原理:
线程层次结构
- CUDA采用了一种层次化的线程组织结构:
- 线程(Thread): 最基本的执行单元
- 线程块(Block): 多个线程组成一个块
- 网格(Grid): 多个块组成一个网格
硬件执行模型
SIMT架构
- CUDA基于SIMT(Single Instruction, Multiple Thread)架构:
- 线程以线程束(Warp)为单位执行,通常每个线程束包含32个线程
- 同一线程束中的线程执行相同的指令,但可以操作不同的数据
- 当线程束中的线程执行路径分叉时(如if-else),会发生线程束分化(Warp Divergence),降低执行效率
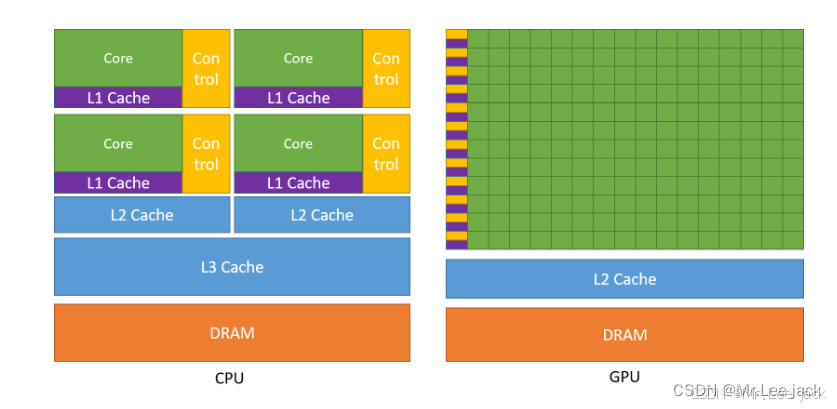
硬件资源分配
SM(Streaming Multiprocessor): GPU的核心计算单元
- 每个SM可以同时处理多个线程块
- SM内部有多个CUDA核心,负责实际的计算工作
调度机制
- 块级调度:线程块被分配到SM上执行
- 线程束调度:SM内部的线程束调度器决定哪些线程束执行
- 零开销线程切换:当一个线程束等待内存操作时,调度器可以立即切换到另一个准备好的线程束
内存访问模式
- 合并访问(Coalesced Access):当线程束中的线程访问连续的内存地址时,可以合并为一次内存事务
- 共享内存(Shared Memory):块内线程可以通过共享内存快速交换数据
- 全局内存(Global Memory):所有线程都可访问,但延迟较高
同步机制
- syncthreads():块内线程同步点,所有线程必须到达此点才能继续
- 不同块之间的线程无法直接同步,需要通过内核函数的结束和启动来实现
Cuda编程模型

实际应用示例
低效率案例:条件分支导致的线程束分化
__global__ void conditionalKernel(float *input, float *output, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
// 基于数据值的条件分支
if (input[idx] > 0) {
// 复杂计算A - 一些线程会执行这部分
for (int i = 0; i < 100; i++) {
output[idx] = sqrt(input[idx]) * sin(input[idx]) + cos(input[idx]);
}
} else {
// 复杂计算B - 其他线程会执行这部分
for (int i = 0; i < 100; i++) {
output[idx] = log(fabs(input[idx]) + 1) * exp(input[idx] * 0.1);
}
}
}
}
// 主机代码
int main() {
// ...
dim3 threadsPerBlock(256);
dim3 numBlocks((N + threadsPerBlock.x - 1) / threadsPerBlock.x);
conditionalKernel<<<numBlocks, threadsPerBlock>>>(d_input, d_output, N);
// ...
}
问题分析
这个内核的利用率低下主要有以下原因:
- 线程束分化:
- 当同一线程束(warp)中的线程遇到if (input[idx] > 0)条件时,一些线程可能执行if分支,而其他线程执行else分支
- 由于SIMT架构,GPU实际上会让线程束中的所有线程执行两个分支,但屏蔽不需要的结果
- 这意味着在最坏情况下,GPU的利用率可能只有50%
- 不平衡的工作负载:
- 如果数据分布不均匀,某些线程束可能大部分执行if分支,而其他线程束执行else分支
- 这会导致一些SM完成工作后闲置,而其他SM仍在忙碌
- 循环中的分支:
- 循环内的计算复杂且不同,进一步加剧了线程束分化的影响
其他常见的低利用率情况
不规则内存访问模式:
__global__ void irregularAccess(float *input, float *output, int *indices, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
// 不连续的内存访问导致非合并访问
output[idx] = input[indices[idx]];
}
}
负载不平衡
__global__ void imbalancedLoad(int *data, int *results, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
int iterations = data[idx]; // 每个线程的工作量不同
int sum = 0;
for (int i = 0; i < iterations; i++) {
sum += i;
}
results[idx] = sum;
}
}
过多的同步点:
__global__ void excessiveSynchronization(float *data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
for (int i = 0; i < 100; i++) {
data[idx] += 1.0f;
__syncthreads(); // 每次迭代都同步,导致大量等待
}
}
}
内核的利用率低优化
分离内核
__global__ void positiveKernel(float *input, float *output, bool *flags, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N && flags[idx]) {
for (int i = 0; i < 100; i++) {
output[idx] = sqrt(input[idx]) * sin(input[idx]) + cos(input[idx]);
}
}
}
__global__ void negativeKernel(float *input, float *output, bool *flags, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N && !flags[idx]) {
for (int i = 0; i < 100; i++) {
output[idx] = log(fabs(input[idx]) + 1) * exp(input[idx] * 0.1);
}
}
}
__global__ void flagData(float *input, bool *flags, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
flags[idx] = (input[idx] > 0);
}
}
// 主机代码
void optimizedApproach(float *d_input, float *d_output, int N) {
bool *d_flags;
cudaMalloc(&d_flags, N * sizeof(bool));
dim3 threadsPerBlock(256);
dim3 numBlocks((N + threadsPerBlock.x - 1) / threadsPerBlock.x);
// 标记数据
flagData<<<numBlocks, threadsPerBlock>>>(d_input, d_flags, N);
// 分别处理正值和负值
positiveKernel<<<numBlocks, threadsPerBlock>>>(d_input, d_output, d_flags, N);
negativeKernel<<<numBlocks, threadsPerBlock>>>(d_input, d_output, d_flags, N);
cudaFree(d_flags);
}
线程协作
__global__ void cooperativeKernel(float *input, float *output, int N) {
__shared__ int positive_count;
__shared__ int negative_count;
__shared__ int positive_indices[256]; // 假设块大小为256
__shared__ int negative_indices[256];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// 初始化
if (tid == 0) {
positive_count = 0;
negative_count = 0;
}
__syncthreads();
// 分类阶段
bool is_positive = false;
if (idx < N) {
is_positive = (input[idx] > 0);
if (is_positive) {
int pos = atomicAdd(&positive_count, 1);
positive_indices[pos] = tid;
} else {
int pos = atomicAdd(&negative_count, 1);
negative_indices[pos] = tid;
}
}
__syncthreads();
// 处理正值
for (int i = 0; i < positive_count; i++) {
if (tid == positive_indices[i]) {
for (int j = 0; j < 100; j++) {
output[idx] = sqrt(input[idx]) * sin(input[idx]) + cos(input[idx]);
}
}
}
// 处理负值
for (int i = 0; i < negative_count; i++) {
if (tid == negative_indices[i]) {
for (int j = 0; j < 100; j++) {
output[idx] = log(fabs(input[idx]) + 1) * exp(input[idx] * 0.1);
}
}
}
}

















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









