







 本文深入探讨了K-means算法的工作原理,包括随机初始化聚类中心、簇分配、聚类中心移动等关键步骤。介绍了如何通过代价函数最小化实现聚类优化,以及如何避免局部最优解,选择合适的K值。
本文深入探讨了K-means算法的工作原理,包括随机初始化聚类中心、簇分配、聚类中心移动等关键步骤。介绍了如何通过代价函数最小化实现聚类优化,以及如何避免局部最优解,选择合适的K值。
K-meas 算法概述


随机生成K个点,称为聚类中心。K-means算法实际上是一个迭代算法,他有两步动作。在算法的最开始,随机初始化K个聚类中心,坐标位置分别为。第一步是簇分配,第二步是移动聚类中心。遍历图中的每一个点,判断点跟哪个聚类中心的距离更近,进而划分到这个聚类中心名下,并将聚类中心的下标赋给对应样本点
的
,这个步骤其实也是代价函数的最小化过程。然后对所有
的样本点向量求平均值(忽略
)将聚类中心移动到同类点的均值处。重复以上过程,直到各个聚类中心已经不再移动了。如果有一个没有点的聚类中心,则一般做法是移除之。如果仍需保留K个簇,则可以重新随机初始化这一没有点的聚类中心。
K平均算法可以将一堆数据分类为K组,这类似于市场划分,可以应用到产品型号生产中去。
K-meas 算法代价函数

注意,是
代表的簇的聚类中心所在的坐标位置。K平均算法是根据代价函数找到使得其最小的c和u。这个代价函数的每次变动也叫失真。J也称为失真函数。第一步是u不变,找到使得失真函数最小的c。第二部c不变,找到使得失真函数最小的u。
避免局部最优

在算法的一开始,我们需要随机初始化聚类中心的位置。
最好的办法是从训练样本中随机挑选K个点,作为u1...uk。
然而,K平均算法可能收敛到不同的结果,这取决于初始化时聚类状态。我们可以尝试多次随机初始化,运行K算法,计算畸变函数。最后我们选取畸变值最小,也就是代价最小的。
当K较小,即约为2-10时,多次随机初始化效果较好。否则可能虽然有改善,但第一次的值已经相对不错,后面的改善较小。
K值的选择
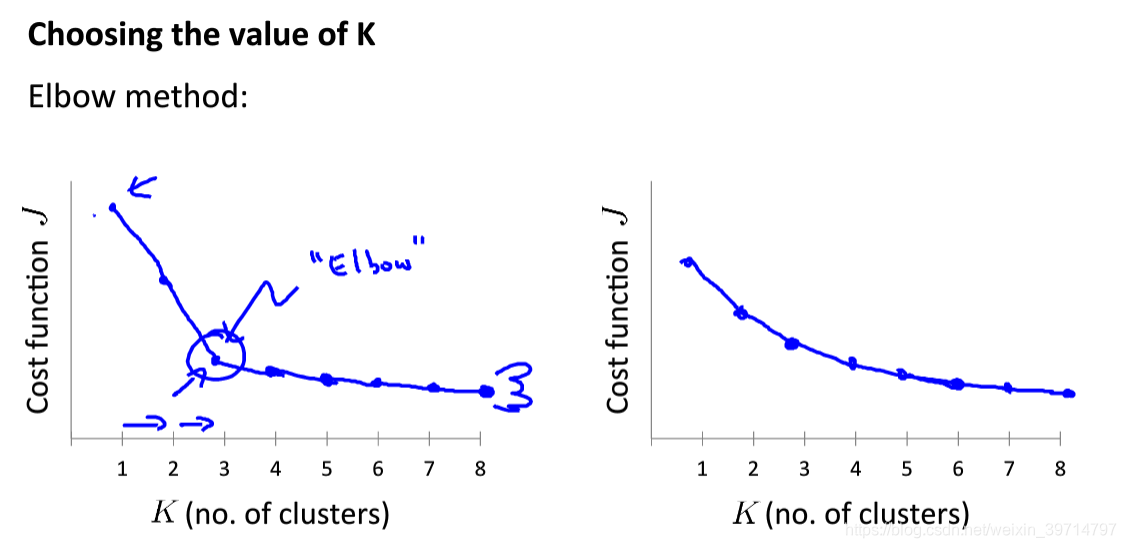
- “肘部”原则。
- 通过使用价值人工指定。

















 1949
1949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









