







 超级会员免费看
超级会员免费看
 本文介绍了无监督学习的概念,通过聚类算法的应用,如谷歌新闻的新闻分组和市场细分,展示了无监督学习如何在没有标签的数据中发现结构。此外,还提到了鸡尾酒宴问题,说明了无监督学习在音频信号处理中的应用。最后,强调了使用工具如Octave进行机器学习算法原型构建的重要性。
本文介绍了无监督学习的概念,通过聚类算法的应用,如谷歌新闻的新闻分组和市场细分,展示了无监督学习如何在没有标签的数据中发现结构。此外,还提到了鸡尾酒宴问题,说明了无监督学习在音频信号处理中的应用。最后,强调了使用工具如Octave进行机器学习算法原型构建的重要性。
本次我们将介绍第二种主要的机器学习问题。叫做无监督学习。
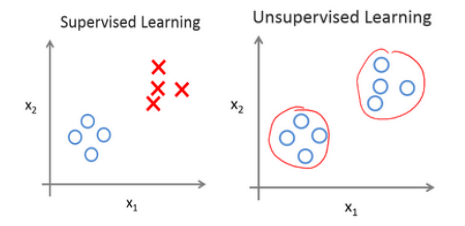 前面已经介绍了监督学习。回想当时的数据集,如图表所示,这个数据集中每条数据都已经标明是阴性或阳性,即是良性或恶性肿瘤。所以,对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案,是良性或恶性了。
前面已经介绍了监督学习。回想当时的数据集,如图表所示,这个数据集中每条数据都已经标明是阴性或阳性,即是良性或恶性肿瘤。所以,对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案,是良性或恶性了。
在无监督学习中,我们已知的数据。看上去有点不一样,不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
聚类应用的一个例子就是在谷歌新闻中。如果你以前从来没见过它,你可以到这个URL网址news.google.com去看看。谷歌新闻每天都在,收集非常多,非常多的网络的新闻内容。它再将这些新闻分组,组成有关联的新闻。所以谷歌新闻做的就是搜索非常多的新闻事件,自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,所以显示到一起。
事实证明,聚类算法和无监督学习算法同样还用在很多其它的问题上。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











